司法领域大模型调研一
本文最后更新于:2 年前
调研来源:
1 | |
背景介绍
据不完全统计、北京大学、山东大学、阿里云等超过20家学校、厂商都发布了面向法律行业的大模型产品,尽管侧重点不同,但都是尽可能聚焦大模型在文本生成、知识学习等方面的能力,助力法律咨询、文书写作等方面的工作。
有鉴于“百模大战”的“盛况”,行业呼唤通过一套较为全面、系统、实用的评估指标和测评方法,指引和推动法律大模型的研发、测评工作。
在这一背景下,由智慧司法技术总师系统、浙江大学、上海交通大学等联合发布的行业首个《法律大模型评估指标和测评方法(征求意见稿)》(以下简称《标准》)问世,围绕语言理解、知识问答、内容生产、逻辑推理等四个维度,定义了法律大模型所需要的12项能力体系,还从性能指标对大模型的响应速度、有效性等提出了要求,对法律大模型提出了全面的规范化要求
《标准》发布不久后,10月24日,科大讯飞正式对外发布了基于讯飞星火认知大模型打造的星火法律大模型,这也是行业首个完全对标《标准》的法律大模型。
研究现状
1.ChatLaw系列模型
来源:arXiv: ChatLaw
由北大开源的一系列法律领域的大模型,并针对LLM 和知识库的结合问题给出了法律场景下合理的解决方案。
- ChatLaw-13B,此版本为学术 demo 版,基于姜子牙 Ziya-LLaMA-13B-v1 训练而来,中文各项表现很好,但是逻辑复杂的法律问答效果不佳,需要用更大参数的模型来解决。
- ChatLaw-33B,此版本为学术 demo 版,基于 Anima-33B 训练而来,逻辑推理能力大幅提升,但是因为 Anima 的中文语料过少,导致问答时常会出现英文数据。
- ChatLaw-Text2Vec,使用 93 w 条判决案例做成的数据集基于 BERT 训练了一个相似度匹配模型,可将用户提问信息和对应的法条相匹配。
数据集
数据主要由论坛、新闻、法条、司法解释、法律咨询、法考题、判决文书组成,随后经过清洗、数据增强等来构造对话数据。
