ML_DL
本文最后更新于:3 年前
开发工具
Paddle常用API
| 目录 | 功能和包含的API |
|---|---|
| paddle.* | paddle 根目录下保留了常用API的别名,包括:paddle.tensor, paddle.framework, paddle.device 目录下的所有API |
| paddle.tensor | Tensor操作相关的API,包括 创建zeros, 矩阵运算matmul, 变换concat, 计算add, 查找argmax等 |
| paddle.framework | 框架通用API和动态图模式的API,包括 no_grad 、 save 、 load 等。 |
| paddle.device | 设备管理相关API,包括 set_device, get_device 等。 |
| paddle.linalg | 线性代数相关API,包括 det, svd 等。 |
| paddle.fft | 快速傅里叶变换的相关API,包括 fft, fft2 等。 |
| paddle.amp | 自动混合精度策略,包括 auto_cast 、 GradScaler 等。 |
| paddle.autograd | 自动求导相关API,包括 backward、PyLayer 等。 |
| paddle.callbacks | 日志回调类,包括 ModelCheckpoint 、 ProgBarLogger 等。 |
| paddle.distributed | 分布式相关基础API。 |
| paddle.distributed.fleet | 分布式相关高层API。 |
| paddle.hub | 模型拓展相关的API,包括 list、load、help 等。 |
| paddle.io | 数据输入输出相关API,包括 Dataset, DataLoader 等。 |
| paddle.jit | 动态图转静态图相关API,包括 to_static、 ProgramTranslator、TracedLayer 等。 |
| paddle.metric | 评估指标计算相关的API,包括 Accuracy, Auc等。 |
| paddle.nn | 组网相关的API,包括 Linear 、卷积 Conv2D 、 循环神经网络 RNN 、损失函数 CrossEntropyLoss 、 激活函数 ReLU 等。 |
| paddle.onnx | paddle转换为onnx协议相关API,包括 export 等。 |
| paddle.optimizer | 优化算法相关API,包括 SGD,Adagrad, Adam 等。 |
| paddle.optimizer.lr | 学习率衰减相关API,包括 NoamDecay 、 StepDecay 、 PiecewiseDecay 等。 |
| paddle.regularizer | 正则化相关API,包括 L1Decay、L2Decay 等。 |
| paddle.static | 静态图下基础框架相关API,包括 Variable, Program, Executor等 |
| paddle.static.nn | 静态图下组网专用API,包括 全连接层 fc 、控制流 while_loop/cond 。 |
| paddle.text | NLP领域API,包括NLP领域相关的数据集, 如 Imdb 、 Movielens 。 |
| paddle.utils | 工具类相关API,包括 CppExtension、CUDAExtension 等。 |
飞桨产业级深度学习开源开放平台
飞桨(PaddlePaddle)以百度多年的深度学习技术研究和业务应用为基础,集深度学习核心训练和推理框架、基础模型库、端到端开发套件、丰富的工具组件于一体,是中国首个自主研发、功能丰富、开源开放的产业级深度学习平台。飞桨于2016 年正式开源,是主流深度学习框架中一款完全国产化的产品。相比国内其他产品,飞桨是一个功能完整的深度学习平台,也是唯一成熟稳定、具备大规模推广条件的深度学习开源开放平台。根据国际权威调查机构IDC报告显示,2021年飞桨已位居中国深度学习平台市场综合份额第一。
目前,飞桨已凝聚477万开发者,基于飞桨开源深度学习平台创建56万个模型,服务了18万家企事业单位。飞桨助力开发者快速实现AI想法,创新AI应用,作为基础平台支撑越来越多行业实现产业智能化升级,并已广泛应用于智慧城市、智能制造、智慧金融、泛交通、泛互联网、智慧农业等领域,如 图1 所示。
飞桨产业级深度学习开源开放平台包含核心框架、基础模型库、端到端开发套件与工具组件几个部分,各组件使用场景如 图2 所示。
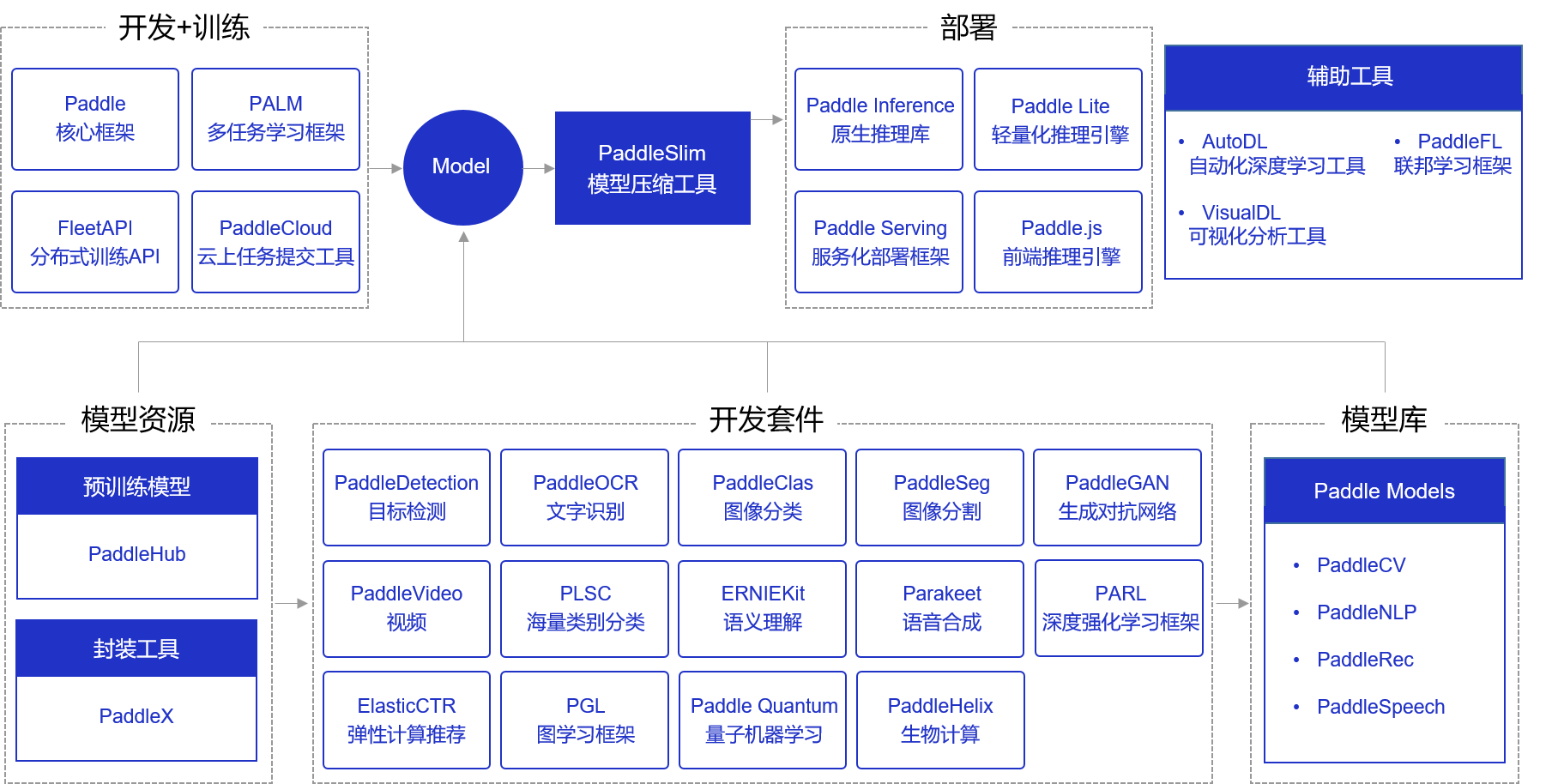
图2:飞桨开源组件使用场景概览
模型开发和训练组件
飞桨核心框架Paddle支持用户完成基础的模型编写和单机训练功能。除核心框架之外,飞桨还提供了分布式训练框架FleetAPI、云上任务提交工具PaddleCloud和多任务学习框架PALM。
模型部署组件
针对不同硬件环境,飞桨提供了丰富的支持方案:
Paddle Inference:飞桨原生推理库,用于服务器端模型部署,支持Python、C、C++、Go等语言,可将模型融入业务系统。
Paddle Serving:飞桨服务化部署框架,用于云端服务化部署,可将模型作为单独的Web服务。
Paddle Lite:飞桨轻量化推理引擎,用于Mobile、IoT等场景的部署,有着广泛的硬件支持。
Paddle.js:使用JavaScript(Web)语言部署模型,用于在浏览器、小程序等环境快速部署模型。
PaddleSlim:模型压缩工具,获得更小体积的模型和更快的执行性能,通常在模型部署前使用。
X2Paddle:飞桨模型转换工具,将其他框架模型转换成Paddle模型,转换格式后可以方便的使用上述5个工具。
其他全研发流程的辅助工具组件
AutoDL:飞桨自动化深度学习工具,自动搜索最优的网络结构与超参数,实现网络结构设计。免去用户在诸多网络结构中选择困难的烦恼和人工调参的繁琐工作。
VisualDL:飞桨可视化分析工具,以丰富的图表呈现训练参数变化趋势、模型结构、数据样本、高维数据分布、精度召回曲线等模型关键信息,帮助用户清晰直观地理解深度学习模型训练过程及模型结构,启发优化思路。
PaddleFL:飞桨联邦学习框架,通过PaddleFL复制和比较不同的联邦学习算法,实现大规模分布式集群部署,并且提供丰富的横向和纵向联邦学习策略及其在计算机视觉、自然语言处理、推荐算法等领域的应用。
产业级开源模型库
飞桨提供了产业级开源模型库,覆盖计算机视觉(PaddleCV)、自然语言处理(PaddleNLP)、推荐(PaddleRec)、语音(PaddleSpeech)四大应用领域,包含经过产业实践长期打磨的主流模型以及在国际竞赛中的夺冠模型。同时,飞桨将主流模型按照领域组织成端到端开发套件,助力快速的产业应用。
1)预训练模型和封装工具:通过低代码形式,支持企业POC快速验证、快速实现深度学习算法开发及产业部署。
PaddleHub:飞桨预训练模型应用工具,提供超过350个预训练模型,覆盖文本、图像、视频、语音四大领域。模型即软件,通过Python API或者命令行工具,一行代码完成预训练模型的预测。结合Fine-tune API,10行代码完成迁移学习,是进行原型验证(POC)的首选。
PaddleX:飞桨全流程开发工具,以低代码的形式支持开发者快速实现深度学习算法开发及产业部署。提供极简Python API和可视化界面Demo两种开发模式,可一键安装。提供CPU、GPU、树莓派等通用硬件高性能部署方案,并通过Maufacture SDK支持用户流程化串联部署任务,极大降低部署成本。
2)开发套件:针对具体的应用场景提供了全套的研发工具,例如:在图像检测场景不仅提供了预训练模型,还提供了数据增强等工具。开发套件覆盖计算机视觉、自然语言处理、语音、推荐四大主流领域,甚至还包括图神经网络和增强学习。开发套件可以提供一个领域极致优化(State Of The Art)的实现方案,曾有国内团队使用飞桨的开发套件获得了国际建模竞赛的大奖。
- PaddleClas:飞桨图像分类开发套件,提供通用图像识别系统PP-ShiTu,可高效实现高精度车辆、商品等多种识别任务;同时提供37个系列213个高性能图像分类预训练模型,其中包括10万分类预训练模型、PP-LCNet等明星模型;以及SSLD知识蒸馏等先进算法优化策略,可被广泛应用于高阶视觉任务,辅助产业及科研领域快速解决多类别、高相似度、小样本等业界难点。
- PaddleDetection:飞桨目标检测开发套件,内置190个主流目标检测、实例分割、跟踪、关键点检测算法,其中包括服务器端和移动端产业级SOTA模型、冠军方案和学术前沿算法,并提供配置化的网络模块组件、十余种数据增强策略和损失函数等高阶优化支持和多种部署方案,在打通数据处理、模型开发、训练、压缩、部署全流程的基础上,提供丰富的案例及教程,加速算法产业落地应用。
- PaddleSeg:飞桨图像分割套件PaddleSeg,提供语义分割、交互式分割、全景分割、Matting四大图像分割能力,涵盖30+主流分割网络,80+高质量预训练模型。通过模块化的设计,提供了配置化驱动和API调用等两种应用方式,帮助开发者更便捷地完成从训练到部署的全流程图像分割应用,被广泛应用在自动驾驶、遥感、医疗、质检、巡检、互联网娱乐等行业。
- PaddleOCR: 飞桨文字识别开发套件,旨在打造一套丰富、领先且实用的OCR工具库,开源了基于PP-OCRv2的实用超轻量中英文OCR模型、通用中英文OCR模型,以及德法日韩等80多种多语言OCR模型,并提供上述模型训练方法和多种预测部署方式。同时开源文本风格数据合成工具Style-Text和半自动文本图像标注工具PPOCRLabel,目前已经成为全球知名的OCR开源项目。
- PaddleGAN:飞桨生成对抗网络开发套件,提供图像生成、风格迁移、超分辨率、影像上色、人脸属性编辑、人脸融合、动作迁移等前沿算法,其模块化设计,便于开发者进行二次研发,同时提供30+预训练模型,助力开发者快速开发丰富的应用。
- PaddleVideo:飞桨视频模型开发套件,具有高指标的模型算法、全流程可部署、更快训练速度和丰富的应用案例、保姆级教程并在体育、安防、互联网、媒体等行业有广泛应用,如:足球/蓝球动作检测、乒乓球动作识别、花样滑冰动作识别、知识增强的大规模视频分类打标签、智慧安防、内容分析等产业实践案例。
