后端开发学习
本文最后更新于:5 个月前
1 Java 基础
1.1 变量
从小到大自动转,从大到小强制转(精度丢失,值可能不正确)
Java 中进行二元与运算类型的提升规则
- 整数运算: 如果两个操作数有一个为 long,则结果也为 long;没有 long 时,结果为 int。即使操作数全为 short、byte,结果也是 int。
- 浮点运算: 如果两个操作数有一个为 double,则结果为 double;只有两个操作数都是 float,则结果才为 float。注意:int 与 float 运算,结果为 float。
1.2 命名规则
- 变量命名只能使用字母数字 $ _
- 变量第一个字符只能使用字母 $ _
- 变量第一个字符不能使用数字,不能使用关键字
注:_ 是下划线,不是-减号或者—— 破折号
java 关键字:


### 1.3 final 修饰词
当形参被 final 修饰时不能对形参再次赋值,如果形参是对象可以改变内部的属性
1. final 修饰类
- 当 final 修饰类时,该类无法被继承
2. final 修饰方法
- 被 final 修饰的方法不能被重写
3. final 修饰基本类型变量
- 当一个变量被 final 修饰的时候,该变量只有一次赋值的机会
4. final 修饰引用
- 被 final 修饰的引用只能指向一次对象
5. final 修饰常量
- 常量值不变
1.4 操作符 Scanner
使用 Scanner 类,需要在最前面加上import java.util.Scanner;
如果在通过
nextInt()读取了整数后,再接着读取字符串,读出来的是回车换行: “\r\n”, 因为 nextInt 仅仅读取数字信息,而不会读取回车换行”\r\n”.
所以,如果在业务上需要读取了整数后,接着读取字符串,那么就应该**连续执行两次 nextLine ()**,第一次是取走回车换行,第二次才是读取真正的字符串
1 | |
1.5 数组
数组是一个固定长度,包含了相同类型数据的容器int[] a; 和 int a[] 都声明了一个数组变量,仅仅声明并没有创建分配空间。
创建一个长度是 5 的数组,并且使用引用 a 指向该数组,a 是一个地址,占据 4 个字节a = new int[5];
常用方法:
1 | |
eg:
1 | |
[!NOTE]
分配空间,同时赋值
写法一: 分配空间同时赋值int[] a = new int[]{100,102,444,836,3236};写法二: 省略了 new int[], 效果一样
int[] b = {100,102,444,836,3236};
数组排序:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
import java.util.Arrays;
public class MySort {
int [] a;
MySort(int []array ){
this.a = array;
}
public void ChoseSort(int [] array){
for (int i = 0; i < array.length; i++) {
for (int j = i+1; j < array.length; j++) {
if (array[i]> array[j]) {
int temp = array[i];
array[i] = array[j];
array[j] = temp;
}
}
}
}
public void BubbleSort(int [] array){
for (int i = 0; i < array.length; i++) {
for (int j = 0; j < array.length-1-i; j++) {
if (array[j]> array[j+1]) {
int temp = array[j];
array[j] = array[j+1];
array[j+1] = temp;
}
}
}
}
public static void main(String[] args) {
MySort sort = new MySort(new int[]{1, 3, 4, 6, 2, 7, 8, 5, 9, 10});
sort.ChoseSort(sort.a);
sort.BubbleSort(sort.a);
System.out.println(Arrays.toString(sort.a));
}
}
增强型 for 循环遍历
1
2
3
for (int each : values) {
System.out.println (each);
}
#### 1.5.1 二维数组
1
2
3
4
5
6
7
8
9
10
11
12
13
//初始化二维数组,
int[][] a = new int[2][3]; //有两个一维数组,每个一维数组的长度是3
a[1][2] = 5; //可以直接访问一维数组,因为已经分配了空间
//只分配了二维数组
int[][] b = new int[2][]; //有两个一维数组,每个一维数组的长度暂未分配
b[0] =new int[3]; //必须事先分配长度,才可以访问
b[0][2] = 5;
//指定内容的同时,分配空间
int[][] c = new int[][]{
{1,2,4},
{4,5},
{6,7,8,9}
};
### 1.6 类和对象
#### 1.6.1 引用
引用的概念,如果一个变量的类型是类类型,而非基本类型,那么该变量又叫做引用。
Hero h = new Hero();
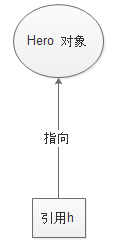
> 引用 h 指向 Hero 对象
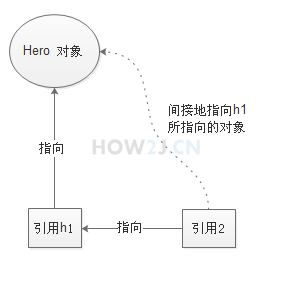
> 多个引用指向同一个对象
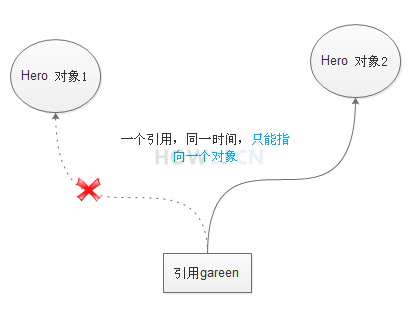
> 一个引用只能指向一个对象
### 1.7 包 (package)
- 把比较接近的类,规划在同一个包下
- 在最开始的地方声明该类所处于的包名
- 使用同一个包下的其他类,直接使用即可
- 但是要使用其他包下的类,必须 import
### 1.8 访问修饰符
成员变量有四种修饰符:
1. private 私有的
2. package/friendly/default 不写
3. protected 受保护的
4. public 公共的



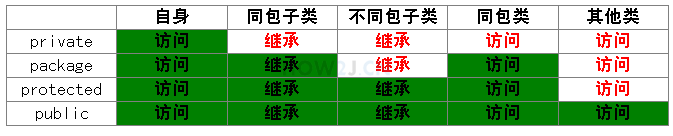
> [!NOTE]
> 那么什么情况该用什么修饰符呢?
> 从作用域来看,public 能够使用所有的情况。但是大家在工作的时候,又不会真正全部都使用 public, 那么到底什么情况该用什么修饰符呢?
>
> 1. 属性通常使用 private 封装起来
> 2. 方法一般使用 public 用于被调用
> 3. 会被子类继承的方法,通常使用 protected
> 4. package 用的不多,一般新手会用 package, 因为还不知道有修饰符这个东西
>
> 再就是作用范围最小原则
> 简单说,能用 private 就用 private,不行就放大一级,用 package, 再不行就用 protected,最后用 public。这样就能把数据尽量的封装起来,没有必要露出来的,就不用露出来了
### 1.9 类属性(static 变量)
1. 当一个属性被 static 修饰的时候,就叫做类属性,又叫做静态属性
2. 当一个属性被声明成类属性,那么所有的对象,都共享一个值
访问方式:
1. 对象. 类属性
2. 类. 类属性
对象属性初始化:
1. 声明该属性的时候初始化
2. 构造方法中初始化
3. 初始化块
静态属性初始化:
1. 声明该属性的时候初始化
2. 静态初始化块
> 初始化顺序:静态属性声明>静态初始化块>对象属性声明>对象属性初始化块>构造方法
### 1.10 类方法(static 方法)
- 类方法: 又叫做静态方法
- 对象方法: 又叫实例方法,非静态方法
> 访问一个对象方法,必须建立在有一个对象的前提的基础上
> 访问类方法,不需要对象的存在,直接就访问
> 静态方法只能调用静态方法和静态属性,不能调用对象属性和方法
### 1.11 单例模式
单例模式又叫做 Singleton 模式,指的是一个类,在一个 JVM 里,只有一个实例存在。
单例模式的设计目的是确保一个类只有一个实例,并提供全局访问点以供其他对象使用。因此,在传统的单例模式中,不允许继承该类,因为继承会导致类的实例数量增多。
#### 1.11.1 饿汉式单例模式
单例模式的类应该只有一个示例,通过私有化其构造方法,使得外部无法通过 new 得到新的实例。
这种单例模式又叫做饿汉式单例模式,无论如何都会创建一个实例
1
2
3
4
5
6
7
8
9
10
11
12
package charactor;
public class GiantDragon {
//私有化构造方法使得该类无法在外部通过new 进行实例化
private GiantDragon(){
}
//准备一个类属性,指向一个实例化对象。 因为是类属性,所以只有一个
private static GiantDragon instance = new GiantDragon();
//public static 方法,提供给调用者获取12行定义的对象
public static GiantDragon getInstance(){
return instance;
}
}
#### 1.11.2 懒汉式单例模式
懒汉式单例模式与饿汉式单例模式不同,只有在调用 getInstance 的时候,才会创建实例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
package charactor;
public class GiantDragon {
//私有化构造方法使得该类无法在外部通过new 进行实例化
private GiantDragon(){
}
//准备一个类属性,用于指向一个实例化对象,但是暂时指向null
private static GiantDragon instance;
//public static 方法,返回实例对象
public static GiantDragon getInstance(){
//第一次访问的时候,发现instance没有指向任何对象,这时实例化一个对象
if(null==instance){
instance = new GiantDragon();
}
//返回 instance指向的对象
return instance;
}
}
> [!NOTE]
> 什么时候使用饿汉式,什么时候使用懒汉式?
> 饿汉式,是立即加载的方式,无论是否会用到这个对象,都会加载。
> 如果在构造方法里写了性能消耗较大,占时较久的代码,比如建立与数据库的连接,那么就会在启动的时候感觉稍微有些卡顿。
>
> 懒汉式,是延迟加载的方式,只有使用的时候才会加载。并且有线程安全的考量 (鉴于同学们学习的进度,暂时不对线程的章节做展开)。
> 使用懒汉式,在启动的时候,会感觉到比饿汉式略快,因为并没有做对象的实例化。但是在第一次调用的时候,会进行实例化操作,感觉上就略慢。
>
> 看业务需求,如果业务上允许有比较充分的启动和初始化时间,就使用饿汉式,否则就使用懒汉式
#### 1.11.3 单例模式的三要素
什么是单例模式?