参考价值
- 提出了一种将 LLM 与矢量知识数据库相结合的新方法,并且将矢量数据库检索与关键词检索相结合,有效降低了单纯依赖矢量数据库检索的不准确性,克服模型幻觉问题。
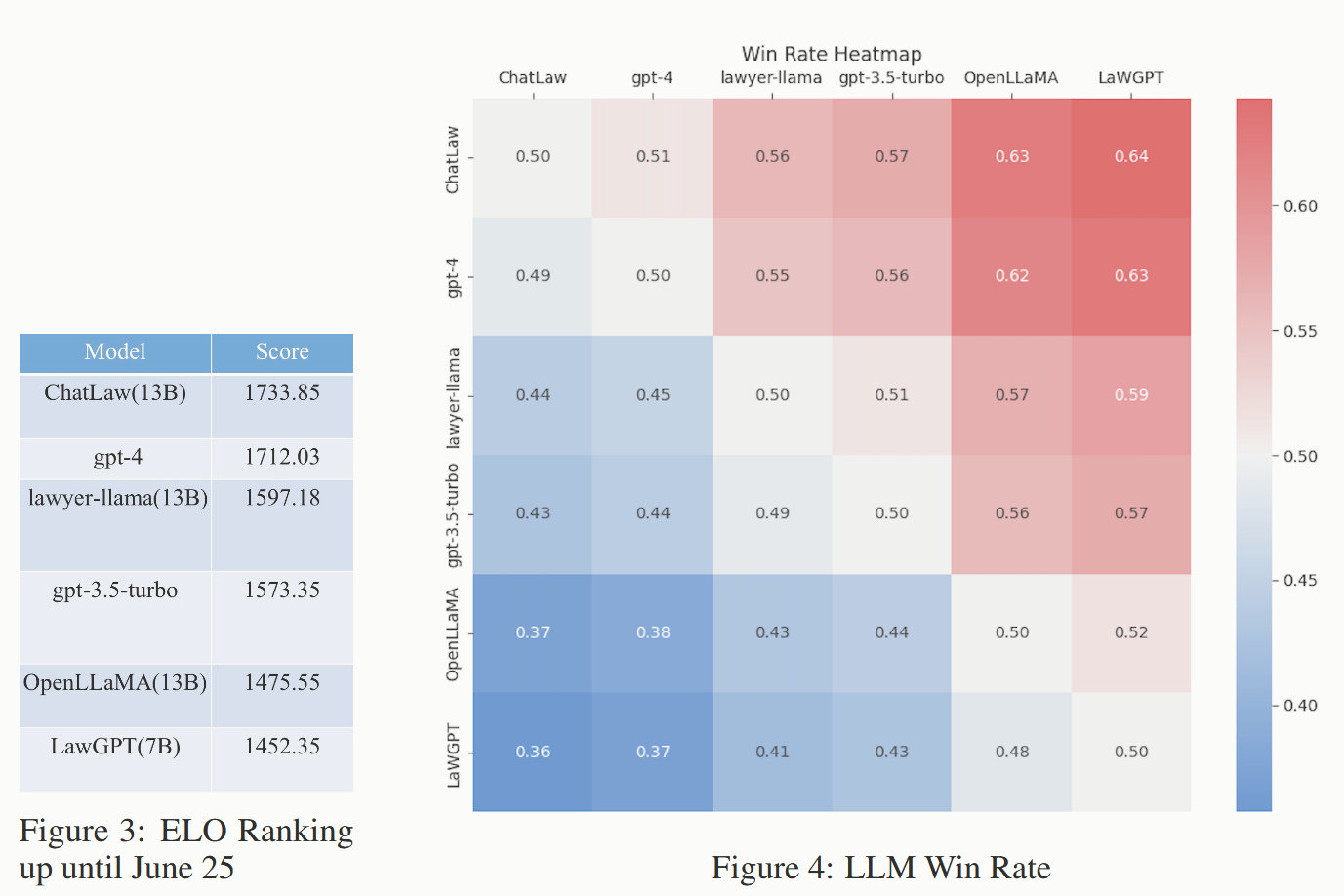
- 传统使用司法选择题来衡量司法大模型性能,但准确率普遍较低参考意义不大,借鉴电子竞技中的匹配机制和聊天机器人竞技场(Chatbot Arena)的设计,建立了模型竞逐 Elo 积分的评估机制,以更有效地评估模型处理法律多选题的能力。
2.智海-录问
智海-录问 (wisdomInterrogatory)是由浙江大学、阿里巴巴达摩院以及华院计算三家单位共同设计研发的法律大模型。核心思想:以“普法共享和司法效能提升”为目标,从推动法律智能化体系入司法实践、数字化案例建设、虚拟法律咨询服务赋能等方面提供支持,形成数字化和智能化的司法基座能力。
数据集
- 模型基座是 Baichuan-7B,在此基础上,进行了二次预训练目的是给通用的大模型注入法律领域的知识。预训练的数据包括法律文书、司法案例以及法律问答数据。再进行指令微调训练。
- 微调训练数据类别包括法考题、司法咨询、法律情景问答、触犯法律与罪名预测、刑期预测、法院意见、案件摘要提取等。
参考价值
构建司法知识库从中进行知识检索并融合,然后与用户输入共同输入到大模型中达到知识增强的目的,从而更好地完成各项任务。

共收集了 6 种类型的知识库,包括法条类、案例类、模板类、书籍类、法律考试类、法律日常问答类。

知识融合作为知识增强中的核心部分,将检索到的不同来源的知识融合后输入给法律大模型,让问题本身附带更多的司法信息,从而优化提高模型回答的效果。比如询问一个案例如何判罚时,意图识别阶段识别出应在法条库和类案库做检索,我们把和知识库名和其下检索到的知识拼接,再和问题拼接,共同输入到模型生成答案:
- 可参考的知识:法条:知识 1,知识 2 类案:知识 1,知识 2 问题:XXX,请问这个案例应该如何判罚?