- ERNIEKit:飞桨语义理解套件,基于持续学习的知识增强语义理解框架实现,内置业界领先的系列ERNE预训练模型,该套件全面升级飞桨框架v2.2,同时支持动态图和静态图,兼顾了开发的便利性与部署的高性能需求。同时还能够支持各类NLP算法任务Fine-tuning,包含保证极速推理的Fast-inference API,灵活部署的ERNIE Service和轻量化解决方案ERNIE Slim,训练过程所见即所得,支持动态debug同时方便二次开发。
- PLSC:飞桨海量类别分类套件,为用户提供了大规模分类任务从训练到部署的全流程解决方案。提供简洁易用的高层API,通过数行代码即可实现千万类别分类模型的训练,并提供快速部署模型的能力。
- ElasticCTR:飞桨个性化推荐开发套件,可以实现分布式训练CTR预估任务和基于PaddleServing的在线个性化推荐服务。PaddleServing服务化部署框架具有良好的易用性、灵活性和高性能,可以提供端到端的CTR训练和部署解决方案。ElasticCTR具备产业实践基础、弹性调度能力、高性能和工业级部署等特点。
- Parakeet:飞桨语音合成套件,提供了灵活、高效、先进的文本到语音合成工具,帮助开发者更便捷高效地完成语音合成模型的开发和应用。
- PGL:飞桨图学习框架,业界首个提出通用消息并行传递机制,支持万亿级巨图的工业级图学习框架。PGL 原生支持异构图,支持分布式图存储及分布式学习算法,支持 GNNAutoScale实现单卡深度图卷积,覆盖 30+ 图学习模型,并内置 KDDCup 2021 PGL 冠军算法。内置图推荐算法套件 Graph4Rec 以及高效知识表示套件 Graph4KG。历经大量真实工业应用验证,能够灵活、高效地搭建前沿的大规模图学习算法。
- PARL:飞桨深度强化学习框架,夺得NeurIPS强化学习挑战赛三连冠。具有高灵活性、可扩展性和高性能的特点,可支持实现数千台CPU和GPU的高性能并行,实现了数十种主流强化学习算法的示例,覆盖了从单智能体到多智能体,离散决策到连续控制,离线学习到在线学习等多样化的强化学习支持。此外,飞桨还发布了业界首个通用元智能体训练环境MetaGym,提升算法在不同配置智能体和多种环境中的适应能力,目前包含四轴飞行器、电梯调度、四足机器狗、3D迷宫等多个仿真训练环境。
- Paddle Quantum:量桨,基于飞桨的量子机器学习工具集,提供组合优化、量子化学等前沿功能,常用量子电路模型,以及丰富的量子机器学习案例,帮助开发者便捷地搭建量子神经网络,开发量子人工智能应用。
- PaddleHelix:飞桨螺旋桨生物计算平台,面向新药研发、疫苗设计、精准医疗等场景提供AI能力。在新药研发上,提供基于大规模数据预训练的分子表征和蛋白表征模型,助力分子生成、药物筛选、化合物合成等任务,同时提供从分子生成到药物筛选到全流程pipeline。在疫苗设计上,Linear系列算法相比传统方法在RNA折叠上提升了几百上干倍的效率,在mRNA序列设计上其结构紧密性、稳定性、细胞内蛋白表达水平以及动物免疫原性方面超过标准算法设计的基准序列。在精准医疗上,PaddleHelix提供了利用组学信息精准定位药物,进行双药联用提升治愈率的高性能模型。
开发套件中的大量模型,既可以通过调整配置文件直接使用的模式,也可以定位到模型的源代码文件进行二次研发。
比较几种模型工具,PaddleHub的使用最为简易,二次研发模型源代码的灵活性最好。读者可以参考“使用PaddleHub->基于配置文件使用各领域的开发套件->二次研发原始模型代码”的顺序来使用飞桨产业级模型库,在此基础上根据业务需求进行优化,即可达到事半功倍的效果。
深度学习基础
基本步骤
模型假设
优化目标
寻解算法
公式法:
梯度下降法:
方向
步长
特征缩放
梯度决定步长
![]()
激活函数(sigmoid):
$$
y=\frac{1}{1+e^{-x}}
$$
激活函数(RELU):
$$
y=
\begin{cases}
0 & x<0\
kx & x>=0
\end{cases}
$$
卷积核就是提取的特征,训练过程中通过反向传播不断改变卷积核,最终得到的卷积核就是识别目标的特征。
卷积核与输入的卷积结果为特征层
优化器,学习率,学习策略,模型,预处理方法
实例
常用的库
numpy是Python科学计算库的基础。包含了强大的N维数组对象和向量运算。
pandas是建立在numpy基础上的高效数据分析处理库,是Python的重要数据分析库。
Matplotlib是一个主要用于绘制二维图形的Python库。用途:绘图、可视化
PIL库是一个具有强大图像处理能力的第三方库。用途:图像处理
Numpy库
- 可以使用array函数从常规Python列表或元组中创建数组。得到的数组的类型是从Python列表中元素的类型推导出来的
1 | |
1.常用函数
zeros():可以创建指定长度或者形状的全0数组
ones():可以创建指定长度或者形状的全1数组
empty():创建一个数组,其初始内容是随机的,取决于内存的状态
arange():创建一个指定处末位置和步长的数字数组
random.random((m,n)):生成0~1之间的m行n列的数组
random.randint(a, b, (m,n )):生成a~b之间左开右闭区间m行n列的随机整数
1 | |
- 输出数组的一些信息,如维度、形状、元素个数、元素类型等
1 | |
- reshape([m,n])重新定义数字的形状为m行n列。
1 | |
2.数组计算
注:大小相等的数组之间的任何算术运算都会将运算应用到元素级。同样,数组与标量的算术运算也会将那个标量值传播到各个元素.
矩阵基础运算:
1
2
3
4
5
6
7
8arr1 = np.array([[1,2,3],[4,5,6]])
arr2 = np.ones([2,3],dtype=np.int64)
print(arr1 + arr2)
print(arr1 - arr2)
print(arr1 * arr2)
print(arr1 / arr2)
print(arr1 ** 2)矩阵乘法:
1
2
3
4
5arr3 = np.array([[1,2,3],[4,5,6]])
arr4 = np.ones([3,2],dtype=np.int64)
print(arr3)
print(arr4)
print(np.dot(arr3,arr4))矩阵其他运算:
1
2
3
4
5
6
7
8print(np.sum(arr3,axis=1)) #axis=1,每一行求和 axie=0,每一列求和
print(np.max(arr3))
print(np.min(arr3))
print(np.mean(arr3))
print(np.argmax(arr3),axis=0/1)#axis=1,每一行求最大值的索引 axie=0,每一列求最大值索引
print(np.argmin(arr3),axis=0/1)#axis=1,每一行求最小值的索引 axie=0,每一列求最小值索引
print(arr3.transpose())#求数组的转置矩阵
print(arr3.flatten())#将数组降为一维
3.数组的索引与切片
1 | |
4.线性代数常用库函数
1 | |
5.文件写入和读取
- tofile()和fromfile()
tofile()将数组中的数据以二进制格式写进文件
tofile()输出的数据不保存数组形状和元素类型等信息
fromfile()函数读回数据时需要用户指定元素类型,并对数组的形状进行适当的修改
1 | |
- save() 和 load(),savez()
NumPy专用的二进制格式保存数据,它们会自动处理元素类型和形状等信息
如果想将多个数组保存到一个文件中,可以使用savez(),savez()的第一个参数是文件名,其后的参数都是需要保存的数组,也可以使用关键字参数为数组起名非关键字参数传递的数组会自动起名为arr_0、arr_1、…。savez()输出的是一个扩展名为npz的压缩文件,其中每个文件都是一个save()保存的npy文件,文件名和数组名相同
load()自动识别npz文件,并且返回一个类似于字典的对象,可以通过数组名作为键获取数组的内容
1 | |
6.统计函数
可以通过数组上的一组数学函数对整个数组或某个轴向的数据进行统计计算。主要包括如下统计方法:
mean:计算算术平均数,零长度数组的mean为NaN。std和var:计算标准差和方差,自由度可调(默认为n)。sum:对数组中全部或某轴向的元素求和,零长度数组的sum为0。max和min:计算最大值和最小值。argmin和argmax:分别为最大和最小元素的索引。cumsum:计算所有元素的累加。cumprod:计算所有元素的累积。
说明:
sum、mean以及标准差std等聚合计算既可以当做数组的实例方法调用,也可以当做NumPy函数使用。
7.随机数np.random
主要介绍创建ndarray随机数组以及随机打乱顺序、随机选取元素等相关操作的方法。
7.1 创建随机ndarray数组
创建随机ndarray数组主要包含设置随机种子、均匀分布和正态分布三部分内容,具体代码如下所示。
设置随机数种子
1
2
3
4
5# 可以多次运行,观察程序输出结果是否一致
# 如果不设置随机数种子,观察多次运行输出结果是否一致
np.random.seed(10)
a = np.random.rand(3, 3)
a
均匀分布
1
2
3
4
5
6# 生成均匀分布随机数,随机数取值范围在[0, 1)之间
a = np.random.rand(3, 3)
a
# 生成均匀分布随机数,指定随机数取值范围和数组形状
a = np.random.uniform(low = -1.0, high = 1.0, size=(2,2))
a
- 正态分布
1 | |
7.2 随机打乱ndarray数组顺序
- 随机打乱1维ndarray数组顺序,发现所有元素位置都被打乱了,代码如下所示。
1 | |
7.3 随机选取元素
1 | |
8. NumPy应用举例
5.1 计算激活函数Sigmoid和ReLU
使用ndarray数组可以很方便的构建数学函数,并利用其底层的矢量计算能力快速实现计算。下面以神经网络中比较常用激活函数Sigmoid和ReLU为例,介绍代码实现过程。
- 计算Sigmoid激活函数
$$
y = \frac{1}{1 + e^{-x}}
$$
- 计算ReLU激活函数
$$
y=\left{
\begin{aligned}
0 & , & (x<0) \
x & , & (x\ge 0)
\end{aligned}
\right.
