GPU使用指南
本文最后更新于:5 个月前
1 登录
1 | |
2 创建项目
进入 rancher,点 research 集群,点击 Project/Namespace
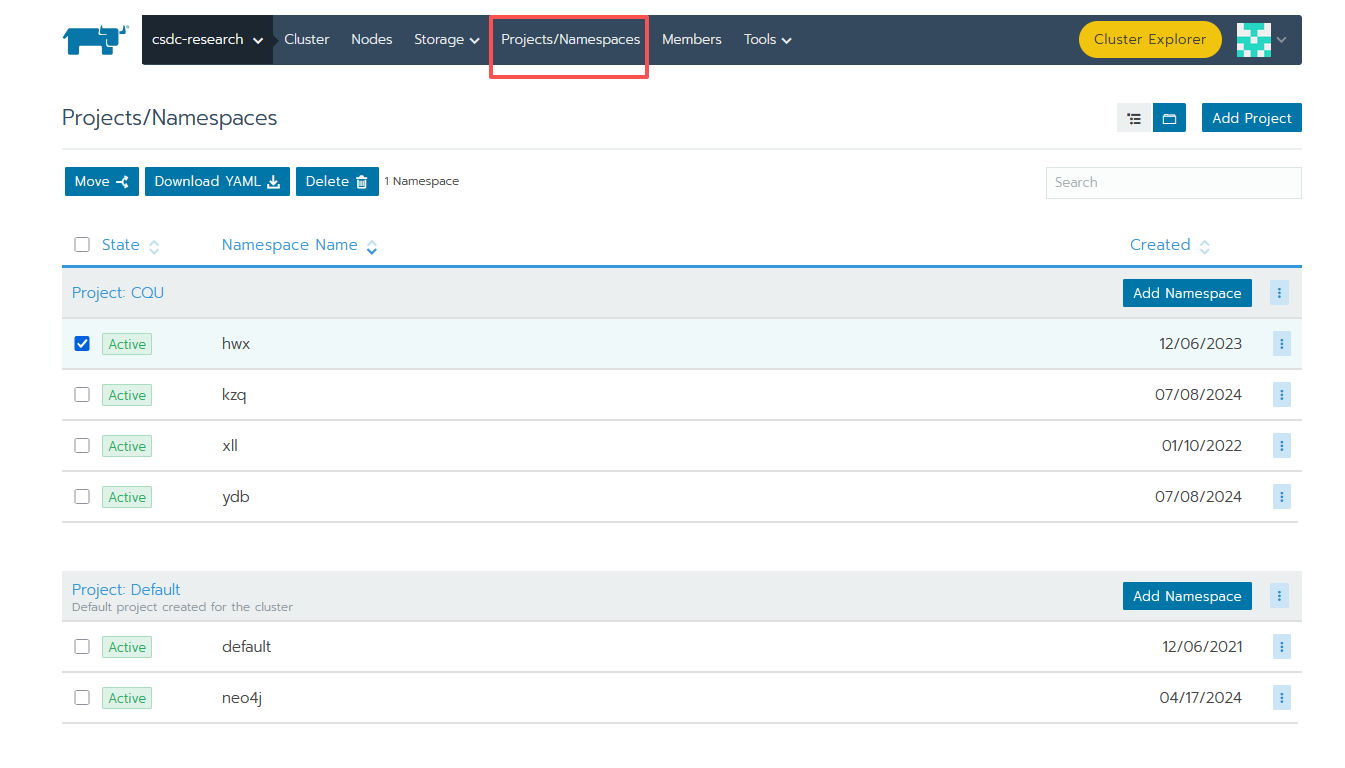
起个名字直接 create