3. LexiLaw - 中文法律大模型
LexiLaw 是一个经过微调的中文法律大模型,它基于 ChatGLM-6 B 架构,通过在法律领域的数据集上进行微调,使其在提供法律咨询和支持方面具备更高的性能和专业性。
数据集
通用司法领域相关数据集+知识库
- 通用领域数据:通用领域文本数据集 BELLE 1.5 M,其中包括不同指令类型、不同领域的文本。
- 专业法律数据:常见法律问题和相应的答案。这些问答数据涵盖了多个法律领域,如合同法、劳动法、知识产权等。**法律法规** 包含刑法、民法、宪法、司法解释等法律法规。**法律参考书籍** JEC-QA 数据集提供的法律参考书籍
- LawGPT_zh : 52 k 单轮问答数据和 92 k 带有法律依据的情景问答
- Lawyer LLaMA : 法考数据和法律指令微调数据
- 华律网问答数据 : 20 k 高质量华律网问答数据
- 法律知道 : 百度知道收集的 36 k 条法律问答数据
- 法律文书:
使用了包括判决书、法院裁定书和法律文件等在内的法律文书。这些文书涵盖了各种法律领域和案件类型,从法律裁判文书网收集 50 k 法律文书,使用正则匹配提取文书的事实部分和裁判分析过程部分。
参考价值
- 数据集构建可以使用通用司法数据集(开源法律数据集、法律文书、司法案例)+知识库(法律法规、法律书籍)。
- 类案检索设计的结构感知预训练语言模型 SAILER。
1. 优点:
(1) SAILER 充分利用法律案例文档中包含的结构信息,更加关注关键法律要素,类似于法律专家浏览法律案例文档的方式。
(2) SAILER 采用非对称编码器-解码器架构,整合了多个不同的预训练目标。这样,跨任务的丰富语义信息就会被编码成密集向量。
