残差神经网络
本文最后更新于:2 年前
摘要
本文提出了一个残差学习框架,用于训练深度神经网络。通过引入残差块,可以让网络更深,同时避免了梯度消失和梯度弥散的问题。在多个视觉识别任务中,残差网络都取得了比传统网络更好的结果。
背景介绍(相关研究)
在近些年中,深度网络逐渐往更深的方向发展,但是更深的网络训练更加困难,因为梯度消失和梯度弥散的问题会导致网络难以收敛。之前的研究提出了一些方法,如使用更好的初始化方法、使用更好的激活函数等,但是这些方法并不能完全解决问题。本文提出了一种新的方法,即残差学习框架,通过引入残差块来解决梯度消失和梯度弥散的问题。![]()
![]()
方法
Identity Mapping by Shortcuts
$$y=F(x, \left{ W_{i}\right})+x$$
$$y=F(x, \left{ W_{i}\right})+W_{s}x$$
若残差块输入输出维度一致,则直接短接即可;
若唯独不一致,则对输入进行降维增维处理将输入输出维度统一。
网络架构
![]()
实现为等维直接短接,虚线为异维进行 A (0 填充) /B(投影快捷映射)
实验
ImageNet
![]()
CIFAR-10
![]()
![]()
上图左边指的是 Plain Net, 然而 deeper 的时候,会出现明显的 degradation。当深度达到 100+的时候,plain Net 的错误率达到了 60%以上。
上图中间这是 ResNet,可以看到当 deeper 的时候,错误率也在降低,并没有出现所谓的 degradation。
然而右边则显示 1202 layers 的 ResNet 的错误率比 101 layers 的错误率高,作者认为这不是 degradation 导致,而是由于这么大的参数量在 cifar 10 这个小数据集上过拟合导致。
重点总结
1. 残差块
作者发现,当加深模型深度时,模型的测试效果没有变好,反而变差。不符合所想的结果,因为浅层的网络应该是深层网络的一个子集,深层网络不应该比浅层网络表现的不好。然而实验的结果表明,当在浅层网络后加恒等映射层,深层网络的效果反而没有浅层网络好。为什么会出现这种原因呢?作者猜想,可能是因为深层网络难以训练。那么为什么会难以训练呢?可能是因为深层网络的最后面的层难以学习到恒等映射,因为浅层网络已经有很好的表现效果了,最后面的层如果找不到更好的表示效果就需要学习恒等映射,而让网络去学习恒等映射是很困难的。
为了解决网络学习恒等映射困难的问题,作者就想,既然学习恒等映射困难,我们就让网络学习 $f(x)=0$ 这个映射。也就引出了参差学习块。
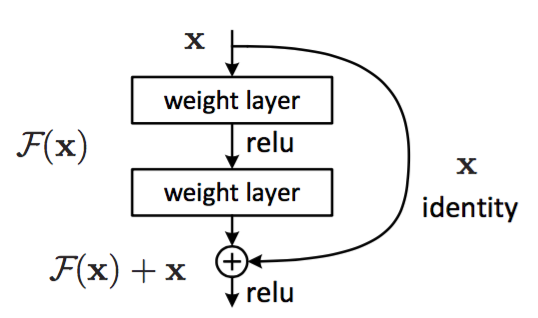
正常网络的输入是 x ,输出是 f (x),如果我们要学习恒等映射,也就是让网络的部分学会 f (x)=x,即图中 f (x) 的部分学会一个 f (x) = x 的映射关系,但是我们说直接让网络去学习恒等映射很困难,怎么办?
假设网络的输出是 h (x),那么不加 shortcut connection 的网络的输出就是 h (x)=f (x)=x,为了让网络更好拟合恒等映射,我们让 h (x)=f (x)+x,那么我们看网络要学习的映射 f (x),就变为了 f (x)=h (x)−x,这时我们发现,如果直接让 f (x)=0,那么 h (x)=x,也就是说我们让网络输出的结果和恒等映射相同,而网络只学习了 f (x)=0 这个映射,这个映射要比 f (x)=x 恒等映射更好学习,即模型会更好训练,而不受深层的影响,因为深层中多余的层我们可以都学恒等映射,最起码结果不会比浅层的结果差。然而实验结果表明,加上 shortcut connection 的深层网络比不加 shortcut connection 的浅层网络效果还好,这也就说明了深层网络所能提取的信息更高,抽象能力更强。
2. 恒等快捷映射和投影快捷映射
当 shortcut 的输入通道数和输出通道数相同时,我们可以使用恒等映射即 $f (x)=x$,也就是将 shortcut 的输出直接加上输入即可(恒等快捷映射)。
但是,当 shortcut connection 的输入不等于输出的时候怎么办?(两种方法)
① 将输入数据扩充维度,多余的维度的数据用 0 填充。
② 使用 1 x 1 的卷积扩充维度(投影快捷映射)我们实际上有三种方式组合:
① 零填充快捷连接用来增加维度,所有的快捷连接是没有参数的。
② 投影快捷连接用来增加维度,其它的快捷连接是恒等的。
③ 所有的快捷连接都是投影。
以上三种情况都比没有加 shortcut connection 的好,效果 ③ > ② > ①,但是 ③ 的计算量太大,提升的效果也不大,所以我们一般不用,我们一般用的最多的是 ②。
投影快捷映射:
- 当输入和输出的维度不匹配时,使用一个额外的卷积层来进行维度匹配。
- 可以用于解决深度残差网络中的维度不匹配问题,从而提高网络的性能。
- 在 ResNet 中,投影快捷映射是指使用一个 1 x 1 的卷积层来进行维度匹配。
3. Deeper Bottleneck Architectures
![]()
先用 1 x 1 降维,3 x 3 进行卷积,再用 1 x 1 进行升维。
事实上,deeper 左边这种结构也能获得很好的效果。那么为什么要用右边这种结构呢? 主要是源自于practical,因为左边这种结构在训练时间上要比右边结构长的多。
当换成上图右边这种 Bottleneck 结构的时候,可以发现 152 层的 ResNet 竟然比 VGG 16/19 都要少的复杂度