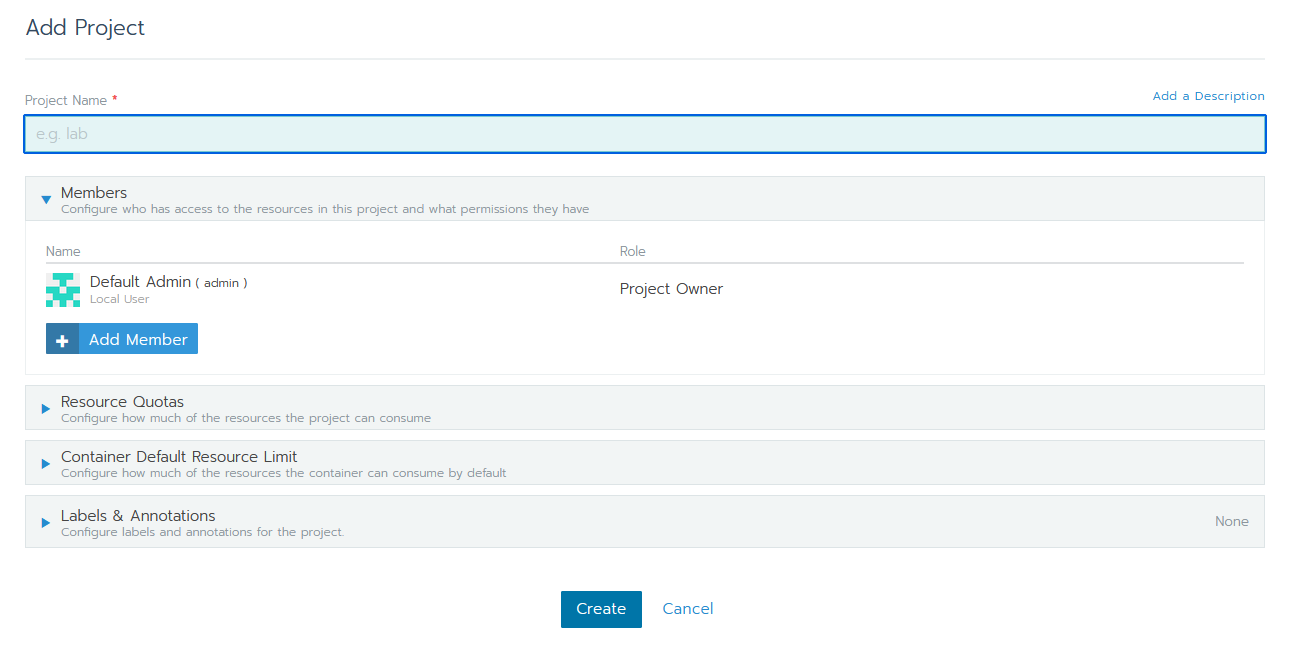
3 创建命名空间
找到创建的 project,点击上方 Add Namespace

添加 Namespace,起个名字(自己的名字缩写)直接点 Create

4 添加 Deployment
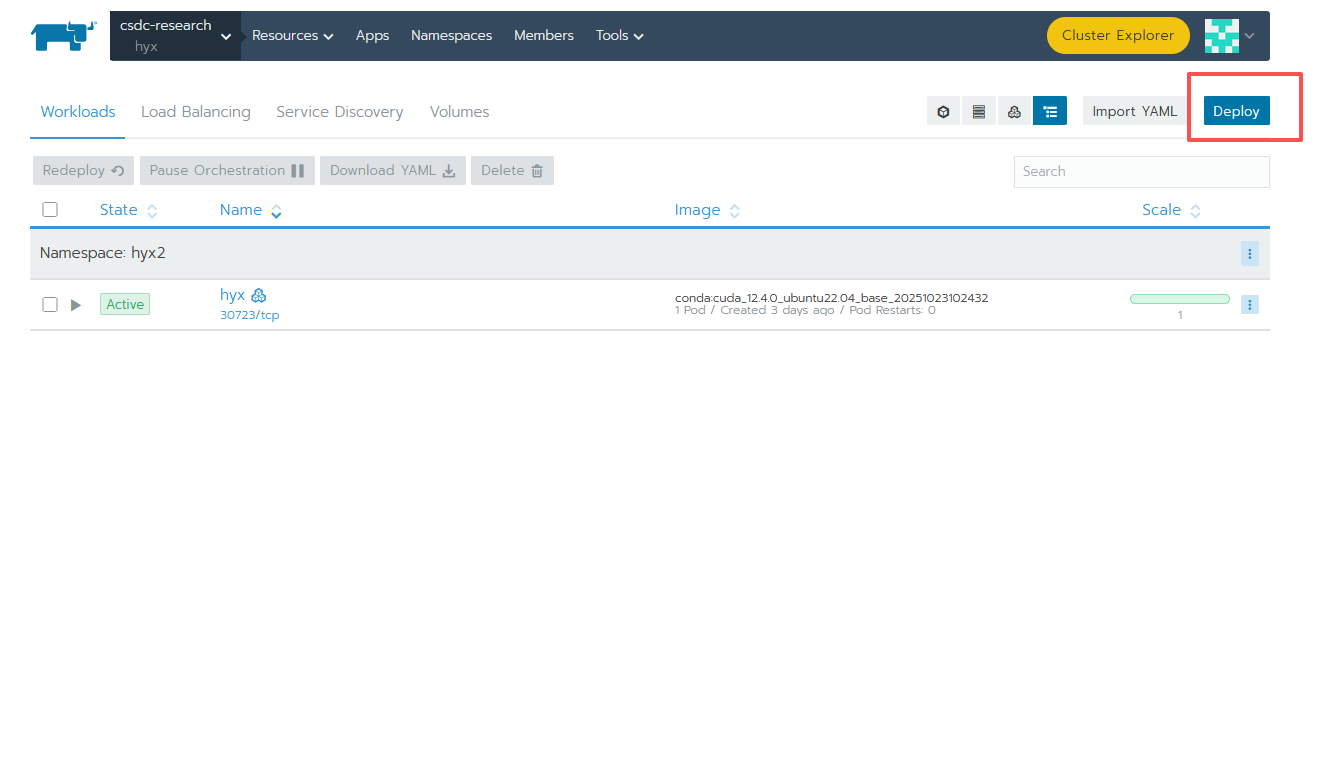
