本文最后更新于:2 个月前
微服务基础
通过使用SpringBoot框架,我们的项目开发速度可以说是得到了质的提升。同时,我们对于项目的维护和理解,也会更加的轻松。可见,SpringBoot为我们的开发带来了巨大便捷。而这一部分,我们将基于SpringBoot,继续深入到企业实际场景,探讨微服务架构下的SpringCloud。这个部分我们会更加注重于架构设计上的讲解,弱化实现原理方面的研究。
传统项目转型 要说近几年最火热的话题,那还得是微服务,那么什么是微服务呢?
我们可以先从技术的演变开始看起,在我们学习JavaWeb之后,一般的网站开发模式为Servlet+JSP,但是实际上我们在学习了SSM之后,会发现这种模式已经远远落后了,第一,一个公司不可能去招那么多同时会前端+后端的开发人员,就算招到,也并不一定能保证两个方面都比较擅长,相比前后端分开学习的开发人员,显然后者的学习成本更低,专注度更高。因此前后端分离成为了一种新的趋势。通过使用SpringBoot,我们几乎可以很快速地开发一个高性能的单体应用,只需要启动一个服务端,我们整个项目就开始运行了,各项功能融于一体,开发起来也更加轻松。
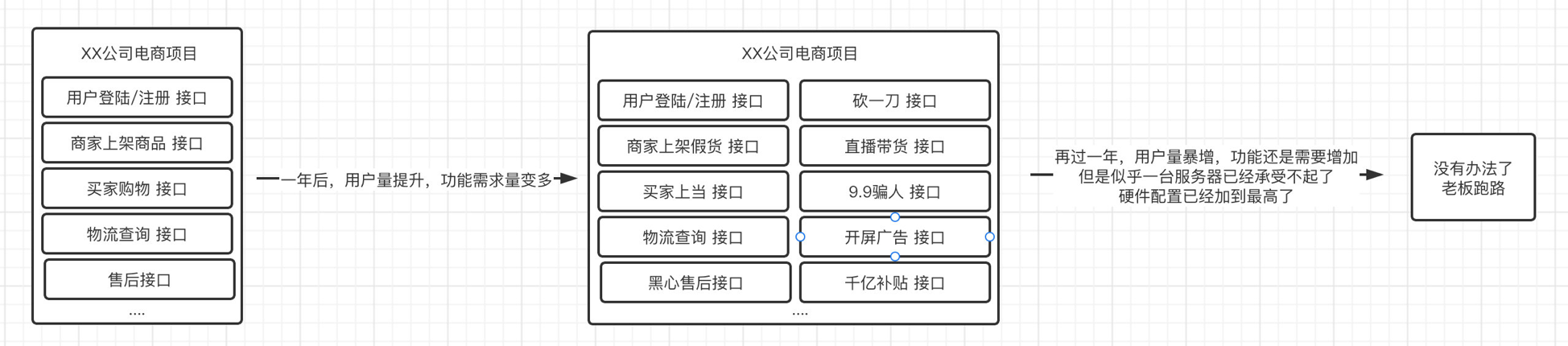
但是随着我们项目的不断扩大,单体应用似乎显得有点乏力了。
随着越来越多的功能不断地加入到一个SpringBoot项目中,随着接口不断增加,整个系统就要在同一时间内响应更多类型的请求,显然,这种扩展方式是不可能无限使用下去的,总有一天,这个SpringBoot项目会庞大到运行缓慢。并且所有的功能如果都集成在单端上,那么所有的请求都会全部汇集到一台服务器上,对此服务器造成巨大压力。
可以试想一下,如果我们的电脑已经升级到i9-12900K,但是依然在运行项目的时候缓慢,无法同一时间响应成千上万的请求,那么这个问题就已经不是单纯升级机器配置可以解决的了。
传统单体架构应用随着项目规模的扩大,实际上会暴露越来越多的问题,尤其是一台服务器无法承受庞大的单体应用部署,并且单体应用的维护也会越来越困难,我们得寻找一种新的开发架构来解决这些问题了。
In short, the microservice architectural style is an approach to developing a single application as a suite of small services, each running in its own process and communicating with lightweight mechanisms, often an HTTP resource API. These services are built around business capabilities and independently deployable by fully automated deployment machinery. There is a bare minimum of centralized management of these services, which may be written in different programming languages and use different data storage technologies.
Martin Fowler在2014年提出了“微服务”架构,它是一种全新的架构风格。
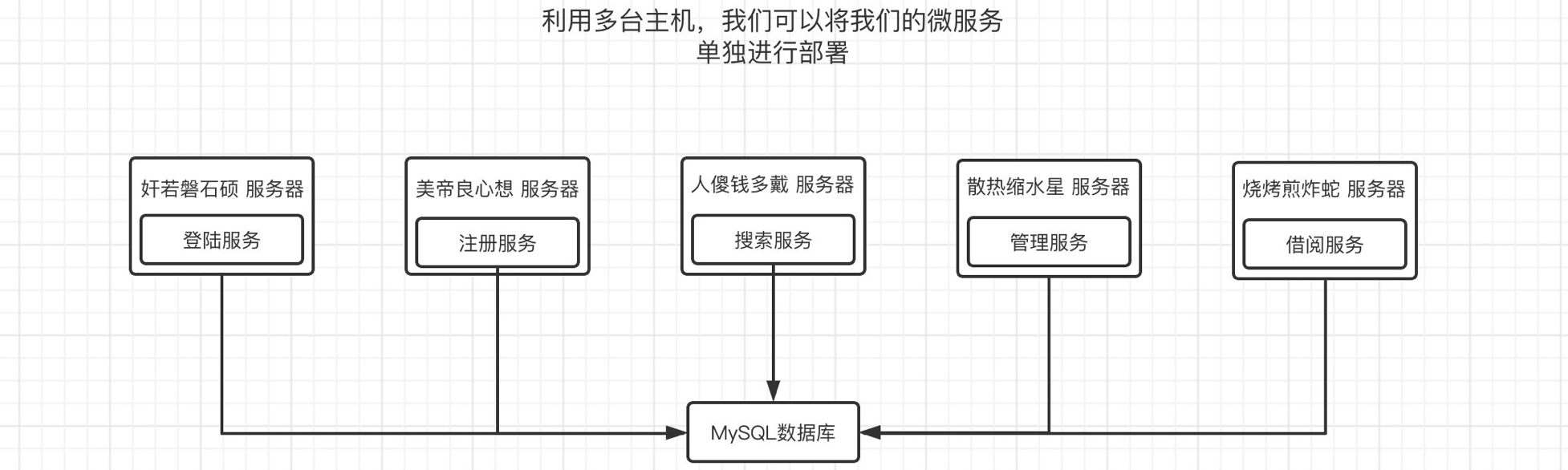
微服务把一个庞大的单体应用拆分为一个个的小型服务,比如我们原来的图书管理项目中,有登录、注册、添加、删除、搜索等功能,那么我们可以将这些功能单独做成一个个小型的SpringBoot项目,独立运行。
每个小型的微服务,都可以独立部署和升级,这样,就算整个系统崩溃,那么也只会影响一个服务的运行。
微服务之间使用HTTP进行数据交互,不再是单体应用内部交互了,虽然这样会显得更麻烦,但是带来的好处也是很直接的,甚至能突破语言限制,使用不同的编程语言进行微服务开发,只需要使用HTTP进行数据交互即可。
我们可以同时购买多台主机来分别部署这些微服务,这样,单机的压力就被分散到多台机器,并且每台机器的配置不一定需要太高,这样就能节省大量的成本,同时安全性也得到很大的保证。
甚至同一个微服务可以同时存在多个,这样当其中一个服务器出现问题时,其他服务器也在运行同样的微服务,这样就可以保证一个微服务的高可用。
当然,这里只是简单的演示一下微服务架构,实际开发中肯定是比这个复杂得多的。
可见,采用微服务架构,更加能够应对当今时代下的种种考验,传统项目的开发模式,需要进行架构上的升级。
走进SpringCloud 前面我们介绍了微服务架构的优点,那么同样的,这些优点的背后也存在着诸多的问题:
要实现微服务并不是说只需要简单地将项目进行拆分,我们还需要考虑对各个微服务进行管理、监控等,这样我们才能够及时地寻找和排查问题。因此微服务往往需要的是一整套解决方案,包括服务注册和发现、容灾处理、负载均衡、配置管理等。
它不像单体架构那种方便维护,由于部署在多个服务器,我们不得不去保证各个微服务能够稳定运行,在管理难度上肯定是高于传统单体应用的。
在分布式的环境下,单体应用的某些功能可能会变得比较麻烦,比如分布式事务。
所以,为了更好地解决这些问题,SpringCloud正式登场。
SpringCloud是Spring提供的一套分布式解决方案,集合了一些大型互联网公司的开源产品,包括诸多组件,共同组成SpringCloud框架。并且,它利用Spring Boot的开发便利性巧妙地简化了分布式系统基础设施的开发,如服务发现注册、配置中心、消息总线、负载均衡、熔断机制、数据监控等,都可以用Spring Boot的开发风格做到一键启动和部署。
由于中小型公司没有独立开发自己的分布式基础设施的能力,使用SpringCloud解决方案能够以最低的成本应对当前时代的业务发展。
可以看到,SpringCloud整体架构的亮点是非常明显的,分布式架构下的各个场景,都有对应的组件来处理,比如基于Netflix(奈飞)的开源分布式解决方案提供的组件:
Eureka - 实现服务治理(服务注册与发现),我们可以对所有的微服务进行集中管理,包括他们的运行状态、信息等。
Ribbon - 为服务之间相互调用提供负载均衡算法(现在被SpringCloudLoadBalancer取代)
Hystrix - 断路器,保护系统,控制故障范围。暂时可以跟家里电闸的保险丝类比,当触电危险发生时能够防止进一步的发展。
Zuul - api网关,路由,负载均衡等多种作用,就像我们的路由器,可能有很多个设备都连接了路由器,但是数据包要转发给谁则是由路由器在进行(已经被SpringCloudGateway取代)
Config - 配置管理,可以实现配置文件集中管理
那么首先,我们就从注册中心开始说起。
Eureka 注册中心 官方文档:https://docs.spring.io/spring-cloud-netflix/docs/current/reference/html/
微服务项目结构 现在我们重新设计一下之前的图书管理系统项目,将原有的大型(也许 项目进行拆分,注意项目拆分一定要尽可能保证单一职责,相同的业务不要在多个微服务中重复出现,如果出现需要借助其他业务完成的服务,那么可以使用服务之间相互调用的形式来实现(之后会介绍):
登录验证服务:用于处理用户注册、登录、密码重置等,反正就是一切与账户相关的内容,包括用户信息获取等。
图书管理服务:用于进行图书添加、删除、更新等操作,图书管理相关的服务,包括图书的存储等和信息获取。
图书借阅服务:交互性比较强的服务,需要和登陆验证服务和图书管理服务进行交互。
那么既然要将单体应用拆分为多个小型服务,我们就需要重新设计一下整个项目目录结构,这里我们就创建多个子项目,每一个子项目都是一个服务,这样由父项目统一管理依赖,就无需每个子项目都去单独管理依赖了,也更方便一点。
我们首先创建一个普通的SpringBoot项目:
然后不需要勾选任何依赖,直接创建即可,项目创建完成并初始化后,我们删除父工程的无用文件,只保留必要文件,像下面这样:
接着我们就可以按照我们划分的服务,进行子工程创建了,创建一个新的Maven项目,注意父项目要指定为我们一开始创建的的项目,子项目命名随意:
子项目创建好之后,接着我们在子项目中创建SpringBoot的启动主类:
接着我们点击运行,即可启动子项目了,实际上这个子项目就一个最简单的SpringBoot web项目,注意启动之后最下方有弹窗,我们点击”使用 服务”,这样我们就可以实时查看当前整个大项目中有哪些微服务了:
接着我们以同样的方法,创建其他的子项目,注意我们最好将其他子项目的端口设置得不一样,不然会导致端口占用,我们分别为它们创建application.yml文件:
接着我们来尝试启动一下这三个服务,正常情况下都是可以直接启动的:
可以看到它们分别运行在不同的端口上,这样,就方便不同的程序员编写不同的服务了,提交当前项目代码时的冲突率也会降低。
接着我们来创建一下数据库,这里还是老样子,创建三个表即可,当然实际上每个微服务单独使用一个数据库服务器也是可以的,因为按照单一职责服务只会操作自己对应的表,这里UP主比较穷,就只用一个数据库演示了:
创建好之后,结果如下,一共三张表,各位可以自行添加一些数据到里面,这就不贴出来了:
如果各位嫌麻烦的话可以下载.sql文件自行导入。
接着我们来稍微写一点业务,比如用户信息查询业务,我们先把数据库相关的依赖进行导入,这里依然使用Mybatis框架,首先在父项目中添加MySQL驱动和Lombok依赖:
1 2 3 4 5 6 7 8 9 <dependency > <groupId > mysql</groupId > <artifactId > mysql-connector-java</artifactId > </dependency > <dependency > <groupId > org.projectlombok</groupId > <artifactId > lombok</artifactId > </dependency >
由于不是所有的子项目都需要用到Mybatis,我们在父项目中只进行版本管理即可:
1 2 3 4 5 6 7 8 9 <dependencyManagement > <dependencies > <dependency > <groupId > org.mybatis.spring.boot</groupId > <artifactId > mybatis-spring-boot-starter</artifactId > <version > 2.2.0</version > </dependency > </dependencies > </dependencyManagement >
接着我们就可以在用户服务子项目中添加此依赖了:
1 2 3 4 5 6 <dependencies > <dependency > <groupId > org.mybatis.spring.boot</groupId > <artifactId > mybatis-spring-boot-starter</artifactId > </dependency > </dependencies >
接着添加数据源信息(UP用到是阿里云的MySQL云数据库,各位注意修改一下数据库地址):
1 2 3 4 5 6 spring: datasource: driver-class-name: com.mysql.cj.jdbc.Driver url: jdbc:mysql://cloudstudy.mysql.cn-chengdu.rds.aliyuncs.com:3306/cloudstudy username: test password: 123456
接着我们来写用户查询相关的业务:
1 2 3 4 5 6 @Data public class User {int uid;
1 2 3 4 5 @Mapper public interface UserMapper {@Select("select * from DB_USER where uid = #{uid}") getUserById (int uid) ;
1 2 3 public interface UserService {getUserById (int uid) ;
1 2 3 4 5 6 7 8 9 10 11 @Service public class UserServiceImpl implements UserService {@Resource @Override public User getUserById (int uid) {return mapper.getUserById(uid);
1 2 3 4 5 6 7 8 9 10 11 12 @RestController public class UserController {@Resource @RequestMapping("/user/{uid}") public User findUserById (@PathVariable("uid") int uid) {return service.getUserById(uid);
现在我们访问即可拿到数据:
同样的方式,我们完成一下图书查询业务,注意现在是在图书管理微服务中编写(别忘了导入Mybatis依赖以及配置数据源):
1 2 3 4 5 6 @Data public class Book {int bid;
1 2 3 4 5 6 @Mapper public interface BookMapper {@Select("select * from DB_BOOK where bid = #{bid}") getBookById (int bid) ;
1 2 3 public interface BookService {getBookById (int bid) ;
1 2 3 4 5 6 7 8 9 10 11 @Service public class BookServiceImpl implements BookService {@Resource @Override public Book getBookById (int bid) {return mapper.getBookById(bid);
1 2 3 4 5 6 7 8 9 10 11 @RestController public class BookController {@Resource @RequestMapping("/book/{bid}") findBookById (@PathVariable("bid") int bid) {return service.getBookById(bid);
同样进行一下测试:
这样,我们一个完整项目的就拆分成了多个微服务,不同微服务之间是独立进行开发和部署的。
服务间调用 前面我们完成了用户信息查询和图书信息查询,现在我们来接着完成借阅服务。
借阅服务是一个关联性比较强的服务,它不仅仅需要查询借阅信息,同时可能还需要获取借阅信息下的详细信息,比如具体那个用户借阅了哪本书,并且用户和书籍的详情也需要同时出现,那么这种情况下,我们就需要去访问除了借阅表以外的用户表和图书表。
但是这显然是违反我们之前所说的单一职责的,相同的业务功能不应该重复出现,但是现在由需要在此服务中查询用户的信息和图书信息,那怎么办呢?我们可以让一个服务去调用另一个服务来获取信息。
这样,图书管理微服务和用户管理微服务相对于借阅记录,就形成了一个生产者和消费者的关系,前者是生产者,后者便是消费者。
现在我们先将借阅关联信息查询完善了:
1 2 3 4 5 6 @Data public class Borrow {int id;int uid;int bid;
1 2 3 4 5 6 7 8 9 10 11 @Mapper public interface BorrowMapper {@Select("select * from DB_BORROW where uid = #{uid}") getBorrowsByUid (int uid) ;@Select("select * from DB_BORROW where bid = #{bid}") getBorrowsByBid (int bid) ;@Select("select * from DB_BORROW where bid = #{bid} and uid = #{uid}") getBorrow (int uid, int bid) ;
现在有一个需求,需要查询用户的借阅详细信息,也就是说需要查询某个用户具体借了那些书,并且需要此用户的信息和所有已借阅的书籍信息一起返回,那么我们先来设计一下返回实体:
1 2 3 4 5 6 @Data @AllArgsConstructor public class UserBorrowDetail {
但是有一个问题,我们发现User和Book实体实际上是在另外两个微服务中定义的,相当于当前项目并没有定义这些实体类,那么怎么解决呢?
因此,我们可以将所有服务需要用到的实体类单独放入另一个一个项目中,然后让这些项目引用集中存放实体类的那个项目,这样就可以保证每个微服务的实体类信息都可以共用了:
然后只需要在对应的类中引用此项目作为依赖即可:
1 2 3 4 5 <dependency > <groupId > com.example</groupId > <artifactId > commons</artifactId > <version > 0.0.1-SNAPSHOT</version > </dependency >
之后新的公共实体类都可以在commons项目中进行定义了,现在我们接着来完成刚刚的需求,先定义接口:
1 2 3 4 public interface BorrowService {getUserBorrowDetailByUid (int uid) ;
1 2 3 4 5 6 7 8 9 10 11 12 @Service public class BorrowServiceImpl implements BorrowService {@Resource @Override public UserBorrowDetail getUserBorrowDetailByUid (int uid) {
需要进行服务远程调用我们需要用到RestTemplate来进行:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 @Service public class BorrowServiceImpl implements BorrowService {@Resource @Override public UserBorrowDetail getUserBorrowDetailByUid (int uid) {RestTemplate template = new RestTemplate ();User user = template.getForObject("http://localhost:8082/user/" +uid, User.class);"http://localhost:8080/book/" +b.getBid(), Book.class))return new UserBorrowDetail (user, bookList);