$$
使用Numpy计算激活函数Sigmoid和ReLU的值,使用matplotlib画出图形,代码如下所示。
1 | |
5.2 图像翻转和裁剪
图像是由像素点构成的矩阵,其数值可以用ndarray来表示。将上述介绍的操作用在图像数据对应的ndarray上,可以很轻松的实现图片的翻转、裁剪和亮度调整,具体代码和效果如下所示。
1 | |
9. Paddle.Tensor
飞桨使用Tensor数据结构来表示数据,在神经网络中传递的数据均为Tensor。Tensor可以将其理解为多维数组,其可以具有任意多的维度,不同Tensor可以有不同的数据类型 (dtype) 和形状 (shape)。同一Tensor的中所有元素的数据类型均相同。如果你对 Numpy 熟悉,Tensor是类似于Numpy数组(array)的概念。
飞桨的Tensor高度兼容Numpy数组(array),在基础数据结构和方法上,增加了很多适用于深度学习任务的参数和方法,如:反向计算梯度,更灵活的指定运行硬件等。
如下述代码声明了两个Tensor类型的向量$x$和$y$,指定CPU为计算运行硬件,要自动反向求导。两个向量除了可以与Numpy类似的做相乘的操作之外,还可以直接获取到每个变量的导数值。
1 | |
此外,飞桨Tensor还可以与Numpy的数组方便的互转,具体方法如下。
1 | |
推荐优先使用Paddle.Tensor的场景
虽然Paddle的Tensor可以与Numpy的数组方便的互相转换,但在实际中两者频繁转换会性能消耗。飞桨的Tensor支持的操作已经基本覆盖Numpy并有所加强,所以推荐用户在程序中优先使用飞桨的Tensor完成各种数据处理和组网操作。具体分为如下两种场景:
- 场景一:在组网程序中,对网络中向量的处理,务必使用Tensor,而不建议转成Numpy的数组。如果在组网过程中转成Numpy的数组,并使用Numpy的函数会拖慢整体性能;
- 场景二:在数据处理和模型后处理等场景,建议优先使用Tensor,主要是飞桨为AI硬件做了大量的适配和性能优化工作,部分情况下会获得更好的使用体验和性能。
Pandas库
注:提供高性能易用数据类型和分析工具;
pandas基于numpy实现,常与numpy和matplotlib一同使用。
Pandas核心数据结构:

1. Series
注:Series是一种类似于一维数组的对象,它由一维数组(各种numpy数据类 型)以及一组与之相关的数据标签(即索引)组成.可理解为带标签的一维数组,可存储整数、浮点数、字符串、Python 对象等类型的数据。
1 | |
注:Series中可以使用index设置索引列表,与字典不同的是,Series允许索引重复。
1 | |
注:Series中最重要的一个功能是它会在算术运算中基于标签自动对齐不同索引的数据。
1 | |
2. DataFrame
注:
- DataFrame是一个表格型的数据结构,类似于Excel或sql表
它含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔值等)
DataFrame既有行索引也有列索引,它可以被看做由Series组成的字典(共用同一个索引)。
- 用多维数组字典、列表字典生成 DataFrame。
1 | |
- 用 Series 字典或字典生成 DataFrame, 即Series可以作为DataFrame的子集。
1 | |
3. 索引对象常用方法
4.常用方法
data.shape返回的是元组(data必须是浮点数类型)
data.shape[0]是行数
data.shape[1]是列数
PIL库
注:
PIL库是一个具有强大图像处理能力的第三方库。
在命令行下的安装方法: pip install pillow。
在使用过程中的弓|入方法: from PIL import Image。
图像的组成:由RGB三原色组成,RGB图像中,一种彩色由R、G、B三原色按照比例混合而成。0-255区分不同亮度的颜色。图像的数组表示:图像是一个由像素组成的矩阵,每个元素是一个RGB值。
Image 是 PIL 库中代表一个图像的类(对象)。
1 | |
Matplotlib库
注:
- Matplotlib库由各种可视化类构成,内部结构复杂。
- matplotlib.pylot是绘制各类可视化图形的命令字库。
1 | |
基础图标函数
![]()
![]()
数据增强
简介:深层神经网络一般都需要大量的训练数据才能获得比较理想的结果。在数据量有限的情况下,可以通过数据增强( Data Augmentation )来增加训练样本的多样性,提高模型鲁棒性。
目的:
增加数据量
采集更多的图像特征
使网络可见更多的数据变化
提高模型的泛化能力
增强方式:
下图所示为一些基础的图像增强方法,如果我们发现数据集中的猫均是标准姿势,而真实场景中的猫时常有倾斜身姿的情况,那么在原始图片数据的基础上采用旋转的方法造一批数据加入到数据集会有助于提升模型效果。类似的,如果数据集中均是高清图片,而真实场景中经常有拍照模糊或曝光异常的情况,则采用降采样和调整饱和度的方式造一批数据,有助于提升模型的效果。
基础的图像增强方法

下图展示了一些高阶的图像增强方法,裁剪和拼接分别适合于“数据集中物体完整,但实际场景中物体存在遮挡”,以及“数据集中物体背景单一,而实际场景中物体的背景多变”的两种情况。
高阶的数据增强方法

下图展示了专门针对文本识别的数据增强方法TIA(Text Image augmentation),对应到“数据集中字体多是平面,而真实场景中的字体往往会在曲面上扭曲的情况,比如拿着相机对一张凸凹不平摆放的纸面拍摄的文字就会存在这种情况”。
TIA(Text Image augmentation):针对文本识别数据增强方法
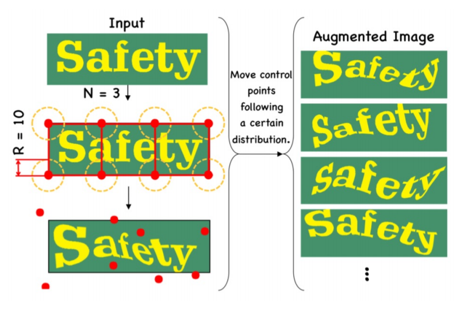
下图展示了一种新颖的数据增强技巧,用于很多现实中的文字检测,要面临复杂多样的背景,比如店铺牌匾上的文字,周围的背景可能是非常多样的。将部分文本区域剪辑出来,随机摆放到图片的各种位置来生成新的训练数据。这样的数据会大大提高模型在复杂背景中,检测到文字内容的能力。
CopyPaste:一种新颖的数据增强技巧

1. 随机旋转
注:使用numpy+ PIL库进行图像的随机旋转
1 | |
2. 随机亮度调整
注:使用numpy+ PIL库进行图像的随机亮度调整
1 | |
3. 训练过程可视化
注:使用Matplotlib库绘制深度学习训练过程中,随着数据的增加,误差与准确率的变化趋势,从而对模型效果进行评估。观察到模型的误差相对较低,而准确率较高,接下来可以使用该模型进行预测。
![]()
入门实战深度学习
1.深度学习模型的基本步骤
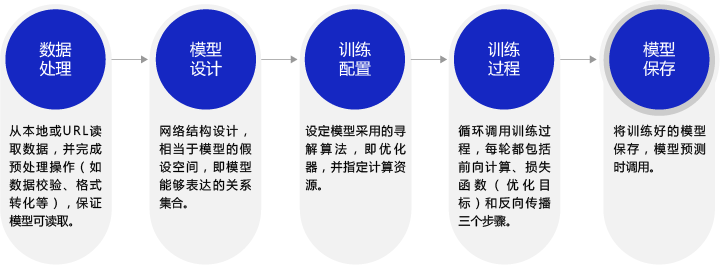
2.实例一“波士顿房价预测”
2.1 数据处理
数据处理包含五个部分:数据导入、数据形状变换、数据集划分、数据归一化处理和封装load data函数。数据预处理后,才能被模型调用。
1 | |
2.1.2 数据形状变换
由于读入的原始数据是1维的,所有数据都连在一起。因此需要我们将数据的形状进行变换,形成一个2维的矩阵,每行为一个数据样本(14个值),每个数据样本包含13个XXX(影响房价的特征)和一个YYY(该类型房屋的均价).
1 | |
2.1.3 数据集划分
将数据集划分成训练集和测试集,其中训练集用于确定模型的参数,测试集用于评判模型的效果。
1 | |
2.1.4 数据归一化处理
对每个特征进行归一化处理,使得每个特征的取值缩放到0~1之间。这样做有两个好处:一是模型训练更高效,在本节的后半部分会详细说明;二是特征前的权重大小可以代表该变量对预测结果的贡献度(因为每个特征值本身的范围相同)。
1 | |
2.1.5 封装成load data函数
将上述几个数据处理操作封装成load data函数,以便下一步模型的调用,实现方法如下。
1 | |
2.2 模型设计
模型设计是深度学习模型关键要素之一,也称为网络结构设计,相当于模型的假设空间,即实现模型“前向计算”(从输入到输出)的过程。
如果将输入特征和输出预测值均以向量表示,输入特征$x$有13个分量,$y$有1个分量,那么参数权重的形状(shape)是$13 \times 1$。假设我们以如下任意数字赋值参数做初始化:
$w=[0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,−0.1,−0.2,−0.3,−0.4,0.0]$
1 | |
取出第1条样本数据,观察样本的特征向量与参数向量相乘的结果。
1 | |
完整的线性回归公式,还需要初始化偏移量$b$,同样随意赋初值-0.2。那么,线性回归模型的完整输出是$z=t+b$,这个从特征和参数计算输出值的过程称为“前向计算”。
1 | |
将上述计算预测输出的过程以“类和对象”的方式来描述,类成员变量有参数$w$和$b$。通过写一个forward函数(代表“前向计算”)完成上述从特征和参数到输出预测值的计算过程,代码如下所示。
1 | |
基于Network类的定义,模型的计算过程如下所示。
1 | |
从上述前向计算的过程可见,线性回归也可以表示成一种简单的神经网络(只有一个神经元,且激活函数为恒等式)。这也是机器学习模型普遍为深度学习模型替代的原因:由于深度学习网络强大的表示能力,很多传统机器学习模型的学习能力等同于相对简单的深度学习模型。
2.3 训练配置
模型设计完成后,需要通过训练配置寻找模型的最优值,即通过损失函数来衡量模型的好坏。训练配置也是深度学习模型关键要素之一。
通过模型计算$x_{1}$表示的影响因素所对应的房价应该是$z$ 但实际数据告诉我们房价是$y$。这时我们需要有某种指标来衡量预测值$z$跟真实值$y$之间的差距。对于回归问题,最常采用的衡量方法是使用均方误差作为评价模型好坏的指标,具体定义如下:
$$
Loss = (y - z)^2
$$
上式中的$Loss$(简记为: $L$)通常也被称作损失函数,它是衡量模型好坏的指标。读者可能会奇怪:如果要衡量预测房价和真实房价之间的差距,是否将每一个样本的差距的绝对值加和即可?差距绝对值加和是更加直观和朴素的思路,为何要平方加和? 损失函数的设计不仅要考虑准确衡量问题的“合理性”,通常还要考虑“易于优化求解”。至于这个问题的答案,在介绍完优化算法后再揭示。
在回归问题中,均方误差是一种比较常见的形式,分类问题中通常会采用交叉熵作为损失函数,在后续的章节中会更详细的介绍。对一个样本计算损失函数值的实现如下。
1 | |
因为计算损失函数时需要把每个样本的损失函数值都考虑到,所以我们需要对单个样本的损失函数进行求和,并除以样本总数$N$。
$$
L= \frac{1}{N}\sum_{i=1}^N{(y_i - z_i)^2}
$$
在Network类下面添加损失函数的计算过程如下。
1 | |
使用定义的Network类,可以方便的计算预测值和损失函数。需要注意的是,类中的变量$x$, $w$,$b$, $z$, $error$等均是向量。以变量$x$为例,共有两个维度,一个代表特征数量(值为13),一个代表样本数量,代码如下所示。
1 | |
2.4 训练过程
上述计算过程描述了如何构建神经网络,通过神经网络完成预测值和损失函数的计算。接下来介绍如何求解参数$w$和$b$的数值,这个过程也称为模型训练过程。训练过程是深度学习模型的关键要素之一,其目标是让定义的损失函数$Loss$尽可能的小,也就是说找到一个参数解$w$和$b$,使得损失函数取得极小值。
我们先做一个小测试:如 图5 所示,基于微积分知识,求一条曲线在某个点的斜率等于函数在该点的导数值。那么大家思考下,当处于曲线的极值点时,该点的斜率是多少?
