本文最后更新于:2 个月前
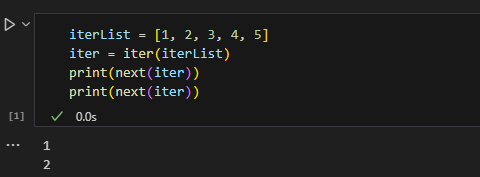
1 Python 爬虫两个核心语法 1.1 迭代器(iterator) 迭代器相当于一个函数,每次调用都可以通过 next()函数返回下一个值,如果迭代结束了,则抛出 StopIteration.异常。从遍历的角度看这和列表没什么区别,但它占用内存更少,因为不需要一下就生成整个列表。
1 2 3 4 iterList = [1 , 2 , 3 , 4 , 5 ]iter = iter (iterList) print (next (iter ))print (next (iter ))
1.2 生成器(generator) 在 Python 中,把使用了 yield 的函数称为生成器(generator)。生成器是一种特殊的迭代器,它形式上和函数很像,只是把 return 换成了 yield。函数在遇到 return 关键字时,会返回值并结束函数。而生成器在遇到 yield 关键字时,会返回迭代器对象,但不会立即结束,而是保存当前的位置,下次执行时会从当前位置继续执行 。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 def get_fibonacci (max_num ):0 , 1 ]while len (fibonacci) < max_num:1 ] + fibonacci[-2 ])return fibonaccidef get_fibonacci_generator (max_num ):0 ,1 ,0 while num < max_num:yield v11 for m in get_fibonacci_generator(10 ):print (m,end=" " )
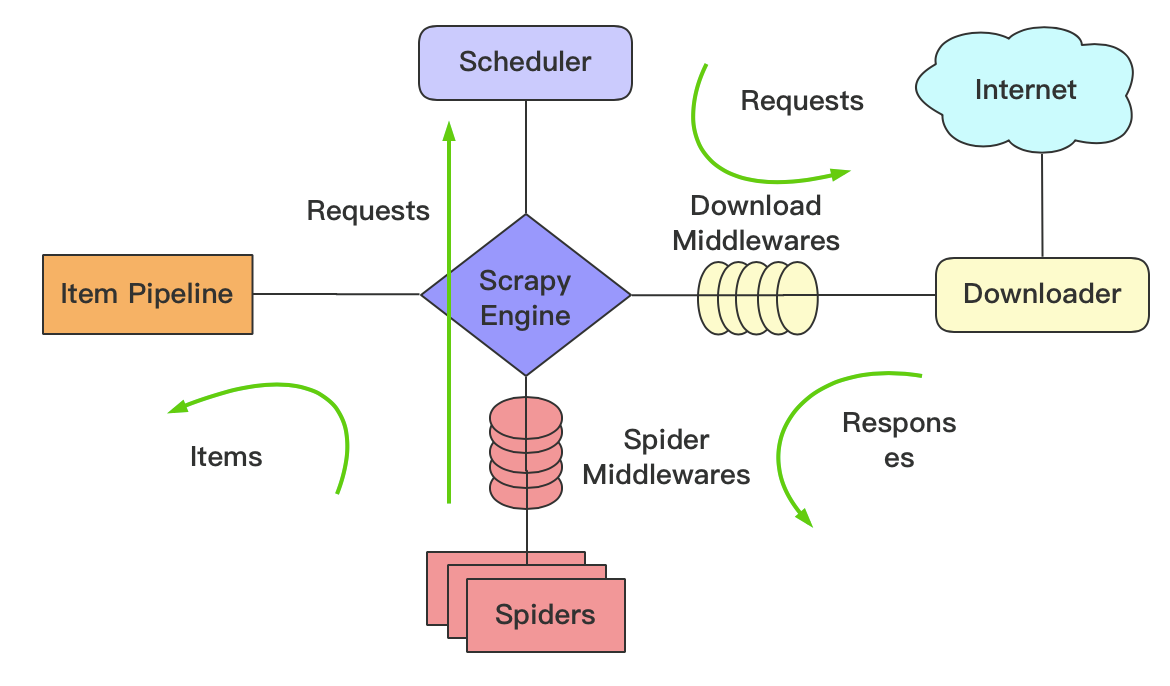
2 Scrapy 简介 2.1 引言 Scrapy 是一个基于 Python 的开源网络爬虫框架,用于快速、高效地从网页中提取数据。它提供了一套强大的工具和库,帮助用户轻松地创建和管理网络爬虫。Scrapy 支持并发请求、异步处理、数据存储和导出等功能,同时还提供了丰富的文档和教程,方便用户学习和使用。
graph TD
A[Scrapy] -->|Spider| B(Crawler)
A -->|Engine| C(Scheduler)
A --> D(Downloader)
B --> E(Pipeline)
C --> F(DupeFilter)
C --> G(Requests Queue)
D --> G
其中 Spider 负责从网站上爬取数据,Crawler 负责协调整个爬虫的流程,Scheduler 负责管理请求队列,Downloader 负责下载网页内容,Pipeline 负责处理爬取到的数据,DupeFilter 负责过滤重复的请求。Requests Queue 用于存储待处理的请求。
2.2 安装 为了方便管理 python 包,使用 anaconda 创建一个新环境进行 Scrapy 的学习,首先确保已经安装了 anaconda,接着打开 conda cmd 新建一个 python 环境并激活该环境,代码如下所示:
1 2 conda create -n master python=3.9
在 master 环境中安装 Scrapy 包:
1 2 pip install scrapy
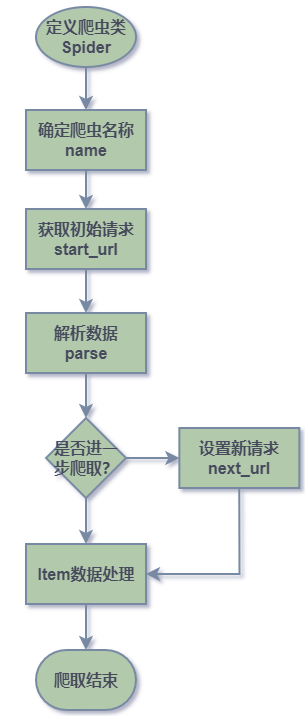
3 Scrapy 快速上手 3.1 起点中文网小说月票榜数据的爬取(静态网页入门) 3.1.1 爬取流程 在 spider 文件夹下创建的爬虫类按照一下流程进行爬取:start_requests 方法对目标地址发起请求,响应成功后自动调用默认回调函数 parse 进行数据解析处理,使用 css 或者 xpath 语法进行解析获取目标数据,再进行 yield 返回,如需进一步爬取需要发起新的请求并 yield 返回。
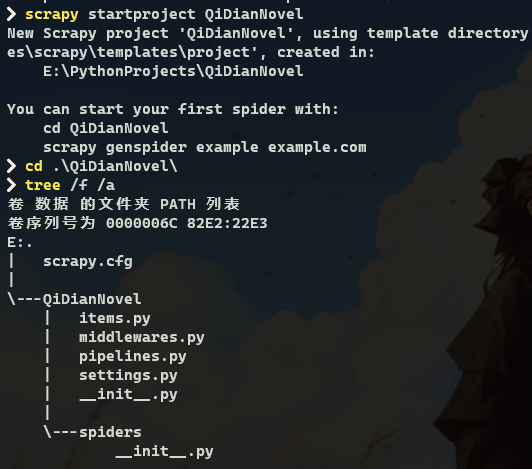
3.1.2 创建项目 使用 scrapy 命令创建一个 scrapy 项目,代码如下所示:
1 2 scrapy startproject <project_name> [project_dir]
创建结果和文件结构如下图所示:
1 2 3 4 5 6 7 8 9 10 E:.
3.1.3 创建爬虫 通过 scrapy genspider [options] <name> <domain> 生成爬虫文件,示例代码如下所示:
1 scrapy genspider qidian_novel https://www.qidian.com/rank/yuepiao/
3.1.4 编写爬取逻辑 根据需求分析中分析的待爬取网页的源代码结构,编写爬取逻辑如下所示:
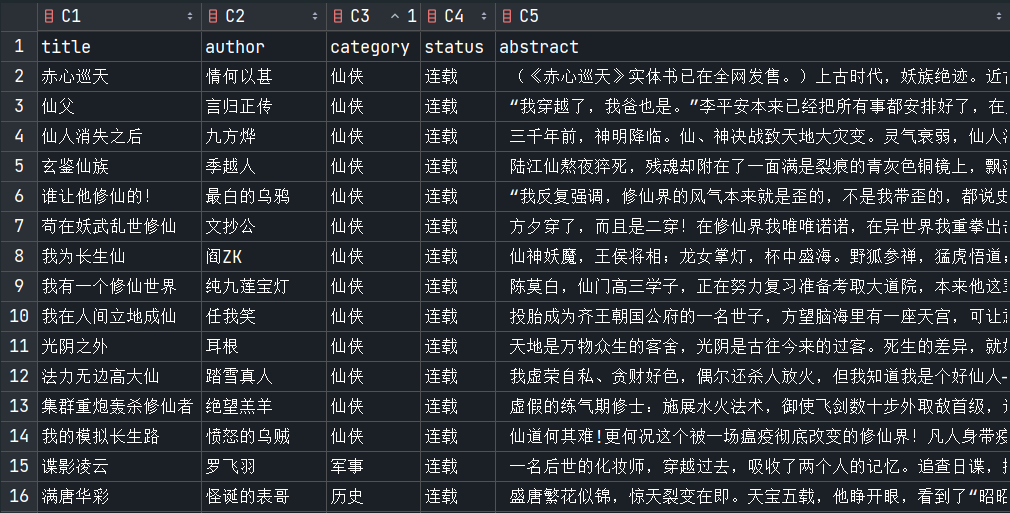
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 import scrapy from scrapy.spiders import Spider class QidianNovelSpider (Spider ): "qidian_novel" "www.qidian.com" ] "https://www.qidian.com/rank/yuepiao/" ] def parse (self, response ): '//div[@class="book-mid-info"]' ) for one_selector in list_selector: 'h2/a/text()' ).extract()[0 ] 'p[1]/a[1]/text()' ).extract()[0 ] 'p[1]/a[2]/text()' ).extract()[0 ] 'p[1]/span/text()' ).extract()[0 ] 'p[2]/text()' ).extract()[0 ] yield { 'title' : title, 'author' : author, 'category' : category, 'status' : status, 'abstract' : abstract "li.lbf-pagination-item > a.lbf-pagination-next::attr(href)" ).extract_first() "https:" + (response.url.replace(response.url, next_page_selector)) if next_page_url is not None and next_page_url != "javascript:;" : yield scrapy.Request(next_page_url)
3.1.5 执行爬取 在根目录下使用 scrapy crawl [options] <spider> 命令启动爬虫:
1 scrapy crawl qidian_novel -o novel.csv
爬取结果如下图所示:
4 Scrapy 基本用法 4.1 爬虫伪装 scrapy.Request 对象的参数和说明如下表所示:
参数
说明
url
请求的 URL 地址
callback
回调函数,用于处理返回的响应数据
method
请求方法,可以是 GET、POST 等
headers
请求头信息,字典型
body
请求体数据,用于 POST 请求
cookies
请求中携带的 cookies
meta
元数据,可以传递一些额外的信息
encoding
响应数据的编码方式
priority
请求的优先级
dont_filter
是否对该请求进行去重处理
errback
错误处理回调函数,处理请求发生错误时的情况
可以重写 start_requests 函数设置请求头参数对爬虫进行伪装避免被封禁。
1 2 3 4 5 6 7 8 def start_requests (self ):'User-Agent' : """Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36 Edg/96.0.1054.62""" for url in self.start_urls:yield scrapy.Request(url=url, headers=self.headers, callback=self.parse, dont_filter=True )
4.2 响应解析 在执行完请求获取到响应 Response 对象后,需要对其进行解析获取目标数据,scrapy 框架中的 Response 对象的常见参数与说明如下表所示:
参数
说明
url
响应的 URL 地址
status
响应的状态码
headers
响应的头部信息
body
响应的内容
flags
标志位,用于标识响应的一些特殊情况
request
生成响应的请求对象
meta
存储请求和响应之间传递的元数据
text
将响应内容解码为 Unicode 字符串
xpath()
对响应内容进行 XPath 查询
css()
对响应内容进行 CSS 选择器查询
4.2.1 Xpath 解析 Scrapy 框架中的 Response 对象提供了方便的方法来进行 XPath 解析。以下是一个简单的示例,演示如何在 Scrapy 中使用 Response 对象进行 XPath 解析:
1 2 3 4 5 6 7 8 9 import scrapyclass MySpider (scrapy.Spider):'myspider' 'http://example.com' ]def parse (self, response ):'//h1/text()' ).extract()for title in titles:print (title)
在上面的示例中,首先定义了一个名为 MySpider 的 Spider 类,并指定了要爬取的起始 URL。然后在 parse 方法中,使用 response 对象的 xpath 方法对页面进行解析,提取出所有 h1 标签中的文本内容,并将其打印出来。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 def parse (self, response ): '//div[@class="book-mid-info"]' ) for one_selector in list_selector: 'h2/a/text()' ).extract()[0 ] 'p[1]/a[1]/text()' ).extract()[0 ] 'p[1]/a[2]/text()' ).extract()[0 ] 'p[1]/span/text()' ).extract()[0 ] 'p[2]/text()' ).extract()[0 ] yield { 'title' : title, 'author' : author, 'category' : category, 'status' : status, 'abstract' : abstract
4.2.2 Css 解析 CSS 全称 Cascading Style Sheets,即层叠样式表,用于表现 HTML 或 XML 的样式。CSS 表达式的语法比 XPath 简洁,但是功能不如 XPath 强大,大多作为 XPath 的辅助。
空格 可以跳跃式解析标签,>是一层一层解析不能跳跃。
表达式
说明
示例
*
选取所有元素
*div ul *::text( 获取ul所有子标签的文本 )
tag > subtag <=> tag subtag选取 tag 的子标签
div > h1 / div h1
tag选择所有具有该标签的元素
div
.class选择所有具有该类的元素
.main-content / .base.default(多个class使用.拼接)
#id选择具有该 id 的元素
#header
[attribute]选择具有指定属性的元素
[href]
[attribute=value]选择具有指定属性值的元素
[href="https://www.example.com"]
:nth-child(n)
选择父元素下第 n 个子元素
ul li:nth-child(2)
:nth-last-child(n)
选取元素是其父元素的倒数第 n 个子元素
p:nth-last-child(1)
:not(selector)
排除符合选择器条件的元素
div:not(.main-content)
:first-child
选择第一个子元素
li:first-child
E::text获取 E 元素的文本
h1::text
例如,假设我们想要从一个网页中提取所有标题的文本信息,可以这样做:
1 titles = response.css('h1::text' ).extract()
这个代码将使用 css 选择器找到所有 h1 标签,并提取其文本内容存储在 titles 变量中。如果我们想要找到所有 class 为”article”的 div 标签下的段落文本内容,可以这样做:
1 paragraphs = response.css('div.article > p::text' ).extract()
这个代码将使用 css 选择器找到所有 class 为”article”的 div 标签下的所有段落标签,并提取其文本内容存储在 paragraphs 变量中。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 def parse (self, response ): 'div[class="book-mid-info"]' ) for one_selector in list_selector: 'h2 a::text' ).extract_first() 'p.author > a::text' ).extract_first() 'p.author > a::text' ).extract()[1 ] 'p.author > span::text' ).extract_first() 'p.intro::text' ).extract_first() yield { 'title' : title, 'author' : author, 'category' : category, 'status' : status, 'abstract' : abstract
4.3 Item 封装数据 前面,我们使用 Spider 从页面中提取数据的方法,并且将提取出来的字段保存于字典中。字典使用虽然方便,但也有它的缺陷:
字段名拼写容易出错且无法检测 到这些错误。
返回的数据类型无法确保一致性 。
不便于将数据传递 给其他组件(如传递给用于数据处理的 pipeline 组件)。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 class QidiannovelItem (scrapy.Item): from QiDianNovel.items import QidiannovelItem'title' ] = title 'author' ] = author 'category' ] = category 'status' ] = status 'abstract' ] = abstract yield item
4.4 ItemLoader 填充数据
统一解析与封装操作,简化数据封装过程 。
目前为止我们爬取的数据的字段较少,但是当项目很大,提取的字段数以百计时,数据的提取规则也会越来越多,再加上还要对提取到的数据做转换处理,代码就会变得庞大,维护起来十分困难。
Item 提供保存抓取到数据的容器,需要手动将数据保存于容器 中。Itemloader 提供的是填充容器的机制 。
1 2 3 4 5 6 7 8 9 10 11 def parse (self, response ): 'div[class="book-mid-info"]' ) for one_selector in list_selector: "title" , 'h2 a::text' ) "author" , 'p.author > a::text' ) "category" , 'p.author > a::text' ) "status" , 'p.author > span::text' ) "abstract" , 'p.intro::text' ) yield novel.load_item()
上面返回值 novel.load_item()是一个字典,字典中包含每个字段的列表,需要进一步处理得到需要的值.