(3) 即使没有任何法律注释数据,SAILER 也具有强大的判别能力。它能准确区分不同指控的法律案件。- 展望:
“In the future, we would like to explore incorporating more expert knowledge such as legal knowledge graphs and law articles into pre-trained language models for better legal case retrieval.”未来,我们希望探索将更多的专家知识(如法律知识图谱和法律文章)纳入预训练语言模型,以便更好地进行法律案件检索。
- 展望:
4.DISC-LawLLM
DISC-LawLLM 是一个旨在为用户提供专业、智能、全面的法律服务的法律领域大模型,由复旦大学数据智能与社会计算实验室 (Fudan-DISC) 开发并开源。
您可以通过访问这个链接来在线体验我们的 DISC-LawLLM。![]()
数据集
不同场景下的法律智能应用通常需要结合法律文本理解和生成的多种基本能力。为此,我们构建了一个高质量的监督微调数据集 DISC-Law-SFT,包括法律信息提取、判决预测、文档摘要和法律问题解答,确保覆盖不同司法应用场景。DISC-Law-SFT 包括两个子集,即 DISC-Law-SFT-Pair 和 DISC-Law-SFT-Triplet(下载地址)。前者旨在为 LLM 引入法律推理能力,后者则有助于提高模型利用外部知识的能力
| 数据集 | 对应任务/来源 | 样本量 | 对应情境 | ||
|---|---|---|---|---|---|