现在我们再最后完善一下Controller:
1 2 3 4 5 6 7 8 9 10 11 @RestController public class BorrowController {@Resource @RequestMapping("/borrow/{uid}") findUserBorrows (@PathVariable("uid") int uid) {return service.getUserBorrowDetailByUid(uid);
在数据库中添加一点借阅信息,测试看看能不能正常获取(注意一定要保证三个服务都处于开启状态,否则远程调用会失败):
可以看到,结果正常,没有问题,远程调用成功。
这样,一个简易的图书管理系统的分布式项目就搭建完成了,这里记得把整个项目压缩打包备份一下 ,下一章学习SpringCloud Alibaba也需要进行配置。
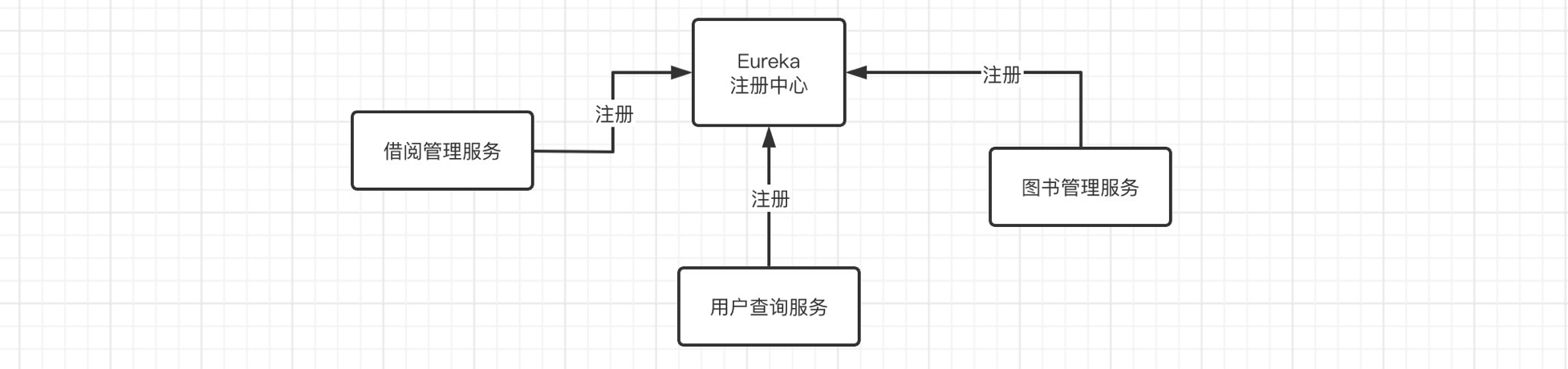
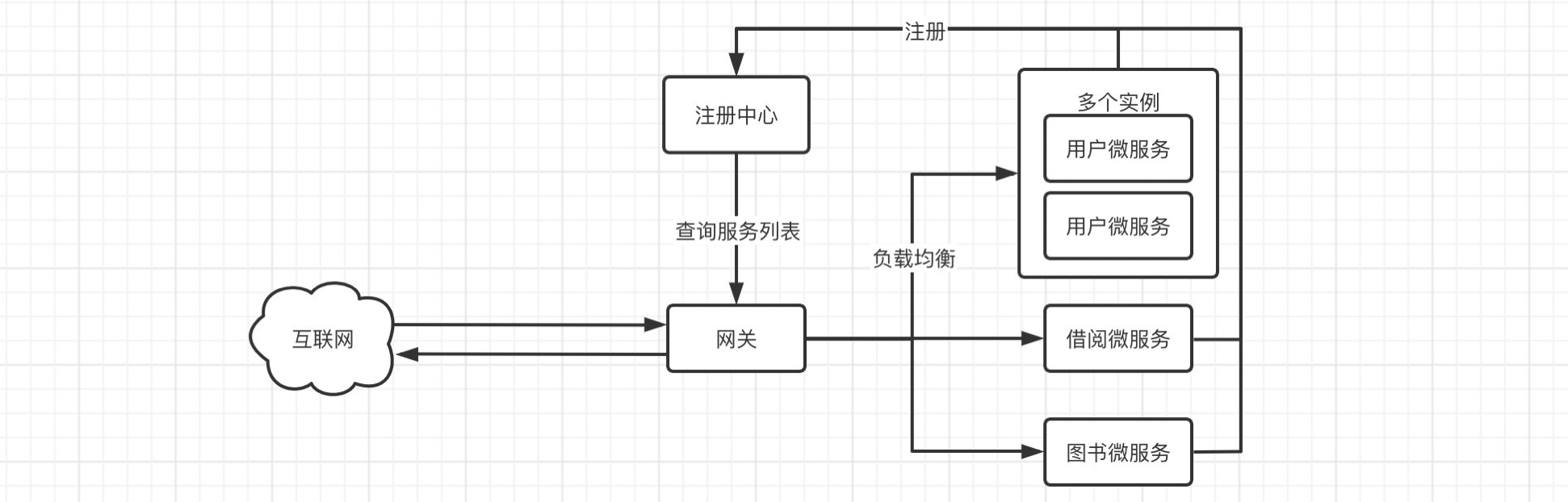
服务注册与发现 前面我们了解了如何对单体应用进行拆分,并且也学习了如何进行服务之间的相互调用,但是存在一个问题,就是虽然服务拆分完成,但是没有一个比较合理的管理机制,如果单纯只是这样编写,在部署和维护起来,肯定是很麻烦的。可以想象一下,如果某一天这些微服务的端口或是地址大规模地发生改变,我们就不得不将服务之间的调用路径大规模的同步进行修改,这是多么可怕的事情。我们需要削弱这种服务之间的强关联性,因此我们需要一个集中管理微服务的平台,这时就要借助我们这一部分的主角了。
Eureka能够自动注册并发现微服务,然后对服务的状态、信息进行集中管理,这样当我们需要获取其他服务的信息时,我们只需要向Eureka进行查询就可以了。
像这样的话,服务之间的强关联性就会被进一步削弱。
那么现在我们就来搭建一个Eureka服务器,只需要创建一个新的Maven项目即可,然后我们需要在父工程中添加一下SpringCloud的依赖管理 ,这里选用2021.0.1版本(Spring Cloud 最新的版本命名方式变更了,现在是 YEAR.x https://spring.io/projects/spring-cloud#learn ):
1 2 3 4 5 6 7 <dependency > <groupId > org.springframework.cloud</groupId > <artifactId > spring-cloud-dependencies</artifactId > <version > 2021.0.1</version > <type > pom</type > <scope > import</scope > </dependency >
接着我们为新创建的项目添加依赖:
1 2 3 4 5 6 <dependencies > <dependency > <groupId > org.springframework.cloud</groupId > <artifactId > spring-cloud-starter-netflix-eureka-server</artifactId > </dependency > </dependencies >
下载内容有点多,首次导入请耐心等待一下。
接着我们来创建主类,还是一样的操作:
1 2 3 4 5 6 7 8 @EnableEurekaServer @SpringBootApplication public class EurekaServerApplication {public static void main (String[] args) {
别着急启动!!!接着我们需要修改一下配置文件:
1 2 3 4 5 6 7 8 9 10 11 12 server: port: 8888 eureka: client: fetch-registry: false register-with-eureka: false service-url: defaultZone: http://localhost:8888/eureka
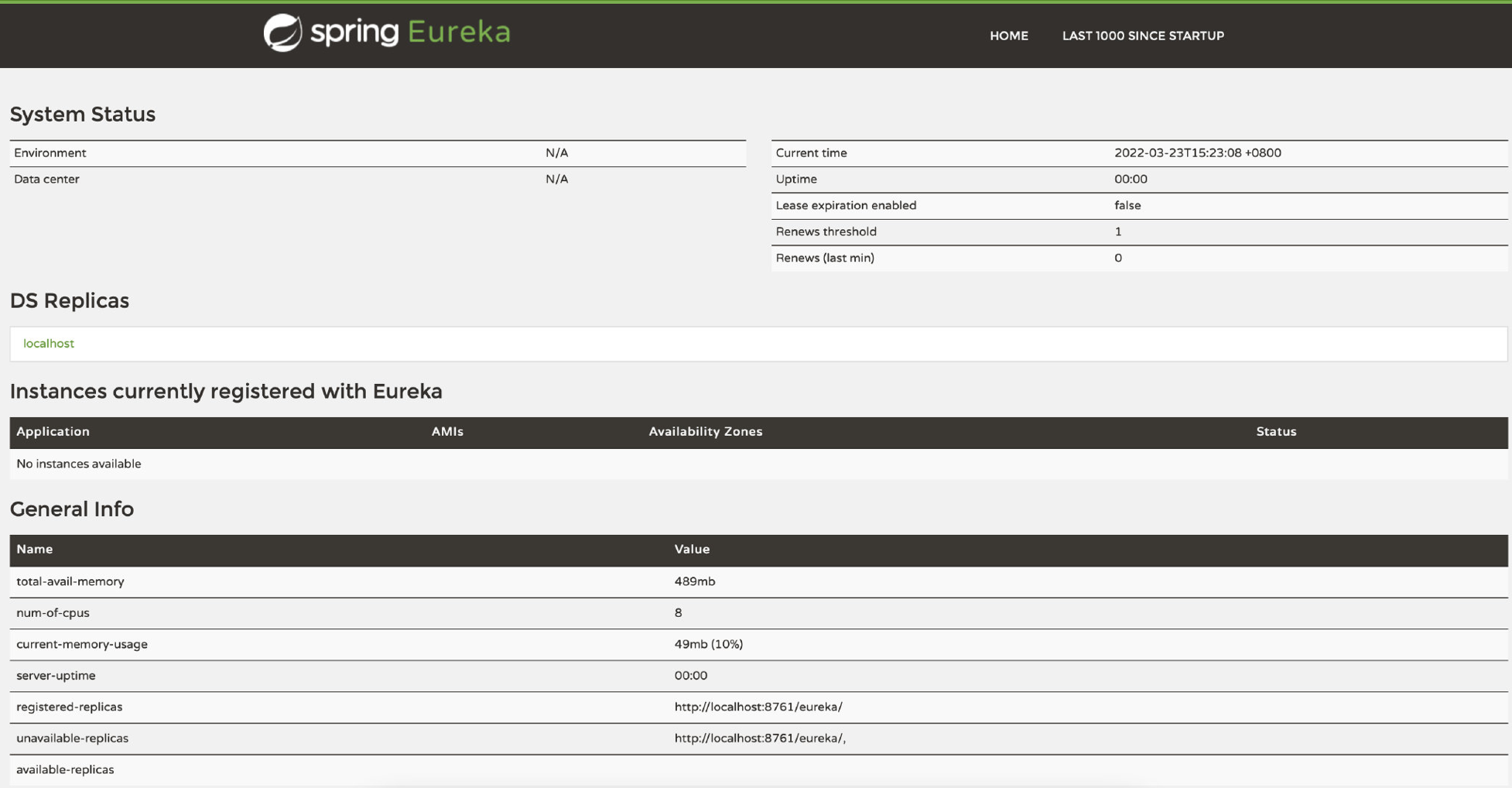
好了,现在差不多可以启动了,启动完成后,直接输入地址+端口即可访问Eureka的管理后台:
可以看到目前还没有任何的服务注册到Eureka,我们接着来配置一下我们的三个微服务,首先还是需要导入Eureka依赖 (注意别导错了,名称里面有个starter的才是):
1 2 3 4 <dependency > <groupId > org.springframework.cloud</groupId > <artifactId > spring-cloud-starter-netflix-eureka-client</artifactId > </dependency >
然后修改配置文件:
1 2 3 4 5 eureka: client: service-url: defaultZone: http://localhost:8888/eureka
OK,无需在启动类添加注解,直接启动就可以了,然后打开Eureka的服务管理页面,可以看到我们刚刚开启的服务:
可以看到8082端口上的服务器,已经成功注册到Eureka了,但是这个服务名称怎么会显示为UNKNOWN,我们需要修改一下:
1 2 3 spring: application: name: userservice
[!NOTE] Tipsname不能大写字母,用小写 。
当我们的服务启动之后,会每隔一段时间跟Eureka发送一次心跳包,这样Eureka就能够感知到我们的服务是否处于正常运行状态。
现在我们用同样的方法,将另外两个微服务也注册进来:
那么,现在我们怎么实现服务发现 呢?
也就是说,我们之前如果需要对其他微服务进行远程调用,那么就必须要知道其他服务的地址:
1 User user = template.getForObject("http://localhost:8082/user/" +uid, User.class);
而现在有了Eureka之后,我们可以直接向其进行查询,得到对应的微服务地址,这里直接将服务名称替换即可:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 @Service public class BorrowServiceImpl implements BorrowService {@Resource @Resource @Override public UserBorrowDetail getUserBorrowDetailByUid (int uid) {User user = template.getForObject("http://userservice/user/" +uid, User.class);"http://bookservice/book/" +b.getBid(), Book.class))return new UserBorrowDetail (user, bookList);
接着我们手动将RestTemplate声明为一个Bean,然后添加@LoadBalanced注解,这样Eureka就会对服务的调用进行自动发现,并提供负载均衡 :
1 2 3 4 5 6 7 8 @Configuration public class BeanConfig {@Bean @LoadBalanced template () {return new RestTemplate ();
现在我们就可以正常调用了:
不对啊,不是说有负载均衡的能力吗,怎么个负载均衡 呢?
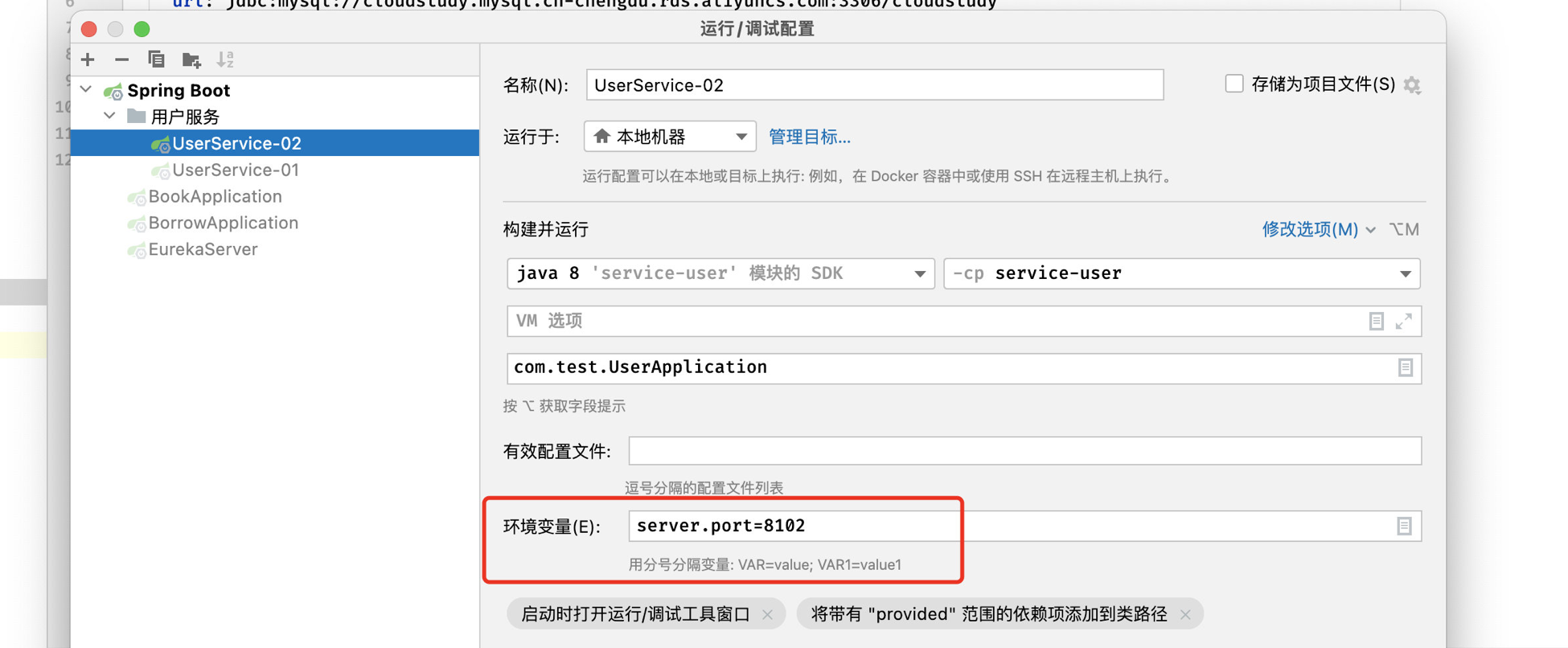
我们先来看看,同一个服务器实际上是可以注册很多个的,但是它们的端口不同,比如我们这里创建多个用户查询服务,我们现在将原有的端口配置修改一下,由IDEA中设定启动参数来决定,这样就可以多创建几个不同端口的启动项了:
可以看到,在Eureka中,同一个服务出现了两个实例:
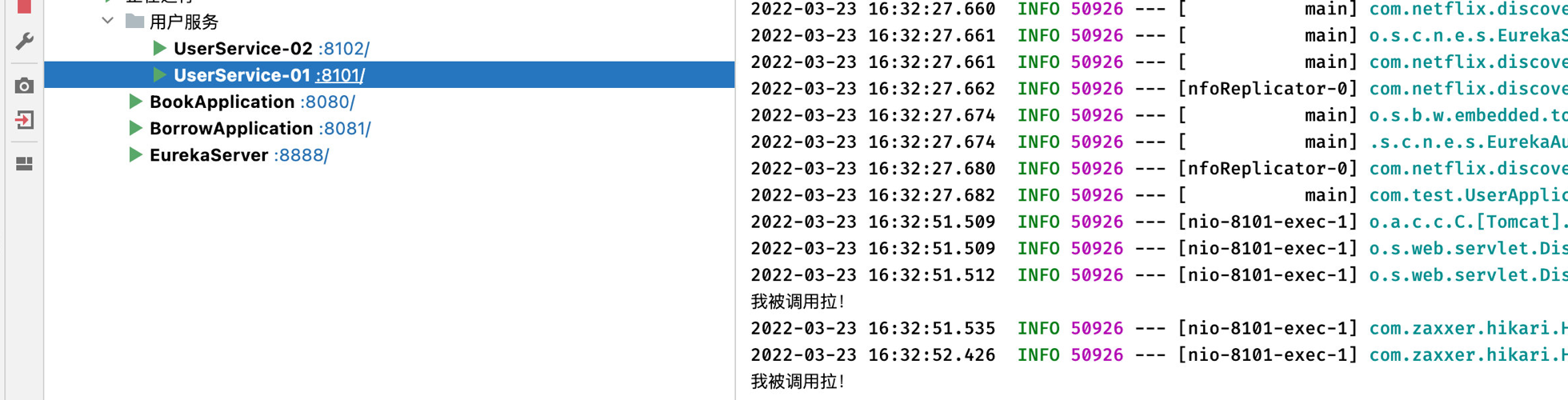
现在我们稍微修改一下用户查询,然后进行远程调用,看看请求是不是均匀地分配到这两个服务端:
1 2 3 4 5 6 7 8 9 10 11 12 @RestController public class UserController {@Resource @RequestMapping("/user/{uid}") public User findUserById (@PathVariable("uid") int uid) {"我被调用拉!" );return service.getUserById(uid);
可以看到,两个实例都能够均匀地被分配请求:
这样,服务自动发现以及简单的负载均衡就实现完成了,并且,如果某个微服务挂掉了,只要存在其他同样的微服务实例在运行,那么就不会导致整个微服务不可用,极大地保证了安全性。
注册中心高可用 各位可否想过这样的一个问题?虽然Eureka能够实现服务注册和发现,但是如果Eureka服务器崩溃了,岂不是所有需要用到服务发现的微服务就GG了?