1 2 3 4 5 6 7 { : [ '一名后世的化妆师,穿越过去,吸收了两个人的记忆。追查日谍,捣毁无数日谍组织,抓捕一名又一名日谍的楚凌云,同时伪装成日本人,深入敌群,套取情报,周旋在日本高层之中。在那个动荡的年代,楚凌云用自己的机智和智慧,为祖国的烽火事业贡献着自己的力量,立下了不可磨灭的功勋。'] , : [ '罗飞羽', '军事', '谍战特工'] , : [ '罗飞羽', '军事', '谍战特工'] , : [ '连载'] , : [ '谍影凌云'] }
4.5 Pipeline 处理数据 当 Spider 将收集到的数据封装为 Item 后,它将会被传递到 Item Pipeline(项目管道)组件中等待进一步处理。
清理数据
验证数据的有效性
查重并丢弃
将数据按照自定义的格式存储到文件中
将数据保存到数据库中
pipeline 默认是关闭的,需要在 setting.py 中开启 ITEM_PIPELINES :
1 2 3 ITEM_PIPELINES = { "QiDianNovel.pipelines.QidiannovelPipeline" : 300 ,
接着编写 pipelines.py 处理逻辑对爬取返回的每个 item 进行处理:
1 2 3 4 5 6 7 8 9 10 11 class QidiannovelPipeline : def __init__ (self ): set () def process_item (self, item, spider ): """ 对item去重 :param item:每个item是解析后的一整条数据 :param spider: :return: """ if item['title' ] in self.author_set: raise DropItem("查找到重复标题的项: %s" % item) return item
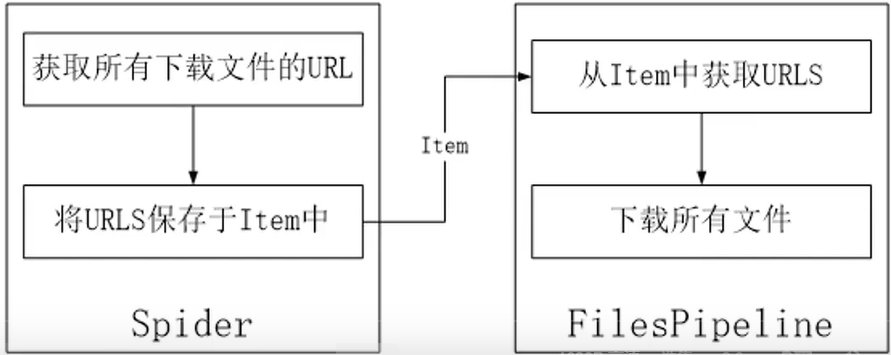
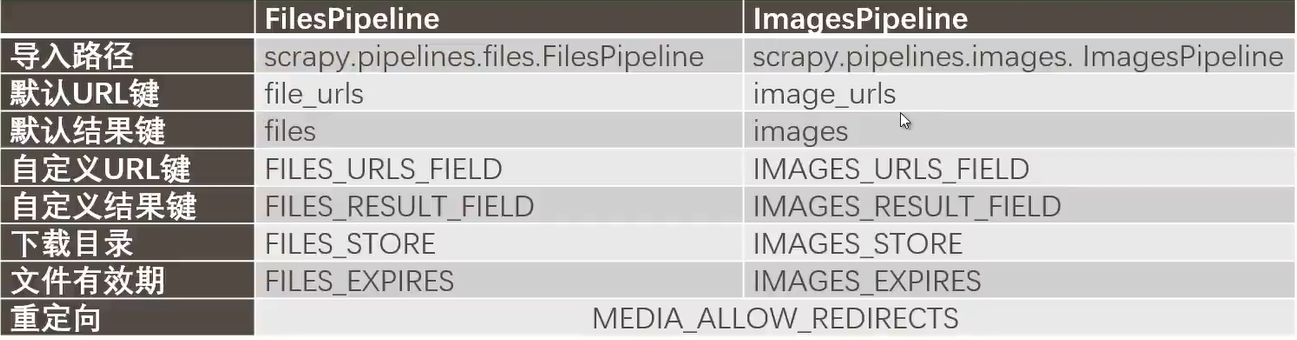
4.6 文件和图片下载 基于文件下载在爬虫中的普遍性和实用性,Scrapy 提供了文件管道 FilesPipeline 用于实现文件的下载。你也可以扩展 FilesPipeline,实现自定义的文件管道功能。
在 Spider 中,将想要下载的文件 URL 地址保存到一个列表中,并赋给 key 为 file_urls 的 Item 字段中(item["file_urls"])。
引擎将 Item 传入到 FilesPipeline 管道中。
FilesPipeline 获取 Item 后,会读取 Item 中 key 为 file urls 的字段(item[“file_urls”]),再根据获得的 URL 地址下载文件。Item 在 FilesPipeline 管道中处于“锁定”状态,直到所有文件全部下载完(或者某种原因下载失败)。
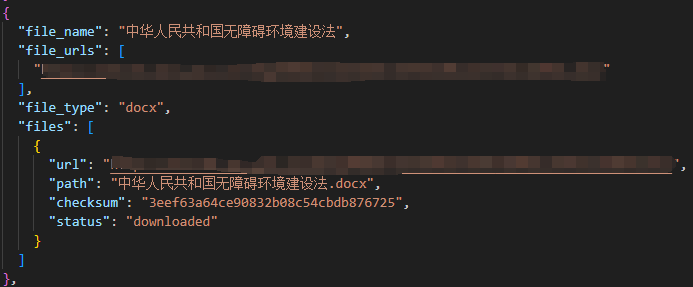
所有文件下载完后,会将各个文件下载的结果信息收集到一个列表中,并赋给 key 为 files 的 Item 字段中(item[“files])。
文件下载的路径
文件的 URL 地址
文件的校验和(Checksum)
4.6.1 文件下载 4.6.1.1 爬取 Seaborn 案例源文件 人工智能、大数据领域的学习者和开发者,对 seaborn 一定不会感到陌生。它是一个免费的、基于 Python 的数据统计可视化库,它提供的高级界面,能够绘制极富吸引力且信息丰富的统计图形。图中就是通过 seaborn,展示的统计图形。Example gallery — seaborn 0.9.0 documentation 本项目要求实现将 seaborn 中所有应用案例的源文件下载到本地。
定义数据结构:
1 2 3 4 5 class SeabornItem (scrapy.Item):
爬取解析逻辑实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 from scrapy import Requestfrom scrapy.http import Requestfrom scrapy.spiders import Spiderfrom Seaborn.items import SeabornItemclass SeabornSpider (Spider ):'seaborn' 'seaborn.com' ]'http://seaborn.pydata.org/archive/0.9/examples/index.html' ]def start_requests (self ):yield Request(url=self.start_urls[0 ], callback=self.parse)def parse (self, response ):'div.figure.align-center a::attr(href)' ).extract()for href in rel_urls:yield Request(url=abs_url, callback=self.parse_file)def parse_file (self, response ):'a.reference.download.internal::attr(href)' ).extract_first()print (abs_down_url)'file_urls' ] = [abs_down_url]yield item
执行上述爬虫,由于网络问题,目标网站是外网,因此无法访问成功。
4.6.1.2 爬取国家法律法规数据库 为了方便学习查阅国家法律法规,合理获取法条信息,用于学习研究,以国家法律法规数据库 为目标获取法律法规文件。
定义数据结构
1 2 3 4 5 6 class LawItem (scrapy.Item):
定义文件下载保存 pipeline
1 2 3 4 5 6 7 8 from scrapy.pipelines.files import FilesPipelinefrom scrapy import Requestclass SaveFilePipeline (FilesPipeline ):def file_path (self, request, response=None , info=None , *, item=None ):'file_name' ] + '.' + item['file_type' ] 'file_type' ] return folder_name + '/' + file_name
修改全局配置文件
1 2 3 4 5 6 7 USER_AGENT = "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:120.0) Gecko/20100101 Firefox/120.0" True """文件下载存储路径""" './laws' "Seaborn.pipelines.SaveFilePipeline" : 300 ,
编写爬取解析逻辑
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 from scrapy.http import Request,FormRequestfrom scrapy.spiders import Spiderfrom Seaborn.items import LawItemimport requests,re,jsonclass LawSpider (Spider ):'law' 'flk.npc.gov.cn' ]'https://flk.npc.gov.cn/api/?type=flfg&searchType=title%3Bvague&sortTr=f_bbrq_s%3Bdesc&gbrqStart=&gbrqEnd=&sxrqStart=&sxrqEnd=&sort=true&size=10&_=1702872631228' ]'http://127.0.0.1:7890' 1 def test_proxy (self,proxy ):try :'http://httpbin.org/get' ,proxies={'http' :proxy},timeout=10 )print (r.text)except Exception as e:print (e)def start_requests (self ):0 ]+"&page=%d" %self.concurrent_pageyield Request(url=self.start_urls[0 ], callback=self.parse,errback=self.errback,meta={'proxy' :self.proxy,'timeout' :10 })def errback (self, failure ):print (failure)def parse (self, response ):'result' ]'data' ]'totalSizes' ]/10 for info in data:'title' ]print (file_name)id = info['id' ]'https://flk.npc.gov.cn/api/detail' yield FormRequest(url=api_url,method="POST" ,formdata={'id' : id },callback=self.parse_file,meta={'file_name' :file_name,'proxy' :self.proxy,'timeout' :10 },dont_filter=True )1 if self.concurrent_page <= 2 :0 ]+"&page=%d" %self.concurrent_pageyield Request(url=next_url, callback=self.parse,errback=self.errback,meta={'proxy' :self.proxy,'timeout' :10 })def parse_file (self, response ):'file_name' ] = response.meta['file_name' ]'result' ]['body' ][0 ]['path' ]'https://wb.flk.npc.gov.cn' +rel_url'file_urls' ] = [abs_url]'file_type' ] = rel_url.split('.' )[-1 ]yield item
爬取结果如下所示:
4.6.2 图片下载 Scrapy 还提供了图片管道 ImagesPipeline 用于实现图片的下载,也可以扩展 ImagesPipeline,实现自定义的图片管道功能。
下载图片必须安装 Pillow 依赖才可以使用:
4.6.2.1 爬取彼岸图网图片 4.6.2.1.1 需求分析
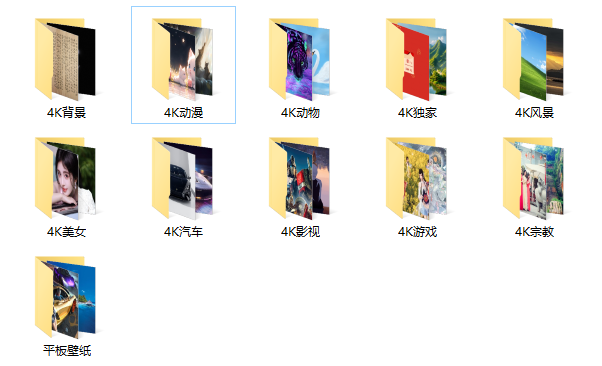
下载彼岸图网中不同主题的第一页图片
下载后的图片名称不变
相同主题的图片放于同一文件夹中,且文件夹按照主题命名
每张图片同时生成两张大小不同的缩略图
忽略尺寸过小的图片(高或宽低于 10 像素)
4.6.2.1.2 逻辑实现
数据结构定义:
1 2 3 4 5 class BianimageItem (scrapy.Item):
图片下载 pipeline 自定义设置:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 from scrapy.pipelines.images import ImagesPipelineclass SaveImagePipeline (ImagesPipeline ):def get_media_requests (self, item, info ):"""传递图片主题""" return [Request(u, meta={'subject' : item['subject' ]}) for u in urls]def file_path (self, request, response=None , info=None , *, item=None ):"""图片重命名""" 'subject' ]'/' )[-1 ]return "%s/%s" % (image_subject, image_name)def thumb_path (self, request, thumb_id, response=None , info=None , *, item=None ):"""设置缩略图路径及名称""" 'subject' ]'/' )[-1 ]return "%s/%s/%s" % (image_subject,thumb_id,image_name)
全局配置文件设置:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 USER_AGENT = "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:120.0) Gecko/20100101 Firefox/120.0" False "./images" "small" : (50 , 50 ),"big" : (270 , 270 ),20 20 "BianImage.pipelines.SaveImagePipeline" : 300 ,
爬取解析逻辑:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 from scrapy import Spider,Requestfrom BianImage.items import BianimageItemclass ImageSpider (Spider ):'bianimage' def start_requests (self ):'https://pic.netbian.com' yield Request(url, callback=self.parse_subject)def parse_subject (self, response ): 'div.classify.clearfix a' )for subject in subjects:'::attr(href)' ).extract_first()'::text' ).extract_first()yield Request(subject_url, callback=self.parse_image,meta={'subject_name' :subject_name})def parse_image (self, response ): 'image_urls' ] = []'subject' ] = response.meta['subject_name' ]'div.slist ul li:not(.nextpage)' )for image in image_li:'a img::attr(src)' ).extract_first()'image_urls' ].append(image_url)yield item
爬取结果如下所示:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 { "image_urls" : [ "https://pic.netbian.com/uploads/allimg/231216/234451-170274149161e1.jpg" , "https://pic.netbian.com/uploads/allimg/231216/234033-1702741233387f.jpg" ] , "subject" : "4K美女" , "images" : [ { "url" : "https://pic.netbian.com/uploads/allimg/231216/234451-170274149161e1.jpg" , "path" : "4K美女/234451-170274149161e1.jpg" , "checksum" : "14ce6e92e874a8ad7c80e639e9e6f367" , "status" : "uptodate" } , { "url" : "https://pic.netbian.com/uploads/allimg/231216/234033-1702741233387f.jpg" , "path" : "4K美女/234033-1702741233387f.jpg" , "checksum" : "4243357f475f2e820f4c1c2e5d330e51" , "status" : "uptodate" } ] } ,