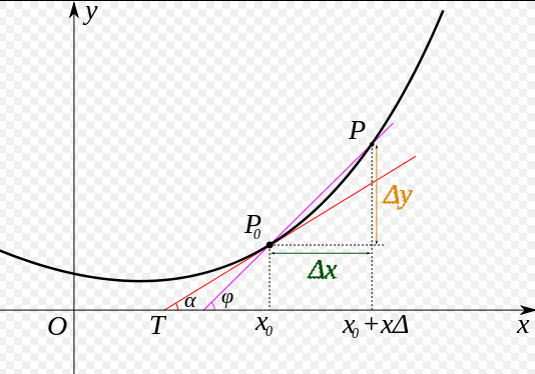
图5:曲线斜率等于导数值
$$
\frac{\partial{L}}{\partial{b}}=0
$$
其中$L$表示的是损失函数的值,$\boldsymbol{w}$为模型权重,$b$为偏置项。$\boldsymbol{w}$和$b$均为要学习的模型参数。
把损失函数表示成矩阵的形式为
$$
L=\frac{1}{N}||\boldsymbol{y}-(\boldsymbol{X}\boldsymbol{w}+\boldsymbol{b})||^2
$$
($||$为范数,表示向量之间的距离,**$||x||_p = (|x_1|^{p} + |x_2|^{p} + ··· + |x_n|^{p}) ^\frac{1}{p}$**)
其中$\boldsymbol{y}$为$N$个样本的标签值构成的向量,形状为$N\times 1$;$\boldsymbol{X}$为$N$个样本特征向量构成的矩阵,形状为$N\times D$,$D$为数据特征长度;$\boldsymbol{w}$为权重向量,形状为$D\times 1$;$\boldsymbol{b}$为所有元素都为$b$的向量,形状为$N\times 1$。
计算公式7对参数$b$的偏导数
$$
\frac{\partial L}{\partial b} = \boldsymbol{1}^T(\boldsymbol{y}-(\boldsymbol{X}\boldsymbol{w}+\boldsymbol{b}))
$$
请注意,上述公式忽略了系数$\frac{2}{N}$,并不影响最后结果。其中$\boldsymbol{1}$为$N$维的全1向量。
令公式8等于0,得到
$$
b^* = \boldsymbol{\bar{x}}^T\boldsymbol{w}-\bar{y}
$$
其中$\bar{y}=\frac{1}{N}\boldsymbol{1}^T\boldsymbol{y}$为所有标签的平均值,$\boldsymbol{\bar{x}}=\frac{1}{N}(\boldsymbol{1}^T\boldsymbol{X})^T$为所有特征向量的平均值。将$b^*$带入公式7中并对参数$\boldsymbol{w}$求偏导得到
$$
\frac{\partial L}{\partial \boldsymbol{w}} = (\boldsymbol{X}-\boldsymbol{\bar{x}}^T)^T((\boldsymbol{y}-\bar{y})-(\boldsymbol{X}-\boldsymbol{\bar{x}}^T)\boldsymbol{w})
$$
令公式10等于0,得到最优参数
$$
\boldsymbol{w}^*=((\boldsymbol{X}-\boldsymbol{\bar{x}}^T)^T(\boldsymbol{X}-\boldsymbol{\bar{x}}^T))^{-1}(\boldsymbol{X}-\boldsymbol{\bar{x}}^T)^T(\boldsymbol{y}-\bar{y}) \
b^* = \boldsymbol{\bar{x}}^T\boldsymbol{w}^*-\bar{y}
$$
将样本数据$(x, y)$带入上面的公式11和公式12中即可求解出$w$和$b$的值,但是这种方法只对线性回归这样简单的任务有效。如果模型中含有非线性变换,或者损失函数不是均方差这种简单的形式,则很难通过上式求解。为了解决这个问题,下面我们将引入更加普适的数值求解方法:梯度下降法。
2.4.1 梯度下降法
在现实中存在大量的函数正向求解容易,但反向求解较难,被称为单向函数,这种函数在密码学中有大量的应用。密码锁的特点是可以迅速判断一个密钥是否是正确的(已知$x$,求$y$很容易),但是即使获取到密码锁系统,也无法破解出正确得密钥(已知$y$,求$x$很难)。
这种情况特别类似于一位想从山峰走到坡谷的盲人,他看不见坡谷在哪(无法逆向求解出$Loss$导数为0时的参数值),但可以伸脚探索身边的坡度(当前点的导数值,也称为梯度)。那么,求解Loss函数最小值可以这样实现:从当前的参数取值,一步步的按照下坡的方向下降,直到走到最低点。这种方法笔者称它为“盲人下坡法”。哦不,有个更正式的说法“梯度下降法”。
训练的关键是找到一组$(w, b)$,使得损失函数$L$取极小值。我们先看一下损失函数$L$只随两个参数$w_5$、$w_9$变化时的简单情形,启发下寻解的思路。
$$L=L(w_5, w_9) (公式13)$$
这里将$w_0, w_1, …, w_{12}$中除$w_5, w_9$之外的参数和$b$都固定下来,可以用图画出$L(w_5, w_9)$的形式,并在三维空间中画出损失函数随参数变化的曲面图。
1 | |
从图中可以明显观察到有些区域的函数值比周围的点小。需要说明的是:为什么选择$w_5$和$w_9$来画图呢?这是因为选择这两个参数的时候,可比较直观的从损失函数的曲面图上发现极值点的存在。其他参数组合,从图形上观测损失函数的极值点不够直观。
观察上述曲线呈现出“圆滑”的坡度,这正是我们选择以均方误差作为损失函数的原因之一。图6 呈现了只有一个参数维度时,均方误差和绝对值误差(只将每个样本的误差累加,不做平方处理)的损失函数曲线图。
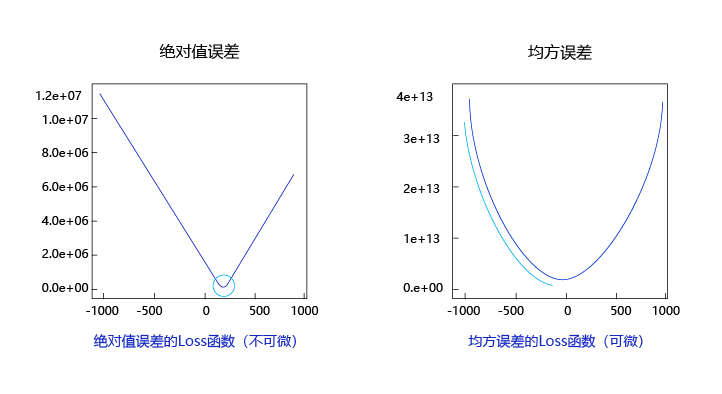
图6:均方误差和绝对值误差损失函数曲线图
- 曲线的最低点是可导的。
- 越接近最低点,曲线的坡度逐渐放缓,有助于通过当前的梯度来判断接近最低点的程度(是否逐渐减少步长,以免错过最低点)。
而绝对值误差是不具备这两个特性的,这也是损失函数的设计不仅仅要考虑“合理性”,还要追求“易解性”的原因。
现在我们要找出一组$[w_5, w_9]$的值,使得损失函数最小,实现梯度下降法的方案如下:
- 步骤1:随机的选一组初始值,例如:$[w_5, w_9] = [-100.0, -100.0]$
- 步骤2:选取下一个点$[w_5^{‘} , w_9^{‘}]$,使得$L(w_5^{‘} , w_9^{‘}) < L(w_5, w_9)$
- 步骤3:重复步骤2,直到损失函数几乎不再下降。
如何选择$[w_5^{‘} , w_9^{‘}]$是至关重要的,第一要保证$L$是下降的,第二要使得下降的趋势尽可能的快。微积分的基础知识告诉我们:沿着梯度的反方向,是函数值下降最快的方向,如 图7 所示。简单理解,函数在某一个点的梯度方向是曲线斜率最大的方向,但梯度方向是向上的,所以下降最快的是梯度的反方向。
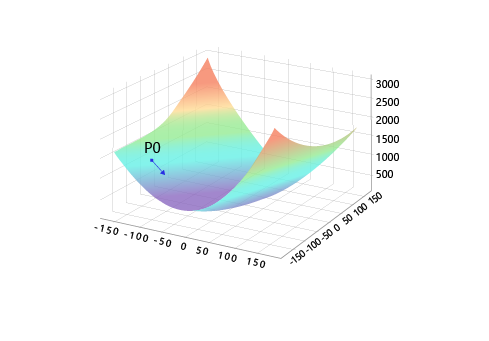
图7:梯度下降方向示意图
上文已经介绍了损失函数的计算方法,这里稍微改写。为了使梯度计算更加简洁,引入因子$\frac{1}{2}$,定义损失函数如下:
$$
L= \frac{1}{2N}\sum_{i=1}^N{(y_i - z_i)^2}
$$
其中$z_i$是网络对第$i$个样本的预测值:
$$
z_i = \sum_{j=0}^{12}{x_i^{j}\cdot w_j} + b
$$
梯度的定义:
$$
𝑔𝑟𝑎𝑑𝑖𝑒𝑛𝑡 = (\frac{\partial{L}}{\partial{w_0}},\frac{\partial{L}}{\partial{w_1}}, … ,\frac{\partial{L}}{\partial{w_{12}}} ,\frac{\partial{L}}{\partial{b}})
$$
可以计算出$L$对$w$和$b$的偏导数:
$$
\frac{\partial{L}}{\partial{w_j}} = \frac{1}{N}\sum_{i=1}^N{(z_i - y_i)\frac{\partial{z_i}}{\partial{w_j}}} = \frac{1}{N}\sum_{i=1}^N{(z_i - y_i)x_i^{j}}
$$
$$
\frac{\partial{L}}{\partial{b}} = \frac{1}{N}\sum_{i=1}^N{(z_i - y_i)\frac{\partial{z_i}}{\partial{b}}} = \frac{1}{N}\sum_{i=1}^N{(z_i - y_i)}
$$
从导数的计算过程可以看出,因子$\frac{1}{2}$被消掉了,这是因为二次函数求导的时候会产生因子$2$,这也是我们将损失函数改写的原因。
下面我们考虑只有一个样本的情况下,计算梯度:
$$
L= \frac{1}{2}{(y_i - z_i)^2}
$$
$$
z_1 = {x_1^{0}\cdot w_0} + {x_1^{1}\cdot w_1} + … + {x_1^{12}\cdot w_{12}} + b
$$
可以计算出:
$$