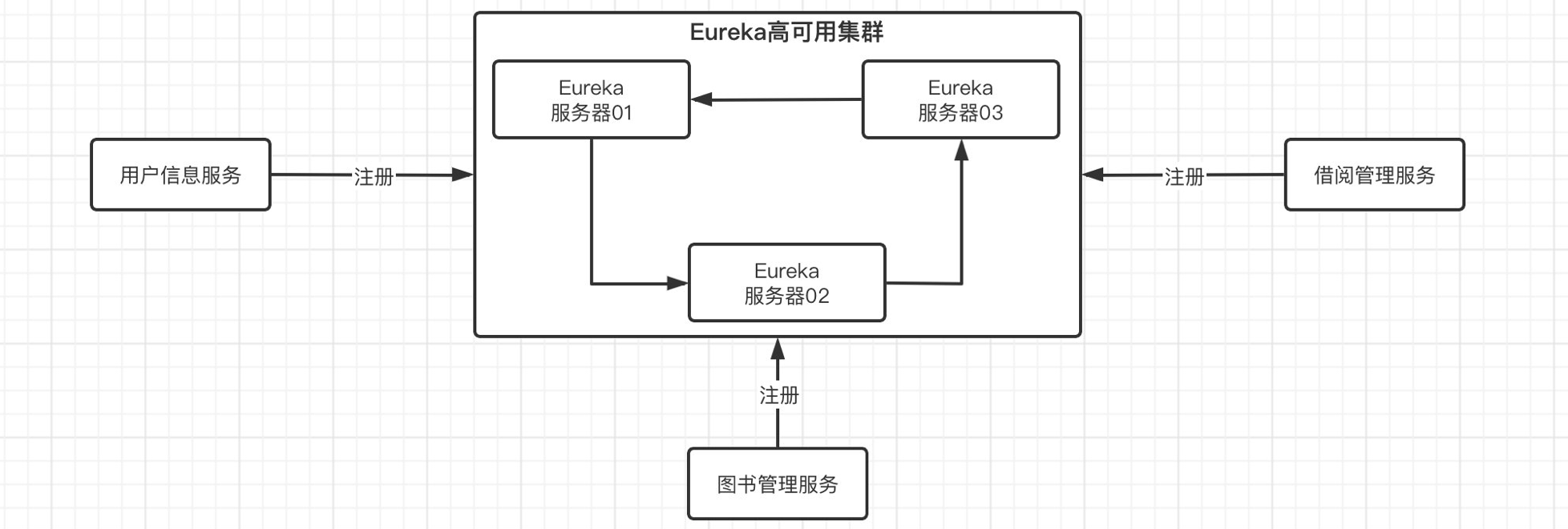
为了避免,这种问题,我们也可以像上面那样,搭建Eureka集群,存在多个Eureka服务器,这样就算挂掉其中一个,其他的也还在正常运行,就不会使得服务注册与发现不可用。当然,要是物理黑客直接炸了整个机房,那还是算了吧。
我们来看看如何搭建Eureka集群,这里由于机器配置不高,就搭建两个Eureka服务器组成集群。
首先我们需要修改一下Eureka服务端的配置文件,这里我们创建两个配置文件,:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 server: port: 8801 spring: application: name: eurekaserver eureka: instance: hostname: eureka01 client: fetch-registry: false service-url: defaultZone: http://eureka02:8802/eureka
1 2 3 4 5 6 7 8 9 10 11 12 server: port: 8802 spring: application: name: eurekaserver eureka: instance: hostname: eureka02 client: fetch-registry: false service-url: defaultZone: http://eureka01:8801/eureka
这里由于我们修改成自定义的地址,需要在hosts文件中将其解析到172.0.0.1才能回到localhost,Mac下文件路径为/etc/hosts,Windows下为C:\Windows\system32\drivers\etc\hosts:
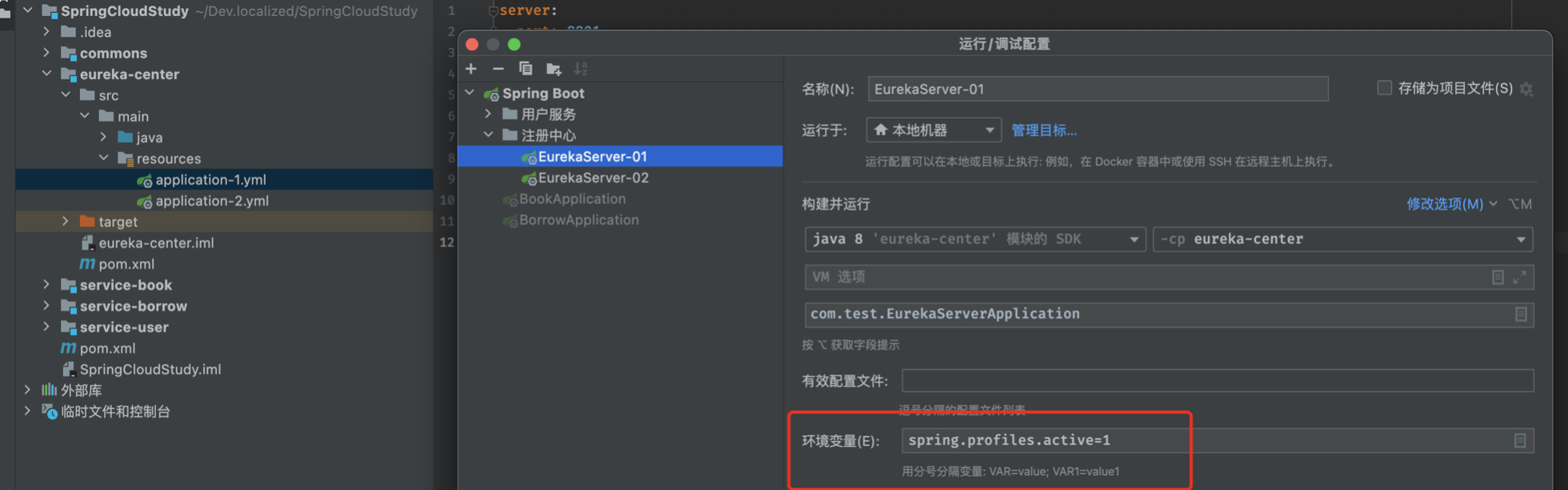
对创建的两个配置文件分别添加启动配置,直接使用spring.profiles.active指定启用的配置文件即可:
接着启动这两个注册中心,这两个Eureka管理页面都可以被访问,我们访问其中一个:
可以看到下方replicas中已经包含了另一个Eureka服务器的地址,并且是可用状态。
接着我们需要将我们的微服务配置也进行修改:
1 2 3 4 5 eureka: client: service-url: defaultZone: http://localhost:8801/eureka, http://localhost:8802/eureka
可以看到,服务全部成功注册,并且两个Eureka服务端都显示为已注册:
接着我们模拟一下,将其中一个Eureka服务器关闭掉,可以看到它会直接变成不可用状态 :
当然,如果这个时候我们重启刚刚关闭的Eureka服务器,会自动同步其他Eureka服务器的数据 。
LoadBalancer 负载均衡 前面我们讲解了如何对服务进行拆分、如何通过Eureka服务器进行服务注册与发现,那么现在我们来看看,它的负载均衡到底是如何实现的,实际上之前演示的负载均衡是依靠LoadBalancer实现的。
在2020年前的SpringCloud版本是采用Ribbon作为负载均衡实现,但是2020年的版本之后SpringCloud把Ribbon移除了,进而用自己编写的LoadBalancer替代。
那么,负载均衡是如何进行的呢?
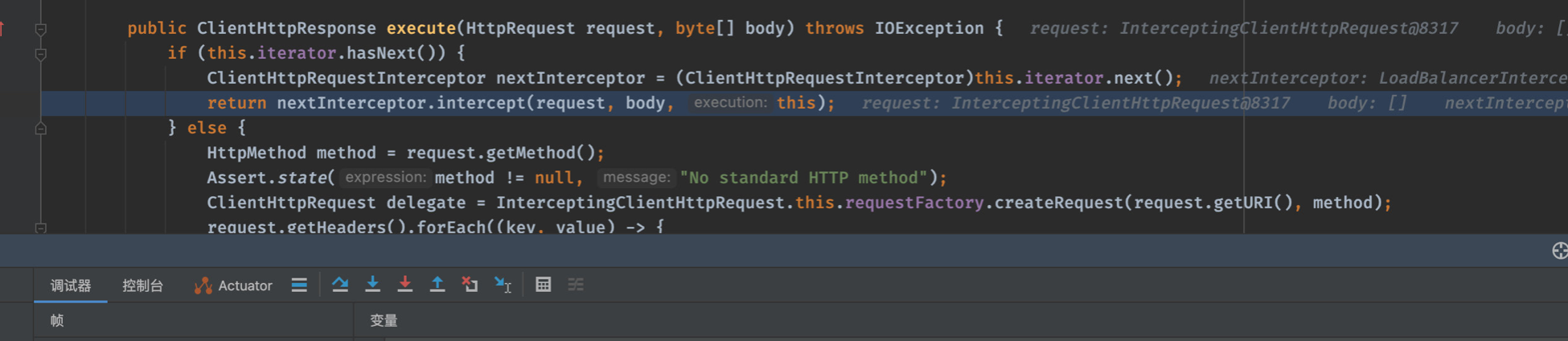
负载均衡 实际上,在添加@LoadBalanced注解之后,会启用拦截器对我们发起的服务调用请求进行拦截(注意这里是针对我们发起的请求进行拦截),叫做LoadBalancerInterceptor,它实现ClientHttpRequestInterceptor接口:
1 2 3 4 @FunctionalInterface public interface ClientHttpRequestInterceptor {intercept (HttpRequest request, byte [] body, ClientHttpRequestExecution execution) throws IOException;
主要是对intercept方法的实现:
1 2 3 4 5 6 public ClientHttpResponse intercept (final HttpRequest request, final byte [] body, final ClientHttpRequestExecution execution) throws IOException {URI originalUri = request.getURI();String serviceName = originalUri.getHost();null , "Request URI does not contain a valid hostname: " + originalUri);return (ClientHttpResponse)this .loadBalancer.execute(serviceName, this .requestFactory.createRequest(request, body, execution));
我们可以打个断点看看实际是怎么在执行的,可以看到:
服务端会在发起请求时执行这些拦截器。
那么这个拦截器做了什么事情呢,首先我们要明确,我们给过来的请求地址,并不是一个有效的主机名称,而是服务名称,那么怎么才能得到真正需要访问的主机名称呢,肯定是得找Eureka获取的。
我们来看看loadBalancer.execute()做了什么,它的具体实现为BlockingLoadBalancerClient:
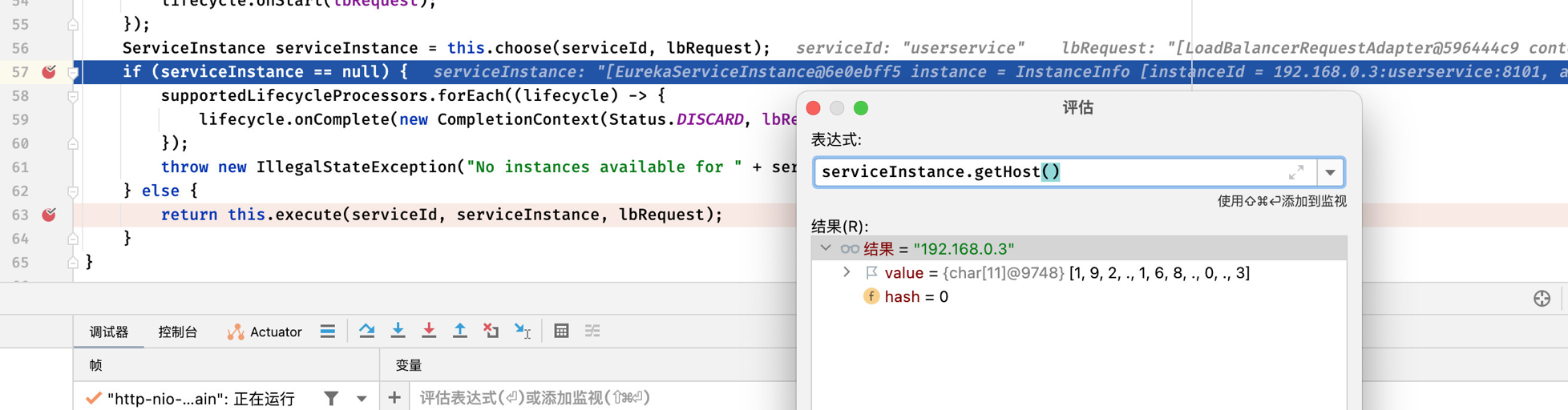
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 public <T> T execute (String serviceId, LoadBalancerRequest<T> request) throws IOException {String hint = this .getHint(serviceId);new LoadBalancerRequestAdapter (request, new DefaultRequestContext (request, hint));this .getSupportedLifecycleProcessors(serviceId);ServiceInstance serviceInstance = this .choose(serviceId, lbRequest);if (serviceInstance == null ) {new CompletionContext (Status.DISCARD, lbRequest, new EmptyResponse ()));throw new IllegalStateException ("No instances available for " + serviceId);else {return this .execute(serviceId, serviceInstance, lbRequest);
所以,实际上在进行负载均衡的时候,会向Eureka发起请求,选择一个可用的对应服务,然后会返回此服务的主机地址等信息:
自定义负载均衡策略 LoadBalancer默认提供了两种负载均衡策略:
RandomLoadBalancer - 随机分配策略
(默认) RoundRobinLoadBalancer - 轮询分配策略
现在我们希望修改默认的负载均衡策略,可以进行指定,比如我们现在希望用户服务采用随机分配策略,我们需要先创建随机分配策略的配置类(不用加@Configuration):
1 2 3 4 5 6 7 8 public class LoadBalancerConfig {@Bean public ReactorLoadBalancer<ServiceInstance> randomLoadBalancer (Environment environment, LoadBalancerClientFactory loadBalancerClientFactory) {String name = environment.getProperty(LoadBalancerClientFactory.PROPERTY_NAME);return new RandomLoadBalancer (loadBalancerClientFactory.getLazyProvider(name, ServiceInstanceListSupplier.class), name);