5 实战案例 5.1 链家网二手房信息(列表—>详情多页面数据传递爬取) 5.1.1 需求分析 链接地址: https://wh.lianjia.com/ershoufang/
使用 Scrapy 爬取链家网中武汉市二手房交易数据并保存于 CSV 文件中。
房屋名称
房屋户型
建筑面积
房屋朝向
装修情况
有无电梯
房屋总价
房屋单价
房屋年限
要求:
房屋面积、总价和单价只需要具体的数字,不需要单位名称。
删除字段不全的房屋数据,如有的房屋朝向会显示“暂无数据”,应该剔除。
保存到 CSV 文件中的数据,字段要按照如下顺序排列:房屋名称,房屋户型,建筑面积,房屋朝向,装修情况,有无电梯,房屋总价,房屋单价,房屋年限。
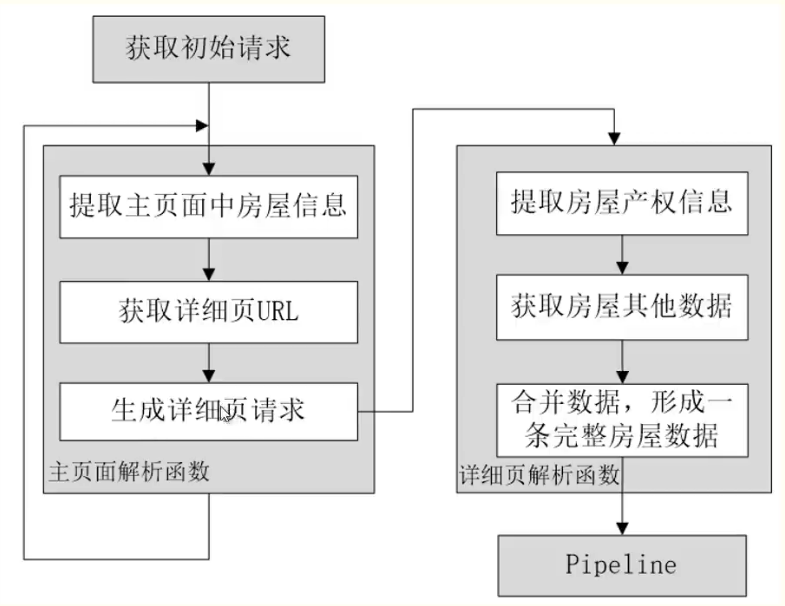
流程图 :
实现流程 :
创建项目 scrapy startproject lianjia_home
使用 ltem 封装数据
创建 Spideri 源文件及 Spider 类
获取初始请求(start requests())
实现主页面解析函数(parse0)
实现详细页解析函数使用 Pipeline 实现数据的处理
启用 Pipeline
运行爬虫
5.1.2 初步爬取 在 items.py 中定义数据格式:
1 2 3 4 5 6 7 8 9 10 11 class LianjiaHomeItem (scrapy.Item):type = scrapy.Field()
在 spiders 文件夹下创建 lianjia_spider.py 文件编写爬取解析逻辑,具体代码如下所示:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 from scrapy import Spiderfrom scrapy import Requestfrom lianjia_home.items import LianjiaHomeItemclass LianjiaSpider (Spider ):'home' 'https://wh.lianjia.com/ershoufang/' 1 def start_requests (self ):yield Request(url=self.start_url, callback=self.parse)def parse (self, response ):""" 解析房源列表页面 """ 'ul.sellListContent > li' )for each in list_selector:try :'div.positionInfo a::text' ).extract_first() 'div.houseInfo::text' ).extract_first() '|' )type = other_list[0 ].strip(" " ) 1 ].strip(" " ) 2 ].strip(" " ) 3 ].strip(" " ) 'div.totalPrice span::text' ).extract_first() 'div.unitPrice span::text' ).extract_first() 'name' ] = name'type' ] = type 'area' ] = area'direction' ] = direction'fitment' ] = fitment'total_price' ] = total_price'unit_price' ] = unit_price'div.info > div.title > a::attr(href)' ).extract_first()yield Request(url=detail_url, callback=self.parse_detail, meta={'item' : item})except :pass 1 100 if self.current_page <= total_page:'pg{}' .format (self.current_page)print ("下一页地址为:" +next_page)yield Request(url=next_page, callback=self.parse)def parse_detail (self, response ):""" 解析详细页 """ 'item' ]'elevator' ] = response.css('div.base div.content ul li:nth-last-child(1)::text' ).extract_first()'age' ] = response.css('div.transaction div.content ul li:nth-child(5) span:nth-last-child(1)::text' ).extract_first()yield item
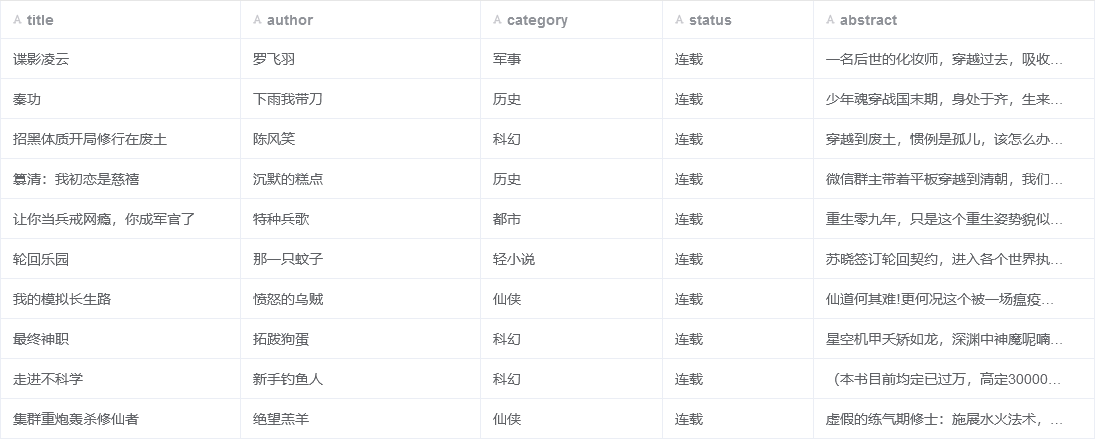
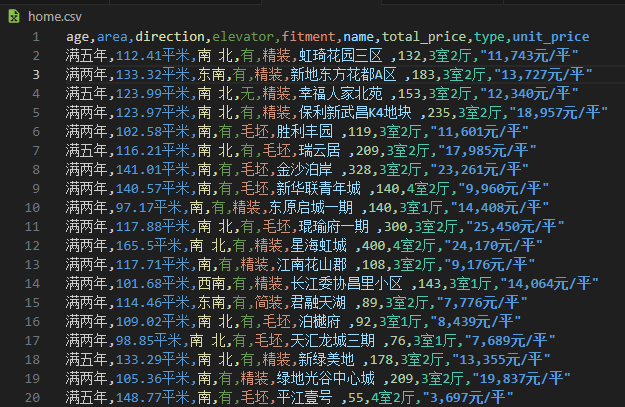
在终端执行 scrapy crawl home -o home.csv 命令进行爬取,爬取结果保存于 home.csv 文件中,部分内容如下图所示:
5.1.3 数据过滤 对于房屋面积、单价只保留数字即可取出多余的文字,对于缺失房屋朝向字段的数据进行删除。
在 pipelines.py 文件中编写数据清洗过滤和保存逻辑,具体代码如下所示:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 from itemadapter import ItemAdapterfrom scrapy.exceptions import DropItemimport reclass LianjiaHomePipeline :def process_item (self, item, spider ):""" 数据清洗过滤 """ "area" ] = re.findall(r"\d+\.?\d*" , item["area" ])[0 ] "unit_price" ] = re.findall(r"\d+\,?\d*" , item["unit_price" ])[0 ].replace(',' , '' ) if item["direction" ] == "暂无数据" : raise DropItem("房屋朝向没有数据,抛弃此条数据项: %s" %item)return itemclass CSVPipeline (object ):""" 将数据写入 csv 文件中 """ None 0 'name' ,'type' ,'area' ,'direction' ,'fitment' ,'elevator' ,'total_price' ,'unit_price' ,'age' ]def open_spider (self, spider ): open ('lianjia_home.csv' , 'a' , encoding='utf-8' )def process_item (self, item, spider ): if self.index == 0 : ',' .join(self.column_name_list)'\n' )1 ',' .join([str (item.get(field, '' )) for field in self.column_name_list])'\n' )return itemdef close_spider (self, spider ):
开启 settings.py 中的 ITEM_PIPELINES 管道,首先进行数据清洗过滤,再进行数据持久化存储:
1 2 3 4 ITEM_PIPELINES = {"lianjia_home.pipelines.LianjiaHomePipeline" : 300 , "lianjia_home.pipelines.CSVPipeline" : 400 ,
为了避免每次都要手动再命令行开启爬虫,编写 start.py 文件执行爬取命令,简化操作,文件内容如下所示:
1 2 3 from scrapy import cmdline"scrapy crawl lianjia_home" .split())
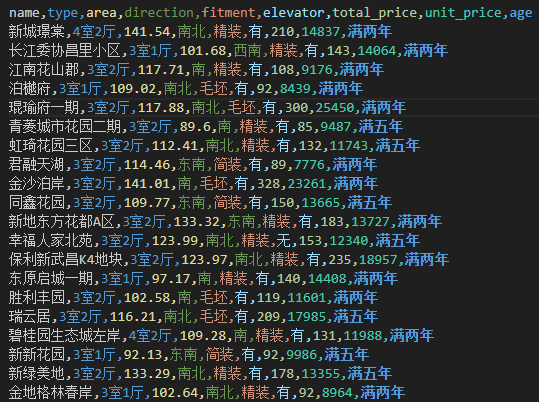
运行 start.py 文件爬取结果保存于 csv 文件中如下所示:
5.1.4 持久存储(数据库) 5.1.4.1 Mysql 数据库
python 安装 mysql 库便于使用 python 直接操作 mysql 数据库,首先需要安装 mysqlclient 第三方库:
保存 qidianNovel 项目中爬取的数据到 mysql 数据库,首先新建 mysql 数据库和数据表定义数据结构:
编写 pipeline 将数据持久化存储到 mysql 数据库:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 import MySQLdbclass MysqlPipeline (object ): def open_spider (self, spider ): 'MYSQL_DBNAME' , 'qidian' )'MYSQL_USER' , 'root' )'MYSQL_PASSWORD' , '123456' )'MYSQL_HOST' , 'localhost' )'utf8' ) def process_item (self, item, spider ): 'title' ],item['author' ],item['category' ],item['status' ],item['abstract' ]) "INSERT INTO novel(title,author,category,status,abstract) VALUES(%s,%s,%s,%s,%s)" return itemdef close_spider (self, spider ):
修改 setting.py 启用 item_pipelines:
1 2 3 4 5 6 7 8 9 10 ITEM_PIPELINES = {"QiDianNovel.pipelines.QidiannovelPipeline" : 300 , "QiDianNovel.pipelines.MysqlPipeline" : 400 , 'localhost' 3306 'root' '123456' 'qidian'
启动爬虫,存储于 MySQL 数据库的结果如图所示:
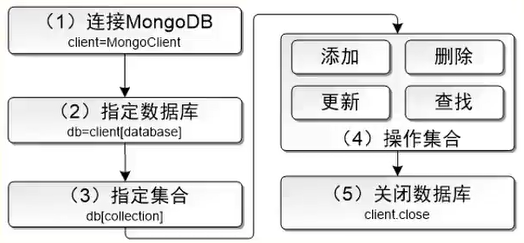
5.1.4.2 MongoDB 数据库 基础用法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 import pymongo 1. "localhost" ,port=27017 )'mongodb://localhost:27017/) 2. #指定集合 db_collection db["hot"] 3. #插入数据 novel-={' name':' 太初', #名称 ' author':' 高楼大厦', #作者 ' form':' 连载', #形式 ' type ':' 玄幻' #类型 } 4. #调用db_collection的insert_one/many方法将新文档插入到集合 result = db_collection.insert_one(novel) result = db_collection.insert_many([novel1,novel2]) print(result) print(result.inserted id) 5. #查询数据 result = db_collection.find_one({"name":"帝国的崛起"}) print(result) cursor = db_collection.find() cursor = db_collection.find({"type":"历史"}) 6. #可以使用集合的update oneO 和 update many()方法实现文档的更新。前者仅更新一个文档;后者可以批量更新多个文档。 7. #删除数据 result = db_collection.delete_one({"name":"太初"}) result = db_collection.delete_many({"type":"历史"}) 8. #关闭数据库 db_client.close()
python 安装 mongodb 库便于使用 python 直接操作 mongodb 数据库,首先需要安装 pymongo 第三方库:
mongodb 操作流程:
编写 pipeline 将数据持久化存储到 mongodb 数据库:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 import pymongoclass MongoDBPipeline (object ):def open_spider (self, spider ): 'MONGODB_HOST' , 'localhost' )'MONGODB_PORT' , 27017 )'MONGODB_DATABASE' , 'qidian' )'MONGODB_COLLECTION' , 'novel' )def process_item (self, item, spider ): dict (item)return itemdef close_spider (self, spider ):
修改 setting.py 启用 item_pipelines:
1 2 3 4 5 6 7 8 9 10 11 ITEM_PIPELINES = {"QiDianNovel.pipelines.QidiannovelPipeline" : 300 ,"QiDianNovel.pipelines.MongoDBPipeline" : 400 ,'MONGODB_HOST' : 'localhost' ,'MONGODB_PORT' : 27017 ,'MONGODB_DATABASE' : 'qidian' ,'MONGODB_COLLECTION' : 'novel' ,
启动爬虫,存储于 MongoDB 数据库的结果如图所示:
5.1.4.3 Redis 数据库
python 安装 redis 库便于使用 python 直接操作 redis 数据库,首先需要安装 redis 第三方库:
编写 pipeline 将数据持久化存储到 redis 数据库:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 import redisclass RedisPipeline (object ):def open_spider (self, spider ): 'REDIS_HOST' , 'localhost' )'REDIS_PORT' , 6379 )'REDIS_DB' , 1 )'REDIS_PASSWORD' , '123456' )def process_item (self, item, spider ): dict (item)) 'novel' ,item_json) return itemdef close_spider (self, spider ):
修改 setting.py 启用 item_pipelines:
1 2 3 4 5 6 7 8 9 10 11 ITEM_PIPELINES = {"QiDianNovel.pipelines.QidiannovelPipeline" : 300 ,"QiDianNovel.pipelines.RedisPipeline" : 400 ,'REDIS_HOST' : 'localhost' ,'REDIS_PORT' : 6379 ,'REDIS_DB' : 1 ,'REDIS_PASSWORD' : '123456' ,
启动爬虫,存储于 Redis 数据库的结果如图所示:
5.2 QQ 音乐榜单歌曲(访问 Json 数据接口解析) 流行指数榜 - QQ音乐-千万正版音乐海量无损曲库新歌热歌天天畅听的高品质音乐平台! 的数据以 js 动态渲染,可以直接采用开发者提供的 https://c.y.qq.com/v8/fcg-bin/fcg_v8_toplist_cp.fcg?&topid=4 访问该接口可以直接返回排行榜 json 数据。
5.2.1 定义数据结构 在 items.py 中定义需要爬取的数据的结构:
1 2 3 4 5 6 class KwmusicItem (scrapy.Item):
5.2.2 编写爬取逻辑 在 spiders 文件夹下新建 music_spider.py 编写爬虫类和爬取解析逻辑:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 from typing import Any , Iterablefrom scrapy import Requestfrom scrapy.http import Request, Responsefrom scrapy.spiders import Spiderfrom KWMusic.items import KwmusicItemimport jsonclass MusicSpider (Spider ):'music' 'c.y.qq.com' ]def __init__ (self, *args, **kwargs ):super (MusicSpider, self).__init__(*args, **kwargs)' https://c.y.qq.com/v8/fcg-bin/fcg_v8_toplist_cp.fcg?&topid=4 ' ]def start_requests (self ) -> Iterable[Request]:yield Request(url=self.start_urls[0 ], callback=self.parse)def parse (self, response: Response, **kwargs: Any ) -> Any :for music in music_dict['songlist' ]:'song_name' ] = music['data' ]['songname' ] 'album_name' ] = music['data' ]['albumname' ] 'singer_name' ] = music['data' ]['singer' ][0 ]['name' ] 'interval' ] = music['data' ]['interval' ] yield item
5.2.3 数据存储与启动 将获取的信息保存为 music.json 文件,编写 start.py 脚本进行爬取并保存:
1 2 3 4 from scrapy.cmdline import executeif __name__ == "__main__" :"scrapy crawl music -o music.json" .split())
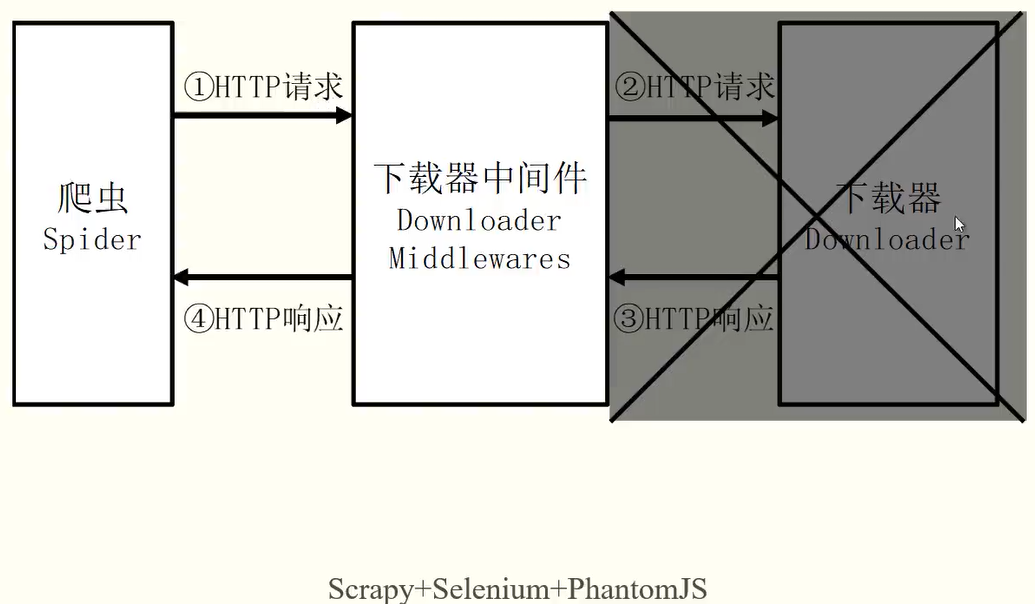
6 Selenium 实现动态页面爬取 对于 js 动态渲染的数据且请求链接经过参数加密动态生成毫无规律时无法通过指定地址进行爬取时,使用 Selenium 进行爬取。
6.1 Selenium 安装
安装 python 库 selenium
安装浏览器驱动程序
(2)下载 Chromedriver
(3)配置环境变量。Download PhantomJS 无头浏览器,提高爬虫效率
6.2 爬取豆瓣中国大陆电影(js 动态渲染或者需要手动下滑等操作网页) 6.2.1.1 需求分析 豆瓣电影网址为 选电影 。页面默认显示 20 条电影信息,将页面拉到最底端,会再加载 20 条信息。因此,如果想要查看更多电影,就必须不断下拉页面。本项目希望使用网络爬虫技术,将尽量多的热点新闻爬取下来保存于 CSV 文件中。
6.2.1.2 方案设计
由于 PhantomJS 浏览器在新版本的 selenium 中已经被弃用,因此采用 firefox 浏览器进行爬取
6.2.1.3 逻辑实现
定义数据结构 :
1 2 3 4 5 6 7 8 9 10 class DoubanmovieItem (scrapy.Item):type = scrapy.Field()
实现下载中间件:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 import timefrom scrapy.http import HtmlResponsefrom selenium.webdriver.common.by import By from selenium.webdriver.support.wait import WebDriverWait from selenium.webdriver.support import expected_conditions as EC from selenium.common.exceptions import TimeoutException, NoSuchElementException class DoubanmovieDownloaderMiddleware :def process_request (self, request, spider ):if spider.name == 'doubanmovie' :try :5 ).until(EC.presence_of_element_located((By.CSS_SELECTOR, 'div.playable-filter-title' )))'div.playable-filter-title' ) 5 ).until(EC.presence_of_element_located((By.CSS_SELECTOR, 'div.article' )))'div.explore-more > button' ) for i in range (5 ): 5 )'utf-8' ,body=origin_code,request=request)return resexcept TimeoutException:print ("time out -> 访问超时" )except NoSuchElementException:print ("no such element -> 没有此元素" )return None
编写 pipelines 管道进行数据清洗 :
1 2 3 4 5 6 7 class DoubanmoviePipeline :def process_item (self, item, spider ):for key in item.keys():if isinstance (item[key], str ):return item
实现 spider 爬取解析逻辑 :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 from typing import Any , Iterable, Optional from scrapy.http import Requestfrom scrapy.spiders import Spiderfrom scrapy import Requestfrom DoubanMovie.items import DoubanmovieItemfrom selenium import webdriverclass DoubanSpider (Spider ):'doubanmovie' 'movie.douban.com' ]def __init__ (self, **kwargs: Any ):'-headless' )' https://movie.douban.com/explore ' ]def start_requests (self ) -> Iterable[Request]:yield Request(url=self.start_urls[0 ], callback=self.parse)def parse (self, response ):'ul.explore-list li' ) for movie in movie_li_selector:'a::attr(href)' ).extract_first()'div.drc-subject-info div:nth-child(1) span::text' ).extract_first()'div.drc-subject-info div:nth-last-child(1) span.drc-rating-num::text' ).extract_first()'div.drc-subject-info div:nth-child(1) div::text' ).extract_first()"/" )'url' ] = url'title' ] = title'rating' ] = rating'year' ] = others_ls[0 ]'source' ] = others_ls[1 ]'type' ] = others_ls[2 ]'director' ] = others_ls[3 ]'actors' ] = others_ls[4 ]yield item
修改 setting 开启代理、下载中间件和项目管道 :
1 2 3 4 5 6 7 8 9 10 11 12 ROBOTSTXT_OBEY = False "Accept" : "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8" ,"Accept-Language" : "en" ,"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:120.0) Gecko/20100101 Firefox/120.0" "DoubanMovie.middlewares.DoubanmovieDownloaderMiddleware" : 543 ,"DoubanMovie.pipelines.DoubanmoviePipeline" : 300 ,
编写 start.py 文件执行命令行命令快速开启爬虫:
1 2 3 4 from scrapy.cmdline import executeif __name__ == "__main__" :"scrapy crawl doubanmovie -o doubanmovie.json" .split())
爬取结果如下图所示:
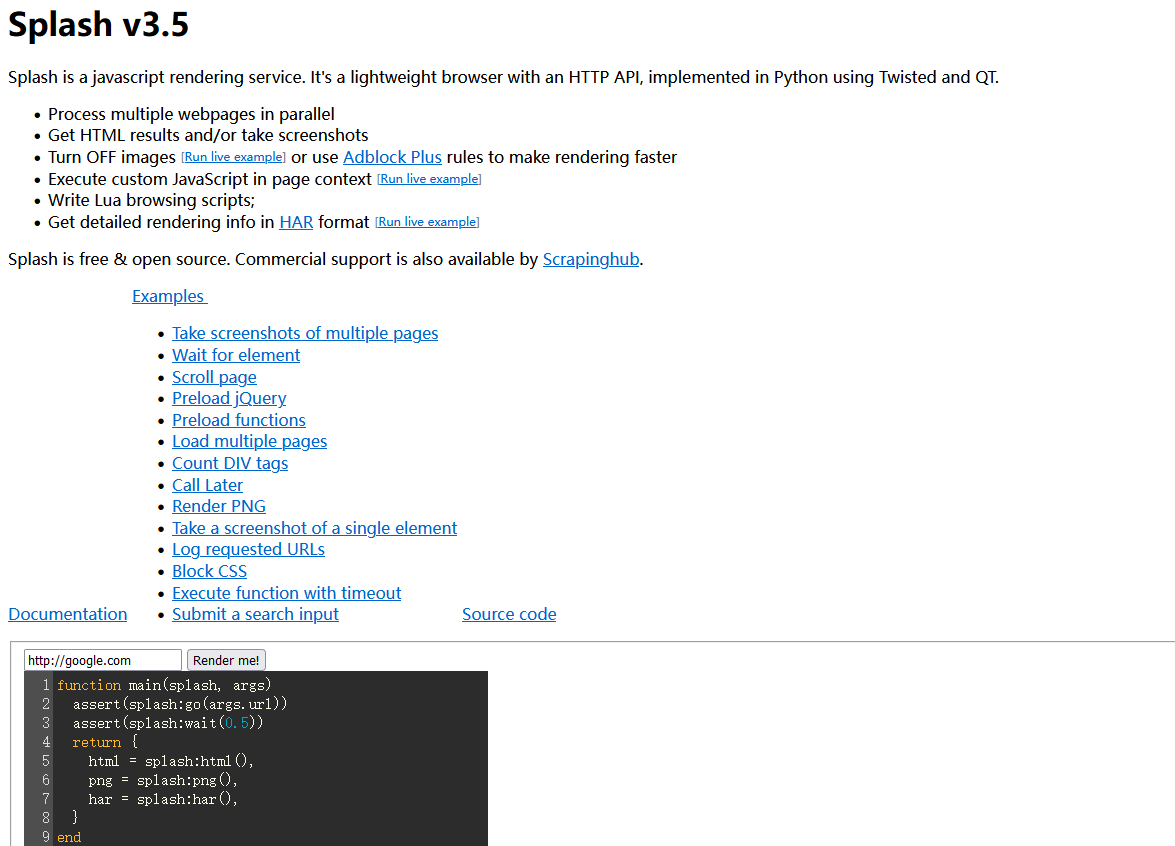
7 Splash 实现动态页面爬取 7.1 Splash 简介 Splash 提供了一个 HTTP API,可以接收 URL 和一些可选参数,并返回渲染后的 HTML。Scrapy 可以利用 Splash 的 API 来请求页面并处理 JavaScript 渲染,实现对动态网页的爬取和数据提取。
通过将 Scrapy 和 Splash 结合使用,可以更轻松地处理需要 JavaScript 渲染的页面,并且可以在爬虫中模拟用户操作,如点击按钮或填写表单。这使得对于动态网页的爬取和数据提取变得更加灵活和高效。
Splash 支持以下功能:
异步方式并行处理多个网页的渲染过程。
获取渲染后的 HTML 源代码或屏幕截图。
通过关闭图片渲染或者使用 Adblock 规则来加快页面渲染速度。
可执行特定的 JavaScript 脚本。
可通过 Lua 脚本来控制页面的渲染过程。
获取渲染的详细过程并通过 HAR(HTTP Archive)格式呈现。
Splash: 一个 Javascript 的渲染服务,带有 HTTP API 的轻量级 Web 浏览器。
Docker: 一种容器引擎,Splash 需要在 Docker 中安装和运行。
Scrapy-Splash: 实现 Scrapy 中使用 Splash 的模块。
7.2 环境搭建
安装 Docker
运行 Docker
拉取和开启 Splash:docker pull scrapinghub/splashdocker run -d --name splash -p 8050:8050 scrapinghub/splashdocker run -d --name splash -p 8050:8050 --memory=2G scrapinghub/splash --maxrss 500docker-machine ip default 查看 ip
Scrapy-Splash 的安装pip install scrapy-splash
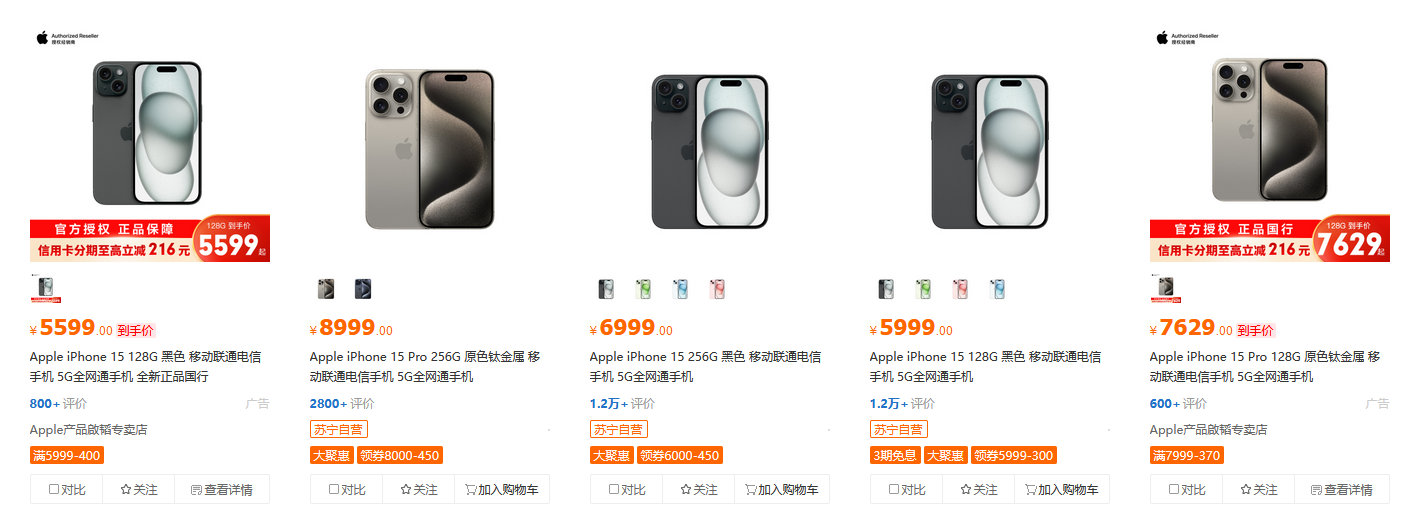
7.3 爬取苏宁易购中的 Iphone 手机信息(利用 Splash 爬取 Js 动态内容) 7.3.1 需求分析 苏宁易购的首页如下图左所示,网址为 苏宁易购(Suning.com)-家电家装成套购,专注服务省心购! 。在页面的搜索栏中输入“iphone”,回车,就会跳转到 iphone 手机的商品销售页面,网址为 https://search.suning.com/iphone/ 如下图右所示。页面默认显示一定条手机信息,将页面往下拉,会不断加载更多手机信息,一页最多有 119 个 ipone 手机的商品信息。本项目希望使用 Splash,将尽量多的 iphone 商品销售信息爬取下来保存于 CSV 文件中。爬取的字段有:商品标题、价格、好评率和店铺名称。
7.3.2 逻辑实现
setting.py 配置 splash 的 spider 中间件和下载中间件:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 "scrapy_splash.SplashDeduplicateArgsMiddleware" : 100 ,"scrapy_splash.SplashCookiesMiddleware" : 723 ,"scrapy_splash.SplashMiddleware" : 725 ,"scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware" : 810 """Splash 设置""" " http://192.168.99.100:8050" "scrapy_splash.SplashAwareFSCacheStorage" "scrapy_splash.SplashAwareDupeFilter"
定义数据结构:
1 2 3 4 5 6 class SuningyigoItem (scrapy.Item):