| DISC-Law-SFT-Pair | 司法要素提取 | 32 K | 法律专业人员助手 | ||
| 司法事件检测 | 27 K | ||||
| 案件分类 | 20 K | ||||
| 判决预测 | 11 K | ||||
| 类案匹配 | 8 K | ||||
| 司法摘要 | 9 K | ||||
| 舆情摘要 | 6 K | ||||
| 法律问答 | 93 K | 法律咨询服务 | |||
| 司法阅读理解 | 38 K | 法律考试助手 | |||
| 法律考试 | 12 K | ||||
| DISC-Law-SFT-Triplet | 判决预测 | 16 K | 法律专业人员助手 | ||
| 法律问答 | 23 K | 法律咨询服务 | |||
| General | Alpaca-GPT 4 | 48 K | 通用场景 | ||
| Firefly | 60 K | ||||
| 总计 | 403 K |
参考价值
- 采用法律逻辑提示策略构建中国司法领域的监督微调数据集,并微调具有法律推理能力的 LLM。我们为 LLM 增加了检索模块(开源检索框架 Langchain-Chatchat),以增强模型获取和利用外部法律知识的能力。
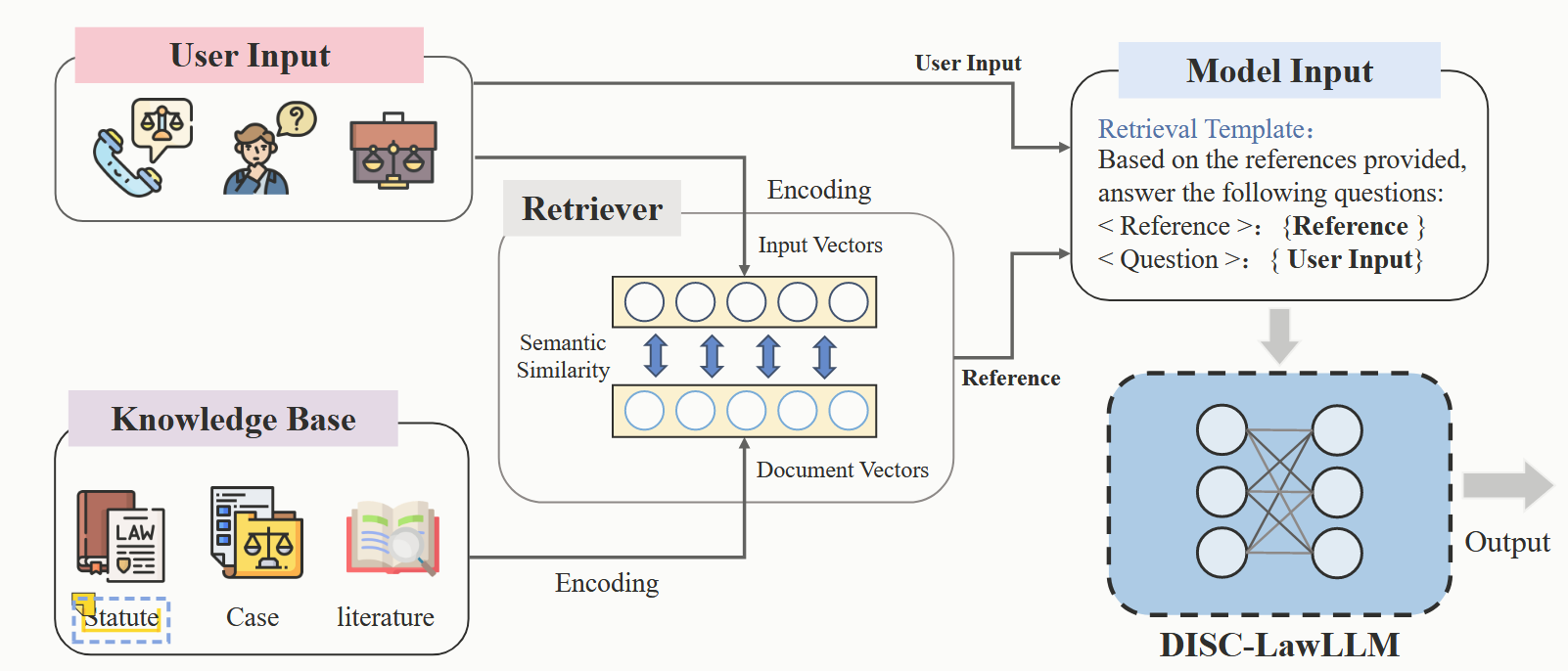
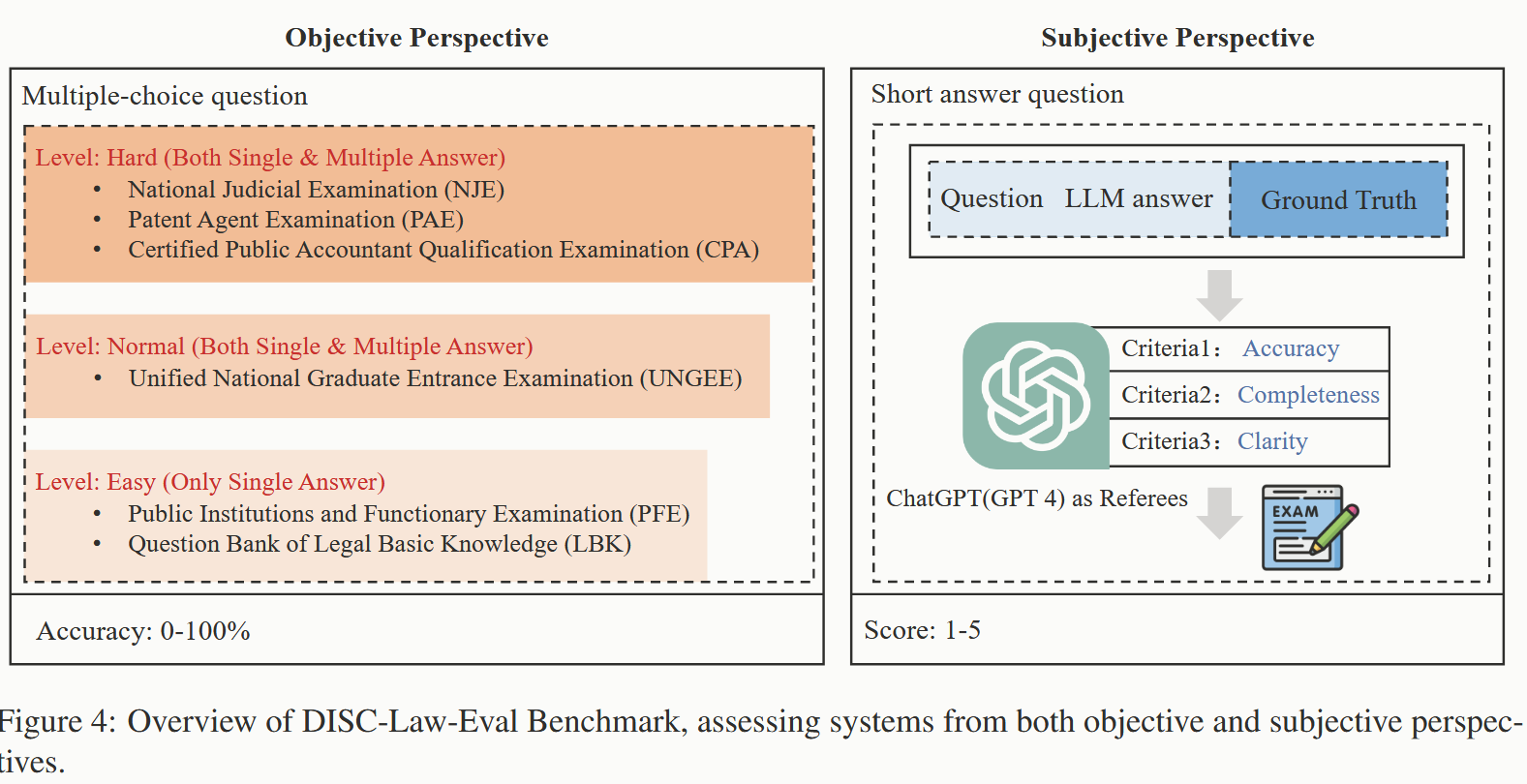
- 提出了一个全面的法律基准–DISC-Law-Eval,通过司法评价数据集(一系列中国法律标准化考试和知识竞赛的单选和多选题)以及问答题形式(法律咨询、在线论坛、与司法相关的出版物和法律文件中手工构建了一个高质量的测试集),从客观和主观两个维度对智能法律系统进行评估.