接着我们需要为对应的服务指定负载均衡策略,直接使用注解即可:
1 2 3 4 5 6 7 8 9 10 @Configuration @LoadBalancerClient(value = "userservice", //指定为 userservice 服务,只要是调用此服务都会使用我们指定的策略 configuration = LoadBalancerConfig.class) public class BeanConfig {@Bean @LoadBalanced template () {return new RestTemplate ();
接着我们在BlockingLoadBalancerClient中添加断点,观察是否采用我们指定的策略进行请求:
发现访问userservice服务的策略已经更改为我们指定的策略了。
OpenFeign实现负载均衡 官方文档:https://docs.spring.io/spring-cloud-openfeign/docs/current/reference/html/
Feign和RestTemplate一样,也是HTTP客户端请求工具,但是它的使用方式更加便捷。首先是依赖:
1 2 3 4 <dependency > <groupId > org.springframework.cloud</groupId > <artifactId > spring-cloud-starter-openfeign</artifactId > </dependency >
接着在启动类添加@EnableFeignClients注解:
1 2 3 4 5 6 7 @SpringBootApplication @EnableFeignClients public class BorrowApplication {public static void main (String[] args) {
那么现在我们需要调用其他微服务提供的接口,该怎么做呢?我们直接创建一个对应服务的接口类即可:
1 2 3 @FeignClient("userservice") public interface UserClient {
接着我们直接创建所需类型的方法,比如我们之前的:
1 2 RestTemplate template = new RestTemplate ();User user = template.getForObject("http://userservice/user/" +uid, User.class);
现在可以直接写成这样:
1 2 3 4 5 6 7 @FeignClient("userservice") public interface UserClient {@RequestMapping("/user/{uid}") getUserById (@PathVariable("uid") int uid) ;
[!NOTE] TipsRequestMapping 地址,则要在 xxxClient 接口方法上提供完整的路径 。
接着我们直接注入使用(有Mybatis那味了):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 @Resource @Override public UserBorrowDetail getUserBorrowDetailByUid (int uid) {User user = userClient.getUserById(uid);"http://bookservice/book/" +b.getBid(), Book.class))return new UserBorrowDetail (user, bookList);
访问,可以看到结果依然是正确的:
并且我们可以观察一下两个用户微服务的调用情况,也是以负载均衡的形式进行的。
按照同样的方法,我们接着将图书管理服务的调用也改成接口形式:
最后我们的Service代码就变成了:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 @Service public class BorrowServiceImpl implements BorrowService {@Resource @Resource @Resource @Override public UserBorrowDetail getUserBorrowDetailByUid (int uid) {User user = userClient.getUserById(uid);return new UserBorrowDetail (user, bookList);
继续访问进行测试:
OK,正常。
当然,Feign也有很多的其他配置选项,这里就不多做介绍了,详细请查阅官方文档。
Hystrix 服务熔断 官方文档:https://cloud.spring.io/spring-cloud-static/spring-cloud-netflix/1.3.5.RELEASE/single/spring-cloud-netflix.html#_circuit_breaker_hystrix_clients
我们知道,微服务之间是可以进行相互调用的,那么如果出现了下面的情况会导致什么问题?
由于位于最底端的服务提供者E发生故障,那么此时会直接导致服务ABCD全线崩溃,就像雪崩了一样。
这种问题实际上是不可避免的,由于多种因素,比如网络卡顿、系统故障、硬件问题等,都存在一定可能,会导致这种极端的情况发生。因此,我们需要寻找一个应对这种极端情况的解决方案。
为了解决分布式系统的雪崩问题,SpringCloud提供了Hystrix熔断器组件,他就像我们家中的保险丝一样,当电流过载就会直接熔断,防止危险进一步发生,从而保证家庭用电安全。可以想象一下,如果整条链路上的服务已经全线崩溃,这时还在不断地有大量的请求到达,需要各个服务进行处理,肯定是会使得情况越来越糟糕的。
我们来详细看看它的工作机制。
服务降级 首先我们来看看服务降级,注意一定要区分开服务降级和服务熔断的区别,服务降级并不会直接返回错误,而是可以提供一个补救措施,正常响应给请求者。这样相当于服务依然可用,但是服务能力肯定是下降了的。
我们就基于借阅管理服务来进行讲解,我们不开启用户服务和图书服务,表示用户服务和图书服务已经挂掉了。
这里我们导入Hystrix的依赖(此项目已经停止维护,SpringCloud依赖中已经不自带了,所以说需要自己单独导入):
1 2 3 4 5 <dependency > <groupId > org.springframework.cloud</groupId > <artifactId > spring-cloud-starter-netflix-hystrix</artifactId > <version > 2.2.10.RELEASE</version > </dependency >
接着我们需要在启动类添加注解开启:
1 2 3 4 5 6 7 @SpringBootApplication @EnableHystrix public class BorrowApplication {public static void main (String[] args) {
那么现在,由于用户服务和图书服务不可用,所以查询借阅信息的请求肯定是没办法正常响应的,这时我们可以提供一个备选方案,也就是说当服务出现异常时,返回我们的备选方案:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 @RestController public class BorrowController {@Resource @HystrixCommand(fallbackMethod = "onError") @RequestMapping("/borrow/{uid}") findUserBorrows (@PathVariable("uid") int uid) {return service.getUserBorrowDetailByUid(uid);onError (int uid) {return new UserBorrowDetail (null , Collections.emptyList());
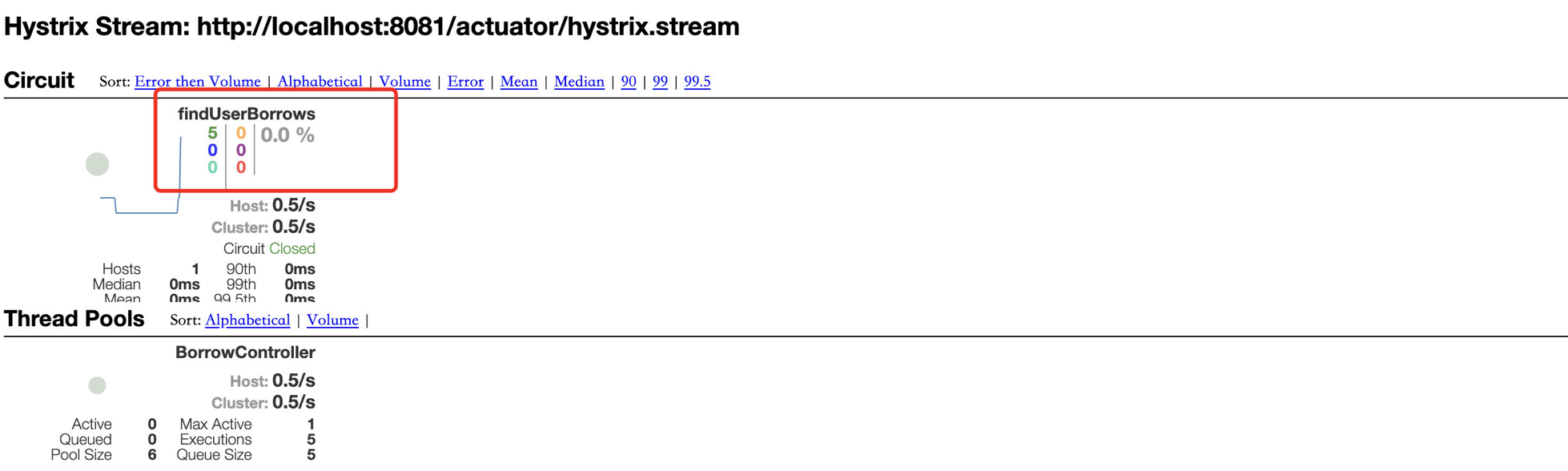
可以看到,虽然我们的服务无法正常运行了,但是依然可以给浏览器正常返回响应数据:
服务降级是一种比较温柔的解决方案,虽然服务本身的不可用,但是能够保证正常响应数据。