实现爬取解析逻辑:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 from scrapy import Requestfrom scrapy.spiders import Spiderfrom Suningyigo.items import SuningyigoItemfrom scrapy_splash import SplashRequest""" function main(splash, args) splash:go(args.url) splash:wait(args.wait) splash:runjs('document.getElementById("bottom_pager").scrollIntoView(true)') splash:wait(args.wait) return splash:html() end """ class IphoneSpider (Spider ):'iphone' ' www.suning.com ' ]' https://search.suning.com/iphone/ ' ]1 def start_requests (self ):yield SplashRequest(url=self.start_urls[0 ], callback=self.parse, endpoint='execute' ,args={'wait' : 3 ,'lua_source' : lua_script, 'timeout' : 10 , 'images' : 0 'lua_source' ])def parse (self, response ):'div #product -list > ul > li' )for li in list_selector:try :'price' ] = li.css('div.res-info > div.price-box span::text' ).extract_first()'title' ] = li.css('div.res-info > div.title-selling-point > a::text' ).extract_first().strip()'comment_count' ] = li.css('div.res-info > div.info-evaluate > i::text' ).extract_first()'store_name' ] = li.css('div.res-info > div.store-stock > a::text' ).extract_first()yield itemexcept Exception as e:print (e)continue int (response.css('div #bottom_pager > div > a:nth-last-child(3)::attr(pagenum)' ).extract_first())'div #bottom_pager > div > a #nextPage ::attr(href)' ).extract_first().replace('/iphone/' ,'' )if next_page:1 if self.current_page <= total_page:yield SplashRequest(url=next_page, callback=self.parse, endpoint='execute' ,args={'wait' : 3 ,'lua_source' : lua_script, 'timeout' : 10 , 'images' : 0 'lua_source' ])
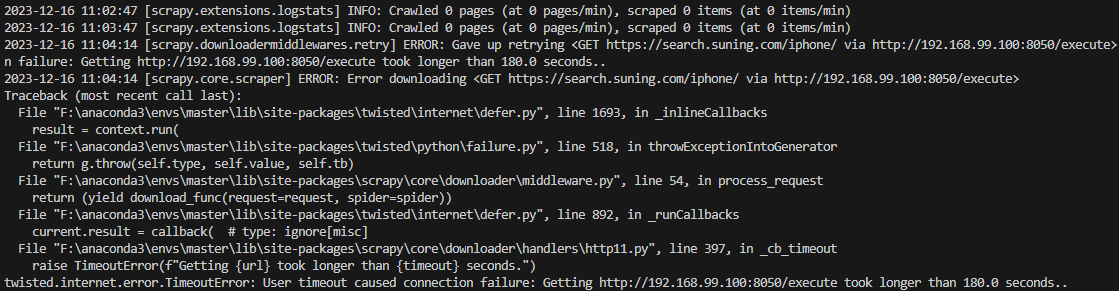
由于 splash 在 scrapy 新版中被弃用,因此出现以下错误,连接 splash 超时,无法进行爬取:
7.4 起点个人书架书籍爬取(携带 Cookie 自动登录) 7.4.1 需求分析 图为登录起点中文网后,“我的书架”页面,地址为: https:/my.qidian.com/bookcase 。书架中罗列了用户加入书架的小说信息,有:类别、书名、更新时间、作者等。本项目的目标就是要将“我的书架”中的所有小说信息爬取下来。字段有:类别、书名、更新时间和作者。
7.4.2 依赖安装
cookie 获取库
1 2 pip install browsercookie
密码加密库
1 2 pip install pycryptodome
7.4.3 逻辑实现
数据结构定义:
1 2 3 4 5 6 class QidianloginItem (scrapy.Item):
spider 爬取解析逻辑实现(核心在于携带 cookie 免除登录,适合可以自动登录的网站 ):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 from typing import Any , Iterable, Optional from scrapy import Requestfrom scrapy.http import Requestfrom scrapy.spiders import Spiderfrom QidianLogin.items import QidianloginItemimport browser_cookie3 as browsercookieclass QidianLoginSpider (Spider ):'bookcase' '.qidian.com' ]' https://my.qidian.com/bookcase ' ]def __init__ (self ):for cookie in cookie_jar:if cookie.domain == '.qidian.com' :if cookie.name in ['_csrfToken' ,'_ga' ,'_ga_FZMMH98S83' ,'_ga_PFYW0QLV3P' ,'_gid' ,'e1' ,'e2' ,'fu' ,'Hm_lpvt_f00f67093ce2f38f215010b699629083' 'Hm_lvt_f00f67093ce2f38f215010b699629083' ,'listStyle' ,'newstatisticUUID' ,'supportwebp' ,'traffic_utm_referer' ,'ywguid' ,'ywkey' ,'ywopenid' ]:def start_requests (self ) -> Iterable[Request]:yield Request(url=self.start_urls[0 ], cookies=self.cookies_dict, callback=self.parse)def parse (self, response ):'table #shelfTable tbody tr' )print (len (tr_selector))for tr in tr_selector:'category' ] = tr.css('td.col2 a.fen-category::text' ).extract_first()'title' ] = tr.css('td.col2 span.shelf-table-name b a:nth-child(2)::text' ).extract_first()'author' ] = tr.css('td.col4 a.shelf-table-author::text' ).extract_first()'update_time' ] = tr.css('td:nth-child(3)::text' ).extract_first()yield item
爬取结果如下 json 文件所示:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 [ { "category" : "「仙侠」" , "title" : "仙父" , "author" : "言归正传" , "update_time" : "7 分钟前" } , { "category" : "「科幻」" , "title" : "说好军转民,这煤气罐什么鬼?" , "author" : "那年回响" , "update_time" : "33 分钟前" } , { "category" : "「玄幻」" , "title" : "宿命之环" , "author" : "爱潜水的乌贼" , "update_time" : "55 分钟前" } , { "category" : "「科幻」" , "title" : "黄昏分界" , "author" : "黑山老鬼" , "update_time" : "1 小时前" } , { "category" : "「都市」" , "title" : "都重生了谁谈恋爱啊" , "author" : "错哪儿了" , "update_time" : "3 小时前" } , { "category" : "「玄幻」" , "title" : "道爷要飞升" , "author" : "裴屠狗" , "update_time" : "4 小时前" } , { "category" : "「历史」" , "title" : "晋末长剑" , "author" : "孤独麦客" , "update_time" : "5 小时前" } , { "category" : "「都市」" , "title" : "逼我重生是吧" , "author" : "幼儿园一把手" , "update_time" : "12 小时前" } , { "category" : "「轻小说」" , "title" : "我的超能力每周刷新" , "author" : "一片雪饼" , "update_time" : "13 小时前" } , { "category" : "「轻小说」" , "title" : "不许没收我的人籍" , "author" : "可怜的夕夕" , "update_time" : "16 小时前" } ]
8 反爬虫反制措施 8.1 降低请求频率 降低请求频率的做法,不仅仅是为了避开网站的侦测,更重要的是体现出了一个爬虫专家基本的素质。我们应该对能够获取免费数据心怀感恩,而不是恶意攻击网站,致其带来很大的带宽压力,甚至瘫痪。毕竟还是有许多网站,对爬虫还是比较宽容的。DOWNLOAD DELAY=3 #设置下载延迟时间为3秒
8.2 修改请求头 网站可能会对 HTTP 请求头的每个属性做“是否具有人性”的检查。
属性
内容
Hostwww.baidu.com
ConnectionKeep-Alive
Accepttext/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,/ ;q=0.8
User-AgentMozilla/5.0 (Windows NT 10.0; Win64; x64; rv:120.0) Gecko/20100101 Firefox/120.0
Accept-Encodinggzip, deflate, br
Accept-Languagezh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2
8.3 禁用 Cookie 有些网站会通过 Cookie 来发现爬虫的轨迹。网站会通过 Cookie 跟踪你的访问过程,如果发现了爬虫异常行为就会中断你的访问,比如极为快速地填写表单,或者浏览大量页面。虽然这些行为可以通过关闭并重新连接或者改变 IP 地址来伪装,但是如果 Cookie 暴露了你的身份,再多努力也是白费。因此,如果不是特殊需要(如需要保持持续登录的状态,Cookie 还是需要的),可以禁用 Cookie,这样网站就无法通过 Cookie 来侦测到爬虫了。Scrapy 中禁止 Cookie 功能也非常简单,在配置文件 settings.py 中将 COOKIES_ENABLED 设置为 False 即可(默认是 True),如下代码所示:
1 2 Disable cookies (enabled by default)False
8.4 伪装成随机浏览器 前面我们都是通过 User-Agent 将爬虫伪装成固定浏览器,但是对于警觉性高的网站,会侦测到这一反常现象,即持续访问网站的是同一种浏览器。因此,每次请求时,可以随机伪装成不同类型的浏览器。Scrapy 中的中间件 UserAgentMiddleware 就是专门用于设置 User-Agent 的。
手动指定 user-agent 池 :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36" ,"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36 OPR/52.0.2871.407" ,"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36 Edg/58.0.2987.100" ,"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36 Vivaldi/1.11.1117.40" ,"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36 YaBrowser/18.10.2.1100 Yowser/2.5 Safari/537.36" ,"QiDianNovel.middlewares.QidiannovelUserAgentMiddleware" : 543 ,from scrapy.downloadermiddlewares.useragent import UserAgentMiddlewareimport random from QiDianNovel.settings import My_USER_AGENTclass QidiannovelUserAgentMiddleware (UserAgentMiddleware ):def process_request (self, request, spider ):list (My_USER_AGENT))print ("user-agent:" ,agent)"User_Agent" ,agent)
使用随机生成 user-agent 的库 :
fake-useragent :该库提供了一个 UserAgent 类,可以生成随机的 user-agent。
fake-useragent 库的使用方法如下:
1 2 3 4 5 6 7 from scrapy.downloadermiddlewares.useragent import UserAgentMiddlewarefrom fake_useragent import UserAgentclass QidiannovelUserAgentMiddleware (UserAgentMiddleware ):def process_request (self, request, spider ):print ("user-agent:" ,agent)"User_Agent" ,agent)
fake-useragent 会随机给出一个 user-agent:Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.84 Safari/537.36
8.5 更换 IP 地址 建立网络爬虫的第一原则是:所有信息都可以伪造。你可以使用非本人的邮箱发送邮件,通过命令自动化控制鼠标的行为,或者通过某个浏览器耗费网站流量来吓唬网管。但是有一件事是不能作假的,那就是你的 IP 地址。封杀 IP 地址这种行为,也许是网站的最后一步棋,不过有效。为了避免 IP 地址被封杀的方法:HTTP 代理。
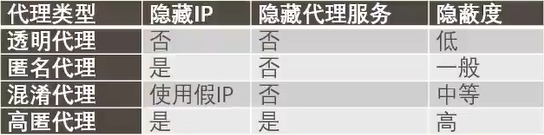
ip 代理服务器分类:
8.5.1 代理中间件(只需要设置代理地址即可)
安装依赖库:
1 pip install scrapy-user-agents scrapy-rotating-proxies
获取 HTTP 代理地址和端口号:
配置 Scrapy 设置
添加 DOWNLOADER_MIDDLEWARES 代理中间件:
1 2 3 4 5 6 DOWNLOADER_MIDDLEWARES = {"scrapy.contrib.downloaderniddleware.useragent.UserAgentMiddleware" : None ,"scrapy_user_agents.middlewares.RandomUserAgentHiddleware" : 400 ,"scrapy_rotating_proxies.middlewares.RotatingProxyMiddleware" : 610 ,"scrapy_rotating_proxies.mdddlewares.BanDetectionMiddleware" : 628.