1. 构造方法私有化
2. 静态属性指向实例
3. public static 的 getInstance 方法,返回第二步的静态属性
### 1.12 枚举(enum)
枚举 enum 是一种特殊的类 (还是类),使用枚举可以很方便的定义常量
eg:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
public enum Season {
SPRING,SUMMER,AUTUMN,WINTER
}
public class HelloWorld {
public static void main(String[] args) {
Season season = Season.SPRING;
switch (season) {
case SPRING:
System.out.println("春天");
break;
case SUMMER:
System.out.println("夏天");
break;
case AUTUMN:
System.out.println("秋天");
break;
case WINTER:
System.out.println("冬天");
break;
}
}
}
借助增强型 for 循环,可以很方便的遍历一个枚举都有哪些常量:
1
2
3
4
5
6
7
public class HelloWorld {
public static void main(String[] args) {
for (Season s : Season.values()) {
System.out.println(s);
}
}
}
1 | |
1 | |
1 | |
1 | |
1 | |
1 | |
1 | |
1.13 接口与继承
1.13.1 接口
接口就像是一种约定,对类进行约束规范,便于顶层设计规范化
eg:
1
2
3
4
5
6
7
8
9
10
11
12
package MyCharacter;
public interface Healer {
void heal(int healAmount);
}
package MyCharacter;
public class Support extends Hero implements Healer {
@Override
public void heal(int healAmount) {
this.setHp(this.getHp() + healAmount);
System.out.println("当前英雄的血量为" + this.getHp() + "点");
}
}
#### 1.13.2 对象转型
##### 1.13.2.1 子类转父类(向上转型)
引用类型和对象类型不一致时,需要进行类型转换,类型转换有时候会成功,有时候会失败。
转换是否成功判别方法:把右边的当做左边来用,看是否能说通
> 子类向父类转型(向上转型)一般都是可以的,父类引用指向子类对象
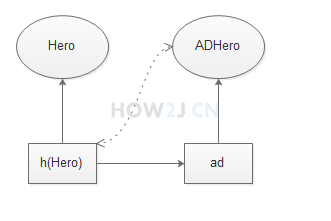
##### 1.13.2.2 父类转子类 (向下转型)
父类转子类,有的时候行,有的时候不行,所以必须进行强制转换。强制转换的意思就是转换有风险,风险自担。
转换总结:
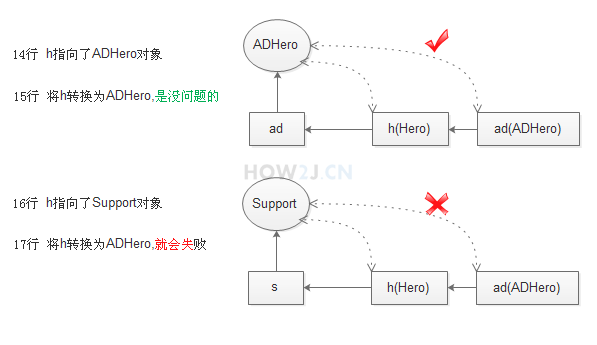
> 10 行: 把 ad 当做 Hero 使用,一定可以,转换之后,h 引用指向一个 ad 对象
> 11 行: h 引用有可能指向一个 ad 对象,也有可能指向一个 support 对象,所以把 h 引用转换成 AD 类型的时候,就有可能成功,有可能失败,因此要进行强制转换,换句话说转换后果自负,到底能不能转换成功,要看引用 h 到底指向的是哪种对象
> 在这个例子里,h 指向的是一个 ad 对象,所以转换成 ADHero 类型,是可以的
> 12 行:把一个 support 对象当做 Hero 使用,一定可以,转换之后,h 引用指向一个 support 对象
> 13 行:这个时候,h 指向的是一个 support 对象,所以转换成 ADHero 类型,会失败。失败的表现形式是抛出异常 ClassCastException 类型转换异常
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
package charactor;
import charactor1.Support;
public class Hero {
public String name;
protected float hp;
public static void main(String[] args) {
Hero h =new Hero();
ADHero ad = new ADHero();
Support s =new Support();
h = ad;
ad = (ADHero) h;
h = s;
ad = (ADHero)h;
}
}
> [!NOTE]
> 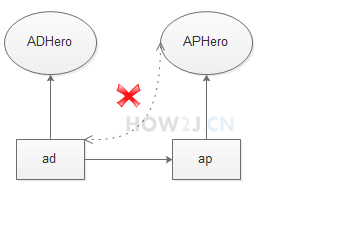
> 没有继承关系的两个类,互相转换一定会失败,抛出异常
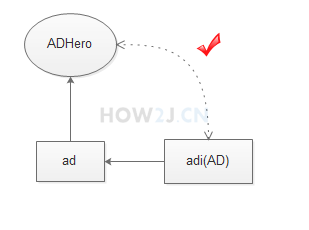
##### 1.13.2.3 实现类转换成接口 (向上转型)
类似于子类转父类,一样可行。
1
2
3
4
5
6
7
8
9
package charactor;
public class Hero {
public String name;
protected float hp;
public static void main(String[] args) {
ADHero ad = new ADHero();
AD adi = ad;
}
}
##### 1.13.2.4 接口转换成实现类 (向下转型)
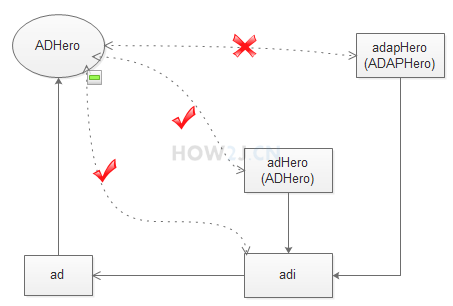
> 7 行: ad 引用指向 ADHero,而 adi 引用是接口类型:AD,实现类转换为接口,是向上转型,所以无需强制转换,并且一定能成功
> 8 行: adi 实际上是指向一个 ADHero 的,所以能够转换成功
> 9 行: adi 引用所指向的对象是一个 ADHero,要转换为 ADAPHero 就会失败。
1
2
3
4
5
6
7
8
9
10
11
12
package charactor;
public class Hero {
public String name;
protected float hp;
public static void main(String[] args) {
ADHero ad = new ADHero();
AD adi = ad;
ADHero adHero = (ADHero) adi;
ADAPHero adapHero = (ADAPHero) adi;
adapHero.magicAttack();
}
}
##### 1.13.2.5 instanceof
a instanceof className 判断一个引用所指向的对象,是否是类的对象,或者子类的对象。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
package charactor;
public class Hero {
public String name;
protected float hp;
public static void main(String[] args) {
ADHero ad = new ADHero();
APHero ap = new APHero();
Hero h1= ad;
Hero h2= ap;
//判断引用h1指向的对象,是否是ADHero类型
System.out.println(h1 instanceof ADHero);
//判断引用h2指向的对象,是否是APHero类型
System.out.println(h2 instanceof APHero);
//判断引用h1指向的对象,是否是Hero的子类型
System.out.println(h1 instanceof Hero);
}
}
#### 1.13.3 重写
子类可以继承父类的对象方法,在继承后,重复提供该方法,就叫做方法的重写,又叫覆盖 override
> 调用子类的方法首先调用重写的方法,如果没有再调用父类方法。
1 | |
1 | |
1 | |
1 | |
1 | |
1.13.4 多态
操作符的多态
+ 可以作为算数运算,也可以作为字符串连接
类的多态
- 父类引用指向子类对象
1.13.4.1 操作符多态
1 | |
1.13.4.2 类多态
父类引用指向子类,调用父类引用被重写的方法,优先执行指向的子类的重写方法,即同类型调用同一方法,呈现不同的状态。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
package property;
public class Item {
String name;
int price;
public void buy(){
System.out.println("购买");
}
public void effect() {
System.out.println("物品使用后,可以有效果 ");
}
public static void main(String[] args) {
Item i1= new LifePotion();
Item i2 = new MagicPotion();
System.out.print("i1是Item类型,执行effect打印:");
i1.effect();
System.out.print("i2也是Item类型,执行effect打印:");
i2.effect();
}
}
> [!NOTE] 类的多态条件
> 1. 父类(接口)引用指向子类对象
> 2. 调用重写的方法
##### 1.13.4.3 使用类多态 VS 不使用类多态
不使用:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
package charactor;
import property.LifePotion;
import property.MagicPotion;
public class Hero {
public String name;
protected float hp;
public void useLifePotion(LifePotion lp){
lp.effect();
}
public void useMagicPotion(MagicPotion mp){
mp.effect();
}
public static void main(String[] args) {
Hero garen = new Hero();
garen.name = "盖伦";
LifePotion lp =new LifePotion();
MagicPotion mp =new MagicPotion();
garen.useLifePotion(lp);
garen.useMagicPotion(mp);
}
}
使用:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
package charactor;
import property.Item;
import property.LifePotion;
import property.MagicPotion;
public class Hero {
public String name;
protected float hp;
public void useItem(Item i){
i.effect();
}
public static void main(String[] args) {
Hero garen = new Hero();
garen.name = "盖伦";
LifePotion lp =new LifePotion();
MagicPotion mp =new MagicPotion();
garen.useItem(lp);
garen.useItem(mp);
}
}
> 由此可知,使用类多态可以简化设计,减少冗余的相同逻辑方法的设计实现,提高开发效率。
##### 1.13.4.4 练习
- immortal 是不朽的,不死的意思
- mortal 就是终有一死的,凡人的意思
> 1. 设计一个接口
> 接口叫做 Mortal, 其中有一个方法叫做 die
> 2. 实现接口
> 分别让 ADHero, APHero, ADAPHero 这三个类,实现 Mortal 接口,不同的类实现 die 方法的时候,都打印出不一样的字符串
> 3. 为 Hero 类,添加一个方法, 在这个方法中调用 m 的 die 方法。
> public void kill (Mortal m)
> 4. 在主方法中
> 首先实例化出一个 Hero 对象: 盖伦
> 然后实例化出 3 个对象,分别是 ADHero, APHero, ADAPHero 的实例
> 然后让盖伦 kill 这 3 个对象
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
//Hero
package MyCharacter;
public class Hero {
private String name;
private float hp;
private int armor;
public static void main(String[] args) {
Hero garLen = new Hero();
garLen.setName("Garlen");
ADHero adHero = new ADHero();
adHero.setName("ADHero");
APHero apHero = new APHero();
apHero.setName("APHero");
ADAPHero adapHero = new ADAPHero();
adapHero.setName("ADAPHero");
garLen.kill(adHero, apHero, adapHero);
}
public void kill(Mortal... ms) {
for (Mortal m : ms) {
m.die();
}
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public float getHp() {
return hp;
}
public void setHp(float hp) {
this.hp = hp;
}
public int getArmor() {
return armor;
}
public void setArmor(int armor) {
this.armor = armor;
}
}
//Mortal
package MyCharacter;
public interface Mortal {
void die();
}
//ADHero
package MyCharacter;
public class ADHero extends Hero implements AD, Mortal {
@Override
public void physicAttack() {
System.out.println("ADHero 物理攻击");
}
@Override
public void die() {
System.out.println(this.getName() + "阵亡");
}
}
//APHero
package MyCharacter;
public class APHero extends Hero implements AP, Mortal {
@Override
public void magicAttack() {
System.out.println("AP Hero magic attack!");
}
@Override
public void die() {
System.out.println(this.getName() + "阵亡");
}
}
//ADAPHero
package MyCharacter;
public class ADAPHero extends Hero implements AD, AP, Mortal {
@Override
public void physicAttack() {
System.out.println("进行物理攻击");
}
@Override
public void magicAttack() {
System.out.println("进行魔法攻击");
}
@Override
public void die() {
System.out.println(this.getName() + "阵亡");
}
}
1 | |
1 | |
1 | |
1 | |
1.13.5 隐藏
与重写类似,方法的重写是子类覆盖父类的对象方法,隐藏,就是子类覆盖父类的类方法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
//父类
package MyCharacter;
public class Hero {
private String name;
private float hp;
private int armor;
public static void battle() {
System.out.println("Hero battleWin");
}
}
//子类隐藏父类的类方法
package MyCharacter;
public class ADHero extends Hero implements AD, Mortal {
//隐藏父类的battleWin方法
public static void battle() {
System.out.println("ad hero battle win");
}
public static void main(String[] args) {
Hero.battle();
ADHero.battle();
}
@Override
public void physicAttack() {
System.out.println("ADHero 物理攻击");
}
@Override
public void die() {
System.out.println(this.getName() + "阵亡");
}
}
> [!NOTE] 父类引用指向子类调用隐藏方法(类方法不存在多态)?