L= \frac{1}{2}{({x_1^{0}\cdot w_0} + {x_1^{1}\cdot w_1} + … + {x_1^{12}\cdot w_{12}} + b - y_1)^2}
$$
可以计算出$L$对$w$和$b$的偏导数:
$$
\frac{\partial{L}}{\partial{w_0}} = ({x_1^{0}\cdot w_0} + {x_1^{1}\cdot w_1} + … + {x_1^{12}\cdot w_12} + b - y_1)\cdot x_1^{0}=({z_1} - {y_1})\cdot x_1^{0}
$$
$$
\frac{\partial{L}}{\partial{b}} = ({x_1^{0}\cdot w_0} + {x_1^{1}\cdot w_1} + … + {x_1^{12}\cdot w_{12}} + b - y_1)\cdot 1 = ({z_1} - {y_1}) (公式23)
$$
1 | |
2.4.3 使用NumPy进行梯度计算
基于NumPy广播机制(对向量和矩阵计算如同对1个单一变量计算一样),可以更快速的实现梯度计算。计算梯度的代码中直接用$(z_1 - y_1) \cdot x_1$,得到的是一个13维的向量,每个分量分别代表该维度的梯度。
1 | |
此处可见,计算梯度gradient_w的维度是$3 \times 13$,并且其第1行与上面第1个样本计算的梯度gradient_w_by_sample1一致,第2行与上面第2个样本计算的梯度gradient_w_by_sample2一致,第3行与上面第3个样本计算的梯度gradient_w_by_sample3一致。这里使用矩阵操作,可以更加方便的对3个样本分别计算各自对梯度的贡献。
那么对于有N个样本的情形,我们可以直接使用如下方式计算出所有样本对梯度的贡献,这就是使用NumPy库广播功能带来的便捷。
小结一下这里使用NumPy库的广播功能:
- 一方面可以扩展参数的维度,代替for循环来计算1个样本对从$w_0$到$w_{12}$的所有参数的梯度。
列表征特征维度 - 另一方面可以扩展样本的维度,代替for循环来计算样本0到样本403对参数的梯度。
行表征样本维度
1 | |
上面gradient_w的每一行代表了一个样本对梯度的贡献。根据梯度的计算公式,总梯度是对每个样本对梯度贡献的平均值。
$$
\frac{\partial{L}}{\partial{w_j}} = \frac{1}{N}\sum_{i=1}^N{(z_i - y_i)\frac{\partial{z_i}}{\partial{w_j}}} = \frac{1}{N}\sum_{i=1}^N{(z_i - y_i)x_i^{j}}
$$
可以使用NumPy的均值函数来完成此过程,代码实现如下。
1 | |
使用NumPy的矩阵操作方便地完成了gradient的计算,但引入了一个问题,gradient_w的形状是(13,),而$w$的维度是(13, 1)。导致该问题的原因是使用np.mean函数时消除了第0维。为了加减乘除等计算方便,gradient_w和$w$必须保持一致的形状。因此我们将gradient_w的维度也设置为(13,1),代码如下:
1 | |
梯度计算综合代码:
1 | |
偏置计算综合代码:
1 | |
总结为OOP的函数:
1 | |
2.4.4 梯度更新
下面研究更新梯度的方法,确定损失函数更小的点。首先沿着梯度的反方向移动一小步,找到下一个点P1,观察损失函数的变化。
1 | |
运行上面的代码,可以发现沿着梯度反方向走一小步,下一个点的损失函数的确减少了。感兴趣的话,大家可以尝试不停的点击上面的代码块,观察损失函数是否一直在变小。
在上述代码中,每次更新参数使用的语句:net.w[5] = net.w[5] - eta * gradient_w5
- 相减:参数需要向梯度的反方向移动。
- eta:控制每次参数值沿着梯度反方向变动的大小,即每次移动的步长,又称为学习率。
大家可以思考下,为什么之前我们要做输入特征的归一化,保持尺度一致?这是为了让统一的步长更加合适,使训练更加高效。
如 图8 所示,特征输入归一化后,不同参数输出的Loss是一个比较规整的曲线,学习率可以设置成统一的值 ;特征输入未归一化时,不同特征对应的参数所需的步长不一致,尺度较大的参数需要大步长,尺寸较小的参数需要小步长,导致无法设置统一的学习率。
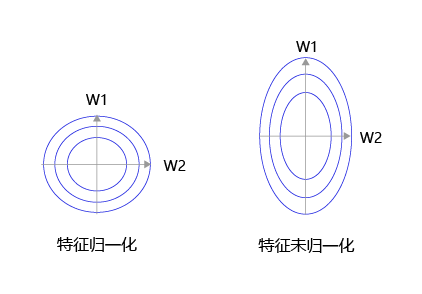
图8:未归一化的特征,会导致不同特征维度的理想步长不同
将上面的循环计算过程封装在train和update函数中,实现方法如下所示。
1 | |
2.4.6 训练过程扩展到全部参数
为了能给读者直观的感受,上文演示的梯度下降的过程仅包含$w_5$和$w_9$两个参数。但房价预测的模型必须要对所有参数$w$和$b$进行求解,这需要将Network中的update和train函数进行修改。由于不再限定参与计算的参数(所有参数均参与计算),修改之后的代码反而更加简洁。
实现逻辑:“前向计算输出、根据输出和真实值计算Loss、基于Loss和输入计算梯度、根据梯度更新参数值”四个部分反复执行,直到到损失函数最小。
1 | |
2.4.7 随机梯度下降法( Stochastic Gradient Descent)
在上述程序中,每次损失函数和梯度计算都是基于数据集中的全量数据。对于波士顿房价预测任务数据集而言,样本数比较少,只有404个。但在实际问题中,数据集往往非常大,如果每次都使用全量数据进行计算,效率非常低,通俗地说就是“杀鸡焉用牛刀”。由于参数每次只沿着梯度反方向更新一点点,因此方向并不需要那么精确。一个合理的解决方案是每次从总的数据集中随机抽取出小部分数据来代表整体,基于这部分数据计算梯度和损失来更新参数,这种方法被称作随机梯度下降法(Stochastic Gradient Descent,SGD),核心概念如下:
- mini-batch:每次迭代时抽取出来的一批数据被称为一个mini-batch。
- batch_size:一个mini-batch所包含的样本数目称为batch_size。
- epoch:当程序迭代的时候,按mini-batch逐渐抽取出样本,当把整个数据集都遍历到了的时候,则完成了一轮训练,也叫一个epoch。启动训练时,可以将训练的轮数num_epochs和batch_size作为参数传入。
下面结合程序介绍具体的实现过程,涉及到数据处理和训练过程两部分代码的修改。
- 数据处理代码修改
数据处理需要实现拆分数据批次和样本乱序(为了实现随机抽样的效果)两个功能。
1 | |
观察上述Loss的变化,随机梯度下降加快了训练过程,但由于每次仅基于少量样本更新参数和计算损失,所以损失下降曲线会出现震荡。
说明:
由于房价预测的数据量过少,所以难以感受到随机梯度下降带来的性能提升。
2.5 模型保存
Numpy提供了save接口,可直接将模型权重数组保存为.npy格式的文件。
1 | |
2.5 小结
本节我们详细介绍了如何使用NumPy实现梯度下降算法,构建并训练了一个简单的线性模型实现波士顿房价预测,可以总结出,使用神经网络建模房价预测有三个要点:
构建网络,初始化参数$w$和$b$,定义预测和损失函数的计算方法。
随机选择初始点,建立梯度的计算方法和参数更新方式。
从总的数据集中抽取部分数据作为一个mini_batch,计算梯度并更新参数,不断迭代直到损失函数几乎不再下降。
2.7 框架实现
1 | |
3.实例二“手写文字识别”
1.单层网络多元逻辑回归模型
模型设计
在房价预测深度学习任务中,我们使用了单层且没有非线性变换的模型,取得了理想的预测效果。在手写数字识别中,我们依然使用这个模型预测输入的图形数字值。其中,模型的输入为784维(28×28)数据,输出为1维数据,如 图5 所示。
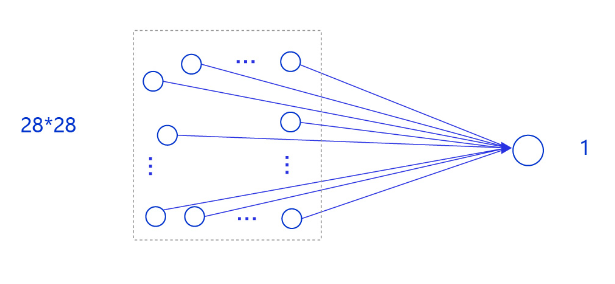
图5:手写数字识别网络模型
输入像素的位置排布信息对理解图像内容非常重要(如将原始尺寸为28×28图像的像素按照7×112的尺寸排布,那么其中的数字将不可识别),因此网络的输入设计为28×28的尺寸,而不是1×784,以便于模型能够正确处理像素之间的空间信息。
说明:
事实上,采用只有一层的简单网络(对输入求加权和)时并没有处理位置关系信息,因此可以猜测出此模型的预测效果可能有限。在后续优化环节介绍的卷积神经网络则更好的考虑了这种位置关系信息,模型的预测效果也会有显著提升。
下面以类的方式组建手写数字识别的网络,实现方法如下所示。
1 | |
训练配置
训练配置需要先生成模型实例(设为“训练”状态),再设置优化算法和学习率(使用随机梯度下降SGD,学习率设置为0.001),实现方法如下所示。
1 | |
训练过程
训练过程采用二层循环嵌套方式,训练完成后需要保存模型参数,以便后续使用。