服务熔断 熔断机制是应对雪崩效应的一种微服务链路保护机制,当检测出链路的某个微服务不可用或者响应时间太长时,会进行服务的降级,进而熔断该节点微服务的调用,快速返回”错误”的响应信息。当检测到该节点微服务响应正常后恢复调用链路。
实际上,熔断就是在降级的基础上进一步升级形成的,也就是说,在一段时间内多次调用失败,那么就直接升级为熔断。
我们可以添加两条输出语句:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 @RestController public class BorrowController {@Resource @HystrixCommand(fallbackMethod = "onError") @RequestMapping("/borrow/{uid}") findUserBorrows (@PathVariable("uid") int uid) {"开始向其他服务获取信息" );return service.getUserBorrowDetailByUid(uid);onError (int uid) {"服务错误,进入备选方法!" );return new UserBorrowDetail (null , Collections.emptyList());
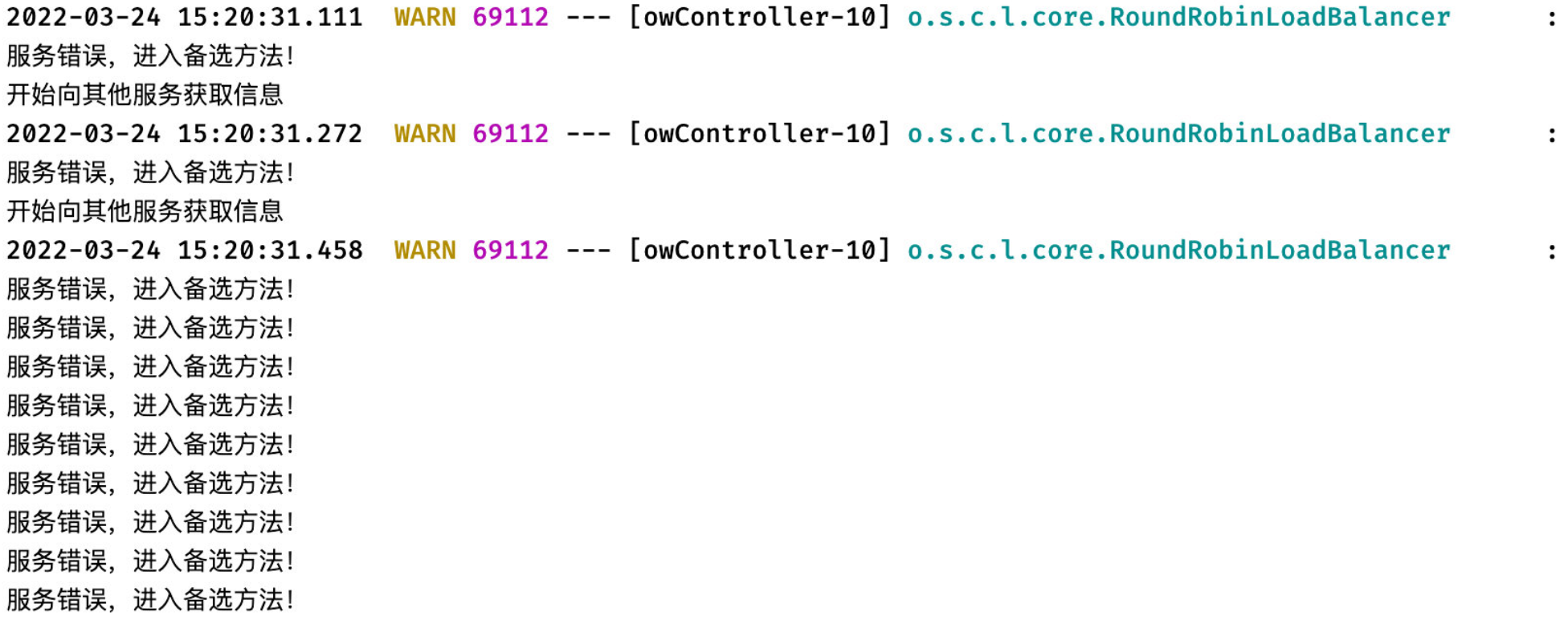
接着,我们在浏览器中疯狂点击刷新按钮,对此服务疯狂发起请求,可以看到后台:
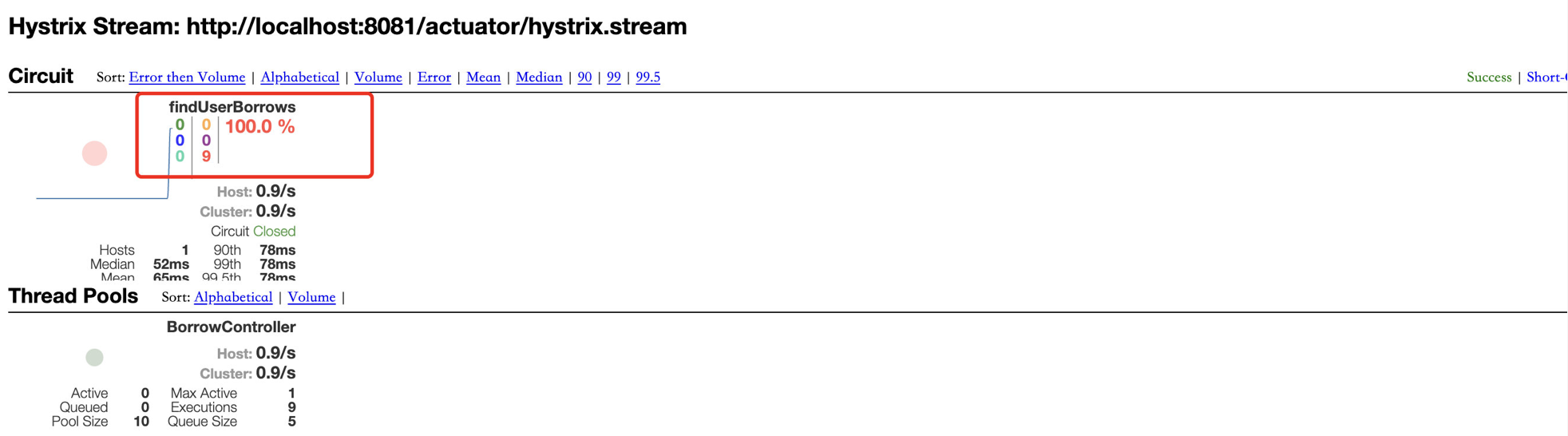
一开始的时候,会正常地去调用Controller对应的方法findUserBorrows,发现失败然后进入备选方法,但是我们发现在持续请求一段时间之后,没有再调用这个方法,而是直接调用备选方案,这便是升级到了熔断状态。
我们可以继续不断点击,继续不断地发起请求:
可以看到,过了一段时间之后,会尝试正常执行一次findUserBorrows,但是依然是失败状态,所以继续保持熔断状态。
所以得到结论,它能够对一段时间内出现的错误进行侦测,当侦测到出错次数过多时,熔断器会打开,所有的请求会直接响应失败,一段时间后,只执行一定数量的请求,如果还是出现错误,那么则继续保持打开状态,否则说明服务恢复正常运行,关闭熔断器。
我们可以测试一下,开启另外两个服务之后,继续点击:
可以看到,当另外两个服务正常运行之后,当再次尝试调用findUserBorrows之后会成功,于是熔断机制就关闭了,服务恢复运行。
总结一下:
OpenFeign实现降级 Hystrix也可以配合Feign进行降级,我们可以对应接口中定义的远程调用单独进行降级操作。
比如我们还是以用户服务挂掉为例,那么这个时候肯定是会远程调用失败的,也就是说我们的Controller中的方法在执行过程中会直接抛出异常,进而被Hystrix监控到并进行服务降级。
而实际上导致方法执行异常的根源就是远程调用失败,所以我们换个思路,既然用户服务调用失败,那么我就给这个远程调用添加一个替代方案,如果此远程调用失败,那么就直接上替代方案。那么怎么实现替代方案呢?我们知道Feign都是以接口的形式来声明远程调用,那么既然远程调用已经失效,我们就自行对其进行实现,创建一个实现类,对原有的接口方法进行替代方案实现:
1 2 3 4 5 6 7 8 9 @Component public class UserFallbackClient implements UserClient {@Override public User getUserById (int uid) { User user = new User ();"我是替代方案" );return user;
实现完成后,我们只需要在原有的接口中指定失败替代实现即可:
1 2 3 4 5 6 7 @FeignClient(value = "userservice", fallback = UserFallbackClient.class) public interface UserClient {@RequestMapping("/user/{uid}") getUserById (@PathVariable("uid") int uid) ;
现在去掉BorrowController的@HystrixCommand注解和备选方法:
1 2 3 4 5 6 7 8 9 10 11 @RestController public class BorrowController {@Resource @RequestMapping("/borrow/{uid}") findUserBorrows (@PathVariable("uid") int uid) {return service.getUserBorrowDetailByUid(uid);
最后我们在配置文件中开启熔断支持 :
1 2 3 feign: circuitbreaker: enabled: true
启动服务,调用接口试试看:
可以看到,现在已经采用我们的替代方案作为结果。
监控页面部署 除了对服务的降级和熔断处理,我们也可以对其进行实时监控 ,只需要安装监控页面即可,这里我们创建一个新的项目,导入依赖:
1 2 3 4 5 <dependency > <groupId > org.springframework.cloud</groupId > <artifactId > spring-cloud-starter-netflix-hystrix-dashboard</artifactId > <version > 2.2.10.RELEASE</version > </dependency >
接着添加配置文件:
1 2 3 4 5 6 server: port: 8900 hystrix: dashboard: proxy-stream-allow-list: "localhost"
接着创建主类,注意需要添加@EnableHystrixDashboard注解开启管理页面:
1 2 3 4 5 6 7 @SpringBootApplication @EnableHystrixDashboard public class HystrixDashBoardApplication {public static void main (String[] args) {
启动Hystrix管理页面服务,然后我们需要在要进行监控的服务中添加Actuator依赖:
1 2 3 4 <dependency > <groupId > org.springframework.boot</groupId > <artifactId > spring-boot-starter-actuator</artifactId > </dependency >
Actuator是SpringBoot程序的监控系统,可以实现健康检查,记录信息等。在使用之前需要引入spring-boot-starter-actuator,并做简单的配置即可。
添加此依赖后,我们可以在IDEA中查看运行情况:
然后在配置文件中配置Actuator添加暴露:
1 2 3 4 5 management: endpoints: web: exposure: include: '*'
接着我们打开刚刚启动的管理页面,地址为:http://localhost:8900/hystrix/
在中间填写要监控的服务:比如借阅服务:http://localhost:8301/actuator/hystrix.stream,注意后面要添加`/actuator/hystrix.stream`,然后点击Monitor Stream即可进入监控页面:
可以看到现在都是Loading状态,这是因为还没有开始统计,我们现在尝试调用几次我们的服务:
可以看到,在调用之后,监控页面出现了信息:
可以看到5次访问都是正常的,所以显示为绿色,接着我们来尝试将图书服务关闭,这样就会导致服务降级甚至熔断,然后再多次访问此服务看看监控会如何变化:
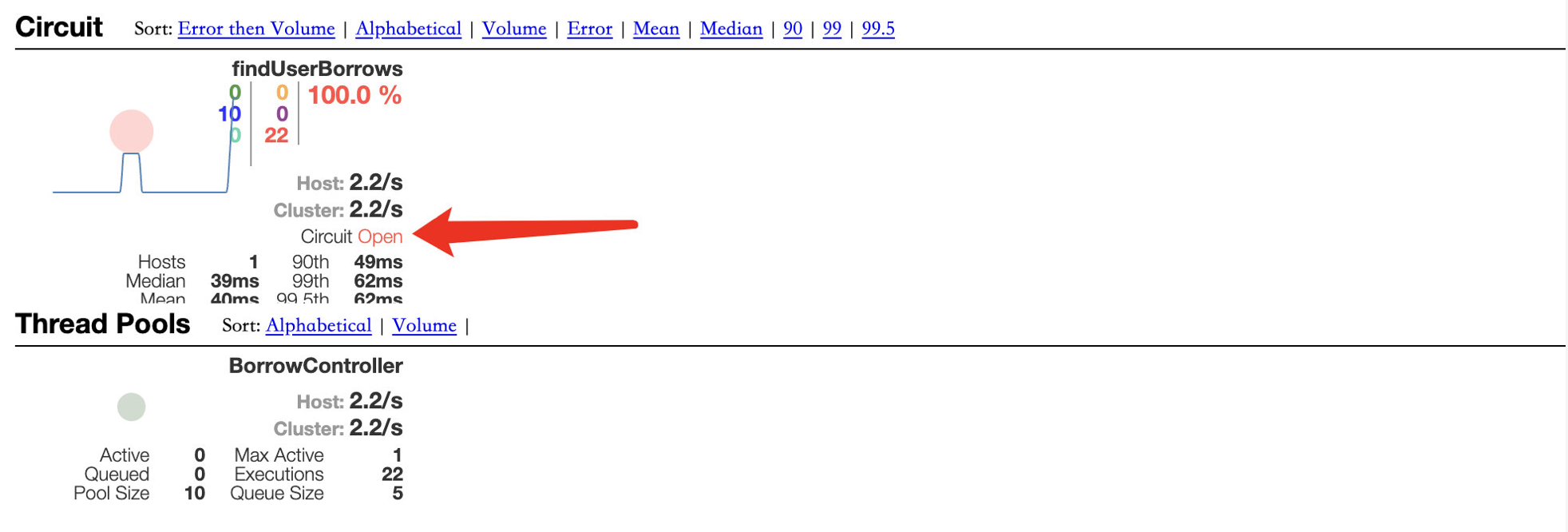
可以看到,错误率直接飙升到100%,并且一段时间内持续出现错误,中心的圆圈也变成了红色,我们继续进行访问:
在出现大量错误的情况下保持持续访问,可以看到此时已经将服务熔断,Circuit更改为 Open 状态,并且图中的圆圈也变得更大,表示压力在持续上升。
Gateway 路由网关 官网地址:https://docs.spring.io/spring-cloud-gateway/docs/current/reference/html/
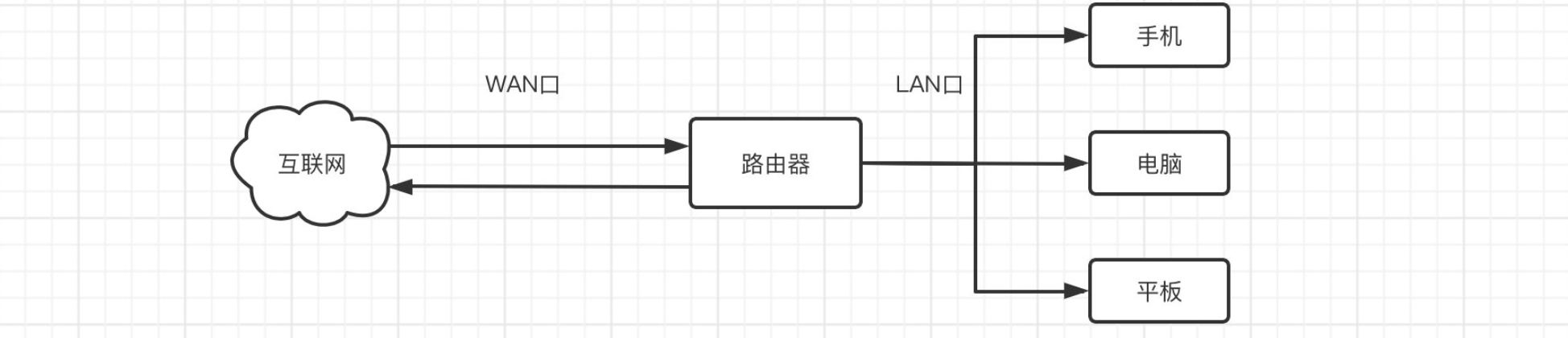
我们家里的路由器充当的是一个什么角色呢?
