计算机视觉概述
本文最后更新于:3 年前
[[卷积神经网络基础]][[目标检测]][[图像分类]]
引言
计算机视觉作为一门让机器学会如何去“看”的学科,具体的说,就是让机器去识别摄像机拍摄的图片或视频中的物体,检测出物体所在的位置,并对目标物体进行跟踪,从而理解并描述出图片或视频里的场景和故事,以此来模拟人脑视觉系统。因此,计算机视觉也通常被叫做机器视觉,其目的是建立能够从图像或者视频中“感知”信息的人工系统。
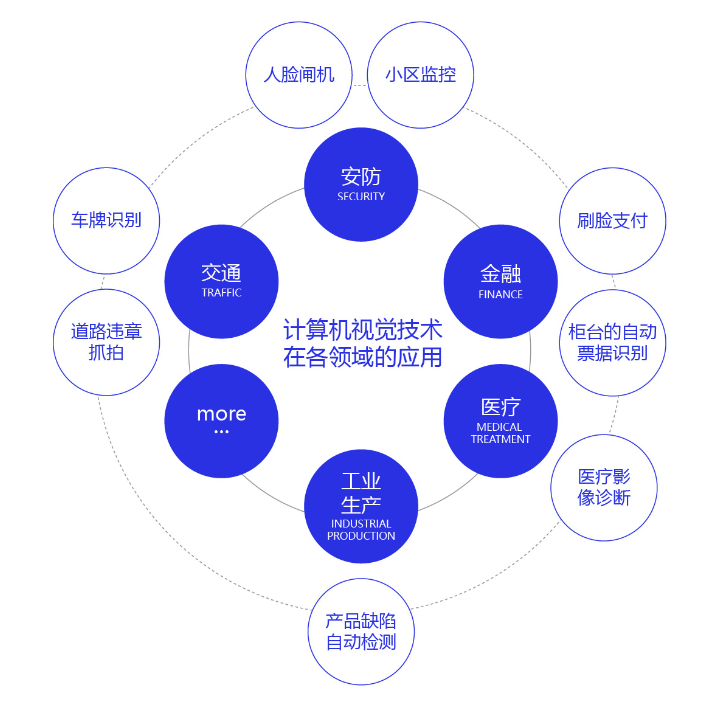
计算机视觉技术经过几十年的发展,已经在交通(车牌识别、道路违章抓拍)、安防(人脸闸机、小区监控)、金融(刷脸支付、柜台的自动票据识别)、医疗(医疗影像诊断)、工业生产(产品缺陷自动检测)等多个领域应用,影响或正在改变人们的日常生活和工业生产方式。未来,随着技术的不断演进,必将涌现出更多的产品和应用,为我们的生活创造更大的便利和更广阔的机会。
飞桨为计算机视觉任务提供了丰富的API,并通过底层优化和加速保证了这些API的性能。同时,飞桨还提供了丰富的模型库,覆盖图像分类、检测、分割、文字识别和视频理解等多个领域。用户可以直接使用这些API组建模型,也可以在飞桨提供的模型库基础上进行二次研发。
由于篇幅所限,本章将重点介绍计算机视觉的经典模型(卷积神经网络)和两个典型任务(图像分类和目标检测)。主要涵盖如下内容:
卷积神经网络:卷积神经网络(Convolutional Neural Networks, CNN)是计算机视觉技术最经典的模型结构。本教程主要介绍卷积神经网络的常用模块,包括:卷积、池化、激活函数、批归一化、丢弃法等。
- 图像分类:介绍图像分类算法的经典模型结构,包括:LeNet、AlexNet、VGG、GoogLeNet、ResNet,并通过眼疾筛查的案例展示算法的应用。
- 目标检测:介绍目标检测YOLOv3算法,并通过林业病虫害检测案例展示YOLOv3算法的应用。
发展历程