> 在 Java 中,对于类方法(静态方法),编译时会根据引用类型(即变量类型)来决定调用的方法。实际上,类方法并不具有多态性,也不会被子类的重写所影响。由于 h 是父类类型的引用,即使它指向一个子类对象(ADHero),编译器仍然会根据引用类型(Hero)来决定调用的方法。
#### 1.13.6 super
实例化子类对象时,其父类的构造方法也会被调用,并且是父类构造方法先调用,子类构造方法会默认调用父类的无参的构造方法
(1)使用关键字 super 显式调用父类带参的构造方法
1
2
3
4
public ADHero(String name){
super(name);
System.out.println("AD Hero的构造方法");
}
(2)通过 super 调用父类属性
1
2
3
public int getMoveSpeed2(){
return super.moveSpeed;
}
(3)通过 super 调用父类方法
1
2
3
4
5
// 重写useItem,并在其中调用父类的userItem方法
public void useItem(Item i) {
System.out.println("adhero use item");
super.useItem(i);
}
1 | |
1 | |
1 | |
1 | |
1.13.7 Object 超类
Object 类是所有类的父类,即基类,声明一个类的时候,默认是继承了 Object
1. Object 类提供一个 toString 方法,所以所有的类都有 toString 方法
toString ()的意思是返回当前对象的字符串表达
2. 当一个对象没有任何引用指向它的时候,它就满足垃圾回收的条件,当它被垃圾回收的时候,它的 finalize () 方法就会被调用。finalize () 不是开发人员主动调用的方法,而是由虚拟机 JVM 调用的。
3. equals () 用于判断两个对象的内容是否相同,假设,当两个英雄的 hp 相同的时候,我们就认为这两个英雄相同
4. == 这不是 Object 的方法,但是用于判断两个对象是否相同,更准确的讲,用于判断两个引用,是否指向了同一个对象
5. hashCode 方法返回一个对象的哈希值,但是在了解哈希值的意义之前,讲解这个方法没有意义。
6. Object 还提供线程同步相关方法:wait (),notify (),notifyAll ()
7. getClass ()会返回一个对象的类对象,属于反射原理。
1.13.8 抽象类
在类中声明一个方法,这个方法没有方法体,是一个“空”方法,这样的方法就叫抽象方法,使用修饰符“abstract“,当一个类有抽象方法的时候,该类必须被声明为抽象类,不能被实例化。
抽象类可以没有抽象方法,也可以有具体方法
[!NOTE] 抽象类和接口的区别
- 区别 1:
- 子类只能继承一个抽象类,不能继承多个
- 子类可以实现多个接口
- 区别 2:
- 抽象类可以定义 public, protected, package, private 静态和非静态属性,final 和非 final 属性
- 但是接口中声明的属性,只能是 public 静态 final 的,即便没有显式的声明
注: 抽象类和接口都可以有实体方法。 接口中的实体方法,叫做默认方法
1.13.9 内部类
分类:
- 非静态内部类
- 静态内部类
- 匿名类
- 本地类
1.13.9.1 非静态内部类
非静态内部类可以直接在一个类里面定义,当外部类对象存在时内部类才有意义。
语法: new 外部类().new 内部类()
1 | |
1.13.9.2 静态内部类
与非静态内部类不同,静态内部类水晶类的实例化不需要一个外部类的实例为基础,可以直接实例化
语法:new 外部类.静态内部类();
因为没有一个外部类的实例,所以在静态内部类里面不可以访问外部类的实例属性和方法,除了可以访问外部类的私有静态成员外,静态内部类和普通类没什么大的区别
1 | |
1.13.9.3 匿名类
匿名类指的是在声明一个类的同时实例化它,使代码更加简洁精练
通常情况下,要使用一个接口或者抽象类,都必须创建一个子类
有的时候,为了快速使用,直接实例化一个抽象类,并“当场”实现其抽象方法。
既然实现了抽象方法,那么就是一个新的类,只是这个类,没有命名。这样的类,叫做匿名类
1 | |
在匿名类中使用外部的局部变量,外部的局部变量必须修饰为 final,否则报错(jdk 8 中不需要强制用 final 修饰,因为编译器会自动加上)
1 | |
1.13.9.4 本地类
本地类可以理解为有名字的匿名类
内部类与匿名类不一样的是,内部类必须声明在成员的位置,即与属性和方法平等的位置。本地类和匿名类一样,直接声明在代码块里面,可以是主方法,for 循环里等等地方
1 | |
1.13.10 默认方法
jdk 8 新特性,指接口也可以提供具体方法,不单单只能提供抽象方法
Mortal 这个接口,增加了一个默认方法 revive,这个方法有实现体,并且必须被声明为 default,实现接口功能扩展。
1 | |
1.13.11 UML
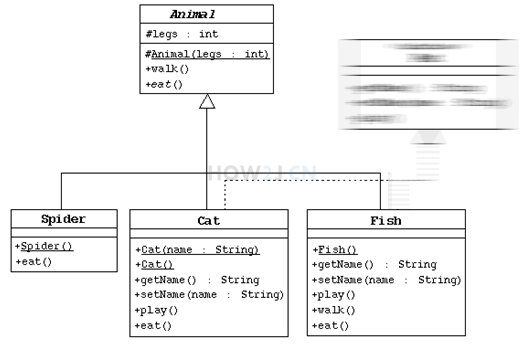
UML-Unified Module Language 统一建模语言,可以很方便的用于描述类的属性,方法,以及类和类之间的关系。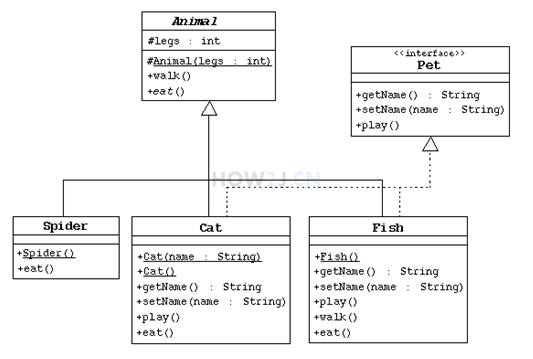
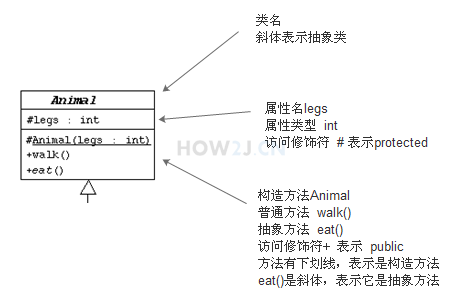
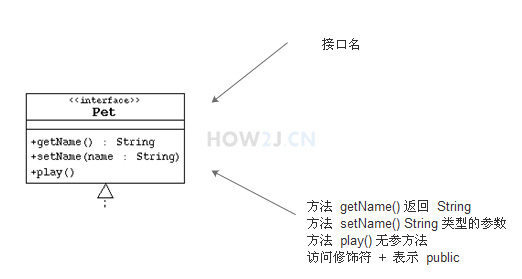
带箭头的实线,表示 Spider,Cat, Fish 都继承于 Animal 这个父类.
表示 Fish 实现了 Pet 这个接口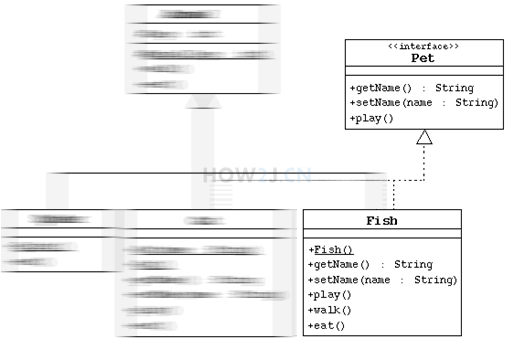
1.14 数字与字符串
1.14.1 封装类
数字封装类有
Byte, Short, Integer, Long, Float, Double
这些类都是抽象类Number的子类
1 | |
- 自动装箱:
- 不需要调用构造方法,通过
=符号自动把基本类型转换为类类型就叫装箱 int i = 5;//自动转换就叫装箱 Integer it 2 = i;
- 不需要调用构造方法,通过
- 自动拆箱
- 不需要调用 Integer 的 intValue 方法,通过=就自动转换成 int 类型,就叫拆箱
int i = 5; Integer it = new Integer (i);//封装类型转换成基本类型 int i 2 = it. intValue ();//自动转换就叫拆箱 int i 3 = it;
- int 的最大值可以通过其对应的封装类 Integer. MAX_VALUE 获取
- int 的最小值可以通过其对应的封装类 Integer. MIN_VALUE 获取
1.14.2 字符串转换
1.14.2.1 数字转字符串
- 方法 1: 使用 String 类的静态方法 valueOf
- 方法 2: 先把基本类型装箱为对象,然后调用对象的toString
1
2
3
4
5
6
7
8
9
10
11package NumberString;
public class NumToStr {
public static void main (String[] args) {
int i = 10;
// 方法 1
String s 1 = String.valueOf (i);
// 方法 2
Integer i 1 = i;
String s 2 = i 1.toString ();
}
}
1.14.2.2 字符串转数字
调用 Integer 的静态方法 parseIntint i 3 = Integer.parseInt (s 1);
1.14.3 数学 Math 包
java. lang. Math 提供了一些常用的数学运算方法,并且都是以静态方法的形式存在
四舍五入, 随机数,开方,次方,π,自然常数:
1 | |
1.14.4 格式化输出
如果不使用格式化输出,就需要进行字符串连接,如果变量比较多,拼接就会显得繁琐
使用格式化输出,就可以简洁明了
- %s 表示字符串
- %d 表示数字
- %n 表示换行
printf 和 format 格式化输出效果一样,printf 中调用了 format1
2
3
4
5
6
7
8//使用格式化输出
//%s 表示字符串,%d 表示数字,%n 表示换行
String name = "亚瑟";
String sentenceFormat = "%s 在进行了连续 %d 次击杀后,获得了 %s 的称号%n";
int kill = 1;
String title = "超神";
System. out. printf (sentenceFormat, name, kill, title);
System. out. format (sentenceFormat, name, kill, title); - 换行符就是另起一行 — ‘\n’ 换行(newline)
- 回车符就是回到一行的开头 — ‘\r’ 回车(return)
1.14.5 immutable
immutable 是指不可改变的, 比如创建了一个字符串对象, String garen =”盖伦”;
不可改变的具体含义是指:
- 不能增加长度
- 不能减少长度
- 不能插入字符
- 不能删除字符
- 不能修改字符
一旦创建好这个字符串,里面的内容永远不能改变, String 的表现就像是一个常量
1.14.6 字符串常用方法
| 方法名 | 简介 | |
|---|---|---|
| charAt | 获取字符 | |
| toCharArray | 获取对应的字符数组 | |
| subString | 截取子字符串 | |
| split | 分隔 | |
| trim | 去掉首尾空格 | |
| toLowerCase toUpperCase |
大小写 | |
| indexOf lastIndexOf contains |
定位 | |
| replaceAll replaceFirst |
替换 |
1.14.7 比较字符串
- 是否是同一个对象
==用于用于判断两个字符串对象是否相同(不是内容是否相同)特例:str 3 与 str 1 内容完全一样,复用之前的对象并未创建新 String 对象1
2
3
4String str 1 = "the light";
String str 2 = new String (str 1);
//==用于判断是否是同一个字符串对象
System. out. println ( str 1 == str 2);1
2
3String str 1 = "the light";
String str 3 = "the light";
System. out. println ( str 1 == str 3); - 是否内容相同
使用 equals 进行字符串内容的比较,必须大小写一致
equalsIgnoreCase,忽略大小写判断内容是否一致1
2System. out. println (str 1. equals (str 3));//大小写不一样,返回 false
System. out. println (str 1. equalsIgnoreCase (str 3));//忽略大小写的比较,返回 true - 是否以子字符串开始或者结束
startsWith //以… 开始,endsWith //以… 结束
1.14.8 StringBuffer
StringBuffer 是可变长的字符串
| 关键字 | 描述 | |
|---|---|---|
| append delete insert reverse | 追加删除插入反转 | |
| length capacity | 长度容量 |
1 | |
StringBuffer 性能明显优于字符串拼接
1.15 日期
时间原点概念:
所有的数据类型,无论是整数,布尔,浮点数还是字符串,最后都需要以数字的形式表现出来。
日期类型也不例外,换句话说,一个日期,比如 2020 年 10 月 1 日,在计算机里,会用一个数字来代替。
那么最特殊的一个数字,就是零. 零这个数字,就代表 Java 中的时间原点,其对应的日期是 1970 年 1 月 1 日 8 点 0 分 0 秒。 (为什么是 8 点,因为中国的太平洋时区是 UTC-8,刚好和格林威治时间差 8 个小时)
为什么对应 1970 年呢? 因为 1969 年发布了第一个 UNIX 版本:AT&T,综合考虑,当时就把 1970 年当做了时间原点。
所有的日期,都是以为这个 0 点为基准,每过一毫秒,就+1。
1.15.1 Date
1.15.1.1 创建日期对象
import java. util. Date
1 | |
- getTime () 获得一个长整型距离 1970-1-1 08:00:00所经过的毫秒数
- System. currentTimeMillis ()效果与 getTime()相同,可能有几十毫秒误差。
1
2
3
4//当前日期的毫秒数
System. out. println ("Date. getTime () \t\t\t 返回值: "+now. getTime ());
//通过 System. currentTimeMillis ()获取当前日期的毫秒数
System. out. println ("System. currentTimeMillis () \t 返回值: "+System. currentTimeMillis ());
1.15.1.2 日期格式化
y 代表年
M 代表月
d 代表日
H 代表 24 进制的小时
h 代表 12 进制的小时
m 代表分钟
s 代表秒
S 代表毫秒
1.15.1.2.1 日期转字符串
SimpleDateFormat 类对象通过 format 方法对日期进行格式化为字符串
1 | |
1.15.1.2.2 字符串转日期
SimpleDateFormat 格式(yyyy/MM/dd HH:mm:ss)需要和字符串格式保持一致,如果不一样就会抛出解析异常 ParseException,通过调用 SimpleDateFormat 对象的 parse 方法将字符串转为日期。
1 | |
1.15.2 Calendar
Calendar 类即日历类,常用于进行“翻日历”,比如下个月的今天是多久
采用单例模式获取日历对象 Calendar. getInstance ();
日历对象的 getTime 方法获取当前日期,setTime 方法设置日历日期。
1 | |
1.15.2.1 翻日历
add方法,在原日期上增加年/月/日set方法,直接设置年/月/日1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28import java. text. SimpleDateFormat;
import java. util. Calendar;
import java. util. Date;
public class TestCalendar {
private static final SimpleDateFormat sdf = new SimpleDateFormat ("yyyy-MM-dd HH:mm: ss");
public static void main (String[] args) {
Calendar c = Calendar. getInstance ();
Date now = c.getTime ();
// 当前日期
System. out. println ("当前日期:\t" + format (c.getTime ()));
// 下个月的今天
c.setTime (now);
c.add (Calendar. MONTH, 1);
System. out. println ("下个月的今天:\t" + format (c.getTime ()));
// 去年的今天
c.setTime (now);
c.add (Calendar. YEAR, -1);
System. out. println ("去年的今天:\t" + format (c.getTime ()));
// 上个月的第三天
c.setTime (now);
c.add (Calendar. MONTH, -1);
c.set (Calendar. DATE, 3);
System. out. println ("上个月的第三天:\t" + format (c.getTime ()));
}
private static String format (Date time) {
return sdf. format (time);
}
}[!NOTE]
对日期需要修改的时候用 Calendar,直接获取当前日期用 Date
2 Java 中级
2.1 异常处理
2.1.1 异常分类

可查异常,运行时异常和错误 3 种,其中,运行时异常和错误又叫非可查异常
2.1.1.1 可查异常: CheckedException
可查异常即必须进行处理的异常,要么 try catch 住, 要么往外抛,谁调用,谁处理,比如 FileNotFoundException ,如果不处理,编译器,就不让你通过
2.1.1.2 运行时异常:RuntimeException
不是必须进行 try catch 的异常 ,但是运行会报错。
常见运行时异常:
- 除数不能为 0 异常: ArithmeticException
- 下标越界异常: ArrayIndexOutOfBoundsException
- 空指针异常:NullPointerException
2.1.1.3 错误:Error
错误 Error,指的是系统级别的异常,通常是内存用光了,在默认设置下,一般 java 程序启动的时候,最大可以使用 16 m 的内存,如例不停的给 StringBuffer 追加字符,很快就把内存使用光了。抛出 OutOfMemoryError
与运行时异常一样,错误也是不要求强制捕捉的,并且无法人为处理。
2.1.2 try catch finally 捕捉处理异常
- 将可能抛出 FileNotFoundException 文件不存在异常的代码放在 try 里
- 如果文件存在,就会顺序往下执行,并且不执行 catch 块中的代码
- 如果文件不存在,try 里的代码会立即终止,程序流程会运行到对应的 catch 块中
- e.