- 内层循环:负责整个数据集的一次遍历,遍历数据集采用分批次(batch)方式。
- 外层循环:定义遍历数据集的次数,本次训练中外层循环10次,通过参数EPOCH_NUM设置。
1 | |
1 | |
另外,从训练过程中损失所发生的变化可以发现,虽然损失整体上在降低,但到训练的最后一轮,损失函数值依然较高。可以猜测手写数字识别完全复用房价预测的代码,训练效果并不好。接下来我们通过模型测试,获取模型训练的真实效果。
模型测试
模型测试的主要目的是验证训练好的模型是否能正确识别出数字,包括如下四步:
- 声明实例
- 加载模型:加载训练过程中保存的模型参数,
- 灌入数据:将测试样本传入模型,模型的状态设置为校验状态(eval),显式告诉框架我们接下来只会使用前向计算的流程,不会计算梯度和梯度反向传播。
- 获取预测结果,取整后作为预测标签输出。
在模型测试之前,需要先从’./work/example_0.png’文件中读取样例图片,并进行归一化处理。
1 | |
1 | |
小结
灰度图:0是黑,255是白
重要函数:
enumerate(train_loader())将迭代器进行迭代np.reshape(1, -1)将ndtype数组转为1维行向量,**-1为占位符**,列数看有多少列就多少列
2.多层网络改进模型
数据同步读取与训练
1 | |
1 | |
上面提到的数据读取采用的是同步数据读取方式。对于样本量较大、数据读取较慢的场景,建议采用异步数据读取方式。异步读取数据时,数据读取和模型训练并行执行,从而加快了数据读取速度,牺牲一小部分内存换取数据读取效率的提升,二者关系如 图4 所示。
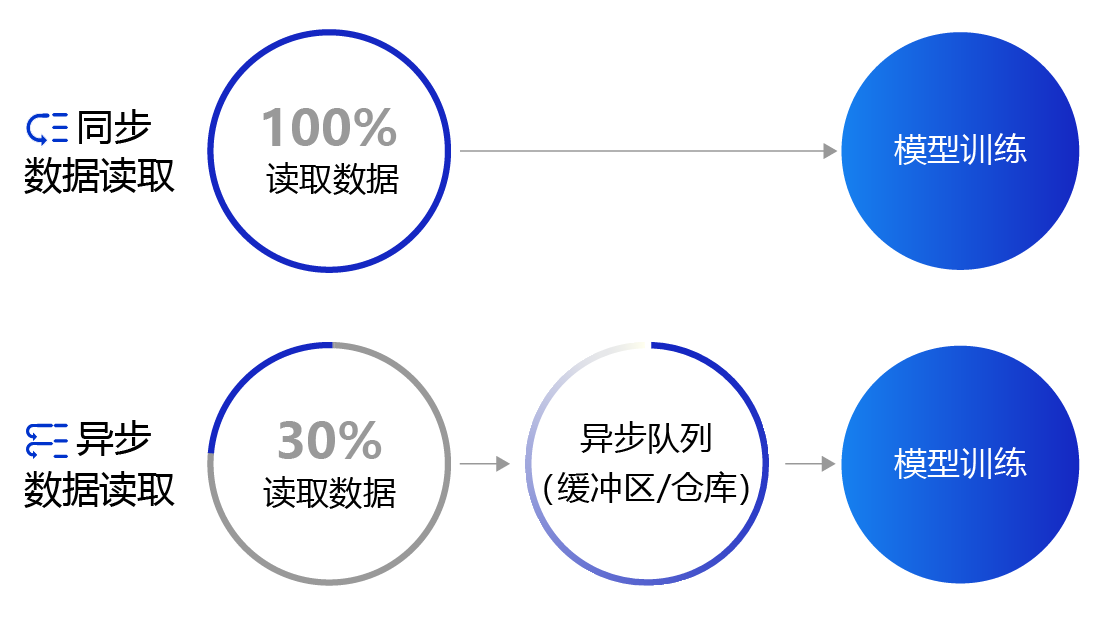
图4:同步数据读取和异步数据读取示意图
使用飞桨实现异步数据读取非常简单,只需要两个步骤:
- 构建一个继承paddle.io.Dataset类的数据读取器。
- 通过paddle.io.DataLoader创建异步数据读取的迭代器。
数据异步读取与训练
1 | |
1 | |
1 | |
小结
- 迭代器迭代器有两个基本的方法:创建迭代器iter() 和 访问迭代器**next()**。
可以直接作用于for循环的对象统称为可迭代对象:Iterable
一类是集合数据类型,如list、tuple、dict、set、str等;
一类是generator,包括生成器和带yield的generator function
迭代器对象从集合的第一个元素开始访问,直到所有的元素被访问完结束。迭代器只能往前不会后退。
- 生成器
如果列表元素可以按照某种算法推算出来,可以在循环的过程中不断推算出后续的元素,这样就不必创建完整的list,从而节省大量的空间。在Python中,这种一边循环一边计算的机制,称为生成器:generator。
- yield:是一个生成器函数,返回的是一个迭代器
yield的作用:返回一个可以用来迭代(for循环)的生成器,它的应用场景通常为一个需要返回一系列值的,含有循环的函数中。
- assert:
assert a > 0,"a超出范围"如果a>0则顺序执行,否则抛出异常提示a超出范围
3.模型设计之损失函数
在之前的方案中,我们复用了房价预测模型的损失函数-均方误差。从预测效果来看,虽然损失不断下降,模型的预测值逐渐逼近真实值,但模型的最终效果不够理想。究其根本,不同的深度学习任务需要有各自适宜的损失函数。我们以房价预测和手写数字识别两个任务为例,详细剖析其中的缘由如下:
- 房价预测是回归任务,而手写数字识别是分类任务,使用均方误差作为分类任务的损失函数存在逻辑和效果上的缺欠。
- 房价可以是大于0的任何浮点数,而手写数字识别的输出只可能是0~9之间的10个整数,相当于一种标签。
- 在房价预测的案例中,由于房价本身是一个连续的实数值,因此以模型输出的数值和真实房价差距作为损失函数(Loss)是符合道理的。但对于分类问题,真实结果是分类标签,而模型输出是实数值,导致以两者相减作为损失不具备物理含义。
Softmax函数
如果模型能输出10个标签的概率,对应真实标签的概率输出尽可能接近100%,而其他标签的概率输出尽可能接近0%,且所有输出概率之和为1。这是一种更合理的假设!与此对应,真实的标签值可以转变成一个10维度的one-hot向量,在对应数字的位置上为1,其余位置为0,比如标签“6”可以转变成[0,0,0,0,0,0,1,0,0,0]。
为了实现上述思路,需要引入Softmax函数,它可以将原始输出转变成对应标签的概率,公式如下,其中$C$是标签类别个数。
$$
softmax(x_i) = \frac {e^{x_i}}{\sum_{j=0}^N{e^{x_j}}}, i=0, …, C-1
$$
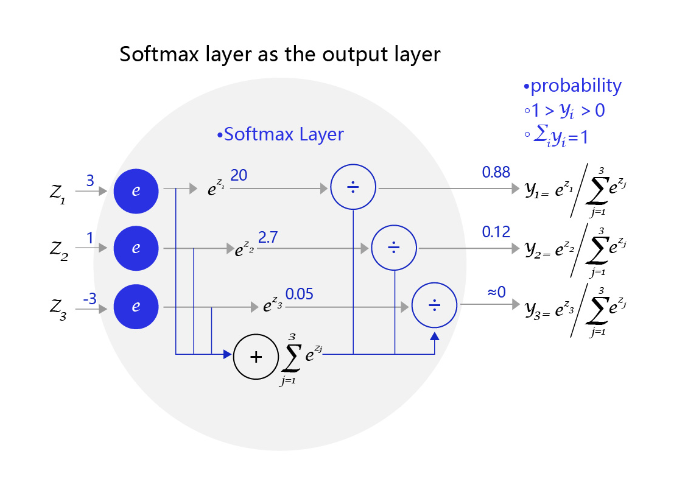
从公式的形式可见,每个输出的范围均在0~1之间,且所有输出之和等于1,这是这种变换后可被解释成概率的基本前提。对应到代码上,需要在前向计算中,对全连接网络的输出层增加一个Softmax运算,outputs = F.softmax(outputs)。
图3 是一个三个标签的分类模型(三分类)使用的Softmax输出层,从中可见原始输出的三个数字3、1、-3,经过Softmax层后转变成加和为1的三个概率值0.88、0.12、0。
交叉熵
在模型输出为分类标签的概率时,直接以标签和概率做比较也不够合理,人们更习惯使用交叉熵误差作为分类问题的损失衡量。
交叉熵损失函数的设计是基于最大似然思想:最大概率得到观察结果的假设是真的。如何理解呢?举个例子来说,如 图7 所示。有两个外形相同的盒子,甲盒中有99个白球,1个蓝球;乙盒中有99个蓝球,1个白球。一次试验取出了一个蓝球,请问这个球应该是从哪个盒子中取出的?
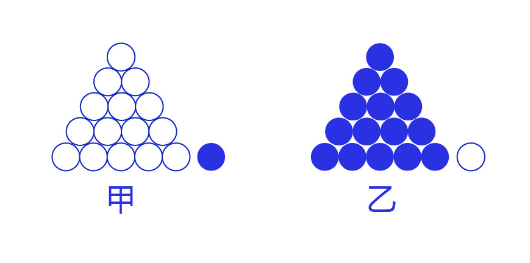
图7:体会最大似然的思想
相信大家简单思考后均会得出更可能是从乙盒中取出的,因为从乙盒中取出一个蓝球的概率更高$(P(D|h))$,所以观察到一个蓝球更可能是从乙盒中取出的$(P(h|D))$。$D$是观测的数据,即蓝球白球;$h$是模型,即甲盒乙盒。这就是贝叶斯公式所表达的思想:
$$P(h|D) ∝ P(h) \cdot P(D|h)$$
依据贝叶斯公式,某二分类模型“生成”$n$个训练样本的概率:
$$P(x_1)\cdot S(w^{T}x_1)\cdot P(x_2)\cdot(1-S(w^{T}x_2))\cdot … \cdot P(x_n)\cdot S(w^{T}x_n)$$
说明:
对于二分类问题,模型为$S(w^{T}x_i)$,$S$为Sigmoid函数。当$y_i$=1,概率为$S(w^{T}x_i)$;当$y_i$=0,概率为$1-S(w^{T}x_i)$。
经过公式推导,使得上述概率最大等价于最小化交叉熵,得到交叉熵的损失函数。交叉熵的公式如下:
$$ L = -[\sum_{k=1}^{n} t_k\log y_k +(1- t_k)\log(1-y_k)] $$
其中,$\log$表示以$e$为底数的自然对数。$y_k$代表模型输出,$t_k$代表各个标签。$t_k$中只有正确解的标签为1,其余均为0(one-hot表示)。
因此,交叉熵只计算对应着“正确解”标签的输出的自然对数。比如,假设正确标签的索引是“2”,与之对应的神经网络的输出是0.6,则交叉熵误差是$−\log 0.6 = 0.51$;若“2”对应的输出是0.1,则交叉熵误差为$−\log 0.1 = 2.30$。由此可见,交叉熵误差的值是由正确标签所对应的输出结果决定的。
自然对数的函数曲线可由如下代码实现。
1 | |
总结
分类任务
- 数据处理部分:将输入的标签label数据类型改为int64型
- 网络定义部分:全连接层输出应该用SoftMax处理,将单一输出改为各类的输出概率,所有概率之和为1。
- 训练过程部分:损失函数改为交叉熵
4.训练配置之优化器
设置学习率
在深度学习神经网络模型中,通常使用标准的随机梯度下降算法更新参数,学习率代表参数更新幅度的大小,即步长。当学习率最优时,模型的有效容量最大,最终能达到的效果最好。学习率和深度学习任务类型有关,合适的学习率往往需要大量的实验和调参经验。探索学习率最优值时需要注意如下两点:
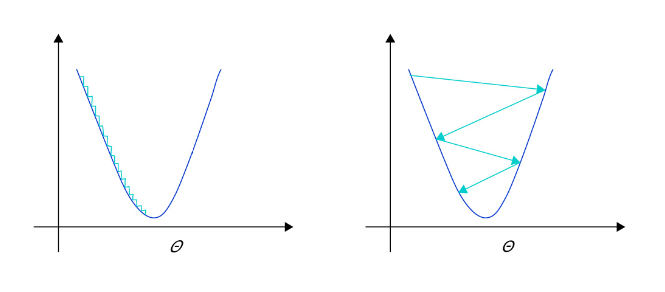
- 学习率不是越小越好。学习率越小,损失函数的变化速度越慢,意味着我们需要花费更长的时间进行收敛,如 图2 左图所示。
- 学习率不是越大越好。只根据总样本集中的一个批次计算梯度,抽样误差会导致计算出的梯度不是全局最优的方向,且存在波动。在接近最优解时,过大的学习率会导致参数在最优解附近震荡,损失难以收敛,如 图2 右图所示。
在训练前,我们往往不清楚一个特定问题设置成怎样的学习率是合理的,因此在训练时可以尝试调小或调大,通过观察Loss下降的情况判断合理的学习率.
