二叉堆详解
本文最后更新于:2 个月前
二叉堆(Binary Heap)技术详解
目录
一、二叉堆的性质
1.1 基本定义
二叉堆(Binary Heap)是一种特殊的完全二叉树数据结构,满足堆性质(Heap Property)。它是实现优先级队列和堆排序算法的基础。
核心特征:
- 完全二叉树结构:所有层级都被填满,除了最后一层,且最后一层的节点从左到右填充
- 堆性质:每个节点的值与其子节点保持特定的大小关系
- 数组表示:可以高效地使用数组存储,无需指针
1.2 堆的两种类型
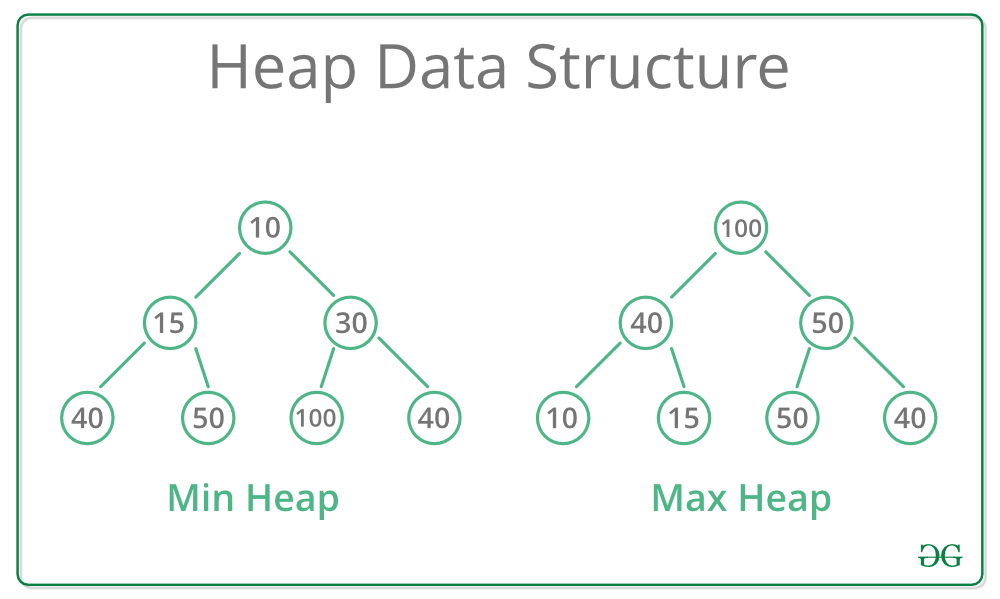
| 类型 | 定义 | 根节点特性 |
|---|---|---|
| 最小堆(Min Heap) | 父节点的值 ≤ 子节点的值 | 根节点为最小值 |
| 最大堆(Max Heap) | 父节点的值 ≥ 子节点的值 | 根节点为最大值 |
1.3 数组索引关系
二叉堆通常使用数组进行层级遍历(Level Order)存储。对于索引为 i 的节点(数组索引从0开始):
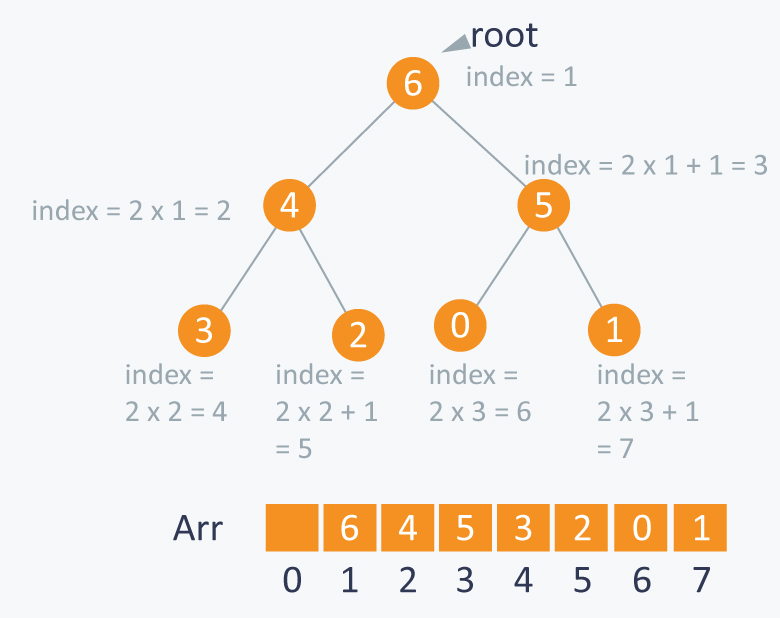
- 父节点索引:
parent(i) = floor((i - 1) / 2) - 左子节点索引:
left(i) = 2 * i + 1 - 右子节点索引:
right(i) = 2 * i + 2
示例:
1 | |
1.4 关键性质总结
- 高度性质:含有 n 个节点的二叉堆高度为 ⌊log₂n⌋
- 时间复杂度:
- 查询最值:O(1)
- 插入操作:O(log n)
- 删除操作:O(log n)
- 空间复杂度:O(n),使用数组紧凑存储
1.5 基础Java实现(最大堆)
1 | |
二、最常见的应用:优先级队列
2.1 概念说明