核心问题
1. 性能评估
1.1 逻辑推理能力
与医疗、教育、金融等垂直领域不同的是,法律场景的真实问答通常涉及很复杂的逻辑推理,这要求模型自身有很强的逻辑能力。
1.1.1 解决思路
可以结合 AutoGPT 将输入的复杂逻辑问题进行分解为多个逻辑简单明确的子问题,分别对各个子问题进行分析处理。![]()
[!NOTE] AutoGPT
自主运行的 GPT,其运行过程无需或少需人工干预,能够根据 GPT 自主决策结果并结合外部资源执行相应操作,通过循环评估策略实时评估目标达成程度,来决定任务是否完成。
主要特点
- 🌐分配要自动处理的任务/目标,直到完成
- 💾将多个 GPT-4 链接在一起以协作完成任务
- 🔗互联网访问和读/写文件的能力
- 🗃️上下文联动记忆性
2. 模型幻觉
1 | |
在语言模型的背景下,幻觉指的是一本正经的胡说八道:看似流畅自然的表述,实则不符合事实或者是错误的,实际上就是模型本身没有自知之明的觉悟,幻觉现象的存在严重影响 LLM 应用的可靠性。
2.1 解决思路(如何让模型知之为知之,不知为不知)
1 | |
- 幻觉检测:
1
2
3
4
5
6url: https://arxiv.org/abs/2303.08896
title: "SelfCheckGPT: Zero-Resource Black-Box Hallucination Detection for Generative Large Language Models"
description: "Generative Large Language Models (LLMs) such as GPT-3 are capable of generating highly fluent responses to a wide variety of user prompts. However, LLMs are known to hallucinate facts and make non-factual statements which can undermine trust in their output. Existing fact-checking approaches either require access to the output probability distribution (which may not be available for systems such as ChatGPT) or external databases that are interfaced via separate, often complex, modules. In this work, we propose \"SelfCheckGPT\", a simple sampling-based approach that can be used to fact-check the responses of black-box models in a zero-resource fashion, i.e. without an external database. SelfCheckGPT leverages the simple idea that if an LLM has knowledge of a given concept, sampled responses are likely to be similar and contain consistent facts. However, for hallucinated facts, stochastically sampled responses are likely to diverge and contradict one another. We investigate this approach by using GPT-3 to generate passages about individuals from the WikiBio dataset, and manually annotate the factuality of the generated passages. We demonstrate that SelfCheckGPT can: i) detect non-factual and factual sentences; and ii) rank passages in terms of factuality. We compare our approach to several baselines and show that our approach has considerably higher AUC-PR scores in sentence-level hallucination detection and higher correlation scores in passage-level factuality assessment compared to grey-box methods."
host: arxiv.org
favicon: https://static.arxiv.org/static/browse/0.3.4/images/icons/favicon-32x32.png
image: https://static.arxiv.org/static/browse/0.3.4/images/arxiv-logo-fb.png - 幻觉检测,评估,消除:
1
2
3
4
5
6url: https://arxiv.org/abs/2305.15852
title: "Self-contradictory Hallucinations of Large Language Models: Evaluation, Detection and Mitigation"
description: "Large language models (large LMs) are susceptible to producing text that contains hallucinated content. An important instance of this problem is self-contradiction, where the LM generates two contradictory sentences within the same context. In this work, we present a comprehensive investigation into self-contradiction for various instruction-tuned LMs, covering evaluation, detection, and mitigation. Our analysis reveals the prevalence of self-contradictions when LMs generate text for open-domain topics, e.g., in 17.7% of all sentences produced by ChatGPT. Self-contradiction also complements retrieval-based methods, as a large portion of them (e.g., 35.8% for ChatGPT) cannot be verified using Wikipedia. We then propose a novel prompting-based framework designed to effectively detect and mitigate self-contradictions. Our detector achieves high accuracy, e.g., around 80% F1 score when prompting ChatGPT. The mitigation algorithm iteratively refines the generated text to remove contradictory information while preserving text fluency and informativeness. Importantly, our entire framework is applicable to black-box LMs and does not require external grounded knowledge. Our approach is practically effective and has been released as a push-button tool to benefit the public, available at https://chatprotect.ai/."