添加 ROTATING_PROXY_LIST,并将其值设置为你的 HTTP 代理地址和端口号的列表
1 2 3 4 5 """代理 IP 池""" " http://123.456.789.123:8888" ," http://456.789.123.456:8888" ,
spider 爬取解析类应用代理,继承 RotatingProxyMixin 类
1 2 3 4 from scrapy.spiders import CrawlerSpiderfrom scrapy_rotating_proxies import RotatingProxyMixinclass QidianNovelSpider (RotatingProxyMixin,CrawlerSpider):
8.5.2 免费代理获取 爬取站大爷站点的免费 ip 代理:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 from typing import Any , Optional from scrapy import Requestfrom scrapy.spiders import Spiderfrom QiDianNovel.items import PDYProxyItemclass QidianNovelSpider (Spider ):"pdyproxy" " www.zdaye.com" ] " https://www.zdaye.com/free/" ] 1 def __init__ (self, url=" https://www.qidian.com/" ):def start_requests (self ):for url in self.start_urls:yield Request(url=url, callback=self.parse, dont_filter=True )def parse (self, response ): """获取免费代理 ip 列表""" 'table #ipc tbody tr' )for one_selector in list_selector:try :'ip' ] = one_selector.css('td:nth-child(1)::text' ).extract_first().strip()'port' ] = one_selector.css('td:nth-child(2)::text' ).extract_first().strip()'response_time' ] = one_selector.css('td:nth-last-child(2) span::text' ).extract_first().strip()'last_checked' ] = one_selector.css('td:nth-child(5)::text' ).extract_first().strip()"({}://{}:{}" .format ("http" ,item['ip' ],item['port' ])"url" ]=urlyield Request(url=self.test_url,callback=self.test_proxy,"proxy" :url,"dont_retry" :True ,"download_timeout" :10 ,"item" :item},True )except Exception as e:print (e)continue """爬取前十页数据""" if self.current_page < 10 :1 'a[title="下一页"]::attr(href)' ).extract_first()yield Request(url=next_page_url, callback=self.parse)def test_proxy (self,response ): """测试代理 ip""" print (response.meta["item" ]["url" ])yield response.meta["item" ]def error_back (self,failure ):"""错误处理""" repr (failure)))
8.5.3 静态代理(指定 Ip Pool 写死) scrapy 使用静态代理 ip
在 Scrapy 中使用静态代理 IP,可以通过在 middlewares 中添加一个 IP 代理中间件来实现。以下是一个简单的示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 class ProxyMiddleware (object ):def __init__ (self, proxy_list ): @classmethod def from_crawler (cls, crawler ):return cls('PROXY_LIST' )def process_request (self, request, spider ):'proxy' ] = f'http://{proxy} '
在 settings.py 文件中添加以下配置:
1 2 3 4 5 6 7 8 9 10 11 'myproject.middlewares.ProxyMiddleware' : 543 ,'ip1:port1' ,'ip2:port2' ,
这样当 Scrapy 发送请求时,会随机选择一个静态代理 IP 来发起请求。注意需要确保你拥有合法的静态代理 IP,并且能够成功连接到目标网站。
8.5.4 动态代理(从代理池数据库中获取代理) 代理地址存储于 redis 数据库中,数据类型为 set 集合,每一条数据类似: http://xxx.xxx.xxx.xxx:port
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 import scrapyfrom scrapy.spiders import Spiderfrom QiDianNovel.items import QidiannovelItemimport jsonimport redisfrom QiDianNovel import settingsclass QidianNovelSpider (Spider ):"qidian_novel_getProxy_byRedis" " www.qidian.com" ] " https://www.qidian.com/rank/yuepiao/year2023-month12-page1/" ] 1 def get_proxy (self ):""" 获取代理 ip :return: """ "proxy_pool" ) print ("proxy:" ,proxy)return proxydef close_redis (self ):""" 爬虫结束时关闭 redis 连接 :param spider: :return: """ def __init__ (self, *args, **kwargs ):if myredis:"REDIS_HOST" ,"localhost" )"REDIS_PORT" ,6379 )"REDIS_PASSWORD" ,"123456" )"REDIS_DB" ,1 )True )def errback (self, failure ):""" 错误回调函数 :param failure: :return: """ repr (failure))print ("当前正在访问的请求:" +request.url,repr (failure))"proxy_pool" ,request.meta["proxy" ])yield scrapy.Request(url=request.url, callback=self.parse, errback=self.errback, meta={"proxy" :self.get_proxy(),"dont_retry" :True ,"download_timeout" :10 },True )def start_requests (self ):print ("""--------------------开始爬取小说信息-------------------- ██ ██ ██ ██ ████████ ██ ██ ░██ ░██ ░██ ░██ ██░░░░░░ ██████ ░░ ░██ ░██ ░██ █████ ░██ ░██ ██████ ░██ ░██░░░██ ██ ░██ █████ ██████ ░██████████ ██░░░██ ░██ ░██ ██░░░░██░█████████░██ ░██░██ ██████ ██░░░██░░██░░█ ░██░░░░░░██░███████ ░██ ░██░██ ░██░░░░░░░░██░██████ ░██ ██░░░██░███████ ░██ ░ ░██ ░██░██░░░░ ░██ ░██░██ ░██ ░██░██░░░ ░██░██ ░██░██░░░░ ░██ ░██ ░██░░██████ ███ ███░░██████ ████████ ░██ ░██░░██████░░██████░███ ░░ ░░ ░░░░░░ ░░░ ░░░ ░░░░░░ ░░░░░░░░ ░░ ░░ ░░░░░░ ░░░░░░ ░░░ """ )yield scrapy.Request(url=self.start_urls[0 ], callback=self.parse, errback=self.errback , meta={"proxy" :self.get_proxy(),"dont_retry" :True ,"download_timeout" :10 },True )def parse (self, response ): """获取小说信息列表""" print ("""--------------------开始解析小说信息-------------------- //\\ .. //\\ //\(( ))/\\ / < `' > \\ \ / \ / \/ \/ """ )print ("response:" ,response.text)'div[class="book-mid-info"]' )print ("list_selector:" ,list_selector)for one_selector in list_selector:"""获取小说标题、作者、分类、状态、摘要""" 'h2 a::text' ).extract_first()'p.author > a::text' ).extract_first()'p.author > a::text' ).extract()[1 ]'p.author > span::text' ).extract_first()'p.intro::text' ).extract_first()'title' ] = title'author' ] = author'category' ] = category'status' ] = status'abstract' ] = abstractyield item"""爬取月票榜前十页数据""" if self.current_page < 10 :1 0 ].replace('page1' , 'page%d' % self.current_page)yield scrapy.Request(url=next_page_url, callback=self.parse,errback=self.errback , meta={"proxy" :self.get_proxy(),"dont_retry" :True ,"download_timeout" :10 },True )
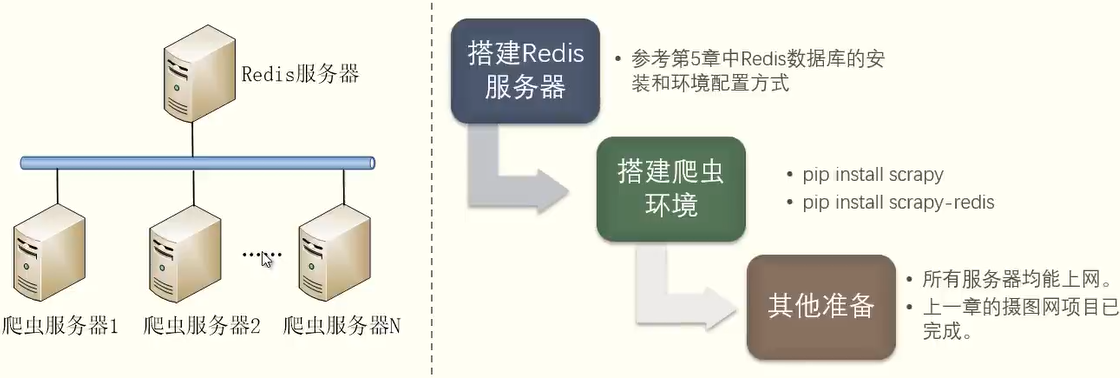