- name 取个名字(自己名字缩写)
- Docker Image 镜像版本选择基础环境的
conda:conda:cuda_12.4.0_ubuntu22.04_base_20251023102432 - Port Mapping 端口映射添加一个
name: ssh;port: 22的端口(后面默认为 nodeport 和 Random)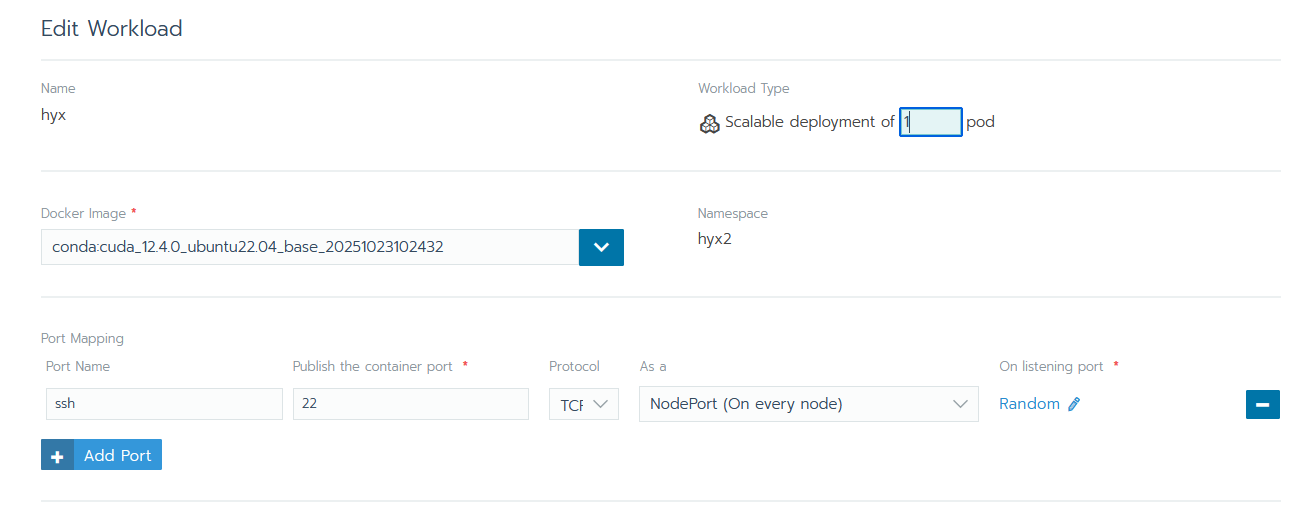
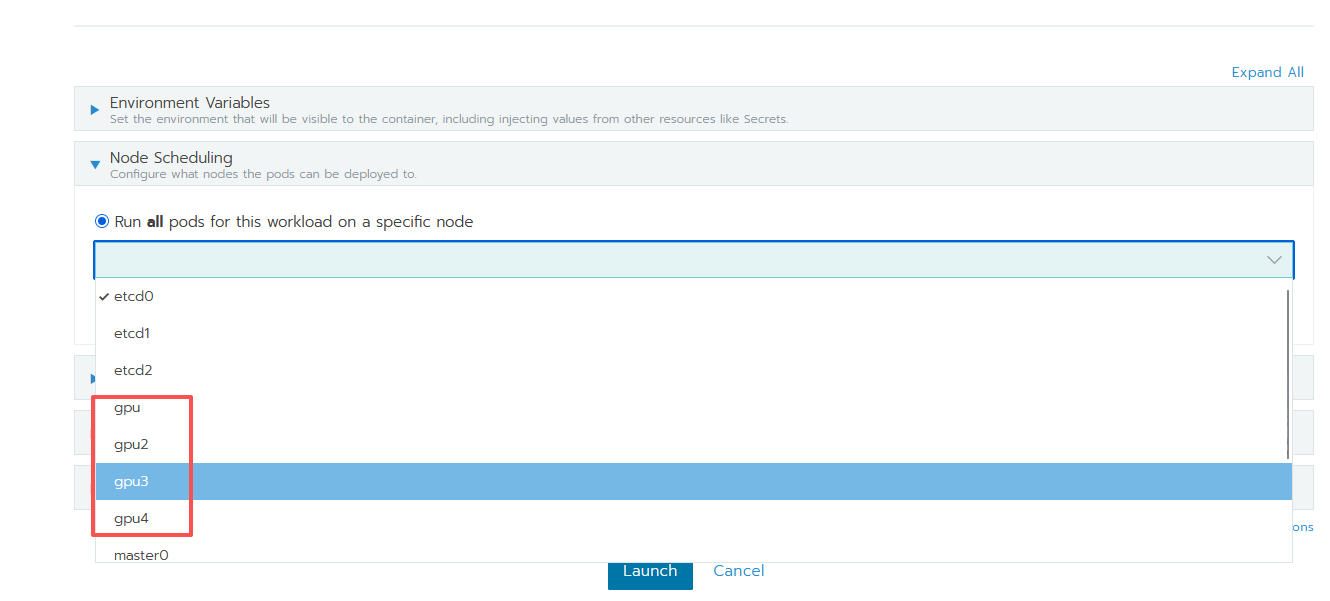
- Node Scheduling 选择指定的名称为 gpu 的节点(目前有 4 个:gpu,gpu2,gpu3 和 gpu4)