我们知道,如果我们需要连接互联网,那么就需要将手机或是电脑连接到家里的路由器才可以,而路由器则连接光猫,光猫再通过光纤连接到互联网,也就是说,互联网方向发送过来的数据,需要经过路由器才能到达我们的设备。而路由器充当的就是数据包中转站,所有的局域网设备都无法直接与互联网连接,而是需要经过路由器进行中转,我们一般说路由器下的网络是内网,而互联网那一端是外网。
我们的局域网设备,无法被互联网上的其他设备直接访问,肯定是能够保证到安全性的。并互联网发送过来的数据,需要经过路由器进行解析,识别到底是哪一个设备的数据包,然后再发送给对应的设备。
而我们的微服务也是这样,一般情况下,可能并不是所有的微服务都需要直接暴露给外部调用,这时我们就可以使用路由机制,添加一层防护,让所有的请求全部通过路由来转发到各个微服务,并且转发给多个相同微服务实例也可以实现负载均衡。
在之前,路由的实现一般使用Zuul,但是已经停更,而现在新出现了由SpringCloud官方开发的Gateway路由,它相比Zuul不仅性能上得到了一定的提升,并且是官方推出,契合性也会更好,所以我们这里就主要讲解Gateway。
部署网关 现在我们来创建一个新的项目,作为我们的网关,这里需要添加两个依赖:
1 2 3 4 5 6 7 8 9 10 <dependencies > <dependency > <groupId > org.springframework.cloud</groupId > <artifactId > spring-cloud-starter-gateway</artifactId > </dependency > <dependency > <groupId > org.springframework.cloud</groupId > <artifactId > spring-cloud-starter-netflix-eureka-client</artifactId > </dependency > </dependencies >
第一个依赖就是网关的依赖,而第二个则跟其他微服务一样,需要注册到Eureka才能生效,注意别添加Web依赖,使用的是WebFlux框架。
然后我们来完善一下配置文件:
1 2 3 4 5 6 7 8 9 server: port: 8500 eureka: client: service-url: defaultZone: http://localhost:8801/eureka, http://localhost:8802/eureka spring: application: name: gateway
现在就可以启动了:
但是现在还没有配置任何的路由功能,我们接着将路由功能进行配置:
1 2 3 4 5 6 7 8 9 spring: cloud: gateway: routes: - id: borrow-service uri: lb://borrowservice predicates: - Path=/borrow/**
路由规则的详细列表(断言工厂列表)在这里:https://docs.spring.io/spring-cloud-gateway/docs/current/reference/html/#gateway-request-predicates-factories ,可以指定多种类型,包括指定时间段、Cookie携带情况、Header携带情况、访问的域名地址、访问的方法、路径、参数、访问者IP等。也可以使用配置类进行配置,但是还是推荐直接配置文件,省事。
[!NOTE] TipsPath 要填写完整的api路径 包括统一的 RequestMapping 路径。
接着启动网关,搭载Arm架构芯片的Mac电脑可能会遇到这个问题:
这是因为没有找到适用于此架构的动态链接库,不影响使用,无视即可,希望以后的版本能修复吧。
可以看到,我们现在可以直接通过路由来访问我们的服务了:
注意此时依然可以通过原有的服务地址进行访问:
这样我们就可以将不需要外网直接访问的微服务全部放到内网环境下,而只依靠网关来对外进行交涉。
路由过滤器 路由过滤器支持以某种方式修改传入的 HTTP 请求或传出的 HTTP 响应,路由过滤器的范围是某一个路由,跟之前的断言一样,Spring Cloud Gateway 也包含许多内置的路由过滤器工厂,详细列表:https://docs.spring.io/spring-cloud-gateway/docs/current/reference/html/#gatewayfilter-factories
比如我们现在希望在请求到达时,在请求头中添加一些信息再转发给我们的服务,那么这个时候就可以使用路由过滤器来完成,我们只需要对配置文件进行修改:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 spring: application: name: gateway cloud: gateway: routes: - id: borrow-service uri: lb://borrowservice predicates: - Path=/borrow/** - id: book-service uri: lb://bookservice predicates: - Path=/book/** filters: - AddRequestHeader=Test, HelloWorld!
接着我们在BookController中获取并输出一下,看看是不是成功添加了:
1 2 3 4 5 6 7 8 9 10 11 12 13 @RestController public class BookController {@Resource @RequestMapping("/book/{bid}") findBookById (@PathVariable("bid") int bid, HttpServletRequest request) {"Test" ));return service.getBookById(bid);
现在我们通过Gateway访问我们的图书管理服务:
可以看到这里成功获取到由网关添加的请求头信息了。
除了针对于某一个路由配置过滤器之外,我们也可以自定义全局过滤器 ,它能够作用于全局 。但是我们需要通过代码的方式进行编写,比如我们要实现拦截没有携带指定请求参数的请求:
1 2 3 4 5 6 7 @Component public class TestFilter implements GlobalFilter {@Override public Mono<Void> filter (ServerWebExchange exchange, GatewayFilterChain chain) { return null ;
接着我们编写判断:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 @Override public Mono<Void> filter (ServerWebExchange exchange, GatewayFilterChain chain) {ServerHttpRequest request = exchange.getRequest();"test" );if (value != null && value.contains("1" )) {return chain.filter(exchange);else {return exchange.getResponse().setComplete();
可以看到结果:
成功实现规则判断和拦截操作。
当然,过滤器肯定是可以存在很多个的,所以我们可以手动指定过滤器之间的顺序:
1 2 3 4 5 6 7 @Component public class TestFilter implements GlobalFilter , Ordered { @Override public int getOrder () {return 0 ;
注意 Order 的值越小优先级越高 ,并且无论是在配置文件中编写的单个路由过滤器还是全局路由过滤器,都会受到Order值影响(单个路由的过滤器Order值按从上往下的顺序从1开始递增 ),最终是按照Order值决定哪个过滤器优先执行,当Order值一样 时 全局路由过滤器 执行 优于 单独的路由过滤器 执行。
SQL过滤器 Spring框架适用 :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 package com.ruoyi.gateway.filter; import com.ruoyi.common.core.utils.JsonUtils; import com.ruoyi.gateway.utils.WebFluxUtils; import lombok.extern.slf4j.Slf4j; import org.springframework.beans.factory.annotation.Value; import org.springframework.cloud.context.config.annotation.RefreshScope; import org.springframework.cloud.gateway.filter.GatewayFilterChain; import org.springframework.cloud.gateway.filter.GlobalFilter; import org.springframework.core.Ordered; import org.springframework.http.server.reactive.ServerHttpRequest; import org.springframework.stereotype.Component; import org.springframework.util.MultiValueMap; import org.springframework.web.server.ServerWebExchange; import reactor.core.publisher.Mono; import java.util.Objects; import java.util.regex.Pattern; @Slf4j @Component @RefreshScope public class GlobalSQLInjectFilter implements GlobalFilter , Ordered { @Value("${security.sql-injection.enable:true}") private Boolean enable; @Value("${security.sql-injection.regex}") private String regEx; private boolean bodyContainIllegalSQL (String jsonParam) { Pattern SQL_INJECTION_PATTERN = Pattern.compile(regEx, return Objects.requireNonNull(JsonUtils.parseMap(jsonParam)) instanceof String) boolean matches = SQL_INJECTION_PATTERN.matcher(String.valueOf(body.getValue())).matches(); if (matches) { "Potential SQL injection detected in request body: {}={}" , body.getKey(), body.getValue()); return matches; @Override public Mono<Void> filter (ServerWebExchange exchange, GatewayFilterChain chain) { if (!enable) { return chain.filter(exchange); ServerHttpRequest request = exchange.getRequest(); if (WebFluxUtils.isJsonRequest(exchange)) { String jsonParam = WebFluxUtils.resolveBodyFromCacheRequest(exchange); if (jsonParam == null ) { return Mono.error(new RuntimeException ("请求参数非法异常!" )); boolean containIllegalSQL = bodyContainIllegalSQL(jsonParam); if (containIllegalSQL) { "Potential SQL injection detected in request body: {}" , jsonParam); return Mono.error(new RuntimeException ("请求参数非法异常!" )); else { if (pathParamContainsSQLInjection(request.getQueryParams())) { "Potential SQL injection detected in query parameters: {}" , request.getQueryParams()); throw new IllegalArgumentException ("请求参数异常非法!" ); return chain.filter(exchange); private boolean pathParamContainsSQLInjection (MultiValueMap<String, String> params) { Pattern SQL_INJECTION_PATTERN = Pattern.compile(regEx, for (String key : params.keySet()) { for (String value : params.get(key)) { if (SQL_INJECTION_PATTERN.matcher(value).matches()) { return true ; return false ; @Override public int getOrder () { return Ordered.LOWEST_PRECEDENCE - 1 ;