计算机视觉的发展历程要从生物视觉讲起。对于生物视觉的起源,目前学术界尚没有形成定论。有研究者认为最早的生物视觉形成于距今约7亿年前的水母之中,也有研究者认为生物视觉产生于距今约5亿年前寒武纪【1, 2】。寒武纪生物大爆发的原因一直是个未解之谜,不过可以肯定的是在寒武纪动物具有了视觉能力,捕食者可以更容易地发现猎物,被捕食者也可以更早的发现天敌的位置。视觉能力加剧了猎手和猎物之间的博弈,也催生出更加激烈的生存演化规则。视觉系统的形成有力地推动了食物链的演化,加速了生物进化过程,是生物发展史上重要的里程碑。经过几亿年的演化,目前人类的视觉系统已经具备非常高的复杂度和强大的功能,人脑中神经元数目达到了1000亿个,这些神经元通过网络互相连接,这样庞大的视觉神经网络使得我们可以很轻松的观察周围的世界,如 图2 所示。
图2:人类视觉感知
对人类来说,识别猫和狗是件非常容易的事。但对计算机来说,即使是一个精通编程的高手,也很难轻松写出具有通用性的程序(比如:假设程序认为体型大的是狗,体型小的是猫,但由于拍摄角度不同,可能一张图片上猫占据的像素比狗还多)。那么,如何让计算机也能像人一样看懂周围的世界呢?研究者尝试着从不同的角度去解决这个问题,由此也发展出一系列的子任务,如 图3 所示。
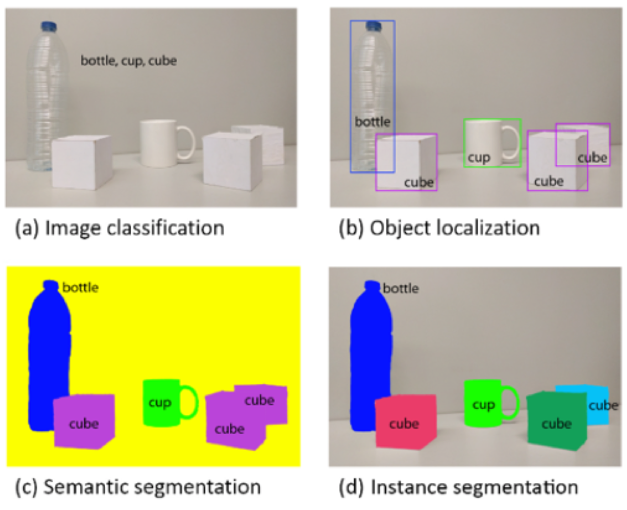
图3:计算机视觉子任务示意图
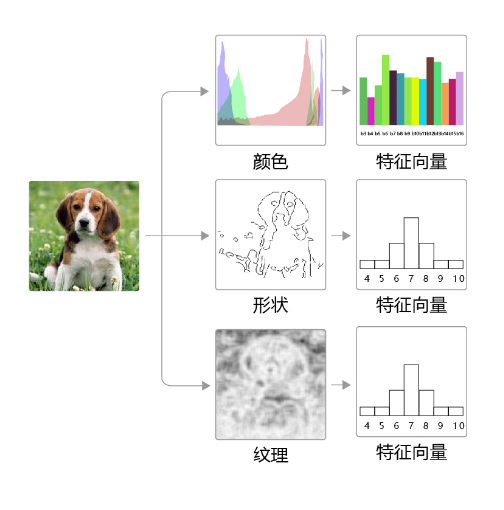
图4:早期的图像分类任务
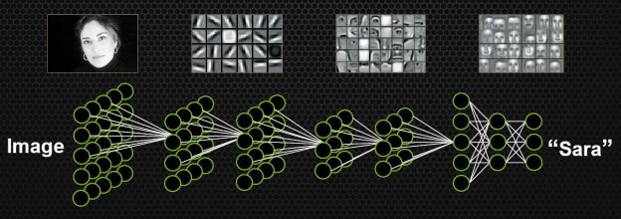
图5:早期的卷积神经网络处理图像任务示意
这一方法在手写数字识别任务上取得了极大的成功,但在接下来的时间里,却没有得到很好的发展。其主要原因一方面是数据集不完善,只能处理简单任务,在大尺寸的数据上容易发生过拟合;另一方面是硬件瓶颈,网络模型复杂时,计算速度会特别慢。
目前,随着互联网技术的不断进步,数据量呈现大规模的增长,越来越丰富的数据集不断涌现。另外,得益于硬件能力的提升,计算机的算力也越来越强大。不断有研究者将新的模型和算法应用到计算机视觉领域。由此催生了越来越丰富的模型结构和更加准确的精度,同时计算机视觉所处理的问题也越来越丰富,包括分类、检测、分割、场景描述、图像生成和风格变换等,甚至还不仅仅局限于2维图片,包括视频处理技术和3D视觉等。