printStackTrace(); 会打印出方法的调用痕迹,如此例,会打印出异常开始于 TestException 的第 16 行,这样就便于定位和分析到底哪里出了异常 - 无论是否出现异常,finally 中的代码都会被执行
2.1.3 多异常捕捉办法
- 分别进行 catch
- 把多个异常,放在一个 catch 里统一捕捉
catch (FileNotFoundException | ParseException e) {}
2.1.4 throw 和 throws 的区别
throws 与 throw 这两个关键字接近,不过意义不一样,有如下区别:
- throws 出现在方法声明上,而 throw 通常都出现在方法体内。
- throws 表示出现异常的一种可能性,并不一定会发生这些异常;throw 则是抛出了异常,执行 throw 则一定抛出了某个异常对象。
2.1.5 Throwable
Throwable 是类,Exception 和 Error 都继承了该类, 所以在捕捉的时候,也可以使用 Throwable 进行捕捉
如图: 异常分 Error 和 Exception
Exception 里又分运行时异常和可查异常。
1 | |
2.1.6 自定义异常
Java 中的异常是通过继承 Throwable 类来实现的。因此,要自定义异常类,只需创建一个继承 Exception 或 RuntimeException 的类即可
1 | |
2.2 I/O
2.2.1 File
常用方法:
1 | |
eg:获取文件夹中最大和最小文件
1 | |
2.2.2 Stream(流)
当不同的介质之间有数据交互的时候,JAVA 就使用流来实现。
数据源可以是文件,还可以是数据库,网络甚至是其他的程序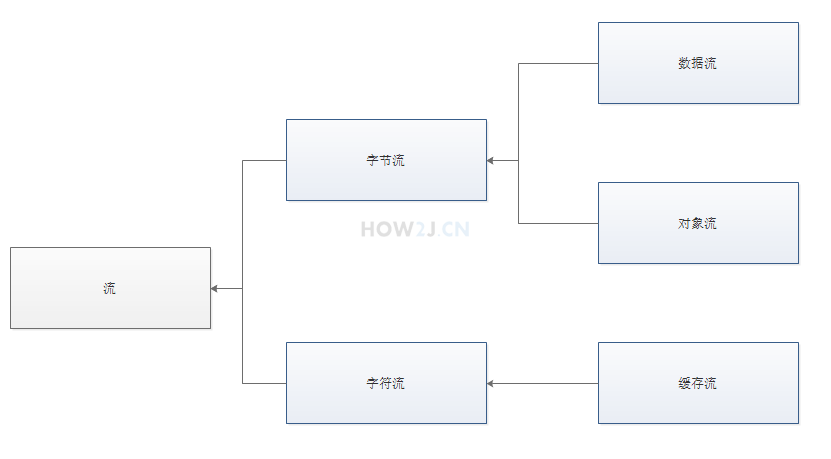
1 | |
2.2.3 字节流
InputStream 字节输入流,OutputStream 字节输出流,用于以字节的形式读取和写入数据
ASCII 码:
所有的数据存放在计算机中都是以数字的形式存放的。所以字母就需要转换为数字才能够存放。
比如 A 就对应的数字 65,a 对应的数字 97. 不同的字母和符号对应不同的数字,就是一张码表。
ASCII 是这样的一种码表。只包含简单的英文字母,符号,数字等等。不包含中文,德文,俄语等复杂的。
InputStream 是字节输入流,同时也是抽象类,只提供方法声明,不提供方法的具体实现。 FileInputStream 是 InputStream子类,read 方法进行读文件数据到(字节数组)内存为 ASCII 码,以 FileInputStream 为例进行文件读取
OutputStream 是字节输出流,同时也是抽象类,只提供方法声明,不提供方法的具体实现。FileOutputStream 是 OutputStream子类,write方法将字节数组数据写入到文件中, 如果写入数字即转为对应 ASCII 码字符,如写入字符则无变化,以 FileOutputStream 为例向文件写出数据
1 | |
关闭流:
把流定义在 try ()里, try, catch 或者 finally 结束的时候,会自动关闭
这种编写代码的方式叫做 try-with-resources,这是从 JDK 7 开始支持的技术
所有的流,都实现了一个接口叫做 AutoCloseable,任何类实现了这个接口,都可以在 try ()中进行实例化。并且在 try, catch, finally 结束的时候自动关闭,回收相关资源。
1 | |
2.2.4 字符流
Reader 字符输入流,Writer 字符输出流,专门用于字符的形式读取和写入数据
- FileReader 是 Reader 子类,以 FileReader 为例进行文件读取
- FIleWriter 是 Writer 子类,以 FileWriter 为例进行文件写入
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21package MyIO;
import java. io.*;
public class TestReaderAndWriter {
public static void main (String[] args) {
File f = new File ("D:/testrw. txt");
try (FileWriter fw = new FileWriter (f)) {
char[] rw = new char[]{'中', '国'};
fw. write (rw);
System. out. println (new String (rw));
} catch (IOException e) {
throw new RuntimeException (e);
}
try (FileReader fr = new FileReader (f)) {
char[] rc = new char[(int) f.length ()];
fr. read (rc);
System. out. println (new String (rc));
} catch (IOException e) {
throw new RuntimeException (e);
}
}
}
2.2.5 编码
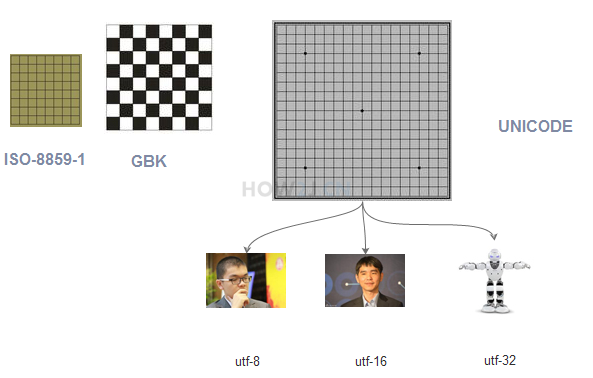
Java 采用的是 Unicode
工作后经常接触的编码方式有如下几种:
ISO-8859-1 ASCII 数字和西欧字母
GBK GB 2312 BIG 5 中文
UNICODE (统一码,万国码)
其中
ISO-8859-1 包含 ASCII
GB 2312 是简体中文,BIG 5 是繁体中文,GBK 同时包含简体和繁体以及日文。
UNICODE 包括了所有的文字,无论中文,英文,藏文,法文,世界所有的文字都包含
UNICODE 对所有字符采用 2 个字节浪费空间,于是出现各种减肥子编码, 比如 UTF-8 对数字和字母就使用一个字节,而对汉字就使用3 个字节,从而达到了减肥还能保证健康的效果,UTF-8,UTF-16 和 UTF-32 针对不同类型的数据有不同的减肥效果,一般说来 UTF-8 是比较常用的方式
UTF-8 编码的字节转中文:
1 | |
2.2.6 缓存流
避免字节流、字符流每次读写都频繁访问磁盘,严重增加磁盘压力,为了减少 IO 操作,采用缓存流对待读写的内容放到缓存中进行临时存储,结束读写时一次性读写磁盘。
缓存流必须建立在一个存在的流(FileReader,FileWriter 等)的基础上
2.2.6.1 缓存流读取数据
缓存字符输入流 BufferedReader 可以一次读取一行数据
2.2.6.2 缓存流写出数据
PrintWriter 缓存字符输出流,可以一次写出一行数据
[!NOTE] BufferWriter 和 PrintWriter 对比
BufferedWriter: 将文本写入字符输出流,缓冲各个字符从而提供单个字符,数组和字符串的高效写入。通过 write ()方法可以将获取到的字符输出,然后通过 newLine ()进行换行操作。BufferedWriter 中的字符流必须通过调用 flush 方法才能将其刷出去。并且 BufferedWriter 只能对字符流进行操作。如果要对字节流操作,则使用 BufferedInputStream。PrintWriter: 向文本输出流打印对象的格式化表示形式 (Prints formatted representations of objects to a text-output stream)。PrintWriter 相对于 BufferedWriter 的好处在于,如果 PrintWriter 开启了自动刷新,那么当 PrintWriter 调用 println,prinlf 或 format 方法时,输出流中的数据就会自动刷新出去。PrintWriter 不但能接收字符流,也能接收字节流。
1 | |
2.2.7 数据流
DataInputStream数据输入流DataOutputStream数据输出流[!NOTE] 注
要用 DataInputStream 读取一个文件,这个文件必须是由 DataOutputStream 写出的,否则会出现 EOFException,因为 DataOutputStream 在写出的时候会做一些特殊标记,只有 DataInputStream 才能成功的读取。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32package MyIO;
import java. io.*;
public class DataStream {
static File f = new File ("D:/testds. txt");
public static void read () {
try (FileInputStream fs = new FileInputStream (f)) {
DataInputStream ds = new DataInputStream (fs);
String utfs = ds. readUTF ();
int i = ds. readInt ();
boolean b = ds. readBoolean ();
System. out. println (utfs);
System. out. println (i);
System. out. println (b);
} catch (IOException e) {
e.printStackTrace ();
}
}
public static void write () {
try (FileOutputStream fo = new FileOutputStream (f)) {
DataOutputStream dos = new DataOutputStream (fo);
dos. writeUTF ("hello");
dos. writeInt (100);
dos. writeBoolean (true);
} catch (IOException e) {
throw new RuntimeException (e);
}
}
public static void main (String[] args) {
write ();
read ();
}
}
2.2.8 对象流
对象流指的是可以直接把一个对象以流的形式传输给其他的介质,比如硬盘
一个对象以流的形式进行传输,叫做序列化。该对象所对应的类,必须是实现 Serializable 接口,并且使用 ObjectOutputStream 和 ObjectInputStream 对流对象使用 writeObject 和 readObject 方法进行写读。
1 | |
2.2.9 系统输入输出流
System. out是常用的在控制台输出数据的System. in可以从控制台输入数据1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18package MyIO;
import java. io. IOException;
import java. io. InputStream;
public class TestSystemIO {
public static void main (String[] args) {
InputStream is = System. in;
while (true) {
try {
/*
敲入 a, 然后敲回车可以看到 97 10 97 是 a 的 ASCII 码 10 分别对应回车换行 */
int i = is. read ();
System. out. println (i);
} catch (IOException e) {
throw new RuntimeException (e);
}
}
}
}
2.2.9.1 Scanner 读取字符串
使用 System. in. read 虽然可以读取数据,但是很不方便,使用 Scanner 就可以逐行读取了
1 | |
2.3 集合框架
2.3.1 ArrayList
ArrayList 相当于 C++里的 Vector,动态数组,可以自动扩容
ArrayList 实现了 List 接口,通常会定义 List 引用指向 ArrayList 对象,便于多态。
| add | 增加 |
| contains | 判断是否存在 |
| get | 获取指定位置的对象 |
| indexOf | 获取对象所处的位置 |
| remove | 删除 |
| set | 替换 |
| size | 获取大小 |
| toArray | 转换为数组 |
| addAll | 把另一个容器所有对象都加进来 |
| clear | 清空 |
| eg:toArray |
1 | |
2.3.2 泛型 Generic
- 不指定泛型的容器,可以存放任何类型的元素
- 指定了泛型的容器,只能存放指定类型的元素以及其子类
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19//对于不使用泛型的容器,可以往里面放英雄,也可以往里面放物品
List heros = new ArrayList ();
heros. add (new Hero ("盖伦"));
//本来用于存放英雄的容器,现在也可以存放物品了
heros. add (new Item ("冰杖"));
//对象转型会出现问题
Hero h 1= (Hero) heros. get (0);
//尤其是在容器里放的对象太多的时候,就记不清楚哪个位置放的是哪种类型的对象了
Hero h 2= (Hero) heros. get (1);
//引入泛型 Generic