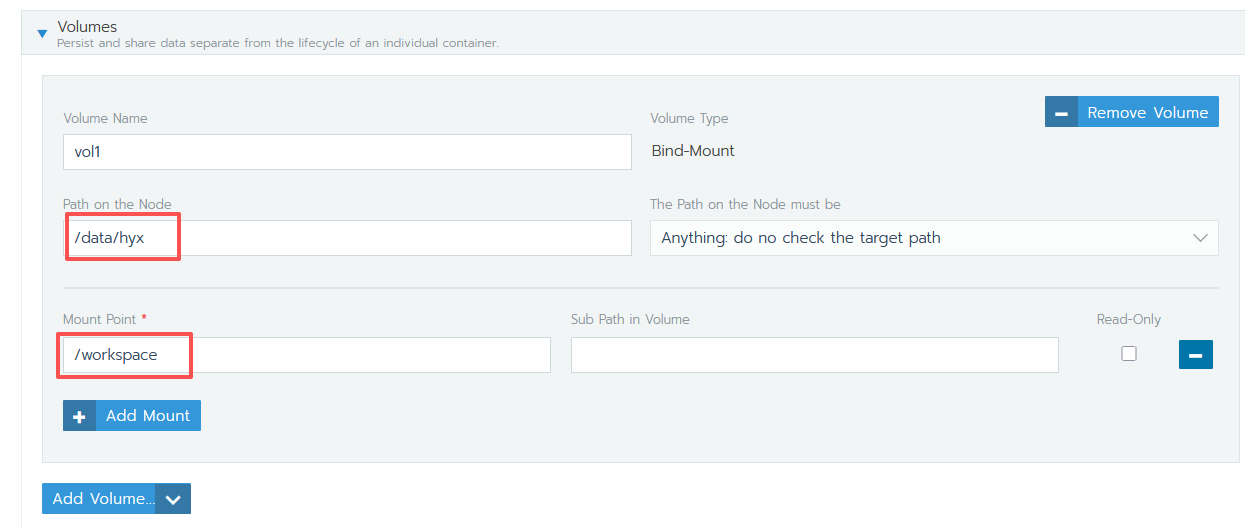
- 添加工作目录挂载点(路径必须是/data/name,name 为名字缩写,Mount Point 必须是/workspace)
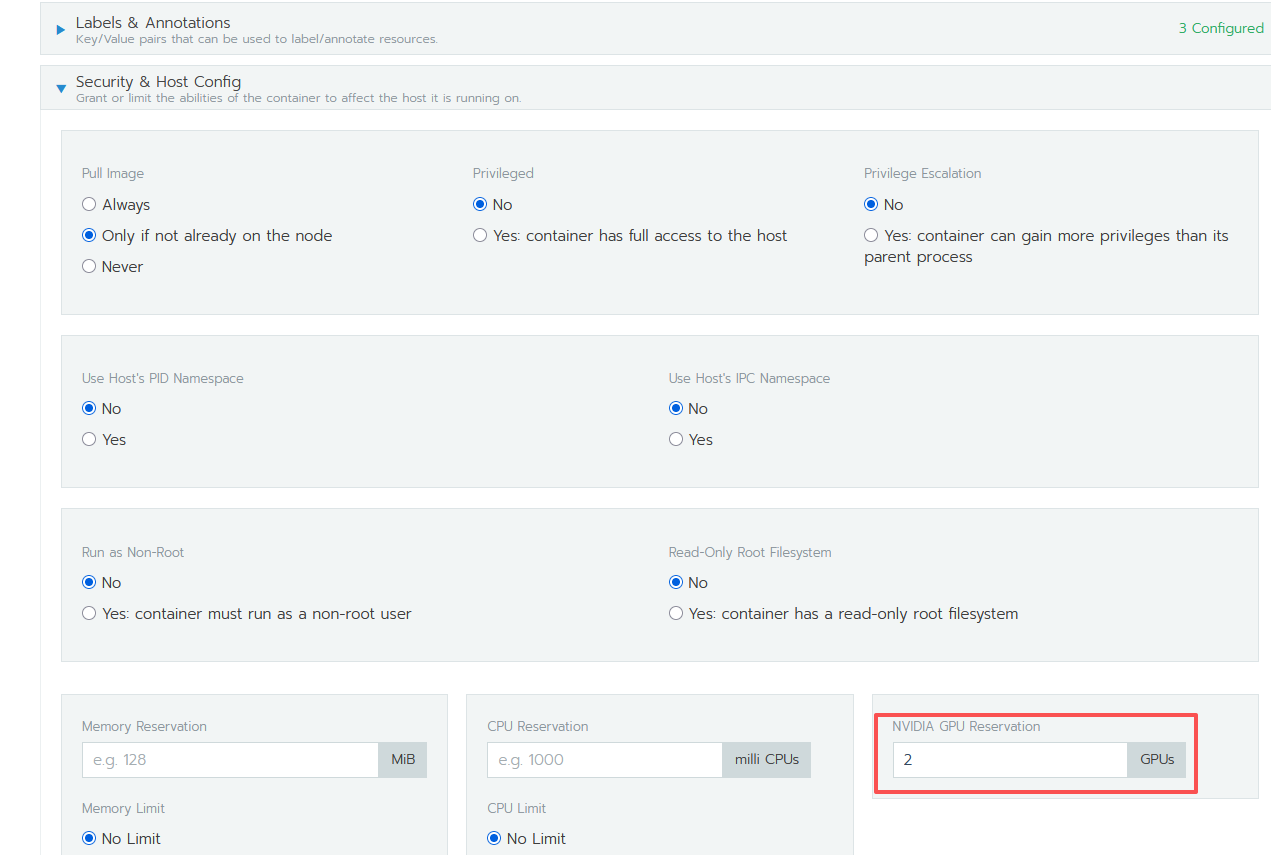