host: arxiv.org
favicon: https://static.arxiv.org/static/browse/0.3.4/images/icons/favicon-32x32.png
image: https://static.arxiv.org/static/browse/0.3.4/images/arxiv-logo-fb.png
3. 隐私安全
如何在保证数据隐私性的前提下,利用私有数据训练大语言模型,从而满足在垂直领域中的应用需求。
eg:三星通过 ChatGPT 泄露了自己的秘密
(1)差分隐私(Differential Privacy)
差分隐私是一种数据隐私保护技术,通过向数据引入噪声来隐藏个体数据,以防止从模型的输出中反推个人信息。差分隐私可用于在保护数据的同时进行大规模数据分析。
(2)联邦学习
联邦学习(Federated learning,FL)是一种机器学习环境,在这种环境下,多个客户端(如移动设备或整个组织)在中央服务器(如服务提供商)的协调下协同训练一个模型,同时保持训练数据的分散性。FL 体现了集中数据收集和最小化的原则,可以减轻传统的集中式机器学习和数据科学方法带来的许多隐私、安全性风险和成本。因此,FL 是一种有效的高性能计算范式,也被看作是满足数据隐私性要求的分布式训练方法,可以用来解决司法领域大模型的隐私安全问题。
1. 分散的数据存储:
联邦学习允许法院、执法机构和其他司法实体将敏感数据保留在本地,而不需要将数据集中存储在一个地方。这减少了中心化数据存储的风险,降低了数据泄露的潜在威胁。
2. 隐私保护的模型训练:
联邦学习允许在本地设备上进行模型训练,同时避免直接访问或暴露个人数据。每个本地设备只共享模型参数的更新,而不是原始数据,这有助于保护数据隐私。
3. 安全的模型聚合:
在联邦学习中,中央服务器负责聚合和整合来自本地设备的模型参数更新。这一过程经过安全的加密和验证,以确保模型更新的完整性和隐私性。
4. 差分隐私:
差分隐私技术可以与联邦学习结合,以进一步增强数据隐私保护。通过向模型参数的更新引入噪声,可以在保持模型性能的同时,提供更高级别的个人数据保护。
个人总结
- 目前司法大模型的研究现状综合来看普遍采用微调模型+知识库来实现大模型的司法领域垂直应用
(1)微调模型
采用LLM通用预训练模型+司法数据集(法律法规,法律书籍,司法试题,论坛咨询和司法文书、案例等)
(2)知识库
采用法条、案例、文书、题库、问答等建立司法知识库,借助开源检索框架( Langchain-Chatchat)对用户输入进行知识检索获得更多关联信息作为辅助指导输入到推理模实现知识增强的效果,从而克服一些模型性能和幻觉问题。
[!NOTE] 思考
个人认为在知识库的基础上可以利用信息抽取技术将其构建为知识图谱,去除冗余信息保留关键实体和关系,再结合图嵌入机制将知识图谱实体和关系映射到低维向量空间中,从而更好地理解和利用知识图谱的信息,便于实现图谱融合,也可结合矢量和关键词检索进行知识增强,进而完成下游任务(如法律咨询、法条检索和类案检索等)。
- 司法大模型性能评估方面可以参考上述中的Elo积分评估机制和DISC的客观选择题及主观问答题形式进行模型效果评估。
- 隐私安全方面,联邦学习可以是一个考虑的方向,目前已经有部分学者在做相关研究(如FedLLM:在专有数据上建立你自己的大型语言模型),但是联邦学习用于大模型的适用性还有待考证。
会议记录
- 深度挖掘科学问题的研究,具体有哪些科学研究需要解决?
- 数据集构建的目的,如何为后续知识图谱的构建提供便利
- 如何构建一个高质量与时俱进的专业领域大模型数据集
- 知识图谱中实体对齐和实体链接是两个核心问题
- 大模型生成的虚拟数据不能用于自己训练,但是可以用于其他的任务
- 大模型的知识检索性能可以用于评估知识图谱
- 知识图谱提供指导参考辅助大模型,大模型也可以反哺知识图谱的构建融合