//声明容器的时候,就指定了这种容器,只能放 Hero,放其他的就会出错
List<Hero> genericheros = new ArrayList<Hero>();
genericheros. add (new Hero ("盖伦"));
//如果不是 Hero 类型,根本就放不进去
//genericheros. add (new Item ("冰杖"));
//除此之外,还能存放 Hero 的子类
genericheros. add (new APHero ());
//并且在取出数据的时候,不需要再进行转型了,因为里面肯定是放的 Hero 或者其子类
Hero h = genericheros. get (0);List<Hero> genericheros = new ArrayList<Hero>();可以简写为List<Hero> genericheros 2 = new ArrayList<>();
ArrayList 容器有迭代器,可以通过迭代器进行遍历全部元素,iterator方法得到迭代器, 迭代器通过hasNext方法进行迭代并自动更新位置。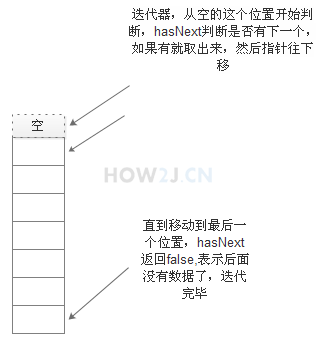
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21List<Hero> heros = new ArrayList<Hero>();
//放 5 个 Hero 进入容器
for (int i = 0; i < 5; i++) {
heros. add (new Hero ("hero name " +i));
}
//第二种遍历,使用迭代器
System. out. println ("--------使用 while 的 iterator-------");
Iterator<Hero> it= heros. iterator ();
//从最开始的位置判断"下一个"位置是否有数据
//如果有就通过 next 取出来,并且把指针向下移动
//直到"下一个"位置没有数据
while (it. hasNext ()){
Hero h = it. next ();
System. out. println (h);
}
//迭代器的 for 写法
System. out. println ("--------使用 for 的 iterator-------");
for (Iterator<Hero> iterator = heros. iterator (); iterator. hasNext ();) {
Hero hero = (Hero) iterator. next ();
System. out. println (hero);
}
2.3.3 其他集合
序列分先进先出 FIFO, 先进后出 FILO
- FIFO 在 Java 中又叫 Queue 队列
- FILO 在 Java 中又叫 Stack 栈
2.3.3.1 LinkedList
LinkedList 也实现了 List 接口,诸如 add, remove, contains 等等方法
2.3.3.1.1 Deque
除了实现了 List 接口外,LinkedList 还实现了双向链表结构 Deque,可以很方便的在头尾插入删除数据
1 | |
2.3.3.1.2 Queue
LinkedList 除了实现了 List 和 Deque 外,还实现了 Queue 接口 (队列)。
Queue 是先进先出队列 FIFO,常用方法:
offer在最后添加元素poll取出第一个元素peek查看第一个元素
1 | |
2.3.3.2 二叉树
二叉树由各种节点组成
二叉树特点:
- 每个节点都可以有左子节点,右子节点
- 每一个节点都有一个值
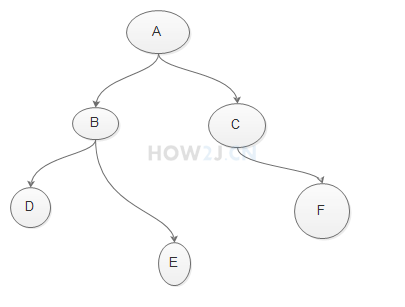
2.3.3.2.1 插入
1 | |
2.3.3.2.2 遍历
二叉树的遍历分左序,中序,右序
- 左序即: 中间的数遍历后放在左边
- 中序即: 中间的数遍历后放在中间
- 右序即: 中间的数遍历后放在右边
eg:中序遍历(递归)
1 | |
eg:英雄 tree
1 | |
2.3.3.3 HashMap
HashMap 储存数据的方式是—— 键值对
1 | |
(1)键唯一,值可重复
对于 HashMap 而言,key 是唯一的,不可以重复的。
所以,以相同的 key 把不同的 value 插入到 Map 中会导致旧元素被覆盖,只留下最后插入的元素。
不过,同一个对象可以作为值插入到 map 中,只要对应的 key 不一样
1 | |
2.3.3.3.1 HashMap 性能卓越的原因
哈希计算数组索引,同哈希值采用链表进行延长存储。
- hashcode 概念
所有的对象,都有一个对应的 hashcode(散列值)
比如字符串“gareen”对应的是 1001 (实际上不是,这里是方便理解,假设的值)
比如字符串“temoo”对应的是 1004
比如字符串“db”对应的是 1008
比如字符串“annie”对应的也是 1008 - 保存数据
准备一个数组,其长度是 2000,并且设定特殊的 hashcode 算法,使得所有字符串对应的 hashcode,都会落在 0-1999 之间
要存放名字是”gareen”的英雄,就把该英雄和名称组成一个键值对,存放在数组的 1001 这个位置上
要存放名字是”temoo”的英雄,就把该英雄存放在数组的 1004 这个位置上
要存放名字是”db”的英雄,就把该英雄存放在数组的 1008 这个位置上
要存放名字是”annie”的英雄,然而 “annie”的 hashcode 1008 对应的位置已经有 db 英雄了,那么就在这里创建一个链表,接在 db 英雄后面存放 annie - 查找数据
比如要查找 gareen,首先计算”gareen”的 hashcode 是 1001,根据 1001 这个下标,到数组中进行定位,(根据数组下标进行定位,是非常快速的) 发现 1001 这个位置就只有一个英雄,那么该英雄就是 gareen.
比如要查找 annie,首先计算”annie”的 hashcode 是 1008,根据 1008 这个下标,到数组中进行定位,发现 1008 这个位置有两个英雄,那么就对两个英雄的名字进行逐一比较 (equals),因为此时需要比较的量就已经少很多了,很快也就可以找出目标英雄,这就是使用 hashmap 进行查询,非常快原理。
2.3.3.4 HashSet
(1)元素不能重复
Set 中的元素,不能重复
(2)没有顺序
Set 中的元素,没有顺序。
严格的说,是没有按照元素的插入顺序排列
HashSet 的具体顺序,既不是按照插入顺序,也不是按照 hashcode 的顺序。
(3)遍历
Set 不提供 get ()来获取指定位置的元素
所以遍历需要用到迭代器,或者增强型 for 循环
1 | |
(4)HashSet 和 HashMap 的关系
通过观察 HashSet 的源代码(如何查看源代码)
可以发现 HashSet 自身并没有独立的实现,而是在里面封装了一个 Map.
HashSet 是作为Map 的 key而存在的
而 value 是一个命名为 PRESENT 的 static 的 Object 对象,因为是一个类属性,所以只会有一个。
2.3.3.5 Collection
Collection 是一个接口
- Collection 是 Set List Queue 和 Deque 的接口
- Queue: 先进先出队列
- Deque: 双向链表
注:Collection 和 Map 之间没有关系,Collection 是放一个一个对象的,Map 是放键值对的
注:Deque 继承 Queue, 间接的继承了 Collection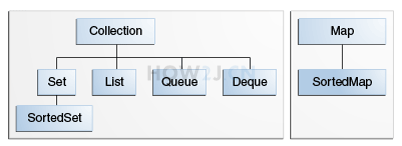
2.3.3.6 Collections
Collections 是一个类,容器的工具类, 就如同 Arrays 是数组的工具类
|关键字|简介|示例代码|
|:—:|:—:|
|reverse|反转|
|shuffle|混淆|
|sort|排序|
|swap|交换|
|rotate|滚动|
|synchronizedList|线程安全化|
1 | |
2.3.4 ArrayList 和 LinkedList 的区别
ArrayList: 有顺序, 可重复
HashSet: 无顺序,不可重复
2.3.5 HashMap 和 Hashtable 的区别
HashMap 和 Hashtable 都实现了 Map 接口,都是键值对保存数据的方式
- 区别 1:
HashMap 可以存放 null
Hashtable 不能存放 null- 区别 2:
HashMap 不是线程安全的类
Hashtable 是线程安全的类
2.3.6 HashSet LinkedHashSet TreeSet
HashSet: 无序
LinkedHashSet: 按照插入顺序
TreeSet: 从小到大排序
2.3.7 比较器
2.3.7.1 Comparator
Comparator 是一个用于比较对象的类,通过重写该类的 compare 方法按照指定规则对类对象进行比较实现排序,compare 方法中返回正数表示第一个形参大于第二个形参,返回负数则相反,返回 0 则相等。
1 | |
2.3.7.2 Comparable
类实现 Comparable 接口重写 compareTo 方法,在类里面提供比较算法Collections. sort 就有足够的信息进行排序了,也无需额外提供比较器 Comparator
注: 如果返回-1, 就表示当前的更小,否则就是更大
1 | |
2.3.8 聚合操作
JDK 8 之后,引入了对集合的聚合操作,可以非常容易的遍历,筛选,比较集合中的元素。用好聚合的前提是必须先掌握 Lambda表达式
1 | |
1 | |
2.4 泛型
2.4.1 容器的泛型
优点:
- 泛型的用法是在容器后面添加
<Type>- Type 可以是类,抽象类,接口
- 泛型表示这种容器,只能存放指定的类型。
1 | |
2.4.2 自定义泛型
设计一个支持泛型的栈 MyStack
设计这个类的时候,在类的声明上,加上一个 <T>,表示该类支持泛型。
1 | |
2.4.3 通配符
2.4.3.1 ? extends
ArrayList heroList<? extends Hero> 表示这是一个 Hero 泛型或者其子类泛型
- heroList 的泛型可能是 Hero
- heroList 的泛型可能是 APHero
- heroList 的泛型可能是 ADHero
所以可以确凿的是,从 heroList 取出来的对象,一定是可以转型成 Hero 的, 但是,不能往里面放东西,因为 - 放 APHero 就不满足
<ADHero> - 放 ADHero 又不满足
<APHero>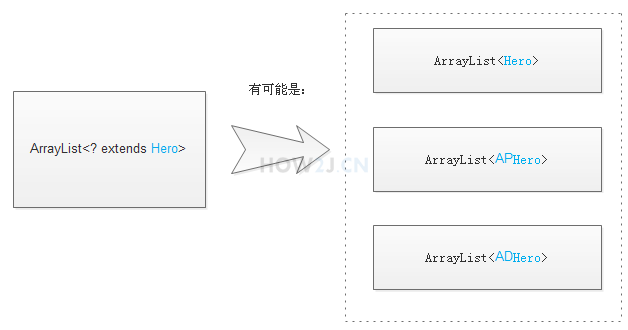
1
2
3
4
5
6
7
8
9
10
11ArrayList<APHero> apHeroList = new ArrayList<APHero>();
apHeroList. add (new APHero ());
ArrayList<? extends Hero> heroList = apHeroList;
//? extends Hero 表示这是一个 Hero 泛型的子类泛型
//heroList 的泛型可以是 Hero
//heroList 的泛型可以使 APHero
//heroList 的泛型可以使 ADHero
//可以确凿的是,从 heroList 取出来的对象,一定是可以转型成 Hero 的
Hero h = heroList. get (0);
//但是,不能往里面放东西, 编译错误
heroList. add (new ADHero ()); //编译错误,因为 heroList 的泛型有可能是 APHero
2.4.3.2 ? super
ArrayList heroList<? super Hero> 表示这是一个 Hero 泛型或者其父类泛型
- heroList 的泛型可能是 Hero
- heroList 的泛型可能是 Object
可以往里面插入 Hero 以及 Hero 的子类
但是取出来有风险,因为不确定取出来是 Hero 还是 Object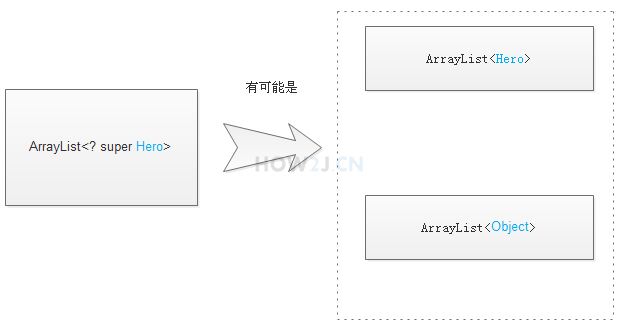
1
2
3
4
5
6
7
8
9
10
11ArrayList<? super Hero> heroList = new ArrayList<Object>();
//? super Hero 表示 heroList 的泛型是 Hero 或者其父类泛型
//heroList 的泛型可以是 Hero
//heroList 的泛型可以是 Object
//所以就可以插入 Hero
heroList. add (new Hero ());
//也可以插入 Hero 的子类
heroList. add (new APHero ());
heroList. add (new ADHero ());
//但是,不能从里面取数据出来, 因为其泛型可能是 Object, 而 Object 是强转 Hero 会失败
Hero h = heroList. get (0);
2.4.3.3 泛型通配符?
泛型通配符? 代表任意泛型 ,这个容器什么泛型都有可能 ,所以只能以 Object 的形式取出来 ,并且不能往里面放对象,因为不知道到底是一个什么泛型的容器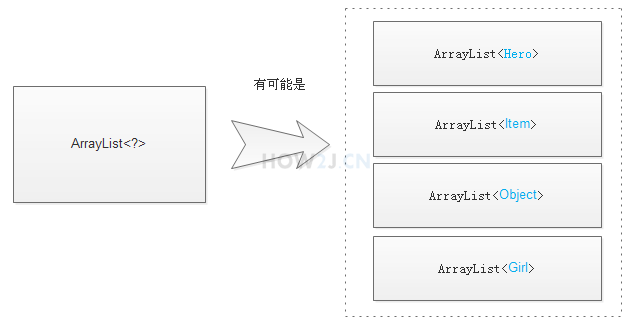
- 如果希望只取出,不插入,就使用? extends Hero
- 如果希望只插入,不取出,就使用? super Hero
- 如果希望,又能插入,又能取出,就不要用通配符?
