集群
本文最后更新于:2 个月前
0.1 主从同步原理
MySQL主从复制的核心就是二进制日志
二进制日志(BINLOG)记录了所有的 DDL(数据定义语言)语句和 DML(数据操纵语言)语句,但不包括数据查询(SELECT、SHOW)语句。
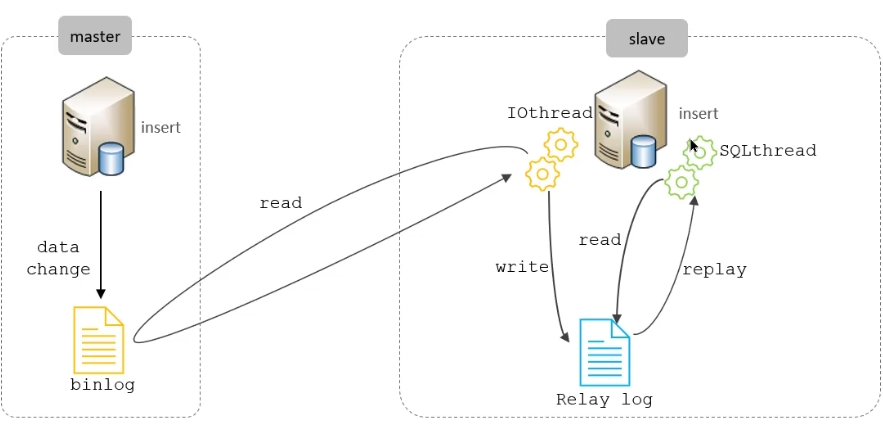
复制分成三步:
- Master 主库在事务提交时,会把数据变更记录在二进制日志文件 Binlog 中。
- 从库读取主库的二进制日志文件Binlog,写入到从库的中继日志 Relay Log 。
- slave重做中继日志中的事件,将改变反映它自已的数据。
0.2 分库分表
分库分表的时机:
- 前提:项目业务数据逐渐增多,或业务发展比较迅速,单表的数据量达1000W或20G以后
- 优化已解决不了性能问题(主从读写分离、查询索引…)
- IO瓶颈(磁盘IO、网络IO)、CPU瓶颈(聚合查询、连接数太多)
0.2.1 拆分策略
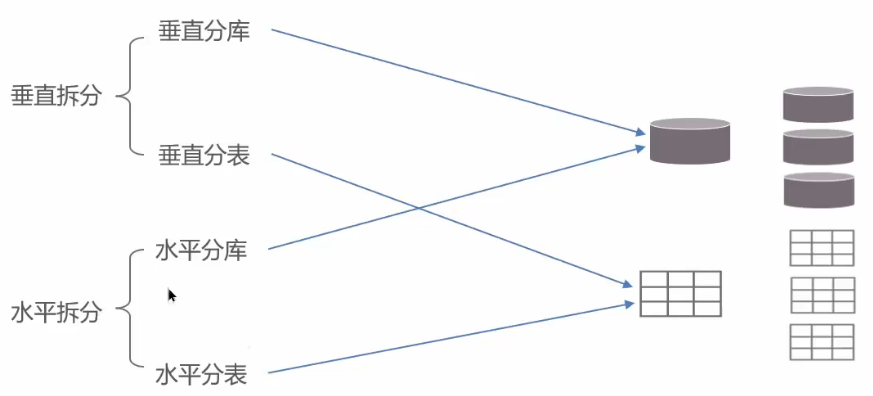
0.2.1.1 垂直分库
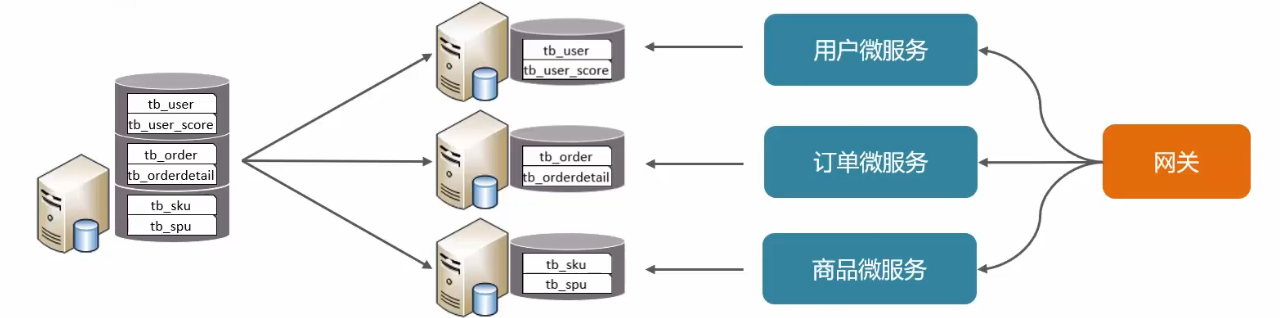
垂直分库:以表为依据,根据业务将不同表拆分到不同库中。
特点:
- 按业务对数据分级管理、维护、监控、扩展
- 在高并发下,提高磁盘IO和数据量连接数
0.2.1.2 垂直分表