优先级队列(Priority Queue) 是一种抽象数据类型,其中每个元素都有关联的优先级。与FIFO(先进先出)的普通队列不同,优先级队列总是先处理优先级最高的元素。
二叉堆实现的优势:
- 插入和删除操作均为 O(log n)
- 查看最高优先级元素为 O(1)
- 空间效率高,实现简洁
2.2 堆操作示意图
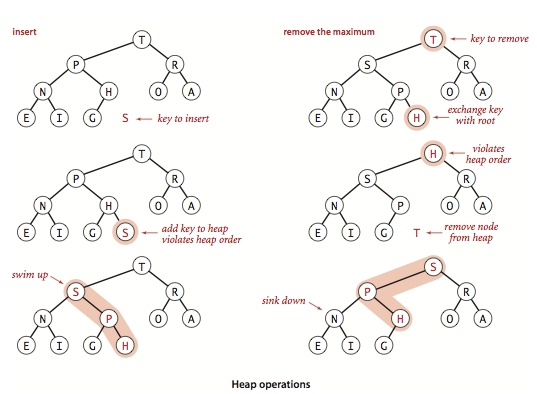
上图展示了堆的核心操作:
- 插入(Insert):新元素添加到末尾,然后上浮
- 删除最大值(Remove the Maximum):交换堆顶与末尾,删除末尾,然后下沉
2.3 完整Java实现(泛型优先级队列)
1 | |
2.4 使用Java标准库PriorityQueue
1 | |
三、另一种应用:堆排序
3.1 算法原理
堆排序(Heap Sort) 是一种基于二叉堆的比较排序算法,由J. W. J. Williams在1964年发明。其核心思想是利用堆的性质进行排序:
算法步骤:
- 建堆(Heapify):将无序数组构建成最大堆,时间复杂度 O(n)
- 排序阶段:重复将堆顶(最大值)与末尾元素交换,然后对剩余元素重新堆化
- 最终数组呈现升序排列
3.2 堆排序过程可视化
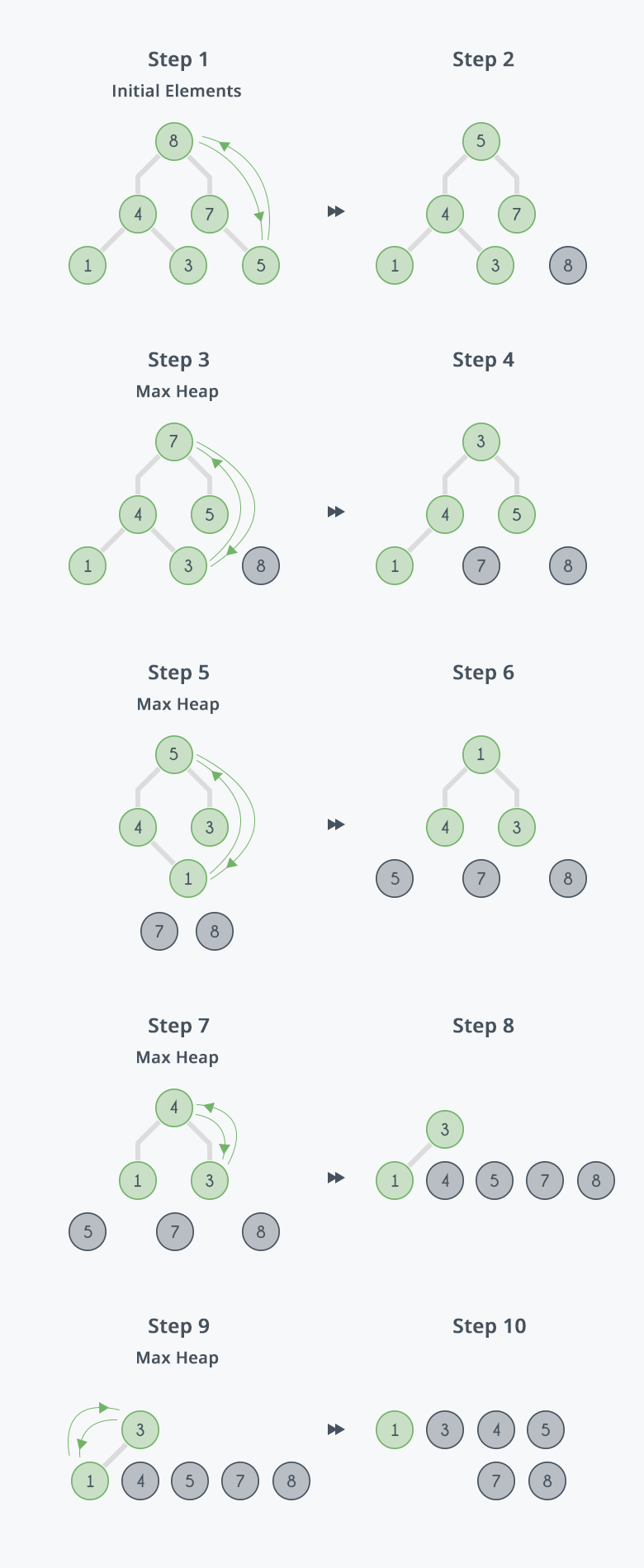
上图展示了堆排序的完整过程:
- Step 1-2:初始数组构建最大堆
- Step 3-10:每次将最大值移到数组末尾,并对剩余部分重新堆化
3.3 完整Java实现
1 | |
3.4 堆排序复杂度分析
| 指标 | 复杂度 | 说明 |
|---|---|---|
| 时间复杂度(最坏) | O(n log n) | 每次堆化为O(log n),执行n次 |
| 时间复杂度(最好) | O(n log n) | 与输入无关,始终一致 |