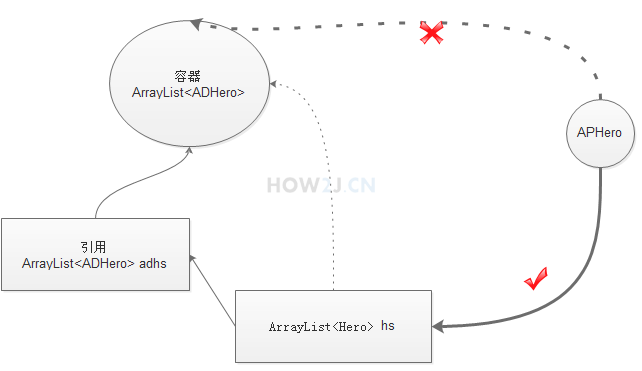
2.4.3.4 泛型转型
2.4.3.4.1 子类泛型转父类泛型
子类泛型无法转为父类泛型
1 | |
2.4.3.4.2 父类泛型转子类泛型
父类泛型不可以转子类泛型
[!NOTE]
引用类型决定容器取出元素的类型,引用指向的对象的类型决定容器可以操作(增删改查)的类型
2.5 Lambda
1 | |
万字长文详解Java lambda表达式 - 知乎
它们要么返回一个值要么执行一段方法
缺点:
- 可读性差,与啰嗦的但是清晰的匿名类代码结构比较起来,Lambda 表达式一旦变得比较长,就难以理解
- 不便于调试,很难在 Lambda 表达式中增加调试信息,比如日志
- 版本支持,Lambda 表达式在 JDK 8 版本中才开始支持,如果系统使用的是以前的版本,考虑系统的稳定性等原因,而不愿意升级,那么就无法使用。
2.5.1 普通方法
使用一个普通方法,在 for 循环遍历中进行条件判断,筛选出满足条件的数据
==hp>100 && damage<50==
1 | |
2.5.2 匿名类方式
首先准备一个接口 HeroChecker,提供一个 test (Hero)方法,然后通过匿名类的方式,实现这个接口
1 | |
2.5.3 Lambda 方式
使用 Lambda 方式筛选出数据filter (heros, (h)->h.hp>100 && h.damage<50);
同样是调用 filter 方法,从上一步的传递匿名类对象,变成了传递一个 Lambda 表达式进去h->h.hp>100 && h.damage<50
1 | |
2.5.4 匿名类->Lambda 表达式
- 匿名类的正常写法
1
2
3
4
5HeroChecker c 1 = new HeroChecker () {
public boolean test (Hero h) {
return (h.hp>100 && h.damage<50);
}
}; - 把外面的壳子去掉
只保留方法参数和方法体
参数和方法体之间加上符号 ->1
2
3HeroChecker c 2 = (Hero h) ->{
return h.hp>100 && h.damage<50;
}; - 把 return 和{}去掉
HeroChecker c 3 = (Hero h) ->h.hp>100 && h.damage<50; - 把参数类型和圆括号去掉 (只有一个参数的时候,才可以去掉圆括号)
HeroChecker c 4 = h ->h.hp>100 && h.damage<50; - 把 c 4 作为参数传递进去
filter (heros, c 4); - 直接把表达式传递进去
filter (heros, h -> h.hp > 100 && h.damage < 50);[!NOTE]
与匿名类 概念相比较,
Lambda 其实就是匿名方法,这是一种把方法作为参数进行传递的编程思想。
2.5.5 方法引用
2.5.5.1 引用静态方法
首先为 TestLambda 添加一个静态方法:
1 | |
Lambda 表达式:filter (heros, h->h.hp>100 && h.damage<50);
在 Lambda 表达式中调用这个静态方法:filter (heros, h -> TestLambda. testHero (h) );
调用静态方法还可以改写为:filter (heros, TestLambda::testHero);
2.5.5.2 引用对象方法
与引用静态方法很类似,只是传递方法的时候,需要一个对象的存在TestLambda testLambda = new TestLambda ();filter (heros, testLambda::testHero);
2.5.5.3 引用容器中的对象的方法
首先为 Hero 添加一个方法
1 | |
使用 Lambda 表达式filter (heros, h-> h.hp>100 && h.damage<50 );
在 Lambda 表达式中调用容器中的对象 Hero 的方法 matchedfilter (heros, h-> h.matched () );
matched 恰好就是容器中的对象 Hero 的方法,那就可以进一步改写为filter (heros, Hero::matched);
2.5.5.4 用构造器
1 | |
2.5.6 聚合操作
2.5.6.1 传统方式与聚合操作方式遍历数据
1 | |
2.5.6.2 Stream 和管道的概念
要了解聚合操作,首先要建立 Stream 和管道的概念
Stream 和 Collection 结构化的数据不一样,Stream 是一系列的元素,就像是生产线上的罐头一样,一串串的出来。
管道指的是一系列的聚合操作。
管道又分 3 个部分:
- 管道源:在这个例子里,源是一个 List
- 中间操作: 每个中间操作,又会返回一个 Stream,比如. filter ()又返回一个 Stream, 中间操作是“懒”操作,并不会真正进行遍历。
- 结束操作:当这个操作执行后,流就被使用“光”了,无法再被操作。所以这必定是流的最后一个操作。结束操作不会返回 Stream,但是会返回 int、float、String、 Collection 或者像 forEach,什么都不返回, 结束操作才进行真正的遍历行为,在遍历的时候,才会去进行中间操作的相关判断
(1)管道源
把 Collection 切换成管道源很简单,调用stream ()就行了。heros. stream ()
但是数组却没有 stream ()方法,需要使用Arrays. stream (hs)或者Stream. of (hs)
(2)中间操作
中间操作比较多,主要分两类
对元素进行筛选和转换为其他形式的流
- ==对元素进行筛选==:
- filter 匹配
- distinct 去除重复 (根据 equals 判断)
- sorted 自然排序
- sorted (
Comparator<T>) 指定排序 - limit 保留
- skip 忽略
- ==转换为其他形式的流==
- mapToDouble 转换为 double 的流
- map 转换为任意类型的流
(3)结束操作1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44Random r = new Random ();
List<Hero> heros = new ArrayList<Hero>();
for (int i = 0; i < 5; i++) {
heros. add (new Hero ("hero " + i, r.nextFloat (1000), r.nextInt (100)));
}
//制造一个重复数据
heros. add (heros. get (0));
System. out. println ("初始化集合后的数据 (最后一个数据重复):");
System. out. println (heros);
System. out. println ("满足条件 getgetHp ()()>100&&damage<50 的数据");
heros
.stream ()
.filter (h -> h.getHp () > 100 && h.getArmor () < 50)
.forEach (h -> System. out. print (h));
System. out. println ("去除重复的数据,去除标准是看 equals");
heros
.stream ()
.distinct ()
.forEach (h -> System. out. print (h));
System. out. println ("按照血量排序");
heros
.stream ()
.sorted ((h 1, h 2) -> h 1. getHp () >= h 2. getHp () ? 1 : -1)
.forEach (h -> System. out. print (h));
System. out. println ("保留 3 个");
heros
.stream ()
.limit (3)
.forEach (h -> System. out. print (h));
System. out. println ("忽略前 3 个");
heros
.stream ()
.skip (3)
.forEach (h -> System. out. print (h));
System. out. println ("转换为 double 的 Stream");
heros
.stream ()
.mapToDouble (Hero::getHp)
.forEach (h -> System. out. println (h));
System. out. println ("转换任意类型的 Stream");
heros
.stream ()
.map ((h) -> h.getName () + " - " + h.getHp () + " - " + h.getArmor ())
.forEach (h -> System. out. println (h));
结束操作才真正进行遍历行为,前面的中间操作也在这个时候,才真正的执行。
常见结束操作如下:- forEach () 遍历每个元素
- toArray () 转换为数组
- min (
Comparator<T>) 取最小的元素 - max (
Comparator<T>) 取最大的元素 - count () 总数
- findFirst () 第一个元素
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40Random r = new Random ();
List<Hero> heros = new ArrayList<Hero>();
for (int i = 0; i < 5; i++) {
heros. add (new Hero ("hero " + i, r.nextFloat (1000), r.nextInt (100)));
}
System. out. println ("遍历集合中的每个数据");
heros
.stream ()
.forEach (h -> System. out. print (h));
System. out. println ("返回一个数组");
Object[] hs = heros
.stream ()
.toArray ();
System. out. println (Arrays. toString (hs));
System. out. println ("返回护甲最低的那个英雄");
Hero minDamageHero =
heros
.stream ()
.min ((h 1, h 2) -> h 1. getArmor () - h 2. getArmor ())
.get ();
System. out. print (minDamageHero);
System. out. println ("返回护甲最高的那个英雄");
Hero mxnDamageHero =
heros
.stream ()
.max ((h 1, h 2) -> h 1. getArmor () - h 2. getArmor ())
.get ();
System. out. print (mxnDamageHero);
System. out. println ("流中数据的总数");
long count = heros
.stream ()
.count ();
System. out. println (count);
System. out. println ("第一个英雄");
Hero firstHero =
heros
.stream ()
.findFirst ()
.get ();
System. out. println (firstHero);
2.6 网络编程
2.6.1 基本概念
获取本机 IP 地址:
1 | |
2.6.2 Socket
使用 Socket (套接字)进行不同的程序之间的通信
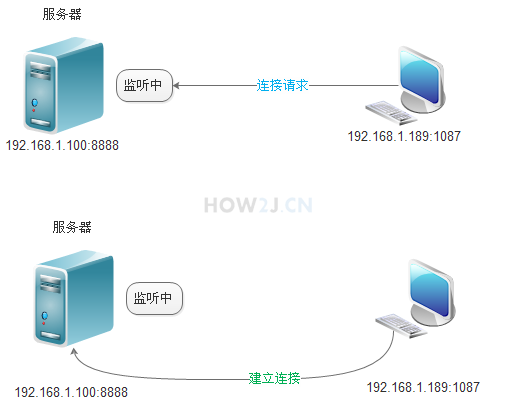
2.6.2.1 建立连接
- 服务端开启 8888 端口,并监听着,时刻等待着客户端的连接请求
- 客户端知道服务端的 ip 地址和监听端口号,发出请求到服务端
客户端的端口地址是系统分配的,通常都会大于 1024
一旦建立了连接,服务端会得到一个新的Socket 对象,该对象负责与客户端进行通信。注意: 在开发调试的过程中,如果修改过了服务器 Server 代码,要关闭启动的 Server, 否则新的 Server 不能启动,因为 8888 端口被占用了
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43//Server. java
package socket;
import java. io. IOException;
import java. net. ServerSocket;
import java. net. Socket;
public class Server {
public static void main (String[] args) {
try {
//服务端打开端口 8888
ServerSocket ss = new ServerSocket (8888);
//在 8888 端口上监听,看是否有连接请求过来
System. out. println ("监听在端口号: 8888");
Socket s = ss. accept ();
System. out. println ("有连接过来" + s);
s.close ();
ss. close ();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace ();
}
}
}
//Client. java
package socket;
import java. io. IOException;
import java. net. Socket;
import java. net. UnknownHostException;
public class Client {
public static void main (String[] args) {
try {
//连接到本机的 8888 端口
Socket s = new Socket ("127.0.0.1", 8888);
System. out. println (s);
s.close ();
} catch (UnknownHostException e) {
// TODO Auto-generated catch block
e.printStackTrace ();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace ();
}
}
}
2.6.2.2 收发数字
一旦建立了连接,服务端和客户端就可以通过 Socket 进行通信了
- 客户端打开输出流,并发送数字 110
- 服务端打开输入流,接受数字 110,并打印
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52//Server. java
package socket;
import java. io. IOException;
import java. io. InputStream;
import java. net. ServerSocket;
import java. net. Socket;
public class Server {
public static void main (String[] args) {
try {
ServerSocket ss = new ServerSocket (8888);
System. out. println ("监听在端口号: 8888");
Socket s = ss. accept ();
//打开输入流
InputStream is = s.getInputStream ();
//读取客户端发送的数据
int msg = is. read ();
//打印出来
System. out. println (msg);
is. close ();
s.close ();
ss. close ();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace ();
}
}
}
//Client. java
package socket;
import java. io. IOException;
import java. io. OutputStream;
import java. net. Socket;
import java. net. UnknownHostException;
public class Client {
public static void main (String[] args) {
try {
Socket s = new Socket ("127.0.0.1", 8888);
// 打开输出流
OutputStream os = s.getOutputStream ();
// 发送数字 110 到服务端
os. write (110);
os. close ();
s.close ();
} catch (UnknownHostException e) {
// TODO Auto-generated catch block
e.printStackTrace ();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace ();
}
}
}
2.6.2.3 收发字符串
直接使用字节流收发字符串比较麻烦,使用数据流对字节流进行封装,这样收发字符串就容易了
- 把输出流封装在 DataOutputStream 中
使用 writeUTF 发送字符串 “Legendary!” - 把输入流封装在 DataInputStream
使用 readUTF 读取字符串, 并打印1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56//Server. java
package socket;
import java. io. DataInputStream;
import java. io. IOException;
import java. io. InputStream;
import java. net. ServerSocket;
import java. net. Socket;
public class Server {
public static void main (String[] args) {
try {
ServerSocket ss = new ServerSocket (8888);