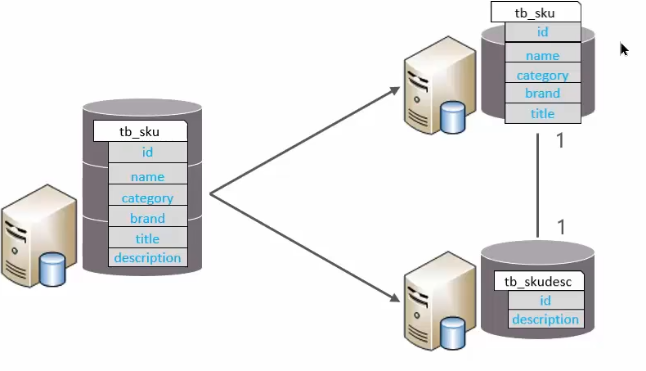
垂直分表:以字段为依据,根据字段属性将不同字段拆分到不同表中。特点:
- 冷热数据分离
- 减少IO过渡争抢,两表互不影响
拆分规则:
- 把不常用的字段单独放在一张表
- 把text,blob等大字段拆分出来放在附表中
0.2.1.3 水平分库
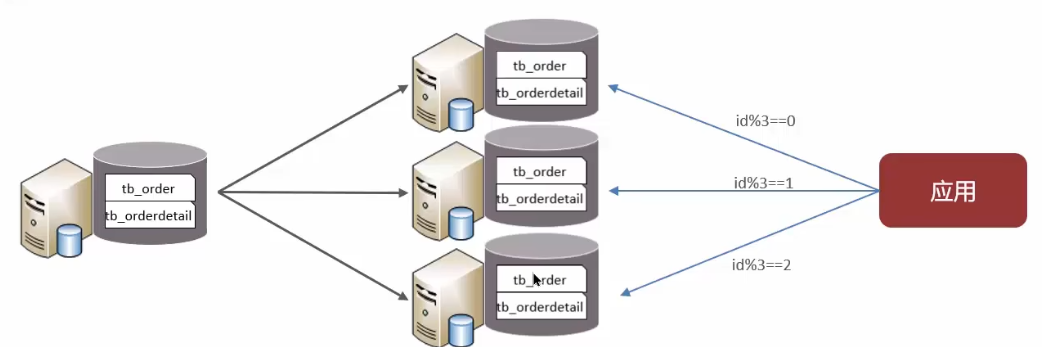
水平分库:将一个库的数据拆分到多个库中。特点:
- 解决了单库大数量,高并发的性能瓶颈问题
- 提高了系统的稳定性和可用性
路由规则
- 根据id节点取模
- 按id也就是范围路由,节点1(1-100万),节点2(100万-200万)
0.2.1.4 水平分表
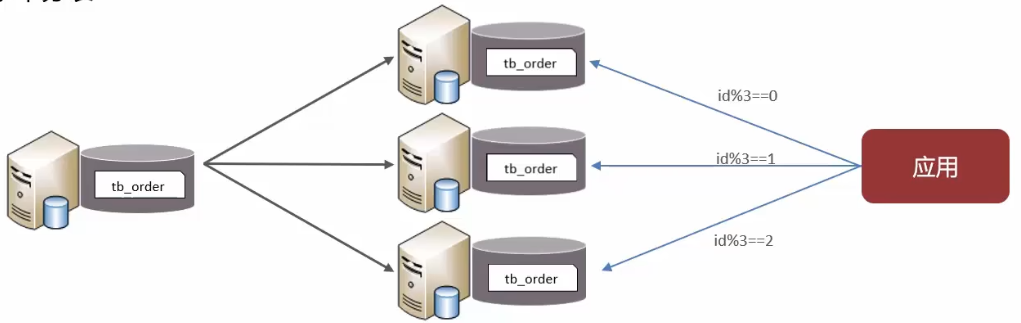
水平分表:将一个表的数据拆分到多个表中(可以在同一个库内)。
特点:
- 优化单一表数据量过大而产生的性能问题;
- 避免IO争抢并减少锁表的几率;
0.2.2 分库之后的问题
- 分布式事务一致性问题
- 跨节点关联查询
- 跨节点分页、排序函数
- 主键避重
解决方案:
分库分表中间件:
- sharding-sphere
- mycat
集群
https://alleyf.github.io/2026/03/2ffe3f22bcdc.html