学习率的主流优化算法
学习率是优化器的一个参数,调整学习率看似是一件非常麻烦的事情,需要不断的调整步长,观察训练时间和Loss的变化。经过研究员的不断的实验,当前已经形成了四种比较成熟的优化算法:SGD、Momentum、AdaGrad和Adam,效果如 图3 所示。
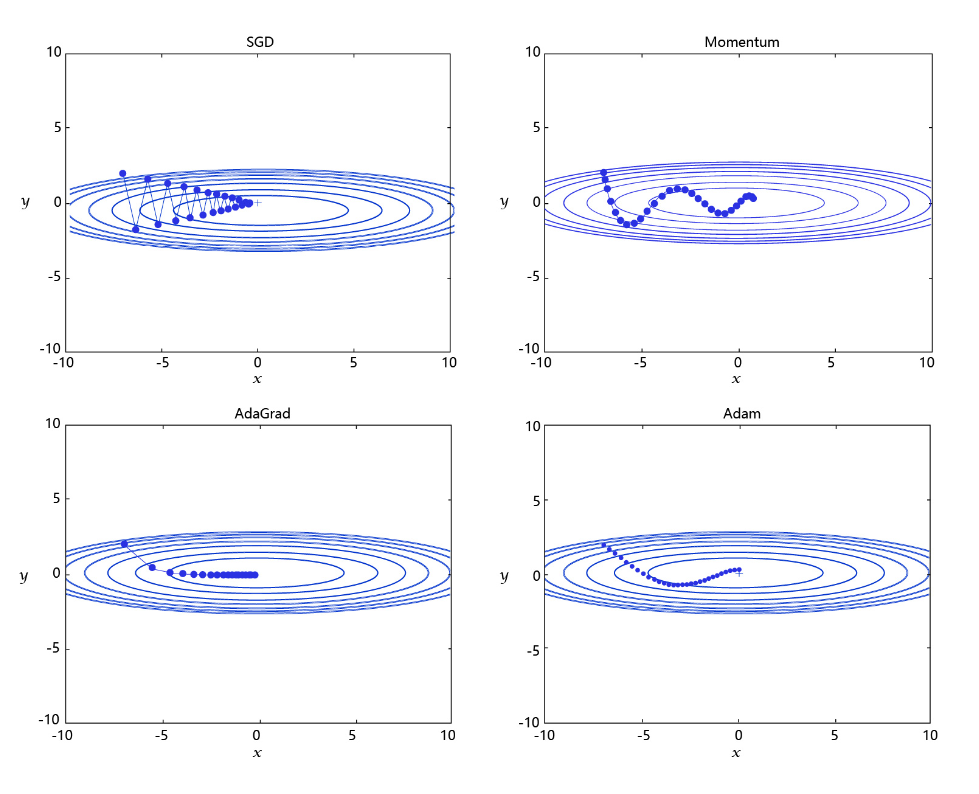
每个批次的数据含有抽样误差,导致梯度更新的方向波动较大。如果我们引入物理动量的概念,给梯度下降的过程加入一定的“惯性”累积,就可以减少更新路径上的震荡,即每次更新的梯度由“历史多次梯度的累积方向”和“当次梯度”加权相加得到。历史多次梯度的累积方向往往是从全局视角更正确的方向,这与“惯性”的物理概念很像,也是为何其起名为“Momentum”的原因。类似不同品牌和材质的篮球有一定的重量差别,街头篮球队中的投手(擅长中远距离投篮)喜欢稍重篮球的比例较高。一个很重要的原因是,重的篮球惯性大,更不容易受到手势的小幅变形或风吹的影响。
- AdaGrad: 根据不同参数距离最优解的远近,动态调整学习率。学习率逐渐下降,依据各参数变化大小调整学习率。
通过调整学习率的实验可以发现:当某个参数的现值距离最优解较远时(表现为梯度的绝对值较大),我们期望参数更新的步长大一些,以便更快收敛到最优解。当某个参数的现值距离最优解较近时(表现为梯度的绝对值较小),我们期望参数的更新步长小一些,以便更精细的逼近最优解。类似于打高尔夫球,专业运动员第一杆开球时,通常会大力打一个远球,让球尽量落在洞口附近。当第二杆面对离洞口较近的球时,他会更轻柔而细致的推杆,避免将球打飞。与此类似,参数更新的步长应该随着优化过程逐渐减少,减少的程度与当前梯度的大小有关。根据这个思想编写的优化算法称为“AdaGrad”,Ada是Adaptive的缩写,表示“适应环境而变化”的意思。RMSProp是在AdaGrad基础上的改进,学习率随着梯度变化而适应,解决AdaGrad学习率急剧下降的问题。
- Adam: 由于动量和自适应学习率两个优化思路是正交的,因此可以将两个思路结合起来,这就是当前广泛应用的算法。
5.调试优化
训练过程优化思路主要有如下五个关键环节:
1. 计算分类准确率,观测模型训练效果。
交叉熵损失函数只能作为优化目标,无法直接准确衡量模型的训练效果。准确率可以直接衡量训练效果,但由于其离散性质,不适合做为损失函数优化神经网络。
2. 检查模型训练过程,识别潜在问题。
如果模型的损失或者评估指标表现异常,通常需要打印模型每一层的输入和输出来定位问题,分析每一层的内容来获取错误的原因。
3. 加入校验或测试,更好评价模型效果。
理想的模型训练结果是在训练集和验证集上均有较高的准确率,如果训练集的准确率低于验证集,说明网络训练程度不够;如果训练集的准确率高于验证集,可能是发生了过拟合现象。通过在优化目标中加入正则化项的办法,解决过拟合的问题。
4. 加入正则化项,避免模型过拟合。
飞桨框架支持为整体参数加入正则化项,这是通常的做法。此外,飞桨框架也支持为某一层或某一部分的网络单独加入正则化项,以达到精细调整参数训练的效果。
5. 可视化分析。
用户不仅可以通过打印或使用matplotlib库作图,飞桨还提供了更专业的可视化分析工具VisualDL,提供便捷的可视化分析方法。
计算模型的分类准确率
准确率是一个直观衡量分类模型效果的指标,由于这个指标是离散的,因此不适合作为损失来优化。通常情况下,交叉熵损失越小的模型,分类的准确率也越高。基于分类准确率,我们可以公平地比较两种损失函数的优劣,例如在【手写数字识别】之损失函数章节中均方误差和交叉熵的比较。
使用飞桨提供的计算分类准确率API,可以直接计算准确率。
class paddle.metric.Accuracy
该API的输入参数input为预测的分类结果predict,输入参数label为数据真实的label。飞桨还提供了更多衡量模型效果的计算指标,详细可以查看paddle.meric包下面的API。
在下述代码中,我们在模型前向计算过程forward函数中计算分类准确率,并在训练时打印每个批次样本的分类准确率。
1 | |
1 | |
检查模型训练过程,识别潜在训练问题
使用飞桨动态图编程可以方便的查看和调试训练的执行过程。在网络定义的Forward函数中,可以打印每一层输入输出的尺寸,以及每层网络的参数。通过查看这些信息,不仅可以更好地理解训练的执行过程,还可以发现潜在问题,或者启发继续优化的思路。
在下述程序中,使用check_shape变量控制是否打印“尺寸”,验证网络结构是否正确。使用check_content变量控制是否打印“内容值”,验证数据分布是否合理。假如在训练中发现中间层的部分输出持续为0,说明该部分的网络结构设计存在问题,没有充分利用。
1 | |
加入校验或测试,更好评价模型效果
在训练过程中,我们会发现模型在训练样本集上的损失在不断减小。但这是否代表模型在未来的应用场景上依然有效?为了验证模型的有效性,通常将样本集合分成三份,训练集、校验集和测试集。
- 训练集 :用于训练模型的参数,即训练过程中主要完成的工作。
- 校验集 :用于对模型超参数的选择,比如网络结构的调整、正则化项权重的选择等。
- 测试集 :用于模拟模型在应用后的真实效果。因为测试集没有参与任何模型优化或参数训练的工作,所以它对模型来说是完全未知的样本。在不以校验数据优化网络结构或模型超参数时,校验数据和测试数据的效果是类似的,均更真实的反映模型效果。
如下程序读取上一步训练保存的模型参数,读取校验数据集,并测试模型在校验数据集上的效果。
1 | |
加入正则化项,避免模型过拟合
过拟合现象
对于样本量有限、但需要使用强大模型的复杂任务,模型很容易出现过拟合的表现,即在训练集上的损失小,在验证集或测试集上的损失较大,如 图2 所示。
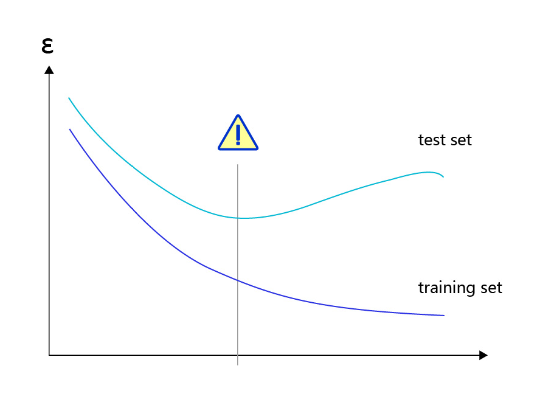
反之,如果模型在训练集和测试集上均损失较大,则称为欠拟合。过拟合表示模型过于敏感,学习到了训练数据中的一些误差,而这些误差并不是真实的泛化规律(可推广到测试集上的规律)。欠拟合表示模型还不够强大,还没有很好的拟合已知的训练样本,更别提测试样本了。因为欠拟合情况容易观察和解决,只要训练loss不够好,就不断使用更强大的模型即可,因此实际中我们更需要处理好过拟合的问题。
导致过拟合原因
造成过拟合的原因是模型过于敏感,而训练数据量太少或其中的噪音太多。
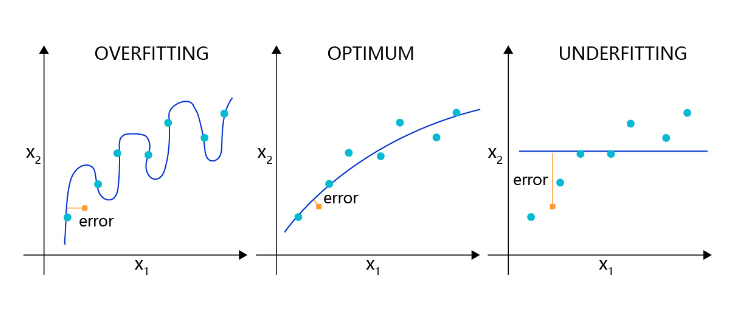
如图3 所示,理想的回归模型是一条坡度较缓的抛物线,欠拟合的模型只拟合出一条直线,显然没有捕捉到真实的规律,但过拟合的模型拟合出存在很多拐点的抛物线,显然是过于敏感,也没有正确表达真实规律。
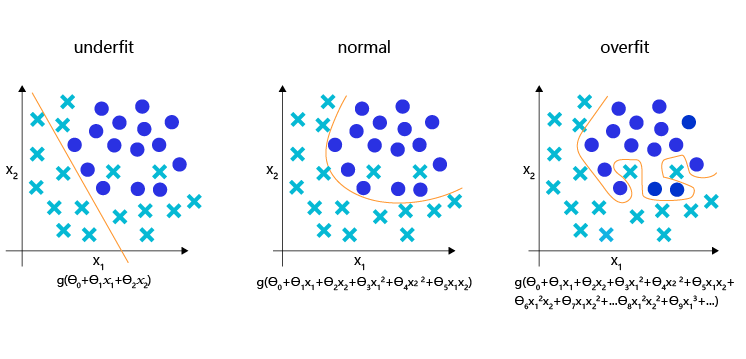
如图4 所示,理想的分类模型是一条半圆形的曲线,欠拟合用直线作为分类边界,显然没有捕捉到真实的边界,但过拟合的模型拟合出很扭曲的分类边界,虽然对所有的训练数据正确分类,但对一些较为个例的样本所做出的妥协,高概率不是真实的规律。
过拟合的成因与防控
为了更好的理解过拟合的成因,可以参考侦探定位罪犯的案例逻辑,如 图5 所示。
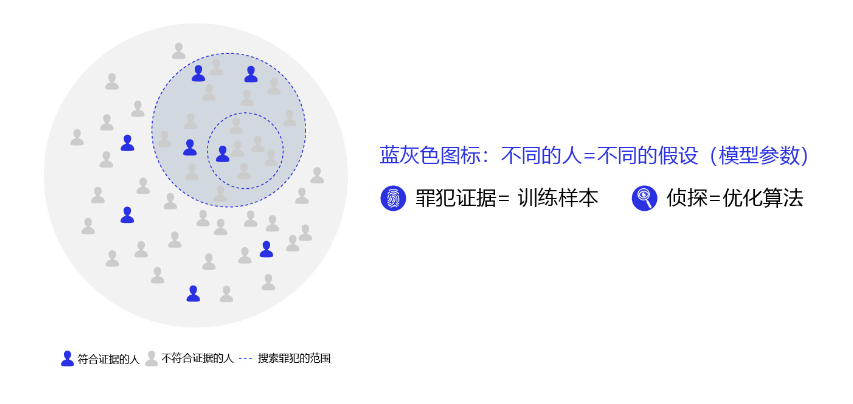
对于这个案例,假设侦探也会犯错,通过分析发现可能的原因:
- 情况1:罪犯证据存在错误,依据错误的证据寻找罪犯肯定是缘木求鱼。
- 情况2:搜索范围太大的同时证据太少,导致符合条件的候选(嫌疑人)太多,无法准确定位罪犯。
那么侦探解决这个问题的方法有两种:或者缩小搜索范围(比如假设该案件只能是熟人作案),或者寻找更多的证据。
归结到深度学习中,假设模型也会犯错,通过分析发现可能的原因:
- 情况1:训练数据存在噪音,导致模型学到了噪音,而不是真实规律。
- 情况2:使用强大模型(表示空间大)的同时训练数据太少,导致在训练数据上表现良好的候选假设太多,锁定了一个“虚假正确”的假设。
对于情况1,我们使用数据清洗和修正来解决。 对于情况2,我们或者限制模型表示能力,或者收集更多的训练数据。
而清洗训练数据中的错误,或收集更多的训练数据往往是一句“正确的废话”,在任何时候我们都想获得更多更高质量的数据。在实际项目中,更快、更低成本可控制过拟合的方法,只有限制模型的表示能力。
正则化项
为了防止模型过拟合,在没有扩充样本量的可能下,只能降低模型的复杂度,可以通过限制参数的数量或可能取值(参数值尽量小)实现。
具体来说,在模型的优化目标(损失)中人为加入对参数规模的惩罚项。当参数越多或取值越大时,该惩罚项就越大。通过调整惩罚项的权重系数,可以使模型在“尽量减少训练损失”和“保持模型的泛化能力”之间取得平衡。泛化能力表示模型在没有见过的样本上依然有效。正则化项的存在,增加了模型在训练集上的损失。
飞桨支持为所有参数加上统一的正则化项,也支持为特定的参数添加正则化项。前者的实现如下代码所示,仅在优化器中设置weight_decay参数即可实现。使用参数coeff调节正则化项的权重,权重越大时,对模型复杂度的惩罚越高。
1 | |
6.可视化分析
训练模型时,经常需要观察模型的评价指标,分析模型的优化过程,以确保训练是有效的。可选用这两种工具:Matplotlib库和VisualDL。