9 分布式爬虫 9.1 Scrapy-Redis 实现分布式爬虫 9.1.1 分布式爬虫爬取彼岸图网图片 9.1.1.1 需求分析 上一章我们实现了彼岸图网图片的下载,但是由于下载的图片量较大,单机独立执行的效率就会比较低。因此需要将其改造为分布式爬虫,实现多机联合,共同完成图片下载任务。
9.1.1.2 方案设计
9.1.1.3 逻辑实现 修改原项目部分代码即可实现分布式多机对协作执行同一爬虫任务。
全局配置文件
1 2 3 4 5 6 7 8 9 10 "scrapy_redis.scheduler.Scheduler" "scrapy_redis.dupefilter.RFPDupeFilter" "redis://8.130.88.159:6379/" "scrapy_redis.pipelines.RedisPipeline" : 200 ,"BianImage.pipelines.SaveImagePipeline" : 300 ,
爬取解析逻辑取消 start_requests 方法(从 redis 中获取起始请求 )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 from scrapy import Spider,Requestfrom BianImage.items import BianimageItemfrom scrapy_redis.spiders import RedisSpiderimport reclass ImageSpider (RedisSpider ):'bianimage' 1 def parse (self, response ): 'div.classify.clearfix a' )for subject in subjects:'::attr(href)' ).extract_first()'::text' ).extract_first()yield Request(subject_url, callback=self.parse_image,meta={'subject_name' :subject_name})def parse_image (self, response ): 'image_urls' ] = []'subject' ] = response.meta['subject_name' ]'div.slist ul li:not(.nextpage)' )for image in image_li:'a img::attr(src)' ).extract_first()'image_urls' ].append(image_url)yield item'div.page a:nth-last-child(1)::attr(href)' ).extract_first()'div.page a:nth-last-child(2)::text' ).extract_first()1 if next_url and total_page and self.current_page <= 5 :yield Request(next_url, callback=self.parse_image,meta={'subject_name' :item['subject' ]})
在 redis 中添加起始请求信息(键名为 bianimage:start_urls 的列表,先 lpush bianimage:start_urls 123 后在修改 123 为以下 json 字符串信息—> LPUSH "bianimage:start_urls" "{\"url\":\"https://pic.netbian.com\",\"meta\":{\"job-id\":\"123img\",\"start-date\":\"dd/mm/yy\"}}")
1 2 3 4 5 6 7 { "url" : "https://pic.netbian.com" , "meta" : { "job-id" : "123img" , "start-date" : "dd/mm/yy" } }
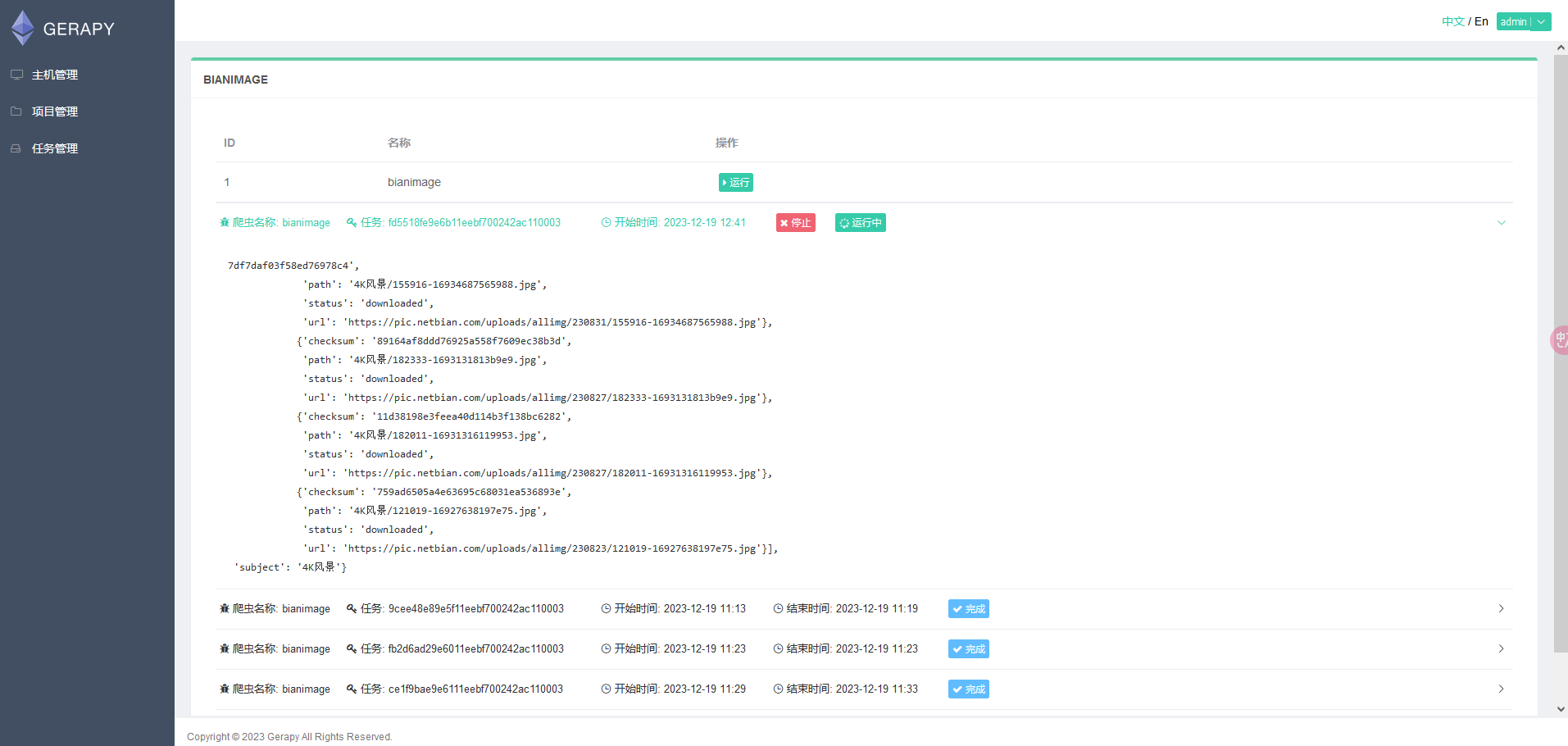
每次启动爬虫后,bianimage:start_urls 键将会被消费掉不复存在,新增 bianimage:items 和 bianimage:duplicate 键记录条目和重复信息。
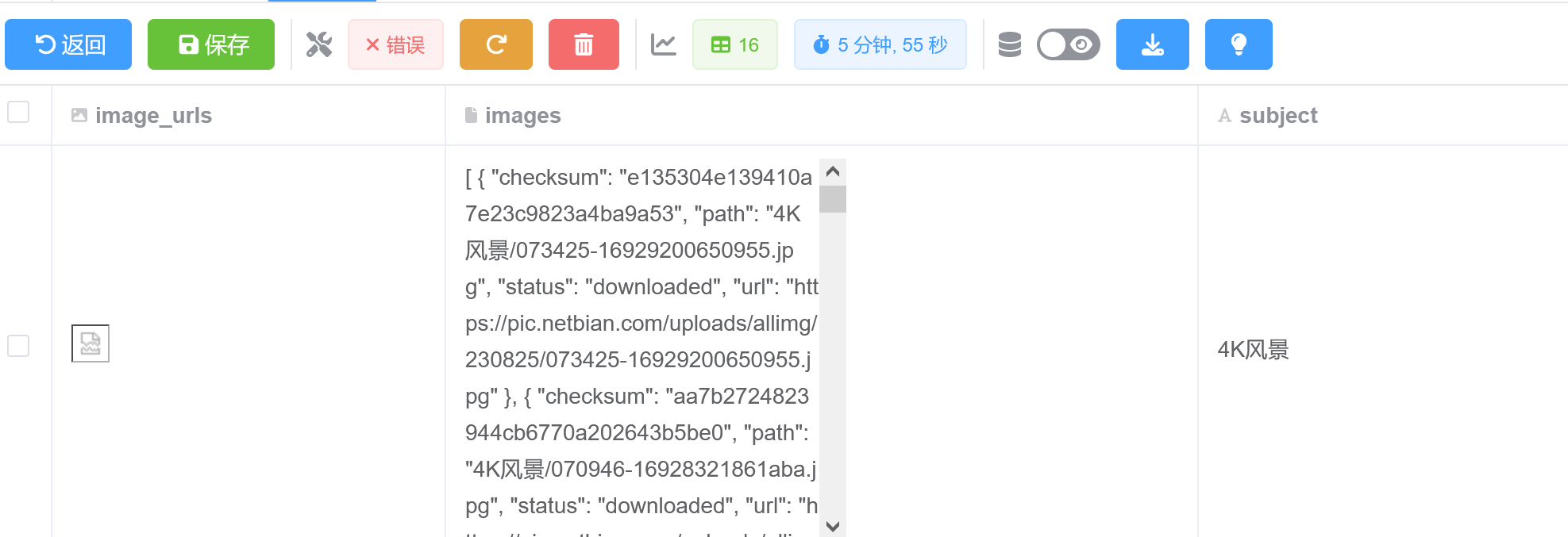
本地爬取结果,缺少部分分类,且已有分类不全 :
云端爬取结果 :
9.2 使用 Scrapyd 部署分布式爬虫 Scrapyd 是一个部署和管理 Scrapy 爬虫的工具,它可以通过一系列 HTTP 接口实现远程部署、启动、停止和删除爬虫程序。Scrapyd 还可以管理多个爬虫项目,每个项目可以上传多个版本,但只执行最新版。http://localhost:6800
9.2.1 Scrapyd 的安装及运行
准备工作
Anaconda
Scrapy
Scrapy-Redis
安装 Scrapyd
配置文件C:\scrapyd\ 中新建一个配置文件 scrapyd.conf。Scrapyd 在运行时会读取此路径下的配置文件,但 Scrapyd 不会自动生成 scrapyd.conf 文件,需要手动生成并添加内容。配置件的内容可以从官方文档(地址为 https://scrapyd.readthedocs..io/en/stable/config.html#config-example )中拷贝下来,再做简单的修改即可。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 [scrapyd]
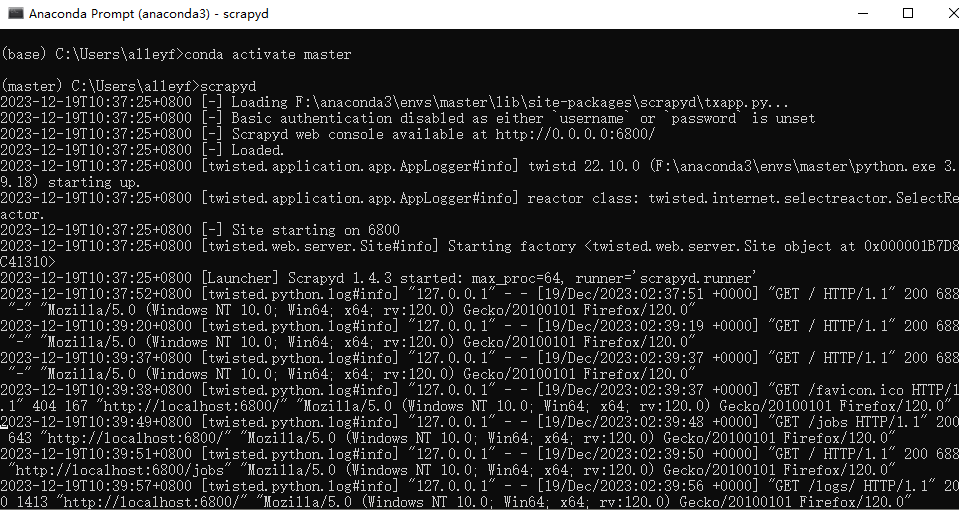
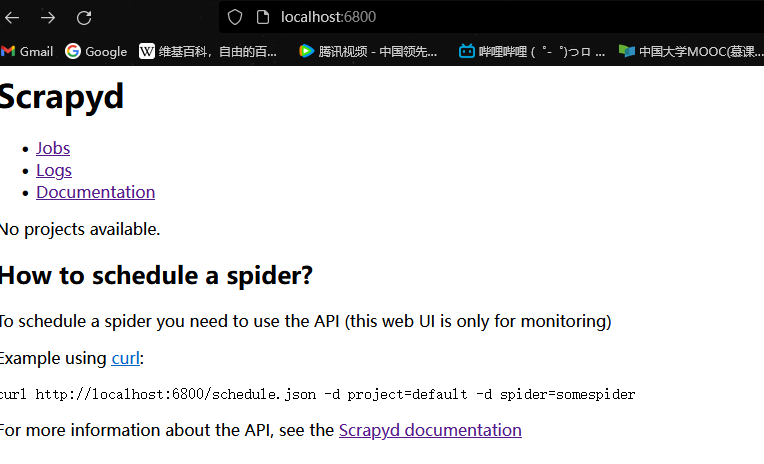
启动 Scrapyd 服务scrapyd,如果访问 http://localhost:6800 出现如下所示信息,说明 Scrapyd 服务启动成功。
9.2.2 Scrapyd 功能介绍
addversion.json:上传 Scrapy 项目或者更新项目版本到爬虫服务器
daemonstatus.json:查看 Scrapyd 当前的服务和任务状态
schedule.json:调度一个爬虫项目的运行
cancel.json:取消爬虫任务
listprojects..json:获取部署到 Scrapyd,服务上的项目列表
listversions.json:获取某个项目的版本号列表
listspiders.json:获取某项目最新版中所有 Spider 名称列表
listjobs.json:获取某个正在等待、运行或运行完的任务列表
delversion.json:删除某个项目的某个版本
delproject.json:删除指定项目
9.2.3 使用 Scrapyd-Clinet 批量部署 Scrapyd-Client 的功能主要有两个:
将项目打包成 egg 文件。
将 egg 文件通过 Scrapyd 的 addversion.json 接口上传到目标服务器。
安装 Scrapyd-Client
1 2 3 pip install scrapyd-client
推送项目到 scrapyd 中scrapy.cfg 文件配置推送目标地址:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 [settings]6800 /192.168 .0 .108 :6800 /192.168 .0 .107 :6800 /
在 anaconda 的 master 环境下在启动 scrapyd 后切换到爬虫项目根目录 下执行以下命令:
1 2 scrapyd-deploy
启动爬虫项目
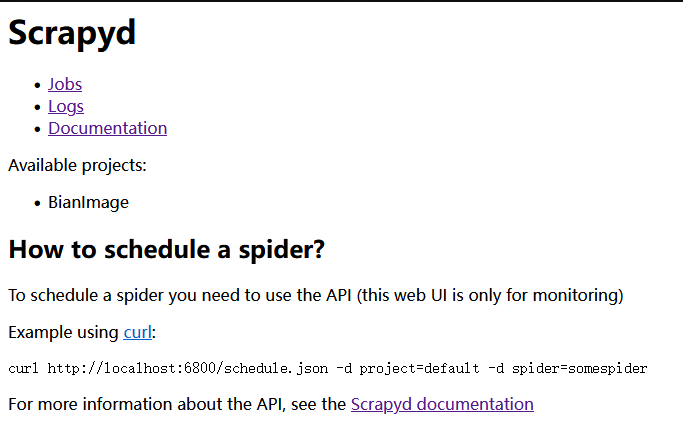
1 curl http://127.0.0.1:6800/schedule.json -d project=BianImage -d spider=bianimage
执行命令后返回如下结果则表明启动成功:{"node_name": "Alleyf", "status": "ok", "jobid": "2b7fa8179e4111ee8991004238aafa7c"}
9.3 使用 Docker 部署分布式爬虫 9.3.1 问题
环境搭建问题:每台服务器的系统环境各不相同,在配置 Python 和 Scrpayd 环境时,难免会遇到各种兼容性和版本冲突的问题。
服务启动问题:Scrapyd 服务需要手动启动,一旦目标服务器将其关闭,需要登录服务器,重新启动。
9.3.2 Docker Docker 提供了一个公共的容器镜像存储库 Docker Hub,它包含了上百万个容器镜像,用户可以免费访问和共享这些公共镜像,也可以发布自己的镜像。我们可以通过 docker pull 命令,从 Docker Hub 中下载了公共的镜像 splash,然后就可以直接启动 Splash 服务了。Docker Hub 的网址为 https:/hub.docker.com/ ,如图所示。
9.3.3 制作自己的 Docker 容器镜像 制作容器镜像,需要用到三个文件,并且这三个文件都要处于同一个文件夹中。
scrapyd.conf
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 [scrapyd]
requirements.txt 文件(文件名可以自定义)pip install pipreqs 使用 pipreqs . --encoding=utf8 --force 命令一键生成项目依赖文件,但是不一定全还需要自己补充修改。
1 2 3 4 5 6 7 scrapyd
Dockerfile:新建文件 Dockerfile(注意,文件名没有后缀)。
1 2 3 4 5 6 7 8 FROM python:3.9 .8 ADD . /code WORKDIR /code COPY ./scrapyd.conf /etc/scrapyd/ EXPOSE 6800 RUN pip3 config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple RUN pip3 install -r requirements.txt CMD scrapyd
也可以用其他 pip 安装源(eg 豆瓣源: http://pypi.douban.com/simple )
参数说明
FROM: 定义了将会被使用的基础镜像,在开始编写 Dockerfile 前必须先指定。 MAINTAINER:定义了镜像创建者的信息。 RUN:在新创建的镜像层上执行命令,用于安装应用程序及其相关依赖。你可以使用多个 RUN 命令,Docker 会创建相应的镜像层。 CMD:为启动的容器指定默认要运行的程序,包括相关参数。 EXPOSE: 通知 Docker 服务端应该监听与运行该应用程序相关的网络端口。 ENV: 定义了将在镜像构建过程中被使用的环境变量。 ADD 和 COPY: 将文件从 Docker 宿主机复制/添加到镜像中。 ADD 具有处理在线 URL 和解压 tar 文件的功能。 ENTRYPOINT: 用于指定容器启动的程序及参数。 VOLUME: 是用来为镜像提供持久化数据功能,可以在容器间共享数据。 WORKDIR: 在镜像内设定一个工作目录,所有后续的操作(CMD、RUN、ENTRYPOINT、COPY、ADD)都会在该目录下进行。 以上是 Dockerfile 的主要使用参数,每一个参数对应的都是 Docker 镜像构建时的一个动作,多个参数能组合起来用于创建自定义 Docker 镜像。
1 2 docker build -t alleyf/scrapyd:0.0.1 .