System. out. println ("监听在端口号: 8888");
Socket s = ss. accept ();
InputStream is = s.getInputStream ();
//把输入流封装在 DataInputStream
DataInputStream dis = new DataInputStream (is);
//使用 readUTF 读取字符串
String msg = dis. readUTF ();
System. out. println (msg);
dis. close ();
s.close ();
ss. close ();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace ();
}
}
}
//Client. java
package socket;
import java. io. DataOutputStream;
import java. io. IOException;
import java. io. OutputStream;
import java. net. Socket;
import java. net. UnknownHostException;
import java. util. Scanner;
public class Client {
public static void main (String[] args) {
try {
Socket s = new Socket ("127.0.0.1", 8888);
OutputStream os = s.getOutputStream ();
//把输出流封装在 DataOutputStream 中
DataOutputStream dos = new DataOutputStream (os);
//使用 writeUTF 发送字符串
dos. writeUTF ("Legendary!");
dos. close ();
s.close ();
} catch (UnknownHostException e) {
// TODO Auto-generated catch block
e.printStackTrace ();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace ();
}
}
}
2.6.2.4 使用 Scanner
1 | |
2.6.3 多线程聊天
为了实现同时收发消息,就需要用到多线程
因为接受和发送都在主线程中,不能同时进行。为了实现同时收发消息,基本设计思路是把收发分别放在不同的线程中进行
- SendThread 发送消息线程
- RecieveThread 接受消息线程
- Server 一旦接受到连接,就启动收发两个线程
- Client 一旦建立了连接,就启动收发两个线程
(1)SendThread. java
1 | |
(2) RecieveThread. java
1 | |
(3) Server. java
1 | |
(4) Server. java
1 | |
2.7 多线程
2.7.1 线程创建
3 种方式:
- 继承 Thread 类,重写 run 方法
- 实现 Runnable 接口
- 匿名类
(1)继承 Thread 类(2)实现 Runnab 接口1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35package MutiThreads;
import MyCharacter. Hero;
import exception. EnemyHeroIsDeadException;
public class MyTread extends Thread {
private final Hero h 1;
private final Hero h 2;
public MyTread (Hero h 1, Hero h 2) {
this. h 1 = h 1;
this. h 2 = h 2;
}
public void run () {
while (! h 2. isDead ()) {
try {
h 1. attack (h 2, 40.0 f);
} catch (EnemyHeroIsDeadException e) {
throw new RuntimeException (e);
}
}
}
}
//test
package MutiThreads;
import MyCharacter. Hero;
public class TestMyThread {
public static void main (String[] args) {
Hero galen = new Hero ("盖伦", 320.0 f, 100);
Hero timo = new Hero ("提莫", 200.0 f, 120);
Hero libai = new Hero ("李白", 210.0 f, 100);
Hero hanxin = new Hero ("韩信", 220.0 f, 110);
MyTread killThread 1 = new MyTread (galen, timo);
MyTread killThread 2 = new MyTread (libai, hanxin);
killThread 1. start ();
killThread 2. start ();
}
}(3)匿名类1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48package MutiThreads;
import MyCharacter. Hero;
import exception. EnemyHeroIsDeadException;
public class Battle implements Runnable {
private final Hero h 1;
private final Hero h 2;
public Battle (Hero h 1, Hero h 2) {
this. h 1 = h 1;
this. h 2 = h 2;
}
public void run () {
while (! h 2. isDead ()) {
try {
h 1. attack (h 2, h 1. getDamage ());
} catch (EnemyHeroIsDeadException e) {
throw new RuntimeException (e);
}
}
}
}
//test
package MutiThreads;
import MyCharacter. Hero;
import exception. EnemyHeroIsDeadException;
public class TestBattle {
public static void main (String[] args) {
Hero gareen = new Hero ();
gareen. setName ("盖伦");
gareen. setHp (616);
gareen. setDamage (50);
Hero teemo = new Hero ();
teemo. setName ("提莫");
teemo. setHp (300);
teemo. setDamage (30);
Hero bh = new Hero ();
bh. setName ("赏金猎人");
bh. setHp (500);
bh. setDamage (65);
Hero leesin = new Hero ();
leesin. setName ("盲僧");
leesin. setHp (455);
leesin. setDamage (80);
Battle battle 1 = new Battle (gareen, teemo);
new Thread (battle 1). start ();
Battle battle 2 = new Battle (bh, leesin);
new Thread (battle 2). start ();
}
}1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48import MyCharacter. Hero;
import exception. EnemyHeroIsDeadException;
public class anonymousThread {
public static void main (String[] args) {
Hero gareen = new Hero ();
gareen. setName ("盖伦");
gareen. setHp (616);
gareen. setDamage (50);
Hero teemo = new Hero ();
teemo. setName ("提莫");
teemo. setHp (300);
teemo. setDamage (30);
Hero bh = new Hero ();
bh. setName ("赏金猎人");
bh. setHp (500);
bh. setDamage (65);
Hero leesin = new Hero ();
leesin. setName ("盲僧");
leesin. setHp (455);
leesin. setDamage (80);
//匿名类
Thread t 1 = new Thread () {
public void run () {
//匿名类中用到外部的局部变量 teemo,必须把 teemo 声明为 final
//但是在 JDK 7 以后,就不是必须加 final 的了 while (! teemo. isDead ()) {
try {
gareen. attack (teemo, gareen. getDamage ());
} catch (EnemyHeroIsDeadException e) {
throw new RuntimeException (e);
}
}
}
};
t 1. start ();
Thread t 2 = new Thread () {
public void run () {
while (! leesin. isDead ()) {
try {
bh. attack (leesin, bh. getDamage ());
} catch (EnemyHeroIsDeadException e) {
throw new RuntimeException (e);
}
}
}
};
t 2. start ();
}
}注: 启动线程是
start()方法,run()并不能启动一个新的线程
2.7.2 常见线程方法
| 关键字 | 简介 | 示例代码 |
|---|---|---|
| sleep | 当前线程暂停 | 示例代码 |
| join | 加入到当前线程中 | 示例代码 |
| setPriority | 线程优先级 | 示例代码 |
| yield | 临时暂停 | 示例代码 |
| setDaemon | 守护线程 | 示例代码 |
| 守护线程的概念是: 当一个进程里,所有的线程都是守护线程的时候,结束当前进程。 |
2.7.3 线程同步
多线程的同步问题指的是多个线程同时修改一个数据的时候,可能导致的问题,多线程的问题,又叫 Concurrency 问题
1 | |
多线程系列教材 (三)- Java 多线程同步 synchronized 详解
2.7.3.1 Synchronized
synchronized 表示当前线程,独占对象 someObject
当前线程独占了对象 someObject,如果有其他线程试图占有对象 someObject,就会等待,直到当前线程释放对 someObject 的占用。
someObject 又叫同步对象,所有的对象,都可以作为同步对象
为了达到同步的效果,必须使用同一个同步对象
2.7.3.2 Lock
与 synchronized 类似的,lock 也能够达到同步的效果
2.7.4 线程池
每一个线程的启动和结束都是比较消耗时间和占用资源的。
如果在系统中用到了很多的线程,大量的启动和结束动作会导致系统的性能变卡,响应变慢。
为了解决这个问题,引入线程池这种设计思想。
线程池的模式很像生产者消费者模式,消费的对象是一个一个的能够运行的任务
2.7.5 原子访问
所谓的原子性操作即不可中断的操作,比如赋值操作int i = 5;
原子性操作本身是线程安全的
1 | |
2.7.5.1 AtomicInteger
JDK 6 以后,新增加了一个包java. util. concurrent. atomic,里面有各种原子类,比如 AtomicInteger。
而 AtomicInteger 提供了各种自增,自减等方法,这些方法都是原子性的。换句话说,自增方法 incrementAndGet 是线程安全的,同一个时间,只有一个线程可以调用这个方法。
1 | |
2.8 JDBC
1 | |
JDBC系列教材 (一)- Java 使用JDBC之前,先要准备mysql
2.8.1 增删改查
1 | |
2.8.2 预编译 PreparedStatement
和 Statement 一样,PreparedStatement 也是用来执行 sql 语句的
与创建 Statement 不同的是,需要根据 sql 语句创建 PreparedStatement
除此之外,还能够通过设置参数,指定相应的值,而不是 Statement 那样使用字符串拼接
注: 这是 JAVA 里唯二的基 1 的地方,另一个是查询语句中的 ResultSet 也是基 1 的。
优点:
- 参数设置
- Statement 需要进行字符串拼接,可读性和维护性比较差
String sql = "insert into hero values (null,"+"'提莫'"+","+313.0 f+","+50+")"; - PreparedStatement 使用参数设置,可读性好,不易犯错
String sql = "insert into hero values (null,?,?,?)";
- Statement 需要进行字符串拼接,可读性和维护性比较差
- 性能表现
- PreparedStatement 有预编译机制,性能比 Statement 更快
- Statement 执行 10 次,需要 10 次把 SQL 语句传输到数据库端
数据库要对每一次来的 SQL 语句进行编译处理 - PreparedStatement 执行 10 次,只需要1 次把 SQL 语句传输到数据库端
数据库对带? 的 SQL 进行预编译
每次执行,只需要传输参数到数据库端- 网络传输量比 Statement 更小
- 数据库不需要再进行编译,响应更快
- Statement 执行 10 次,需要 10 次把 SQL 语句传输到数据库端
- PreparedStatement 有预编译机制,性能比 Statement 更快
- 防止 SQL 注入式攻击
假设 name 是用户提交来的数据
String name = “‘盖伦’ OR 1=1”;
使用 Statement 就需要进行字符串拼接,拼接出来的语句是:select * from hero where name = ‘盖伦’ OR 1=1,因为有 OR 1=1,这是恒成立的,那么就会把所有的英雄都查出来,而不只是盖伦如果 Hero 表里的数据是海量的,比如几百万条,把这个表里的数据全部查出来,会让数据库负载变高,CPU 100%,内存消耗光,响应变得极其缓慢,而 PreparedStatement 使用的是参数设置,就不会有这个问题
2.8.3 execute 和 executeUpdate
- 相同点:
都可以执行增加,删除,修改 - 不同点
- 不同 1:
execute 可以执行查询语句,然后通过getResultSet,把结果集取出来
executeUpdate 不能执行查询语句 - 不同 2:
execute 返回boolean 类型,true 表示执行的是查询语句,false 表示执行的是insert, delete, update等等
executeUpdate 返回的是int,表示有多少条数据受到了影响
- 不同 1:
2.8.4 特殊操作
2.8.4.1 获取自增长 id
在 Statement 通过 execute 或者 executeUpdate 执行完插入语句后,MySQL 会为新插入的数据分配一个自增长 id,(前提是这个表的 id 设置为了自增长, 在 Mysql 创建表的时候,AUTO_INCREMENT 就表示自增长),需要通过 Statement 的 getGeneratedKeys 获取该 idPreparedStatement ps = c.prepareStatement (sql, Statement. RETURN_GENERATED_KEYS);
1 | |
2.8.4.2 获取表的元数据
元数据概念:
和数据库服务器相关的数据,比如数据库版本,有哪些表,表有哪些字段,字段类型是什么等等。
1 | |
2.8.5 实务
四大特性:ACID(原子性 (Atomicity)、一致性 (Consistency)、隔离性 (Isolation)、持久性 (Durability))
- 不使用事务的情况
没有事务的前提下假设业务操作是:加血,减血各做一次
结束后,英雄的血量不变
而减血的 SQL
不小心写错写成了 updata (而非 update)
那么最后结果是血量增加了,而非期望的不变 - 使用事务
在事务中的多个操作,要么都成功,要么都失败通过 c.setAutoCommit (false); 关闭自动提交
使用 c.commit (); 进行手动提交
在 22 行-35 行之间的数据库操作,就处于同一个事务当中,要么都成功,要么都失败
所以,虽然第一条 SQL 语句是可以执行的,但是第二条 SQL 语句有错误,其结果就是两条 SQL 语句都没有被提交。除非两条 SQL 语句都是正确的。1
2
3
4
5
6
7
8
9
10
11
12// 有事务的前提下
// 在事务中的多个操作,要么都成功,要么都失败
c.setAutoCommit (false);
// 加血的 SQL
String sql 1 = "update hero set hp = hp +1 where id = 22";
s.execute (sql 1);
// 减血的 SQL
// 不小心写错写成了 updata (而非 update)
String sql 2 = "updata hero set hp = hp -1 where id = 22";
s.execute (sql 2);
// 手动提交
c.commit ();[!NOTE]
MYSQL 表的类型必须是 INNODB 才支持事务
在 Mysql 中,只有当表的类型是 INNODB 的时候,才支持事务,所以需要把表的类型设置为 INNODB, 否则无法观察到事务.