- Matplotlib库:Matplotlib库是Python中使用的最多的2D图形绘图库,它有一套完全仿照MATLAB的函数形式的绘图接口,使用轻量级的PLT库(Matplotlib)作图是非常简单的。
- VisualDL:如果期望使用更加专业的作图工具,可以尝试VisualDL,飞桨可视化分析工具。VisualDL能够有效地展示飞桨在运行过程中的计算图、各种指标变化趋势和数据信息。
使用Matplotlib库绘制损失随训练下降的曲线图
将训练的批次编号作为X轴坐标,该批次的训练损失作为Y轴坐标。
- 训练开始前,声明两个列表变量存储对应的批次编号(iters=[])和训练损失(losses=[])。
1 | |
- 随着训练的进行,将iter和losses两个列表填满。
1 | |
- 训练结束后,将两份数据以参数形式导入PLT的横纵坐标。
1 | |
- 最后,调用plt.plot()函数即可完成作图。
1 | |
详细代码如下:
1 | |
1 | |
使用VisualDL可视化分析
VisualDL是飞桨可视化分析工具,以丰富的图表呈现训练参数变化趋势、模型结构、数据样本、高维数据分布等。帮助用户清晰直观地理解深度学习模型训练过程及模型结构,进而实现高效的模型调优,具体代码实现如下。
- 步骤1:引入VisualDL库,定义作图数据存储位置(供第3步使用),本案例的路径是“log”。
1 | |
- 步骤2:在训练过程中插入作图语句。当每100个batch训练完成后,将当前损失作为一个新增的数据点(iter和acc的映射对)存储到第一步设置的文件中。使用变量iter记录下已经训练的批次数,作为作图的X轴坐标。
1 | |
7.模型加载及恢复训练
在快速入门中,我们已经介绍了将训练好的模型保存到磁盘文件的方法。应用程序可以随时加载模型,完成预测任务。但是在日常训练工作中我们会遇到一些突发情况,导致训练过程主动或被动的中断。如果训练一个模型需要花费几天的训练时间,中断后从初始状态重新训练是不可接受的。
万幸的是,飞桨支持从上一次保存状态开始训练,只要我们随时保存训练过程中的模型状态,就不用从初始状态重新训练。
下面介绍恢复训练的实现方法,依然使用手写数字识别的案例,网络定义的部分保持不变。
1 | |
定义训练Trainer,包含训练过程和模型保存
1 | |
恢复训练
模型恢复训练,需要重新组网,所以我们需要重启AIStudio,运行MnistDataset数据读取和MNIST网络定义、Trainer部分代码,再执行模型恢复代码
在上述训练代码中,我们训练了五轮(epoch)。在每轮结束时,我们均保存了模型参数和优化器相关的参数。
- 使用
model.state_dict()获取模型参数。 - 使用
opt.state_dict获取优化器和学习率相关的参数。 - 调用
paddle.save将参数保存到本地。
比如第一轮训练保存的文件是mnist_epoch0.pdparams,mnist_epoch0.pdopt,分别存储了模型参数和优化器参数。
使用paddle.load分别加载模型参数和优化器参数,如下代码所示。
1 | |
如何判断模型是否准确的恢复训练呢?
理想的恢复训练是模型状态回到训练中断的时刻,恢复训练之后的梯度更新走向是和恢复训练前的梯度走向完全相同的。基于此,我们可以通过恢复训练后的损失变化,判断上述方法是否能准确的恢复训练。即从epoch 0结束时保存的模型参数和优化器状态恢复训练,校验其后训练的损失变化(epoch 1)是否和不中断时的训练相差不多。
说明:
恢复训练有如下两个要点:
- 保存模型时分别保存模型参数和优化器参数。
- 恢复参数时分别恢复模型参数和优化器参数。
下面的代码将展示恢复训练的过程,并验证恢复训练是否成功。加载模型参数并从第一个epoch开始训练,以便读者可以校验恢复训练后的损失变化。
1 | |
从恢复训练的损失变化来看,加载模型参数继续训练的损失函数值和正常训练损失函数值是相差不多的,可见使用飞桨实现恢复训练是极其简单的。 总结一下:
- 保存模型时同时保存模型参数和优化器参数;
1 | |
- 恢复参数时同时恢复模型参数和优化器参数。
1 | |
8.动静转换
动态图有诸多优点,比如易用的接口、Python风格的编程体验、友好的调试交互机制等。在动态图模式下,代码可以按照我们编写的顺序依次执行。这种机制更符合Python程序员的使用习惯,可以很方便地将脑海中的想法快速地转化为实际代码,也更容易调试。
但在性能方面,由于Python执行开销较大,与C++有一定差距,因此在工业界的许多部署场景中(如大型推荐系统、移动端)都倾向于直接使用C++进行提速。相比动态图,静态图在部署方面更具有性能的优势。静态图程序在编译执行时,先搭建模型的神经网络结构,然后再对神经网络执行计算操作。预先搭建好的神经网络可以脱离Python依赖,在C++端被重新解析执行,而且拥有整体网络结构也能进行一些网络结构的优化。
那么,有没有可能,深度学习框架实现一个新的模式,同时具备动态图高易用性与静态图高性能的特点呢?飞桨从2.0版本开始,新增新增支持动静转换功能,编程范式的选择更加灵活。用户依然使用动态图编写代码,只需添加一行装饰器 @paddle.jit.to_static,即可实现动态图转静态图模式运行,进行模型训练或者推理部署。在本章节中,将介绍飞桨动态图转静态图的基本用法和相关原理。
动态图转静态图训练
飞桨的动转静方式是基于源代码级别转换的ProgramTranslator实现,其原理是通过分析Python代码,将动态图代码转写为静态图代码,并在底层自动使用静态图执行器运行。其基本使用方法十分简便,只需要在要转化的函数(该函数也可以是用户自定义动态图Layer的forward函数)前添加一个装饰器 @paddle.jit.to_static。这种转换方式使得用户可以灵活使用Python语法及其控制流来构建神经网络模型。下面通过一个例子说明如何使用飞桨实现动态图转静态图训练。
1 | |
上述代码构建了仅有一层全连接层的手写字符识别网络。特别注意,在forward函数之前加了装饰器@paddle.jit.to_static,要求模型在静态图模式下运行。下面是模型的训练代码,由于飞桨实现动转静的功能是在内部完成的,对使用者来说,动态图的训练代码和动转静模型的训练代码是完全一致的。训练代码如下:
1 | |
我们可以观察到,动转静的训练方式与动态图训练代码是完全相同的。因此,在动转静训练的时候,开发者只需要在动态图的组网前向计算函数上添加一个装饰器即可实现动转静训练。 在模型构建和训练中,飞桨更希望借用动态图的易用性优势,实际上,在加上@to_static装饰器运行的时候,飞桨内部是在静态图模式下执行OP的,但是展示给开发者的依然是动态图的使用方式。
动转静更能体现静态图的方面在于模型部署上。下面将介绍动态图转静态图的部署方式。
动态图转静态图模型保存
在推理&部署场景中,需要同时保存推理模型的结构和参数,但是动态图是即时执行即时得到结果,并不会记录模型的结构信息。动态图在保存推理模型时,需要先将动态图模型转换为静态图写法,编译得到对应的模型结构再保存,而飞桨框架2.0版本推出paddle.jit.save和paddle.jit.load接口,无需重新实现静态图网络结构,直接实现动态图模型转成静态图模型格式。paddle.jit.save接口会自动调用飞桨框架2.0推出的动态图转静态图功能,使得用户可以做到使用动态图编程调试,自动转成静态图训练部署。
这两个接口的基本关系如下图所示:

当用户使用paddle.jit.save保存Layer对象时,飞桨会自动将用户编写的动态图Layer模型转换为静态图写法,并编译得到模型结构,同时将模型结构与参数保存。paddle.jit.save需要适配飞桨沿用已久的推理模型与参数格式,做到前向完全兼容,因此其保存格式与paddle.save有所区别,具体包括三种文件:保存模型结构的*.pdmodel文件;保存推理用参数的*.pdiparams文件和保存兼容变量信息的*.pdiparams.info文件,这几个文件后缀均为paddle.jit.save保存时默认使用的文件后缀。
比如,如果保存上述手写字符识别的inference模型用于部署,可以直接用下面代码实现:
1 | |
其中,paddle.jit.save API 将输入的网络存储为 paddle.jit.TranslatedLayer 格式的模型,载入后可用于预测推理或者fine-tune训练。 该接口会将输入网络转写后的模型结构 Program 和所有必要的持久参数变量存储至输入路径 path 。
path 是存储目标的前缀,存储的模型结构 Program 文件的后缀为 .pdmodel ,存储的持久参数变量文件的后缀为 .pdiparams ,同时这里也会将一些变量描述信息存储至文件,文件后缀为 .pdiparams.info。
通过调用对应的paddle.jit.load接口,可以把存储的模型载入为 paddle.jit.TranslatedLayer格式,用于预测推理或者fine-tune训练。
1 | |
paddle.jit.save API 可以把输入的网络结构和参数固化到一个文件中,所以通过加载保存的模型,可以不用重新构建网络结构而直接用于预测,易于模型部署。