首先在命令行执行以下命令登录 dockerhub 验证身份
1 docker login -u "username" -p "password" docker.io
1 docker push alleyf/scrapyd:0.0.1
9.3.4 拉取运行镜像 我们将自己制作的 Scrapyd 镜像上传到了 Docker Hub 中后,任何人都可以将该镜像拉取到本地,启用 Scrapyd 服务了。
1 docker pull alleyf/scrapyd:0.0.1
拉取镜像后执行以下命令启动容器:
1 docker run -d --name scrapyd -p 6800:6800 alleyf/scrapyd:0.0.1
启动容器后打开服务器安全组端口,访问 6800 端口即可看到以下页面:
9.3.5 推送运行 Scrapy 爬虫 修改配置文件 scrapy.cfg 设置推送目标地址等信息:
1 2 3 4 5 6 7 8 9 10 11 12 [settings]6800 /6800 /
然后在本地执行以下命令将爬虫项目推送到 docker 容器所在的云端环境中:
接着执行以下命令启动云端刚刚推送的爬虫项目:
1 curl http://xxxx:6800/schedule.json -d project=BianImage -d spider=bianimage
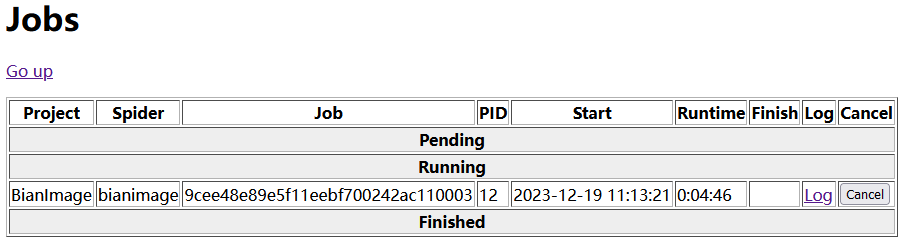
运行成功后在 6800 端口 Jobs 中可以看到正在运行的爬虫项目:
docker 启动容器实例后,容器实例就相当于一个基础的 linux 环境,并且包含了 docker 镜像打包时添加的文件 ,具体如下图所示:
scrapy v2.10.0 不再支持将蜘蛛参数传递给 scrapy.core.engine.ExecutionEngine 的 crawl()方法。也就是说新版本将不在支持启动 scrapy-redis 爬虫后再向 redis 中添加初始请求信息,必须项目启动前添加,或者 scrapy 降级到 2.9.0 版本
9.4 使用 Gerapy 管理分布式爬虫 9.4.1 问题
制作 Python 和 Scrapyd 环境的 Docker 镜像,上传到 Docker Hub 中。
所有爬虫服务器中安装 Docker,并从 Docker Hub 中拉取镜像,启动 Scrapyd 服务。
使用 Scrapyd-Client 命令将 Scrpay:项目部署到爬虫服务器中。
使用 Scrapyd 命令管理爬虫,如启动、停止、删除爬虫,管理版本,查看日志等。
9.4.2 Gerapy 介绍 Gerapy 是一款分布式爬虫管理框架,支持 Python3,基于 Scrapy、Scrapyd、Scrapyd-Client、Scrapy-Redis、Scrapyd-APl、Scrapy-Splash、Jinjia2、Django、Vue.js 开发。
9.4.3 Gerapy 使用方法
安装 Gerapy
初始化 GerapyE:\gerapy;然后,执行初始化命令,如下所示:
生成的目录结构如下:
1 2 3 E:\gerapy
初始化数据库E:\gerapy 目录下,执行初始化数据库的命令,如下所示:
1 2 cd gerapy
创建管理员用户admin
1 2 gerapy initadmin
启动 Gerapy 服务
在浏览器中访问 http:/127.0.0.1:8000(或 http:/localhost:8000),就可以访问 Gerapy 管理界面了。
9.4.4 项目部署
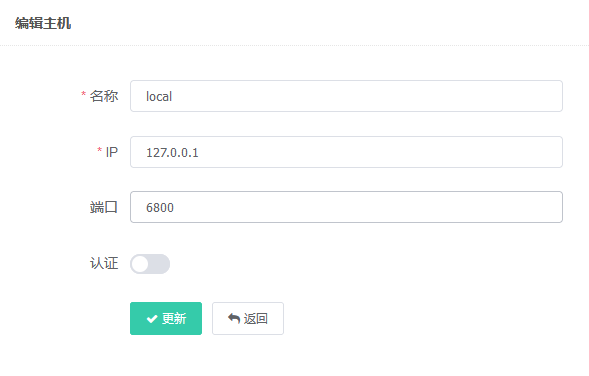
主机管理
项目管理gerpy/projects/ 目录下刷新即可看到项目,也可以通过上传文件的方式添加爬虫项目。
启动项目
10 抢票 10.1 需求分析 每到春节,相信大家最关注的莫过于如何抢到一张回家的火车票。以前,大家只能从黄牛手中高价购买,随着技术的发展,加上巨大的需求和利益驱动,近几年各种抢票软件便应运而生。由于抢票软件具有速度快、持续不间断、无人值守等优势,迅速成为大家抢票的神器。但是使用第三方提供的抢票软件也有诸多问题,如:个人账号有泄露风险(需要提供 12306 账号),所谓的加速包要收费等。既然这样,我们何不开发出款属于自己的抢票软件呢?
10.2 技术分析
自动登录
借助于打码平台。但打码平台不仅收费,而且很多都是人工识别的。
借助于深度学习算法。但实现难度大,识别准确率低,且超出了本书的知识范畴。
自动发邮件
yagmaill 库安装成功后,就可以实现邮件发送功能了,主要有以下两个步骤。
1 2 import yagmail"user@163.com" ,password="1234" ,host='smtp.163.com' )
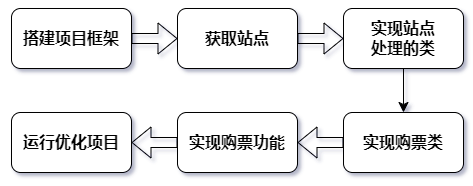
10.3 项目实现
环境准备
Anaconda:Python 开发环境。
Scrapy:Scrapy 爬虫框架。
Selenium:自动化测试工具。
yagmail:邮件发送模块。
新建 Scrapy 项目
1 scrapy startproject tickets
配置 settings.py 选项。
设置 robots 协议:ROBOTSTXT_OBEY 为 False
设置用户代理:USER AGENT
启用下载器中间件:TicketsDownloaderMiddleware
获取站点信息
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 from scrapy import Requestfrom scrapy.spiders import Spiderimport re,osclass SitesSpider (Spider ):'sites' def start_requests (self ):'https://kyfw.12306.cn/otn/resources/js/framework/station_name.js?station_version=1.9286' yield Request(url=url, callback=self.parse)def parse (self, response ):"""使用正则表达式获取站点名和站点代码""" r'[\u4e00-\u9fa5]+\|[A-Z]+' , response.text)if (os.path.exists('sites.txt' )):'sites.txt' )with open ('sites.txt' , 'a' , encoding='utf-8' ) as f:for site in sites:'|' )":" + site_code + '\n' )
实现站点处理类
从文件中获取站点信息。
判断站点是否存在。
根据站点名获取站点编号。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 import osclass SiteCode :def __init__ (self ):def get_sites_from_file (self ):"""获取站点名和站点编码加载到站点字典中""" if not os.path.exists('sites.txt' ):print ('sites.txt文件不存在' )return with open ('sites.txt' ,'r' ,encoding='utf-8' ) as f:for line in f.readlines():if line:':' )def is_exist (self,site_name ):"""判断站点名是否存在""" return site_name in self.sitesdef name2code (self,site_name ):"""根据站点名获取站点编码""" return self.sites[site_name]
实现购票类
读取用户购票信息。
通过 Chrome:浏览器访问 12306 的登录页面。
查询车票信息。
获取购买车票的详细信息。
选择乘客和席别。
核对预定的车票。
发送邮件。
保持登录状态。
利用 selenium 自动填充用户名和密码进行登录,但是由于设置了反爬虫措施需要获取手机验证码登录,因此手动登录。
1 2 3 4 5 6 7 8 9 10 try :10 ).until(EC.presence_of_element_located((By.ID, "J-userName" )))"J-userName" )"J-password" )0 ])1 ])"login_button" )except TimeoutException:print ("登录超时" )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 from selenium import webdriverfrom selenium.webdriver.common.by import Byfrom selenium.webdriver.support.ui import WebDriverWaitfrom selenium.webdriver.support import expected_conditions as ECfrom selenium.common.exceptions import TimeoutExceptionfrom selenium.webdriver.support.select import Selectfrom SiteCode import SiteCode import yagmailimport timeclass Tickets (object ):def __init__ (self ):def read_tickets_from_file (self ):with open ('buy_tickets.txt' ,'r' ,encoding='utf-8' ) as f:for line in f.readlines():"\n" ))def login (self ):"https://kyfw.12306.cn/otn/resources/login.html" )try :100 ).until(EC.url_to_be("https://kyfw.12306.cn/otn/view/index.html" ))except TimeoutException:print ("登录超时" )return False return True def query_tickets (self,flag=0 ):if flag == 0 : "https://kyfw.12306.cn/otn/leftTicket/init" )try :10 ).until(EC.presence_of_element_located((By.ID,"fromStationText" )))0 ])0 ])"document.getElementById(\"fromStation\").value=\"" +site_code+"\";" 1 )10 ).until(EC.presence_of_element_located((By.ID,"toStationText" )))1 ])1 ])"document.getElementById(\"toStation\").value=\"" +site_code+"\";" 10 ).until(EC.presence_of_element_located((By.ID,"train_date" )))"document.getElementById(\"train_date\").value=\"" +self.tickets_info[2 ]+"\";" except TimeoutException:print ("设置超时" )return False try :10 ).until(EC.element_to_be_clickable((By.ID,"query_ticket" )))"query_ticket" ).click()10 ).until(EC.presence_of_element_located((By.XPATH,"//tbody[@id='queryLeftTable']/tr" )))except TimeoutException:print ("查询超时" )return False return True def get_ticket (self ):".//tbody[@id='queryLeftTable']/tr[not(@datatran)]" )for tr in tr_list:"number" ).textif train_number == self.tickets_info[3 ]:if self.tickets_info[4 ] in ["一等座" ]:".//td[3]" ).textelif self.tickets_info[4 ] in ["二等座" ,"二等包座" ]:".//td[4]" ).textelif self.tickets_info[4 ] in ["硬卧" ,"二等卧" ]:".//td[8]" ).textelif self.tickets_info[4 ] in ["硬座" ]:".//td[10]" ).textelse :return -1 if left_seat == "--" :return -1 if left_seat == "有" or left_seat.isdigit():"btn72" )if orderButton.is_enabled():return 1 else :3 )return -2 else :3 )return -2 return -3 def order_ticket (self ):try :100 ).until(EC.url_to_be("https://kyfw.12306.cn/otn/confirmPassenger/initDc" ))100 ).until(EC.presence_of_element_located((By.XPATH,".//ul[@id='normal_passenger_id']/li" )))except TimeoutException:print ("预定超时" )return False ".//ul[@id='normal_passenger_id']/li/label" )5 ].split("," )0 for passenger in passenger_list:if name in order_passenger_list:1 else :"乘客信息不存在" )return False "商务座" :'9' ,"特等座" :'P' ,"一等座" :'M' ,"二等座" :'O' ,"高级软卧" :'6' ,"软卧" :'4' ,"硬卧" :'3' ,"软座" :'2' ,"硬座" :'1' ,"无座" :'1' ,for i in range (1 ,amount+1 ):id ="seatType_%d" %i4 ]]id )).select_by_value(value)"submitOrder_id" )return True def confirm_dialog (self ):try :10 ).until(EC.presence_of_element_located((By.ID,'qr_submit_id' )))5 )'qr_submit_id' )if ConButton.is_displayed():return True else :return False except TimeoutException:return False def send_mail (self ):try :100 ).until(EC.presence_of_element_located((By.CLASS_NAME,"i-lock" )))'alleyf@qq.com' ,"" ,'qq.mail.com' ,"465" )"亲,抢票成功,请在半个小时之内前往支付!" 6 ],"12306购票成功通知" ,except TimeoutException:print ("邮件发送失败" )return False return True def keep_loading (self ):try :'login_user' )except :pass def show_message (self,msg ):"alert(\"" +msg+"\");" )def site_is_exist (self ):if False ==self.sites.is_exist(self.tickets_info[0 ]):return -1 if False ==self.sites.is_exist(self.tickets_info[1 ]):return -2 return 0 def student_dialog (self ):try :3 ).until(EC.presence_of_element_located((By.ID,'dialog_xsertcj_ok' )))'dialog_xsertcj_ok' )except :pass
实现购票功能
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 from typing import Iterablefrom scrapy import Spider,Requestfrom scrapy.http import Requestclass TicketsSpider (Spider ):'tickets' def start_requests (self ) -> Iterable[Request]:'https://kyfw.12306.cn/otn/resources/login.html' yield Request(url=url, callback=self.parse)def parse (self, response ):pass
实现抢票功能:下载器中间件源文件 middlewares.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 from selenium.webdriver.common.by import Byfrom selenium.webdriver.support.wait import WebDriverWaitfrom selenium.webdriver.support import expected_conditions as ECimport timefrom tickets.Tickets import Ticketsclass TicketsDownloaderMiddleware :def process_request (self, request, spider ):if spider.name == "tickets" :0 0 if self.tickets.site_is_exist()==-1 :"出发地的站点不存在" )elif self.tickets.site_is_exist()==-2 :"目的地的站点不存在" )if self.tickets.login():while True :1 if self.tickets.query_tickets(flag):if ticket_info == -1 :"坐席不存在" )break elif ticket_info == -2 :"暂时无票,重新刷新获取票务信息" )1 if count%100 ==0 :0 "已刷新" +str (count)+"次" )elif ticket_info == -3 :"预定的车次不存在" )else :if self.tickets.order_ticket():"预定成功" )if self.tickets.confirm_dialog():if self.tickets.send_email():"邮件发送成功" )break else :"邮件发送失败" )0 else :0 else :"登录超时" )5 )return None
优化项目
选座功能
特殊情况
暂不办理业务:离开车时间不足半小时,会暂停办理购票业务。
有未处理的订单:只要有未处理的订单,就无法再办理购票业务。
取消次数过多:车票取消操作一天最多三次,否则当天无法在办理购票业务
11 参考
Scrapy框架介绍-CSDN博客 预览Scrapy — Scrapy 文档 Python爬虫⚡Python基础→项目实战案例:Scrapy框架、分布式爬虫、数据爬取与项目案例使用教程_哔哩哔哩_bilibili 小说月票排行榜单_2023年12月起点小说月票排行-起点中文网 傻瓜式教程超详细Scrapy设置代理方法-腾讯云开发者社区-腾讯云