修改表的类型为 INNODB 的 SQL:alter table hero ENGINE = innodb;
查看表的类型的 SQLshow table status from how 2 java;
2.8.6 ORM
ORM=Object Relationship Database Mapping
对象和关系数据库的映射,简单说,一个对象,对应数据库里的一条记录
eg:根据 id 返回一个 Hero 对象
1 | |
2.8.7 DAO
DAO=DataAccess Object 数据访问对象
实际上就是运用了练习-ORM 中的思路,把数据库相关的操作都封装在这个类里面,其他地方看不到 JDBC 的代码
1 | |
2.8.8 数据库连接池
1 | |
与线程池类似的,数据库也有一个数据库连接池。不过他们的实现思路是不一样的。
- 传统连接方式
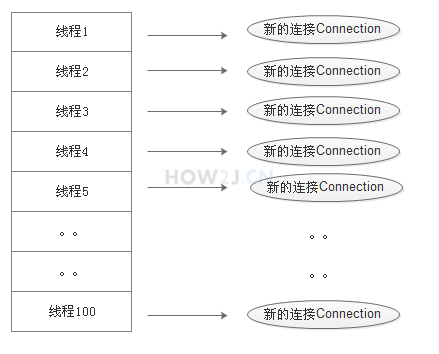
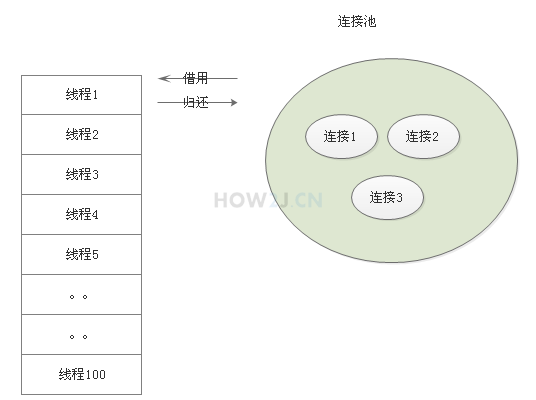
- 连接池方式
3 Java 高级
3.1 反射
3.1.1 类对象
实例对象之间的区别:
- 属性不同
类之间的区别: - 属性和方法不同
3.1.2 获取类对象
获取类对象的 3 种方式:
- Class. forName
- Hero. class
- new Hero (). getClass ()
在一个 JVM 中,一种类,只会有一个类对象存在。所以以上三种方式取出来的类对象,都是一样的。
准确的讲是一个 ClassLoader 下,一种类,只会有一个类对象存在。通常一个 JVM 下,只会有一个 ClassLoader。
1 | |
[!NOTE] 注意
获取类对象的时候,会导致类属性被初始化
为 Hero 增加一个静态属性, 并且在静态初始化块里进行初始化,参考 类属性初始化。
1 | |
无论什么途径获取类对象,都会导致静态属性被初始化,而且只会执行一次。(除了直接使用 Class c = Hero.class 这种方式,这种方式不会导致静态属性被初始化)
3.1.3 创建对象
与传统的通过 new 来获取对象的方式不同,反射机制,会先拿到 Hero 的“类对象”, 然后通过类对象获取“构造器对象” ,再通过构造器对象创建一个对象
- 获取类对象(类锁,3 种方式)
- 获取构造器对象
getConstructor - 创建一个对象
newInstance
(1)通过反射机制创建一个对象:
1 | |
(2)通过配置文件获取对象:
1 | |
3.1.4 访问属性
通过反射机制修改对象的属性
1 | |
3.1.4.1 getField 和 getDeclaredField 的区别
这两个方法都是用于获取字段
getField只能获取 public 的,包括从父类继承来的字段。getDeclaredField可以获取本类所有的字段,包括 private 的,但是不能获取继承来的字段。 (注: 这里只能获取到 private 的字段,但并不能访问该 private 字段的值, 除非加上setAccessible(true))
3.1.5 调用方法
通过反射机制,调用一个对象的方法
1 | |
反射非常强大,在学习了 Spring 的依赖注入,反转控制之后,才会对反射有更好的理解。
3.2 注解
3.2.1 基本内置注解
[!tip] jdk 基本注解
- @
Override: 表示方法重写,用于标记子类中的方法覆盖父类中的方法。- @
Deprecated: 表示该元素已经过时,不推荐使用,但仍然可以使用。- @
SuppressWarnings: 用于抑制编译器产生警告信息。- @
SafeVarargs: 用于标记方法是类型安全的可变参数方法。- @
FunctionalInterface: 用于标记接口是函数式接口,即只包含一个抽象方法的接口。
3.2.1.1 @Override
@Override 用在方法上,表示这个方法重写了父类的方法,如 toString ()。如果父类没有这个方法,那么就无法编译通过。
3.2.1.2 @Deprecated
@Deprecated 表示这个方法已经过期,不建议开发者使用。(暗示在将来某个不确定的版本,就有可能会取消掉)
1 | |
3.2.1.3 @SuppressWarnings
@SuppressWarnings Suppress 英文的意思是抑制的意思,这个注解的用处是忽略警告信息。@SuppressWarnings({ "rawtypes", "unused" })
就对这些警告进行了抑制,即忽略掉这些警告信息。
@SuppressWarnings 有常见的值,分别对应如下意思
[!NOTE]
- deprecation:使用了不赞成使用的类或方法时的警告 (使用@Deprecated 使得编译器产生的警告);
- unchecked:执行了未检查的转换时的警告,例如当使用集合时没有用泛型 (Generics) 来指定集合保存的类型; 关闭编译器警告
- fallthrough:当 Switch 程序块直接通往下一种情况而没有 Break 时的警告;
- path:在类路径、源文件路径等中有不存在的路径时的警告;
- serial:当在可序列化的类上缺少 serialVersionUID 定义时的警告;
- finally:任何 finally 子句不能正常完成时的警告;
- rawtypes 泛型类型未指明
- unused 引用定义了,但是没有被使用
- all:关于以上所有情况的警告。
1 | |
3.2.1.4 @SafeVarargs
@SafeVarargs 这是 1.7 之后新加入的基本注解. 如例所示,当使用可变数量的参数的时候,而参数的类型又是泛型 T 的话,就会出现警告。这个时候,就使用@SafeVarargs 来去掉这个警告
@SafeVarargs 注解只能用在参数长度可变的方法或构造方法上,且方法必须声明为static 或 final,否则会出现编译错误。一个方法使用@SafeVarargs 注解的前提是,开发人员必须确保这个方法的实现中对泛型类型参数的处理不会引发类型安全问题。
1 | |
3.2.1.5 @FunctionalInterface
@FunctionalInterface 这是 Java 1.8 新增的注解,用于约定函数式接口。
函数式接口概念: 如果接口中只有一个抽象方法(可以包含多个默认方法或多个 static 方法),该接口称为函数式接口。函数式接口其存在的意义,主要是配合 Lambda 表达式 来使用。
1 | |
3.2.2 自定义注解
[!warning] 注解分类(根据Annotation是否包含成员变量,可以把Annotation分为两类)
- 标记Annotation:
没有成员变量的Annotation; 这种Annotation仅利用自身的存在与否来提供信息- 元数据Annotation:
包含成员变量的Annotation; 它们可以接受(和提供)更多的元数据;
3.2.2.1 自定义注解@JDBCConfig
- 创建注解类型的时候即不使用 class 也不使用 interface, 而是使用
@interfacepublic @interface JDBCConfig - 元注解
@Target({METHOD,TYPE})表示这个注解可以用用在类/接口上,还可以用在方法上@Retention(RetentionPolicy.RUNTIME)表示这是一个运行时注解,即运行起来之后,才获取注解中的相关信息,而不像基本注解如 @Override 那种不用运行,在编译时 eclipse 就可以进行相关工作的编译时注解。@Inherited表示这个注解可以被子类继承@Documented表示当执行 javadoc的时候,本注解会生成相关文档 - 注解元素,这些注解元素就用于存放注解信息,在解析的时候获取出来
String ip ();int port () default 3306;String database ();String encoding ();String loginName ();String password ();
3.2.2.2 注解方式 DBUtil
有了自定义注解@JDBCConfig 之后,我们就把非注解方式DBUtil 改造成为注解方式 DBUtil。
如例所示,数据库相关配置信息本来是以属性的方式存放的,现在改为了以注解的方式,提供这些信息了。
注: 目前只是以注解的方式提供这些信息,但是还没有解析,接下来进行解析
1 | |
3.2.2.3 解析注解
通过反射,获取这个 DBUtil 这个类上的注解对象JDBCConfig config = DBUtil.class.getAnnotation(JDBCConfig.class);
拿到注解对象之后,通过其方法,获取各个注解元素的值:
- String ip = config. ip ();
- int port = config. port ();
- String database = config. database ();
- String encoding = config. encoding ();
- String loginName = config. loginName ();
- String password = config. password ();
后续就一样了,根据这些配置信息得到一个数据库连接Connection 实例。注: 运行需要用到连接 mysql 的 jar 包,如果没有,可在右侧下载
1 | |
3.2.3 元注解
元数据在英语中对应单词 metadata, metadata在wiki中的解释是:Metadata is data [information] that provides information about other data,为其他数据提供信息的数据.
元注解 meta annotation用于注解自定义注解的注解。
元注解有这么几种:
[!tip] 元注解种类
- @Target
- @Retention
- @Inherited
- @Documented
- @Repeatable (java 1.8 新增)
3.2.3.1 @Target
@Target 表示这个注解能放在什么位置上,是只能放在类上?还是即可以放在方法上,又可以放在属性上。自定义注解@JDBCConfig 这个注解上的@Target 是:@Target ({METHOD, TYPE}),表示他可以用在方法和类型上(类和接口),但是不能放在属性等其他位置。可以选择的位置列表如下:
在这个示例中,当用户点击summary部分时,详细信息部分会展开或者收缩。在实际应用中,可以根据具体需求来添加更多内容和样式来美化详情内容。
- ElementType. TYPE:能修饰类、接口或枚举类型
- ElementType. FIELD:能修饰成员变量
- ElementType. METHOD:能修饰方法
- ElementType. PARAMETER:能修饰参数
- ElementType. CONSTRUCTOR:能修饰构造器
- ElementType. LOCAL_VARIABLE:能修饰局部变量
- ElementType. ANNOTATION_TYPE:能修饰注解
- ElementType. PACKAGE:能修饰包
3.2.3.2 @Retention
@Retention 表示生命周期,自定义注解@JDBCConfig 上的值是 RetentionPolicy. RUNTIME, 表示可以在运行的时候依然可以使用。 @Retention 可选的值有 3 个:
- RetentionPolicy. SOURCE: 注解只在源代码中存在,编译成 class 之后,就没了。@Override 就是这种注解。
- RetentionPolicy. CLASS: 注解在 java 文件编程成. class 文件后,依然存在,但是运行起来后就没了。@Retention 的默认值,即当没有显式指定@Retention 的时候,就会是这种类型。
- RetentionPolicy. RUNTIME: 注解在运行起来之后依然存在,程序可以通过反射获取这些信息,自定义注解@JDBCConfig 就是这样。
3.2.3.3 @Inherited
@Inherited 表示该注解具有继承性。如例,设计一个 DBUtil 的子类,其 getConnection 2 方法,可以获取到父类 DBUtil 上的注解信息。
1 | |
3.2.3.4 @Documented
@Documented 如图所示,在用 javadoc 命令生成 API 文档后,DBUtil 的文档里会出现该注解说明。
3.2.3.5 @Repeatable (java 1.8 新增)
当没有@Repeatable 修饰的时候,注解在同一个位置,只能出现一次,如例所示:
@JDBCConfig (ip = “127.0.0.1”, database = “test”, encoding = “UTF-8”, loginName = “root”, password = “admin”)
@JDBCConfig (ip = “127.0.0.1”, database = “test”, encoding = “UTF-8”, loginName = “root”, password = “admin”)
重复做两次就会报错了。
使用@Repeatable 之后,再配合一些其他动作,就可以在同一个地方使用多次了。
1 | |
3.2.4 注解分类
3.2.4.1 按照作用域分
根据注解的作用域@Retention,注解分为:
- RetentionPolicy. SOURCE: Java 源文件上的注解
- RetentionPolicy. CLASS: Class 类文件上的注解
- RetentionPolicy. RUNTIME: 运行时的注解
3.2.4.2 按照来源分
按照注解的来源,也是分为 3 类:
- 内置注解如@Override,@Deprecated 等等
- 第三方注解,如 Hibernate, Struts 等等
- 自定义注解,如仿hibernate的自定义注解
4 应用
4.1 hutool
- 包含多种工具类:
- 日期与字符串转换
- 文件操作
- 转码与反转码
- 随机数生成
- 压缩与解压
- 编码与解码
- CVS 文件操作
- 缓存处理
- 加密解密
- 定时任务
- 邮件收发
- 二维码创建
- FTP 上传与下载
- 图形验证码生成
Hutool — 🍬A set of tools that keep Java sweet.