| 时间复杂度(平均) | O(n log n) | - |
| 空间复杂度 | O(1) | 原地排序,仅需常数额外空间 |
| 稳定性 | 不稳定 | 相等元素可能改变相对顺序 |
3.5 堆排序 Vs 其他排序算法
| 算法 | 时间复杂度 | 空间复杂度 | 稳定性 | 适用场景 |
|---|---|---|---|---|
| 堆排序 | O(n log n) | O(1) | 不稳定 | 内存受限,需要保证最坏情况性能 |
| 快速排序 | O(n log n) | O(log n) | 不稳定 | 通用场景,平均性能最好 |
| 归并排序 | O(n log n) | O(n) | 稳定 | 需要稳定排序,链表排序 |
| 插入排序 | O(n²) | O(1) | 稳定 | 小规模数据,基本有序数据 |
四、总结
二叉堆作为一种基础而强大的数据结构,在计算机科学中有着广泛的应用:
- 优先级队列:操作系统任务调度、Dijkstra最短路径算法、Huffman编码等
- 堆排序:内存受限环境下的高效排序选择
- 图算法:Prim最小生成树、A*寻路算法等
- 中位数查找:数据流中的动态中位数维护
- Top-K问题:快速查找最大/最小的K个元素
掌握二叉堆的实现原理,是理解更高级数据结构和算法的基础。通过本文提供的Java代码,您可以直接在实际项目中使用或根据需求进行定制优化。
参考资料:
- GeeksforGeeks - Binary Heap
- GeeksforGeeks - Heap Sort
- Interview Cake - Heapsort Algorithm
- Princeton Algorithms - Priority Queues
二叉堆详解
https://alleyf.github.io/2026/03/a215245c1453.html