Structs框架适用 :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 package csdc.tool.security; import java.io.BufferedReader; import java.io.IOException; import java.util.Enumeration; import javax.servlet.Filter; import javax.servlet.FilterChain; import javax.servlet.FilterConfig; import javax.servlet.ServletException; import javax.servlet.ServletRequest; import javax.servlet.ServletResponse; import javax.servlet.http.HttpServletRequest; import javax.servlet.http.HttpServletResponse; public class SqlFilter implements Filter { public void doFilter (ServletRequest request, ServletResponse response, FilterChain chain) throws IOException, ServletException { HttpServletRequest req = (HttpServletRequest) request; HttpServletResponse res = (HttpServletResponse) response; StringBuilder sql = new StringBuilder (); while (params.hasMoreElements()) { String name = params.nextElement().toString(); for (String s : value) { if (sql.length() > 0 ) { ";" ).append(s); else { if ("application/json" .equalsIgnoreCase(req.getContentType())) { StringBuilder jsonBody = new StringBuilder (); BufferedReader reader = req.getReader(); while ((line = reader.readLine()) != null ) { if (jsonBody.length() > 0 ) { ";" ).append(line); else { if (sqlValidate(sql.toString())) { "/error.jsp" ); else { protected static boolean sqlValidate (String str) { String badStr = "'|and|exec|execute|insert|select|delete|update|count|drop|chr|mid|master|truncate|char|declare|sitename|net user|xp_cmdshell|or|like" ; "\\|" ); for (String s : badStrs) { if (str.contains(s)) { ";匹配到SQL注入关键字:" + s); return true ; return false ; public void init (FilterConfig filterConfig) throws ServletException { public void destroy () {
在web.xml中配置拦截器
1 2 3 4 5 6 7 8 9 <filter > <filter-name > SqlFilter</filter-name > <filter-class > csdc.tool.security.SqlFilter</filter-class > </filter > <filter-mapping > <filter-name > SqlFilter</filter-name > <url-pattern > /*</url-pattern > </filter-mapping >
Config 配置中心 官方文档:https://docs.spring.io/spring-cloud-config/docs/current/reference/html/
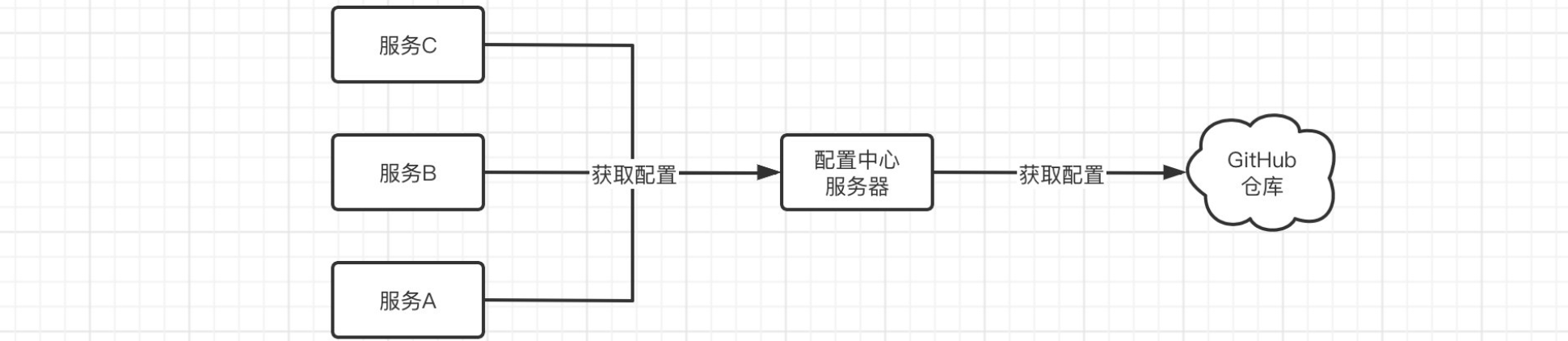
经过前面的学习,我们对于一个分布式应用的技术选型和搭建已经了解得比较多了,但是各位有没有发现一个问题,如果我们的微服务项目需要部署很多个实例,那么配置文件我们岂不是得一个一个去改,可能十几个实例还好,要是有几十个上百个呢?那我们一个一个去配置,岂不直接猝死在工位上。
所以,我们需要一种更加高级的集中化地配置文件管理工具,集中地对配置文件进行配置。
Spring Cloud Config 为分布式系统中的外部配置提供服务器端和客户端支持。使用 Config Server,您可以集中管理所有环境中应用程序的外部配置。
实际上Spring Cloud Config就是一个配置中心,所有的服务都可以从配置中心取出配置,而配置中心又可以从GitHub远程仓库中获取云端的配置文件,这样我们只需要修改GitHub中的配置即可对所有的服务进行配置管理了。
部署配置中心 这里我们接着创建一个新的项目,并导入依赖:
1 2 3 4 5 6 7 8 9 10 <dependencies > <dependency > <groupId > org.springframework.cloud</groupId > <artifactId > spring-cloud-config-server</artifactId > </dependency > <dependency > <groupId > org.springframework.cloud</groupId > <artifactId > spring-cloud-starter-netflix-eureka-client</artifactId > </dependency > </dependencies >
老规矩,启动类:
1 2 3 4 5 6 7 @SpringBootApplication @EnableConfigServer public class ConfigApplication {public static void main (String[] args) {
接着就是配置文件:
1 2 3 4 5 6 7 8 9 server: port: 8700 spring: application: name: configserver eureka: client: service-url: defaultZone: http://localhost:8801/eureka, http://localhost:8802/eureka
先启动一次看看,能不能成功:
这里我们以本地仓库为例(就不用GitHub了,卡到怀疑人生了),首先在项目目录下创建一个本地Git仓库,打开终端,在桌面上创建一个新的本地仓库:
然后我们在文件夹中随便创建一些配置文件,注意名称最好是{服务名称}-{环境}.yml:
然后我们在配置文件中,添加本地仓库的一些信息(远程仓库同理),详细使用教程:https://docs.spring.io/spring-cloud-config/docs/current/reference/html/#_git_backend
1 2 3 4 5 6 7 8 9 spring: cloud: config: server: git: uri: file://${user.home}/Desktop/config-repo default-label: main
然后启动我们的配置服务器,通过以下格式进行访问:
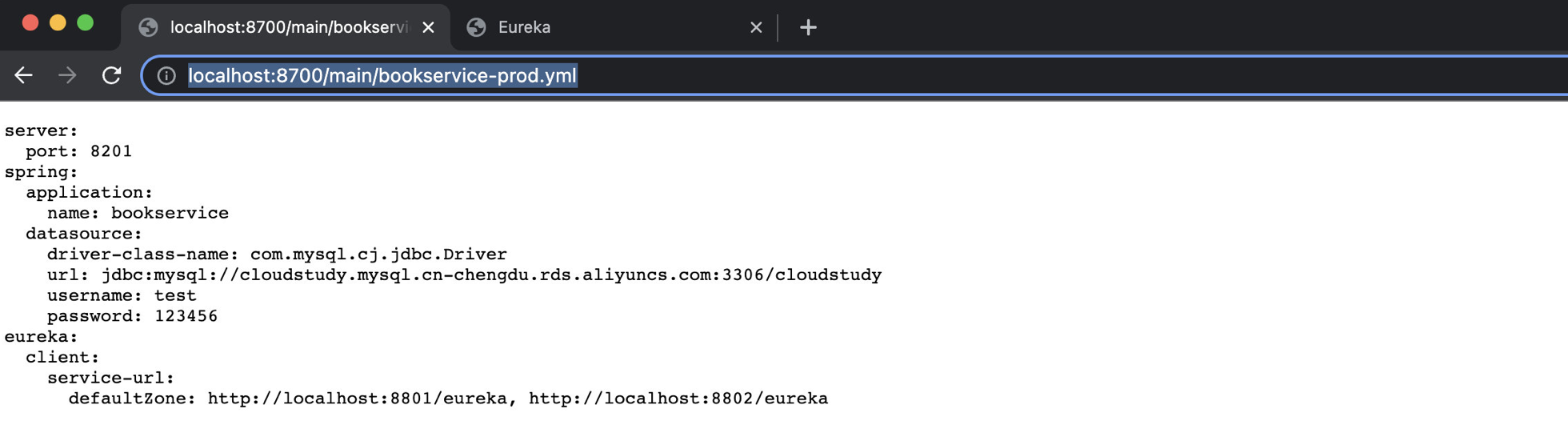
比如我们要访问图书服务的生产环境代码,可以使用 http://localhost:8700/bookservice/prod/main 链接,它会显示详细信息:
也可以使用 http://localhost:8700/main/bookservice-prod.yml 链接,它仅显示配置文件原文:
当然,除了使用Git来保存之外,还支持一些其他的方式,详细情况请查阅官网。
客户端配置 服务端配置完成之后,我们接着来配置一下客户端,那么现在我们的服务既然需要从服务器读取配置文件,那么就需要进行一些配置,我们删除原来的application.yml文件(也可以保留,最后无论是远端配置还是本地配置都会被加载),改用bootstrap.yml(在application.yml之前加载,可以实现配置文件远程获取):
1 2 3 4 5 6 7 8 9 <dependency > <groupId > org.springframework.cloud</groupId > <artifactId > spring-cloud-starter-config</artifactId > </dependency > <dependency > <groupId > org.springframework.cloud</groupId > <artifactId > spring-cloud-starter-bootstrap</artifactId > </dependency >
1 2 3 4 5 6 7 8 9 10 11 spring: cloud: config: name: bookservice uri: http://localhost:8700 profile: prod label: main
配置完成之后,启动图书服务:
可以看到已经从远端获取到了配置,并进行启动。
微服务CAP原则 经过前面的学习,我们对SpringCloud Netflix以及SpringCloud官方整个生态下的组件认识也差不多了,入门教学就到此为止,下一章将开启真正精彩的正片部分,本章的最后我们还是来了解一些理论上的知识。
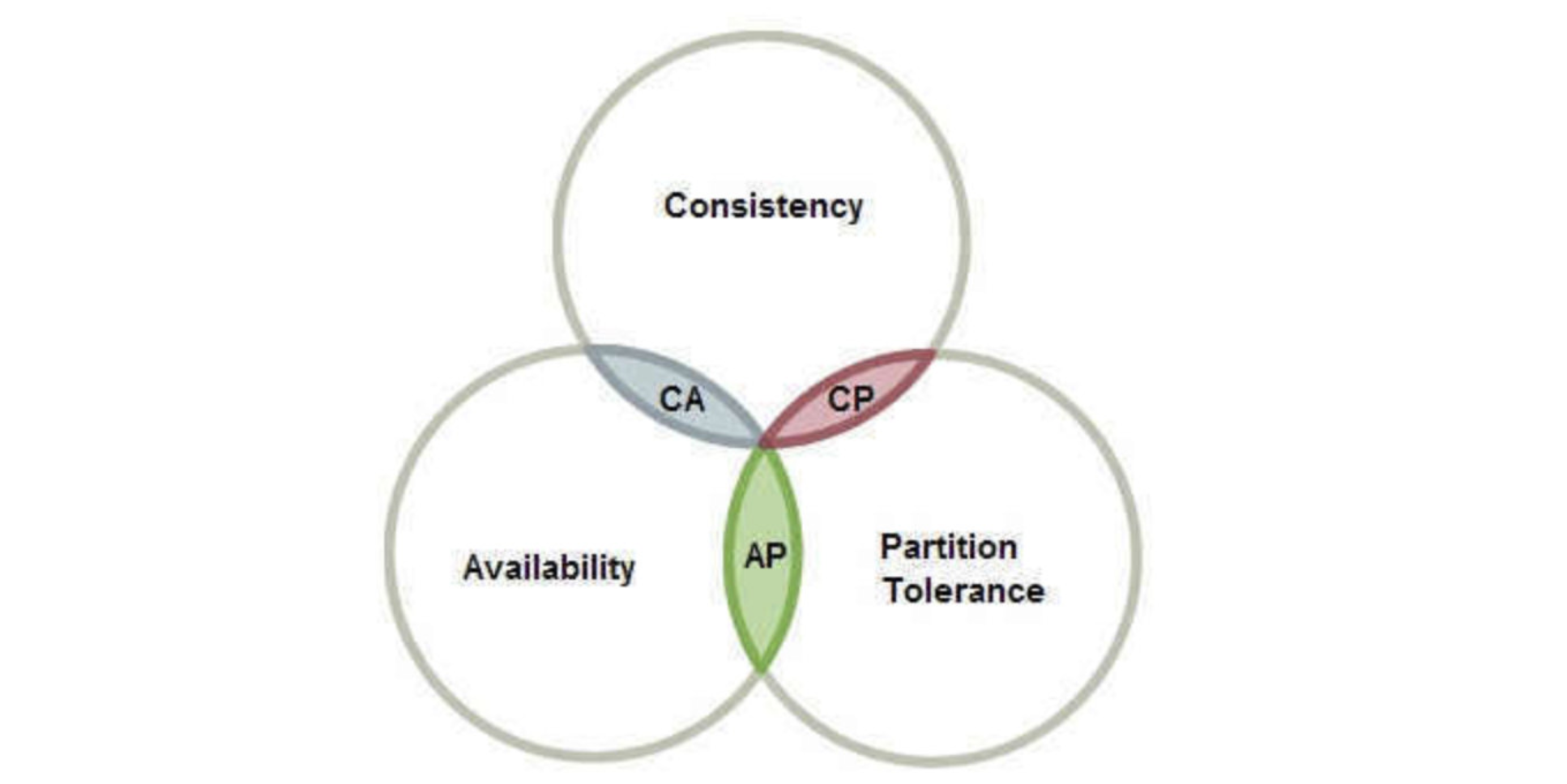
CAP原则又称CAP定理,指的是在一个分布式系统中,存在Consistency(一致性)、Availability(可用性)、Partition tolerance(分区容错性),三者不可同时保证,最多只能保证其中的两者。
一致性(C):在分布式系统中的所有数据备份,在同一时刻都是同样的值(所有的节点无论何时访问都能拿到最新的值)
可用性(A):系统中非故障节点收到的每个请求都必须得到响应(比如我们之前使用的服务降级和熔断,其实就是一种维持可用性的措施,虽然服务返回的是没有什么意义的数据,但是不至于用户的请求会被服务器忽略)
分区容错性(P):一个分布式系统里面,节点之间组成的网络本来应该是连通的,然而可能因为一些故障(比如网络丢包等,这是很难避免的),使得有些节点之间不连通了,整个网络就分成了几块区域,数据就散布在了这些不连通的区域中(这样就可能出现某些被分区节点存放的数据访问失败,我们需要来容忍这些不可靠的情况)
总的来说,数据存放的节点数越多,分区容忍性就越高,但是要复制更新的次数就越多,一致性就越难保证。同时为了保证一致性,更新所有节点数据所需要的时间就越长,那么可用性就会降低。
所以说,只能存在以下三种方案:
AC 可用性+一致性 要同时保证可用性和一致性,代表着某个节点数据更新之后,需要立即将结果通知给其他节点,并且要尽可能的快,这样才能及时响应保证可用性,这就对网络的稳定性要求非常高,但是实际情况下,网络很容易出现丢包等情况,并不是一个可靠的传输,如果需要避免这种问题,就只能将节点全部放在一起,但是这显然违背了分布式系统的概念,所以对于我们的分布式系统来说,很难接受。
CP 一致性+分区容错性 为了保证一致性,那么就得将某个节点的最新数据发送给其他节点,并且需要等到所有节点都得到数据才能进行响应,同时有了分区容错性,那么代表我们可以容忍网络的不可靠问题,所以就算网络出现卡顿,那么也必须等待所有节点完成数据同步,才能进行响应,因此就会导致服务在一段时间内完全失效,所以可用性是无法得到保证的。
AP 可用性+分区容错性 既然CP可能会导致一段时间内服务得不到任何响应,那么要保证可用性,就只能放弃节点之间数据的高度统一,也就是说可以在数据不统一的情况下,进行响应,因此就无法保证一致性了。虽然这样会导致拿不到最新的数据,但是只要数据同步操作在后台继续运行,一定能够在某一时刻完成所有节点数据的同步,那么就能实现最终一致性 ,所以AP实际上是最能接受的一种方案。
比如我们实现的Eureka集群,它使用的就是AP方案,Eureka各个节点都是平等的,少数节点挂掉不会影响正常节点的工作,剩余的节点依然可以提供注册和查询服务。而Eureka客户端在向某个Eureka服务端注册时如果发现连接失败,则会自动切换至其他节点。只要有一台Eureka服务器正常运行,那么就能保证服务可用(A),只不过查询到的信息可能不是最新的 (C)
细节要点
分模块开发时,不同模块存在依赖的实体、工具类 等,将其抽取出来放到一个公共模块(commons) 里,哪里需要用就将该模块作为依赖导入配置文件 中即可。
添加全参构造后也要添加无参构造 ,因为默认不添加时是有无参构造 的,否则容易后续发生问题。
Reference 1 2 3 4 url: https://itbaima.net/
柏码 - 让每一行代码都闪耀智慧的光芒!