- 设置 gpu 数量(切记不可超过 gpu 物理机显卡数量,一般只需要设置为 1,然后可以成功启动 pod,按照需要再逐渐增大目前都是八卡,所有 pod 都没用的情况下才能设为 8)
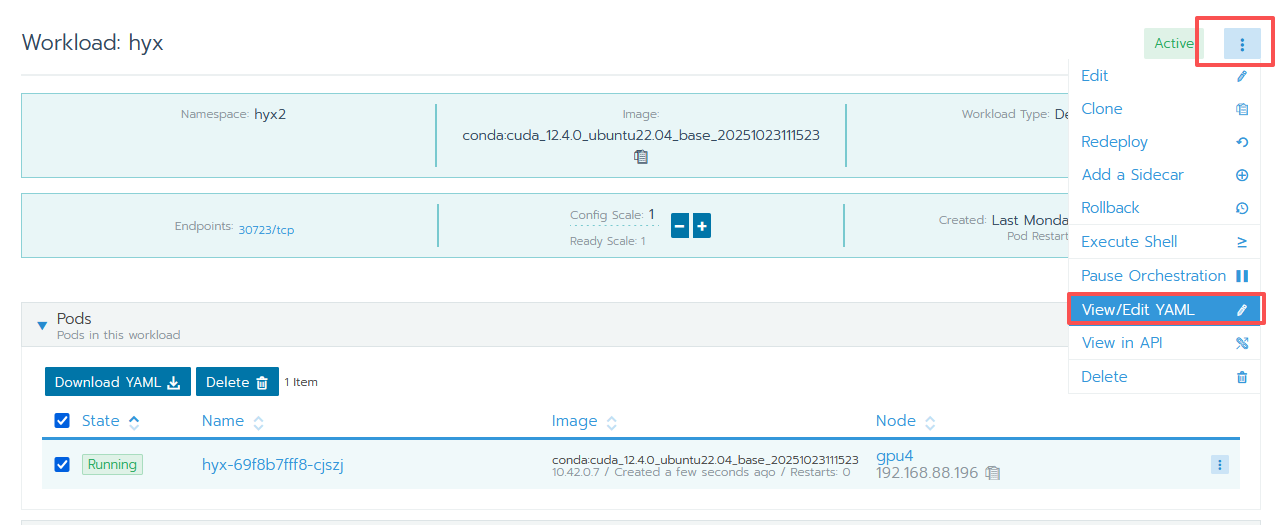
5 配置 pod 对应的虚拟机的 hostname 和 hosts
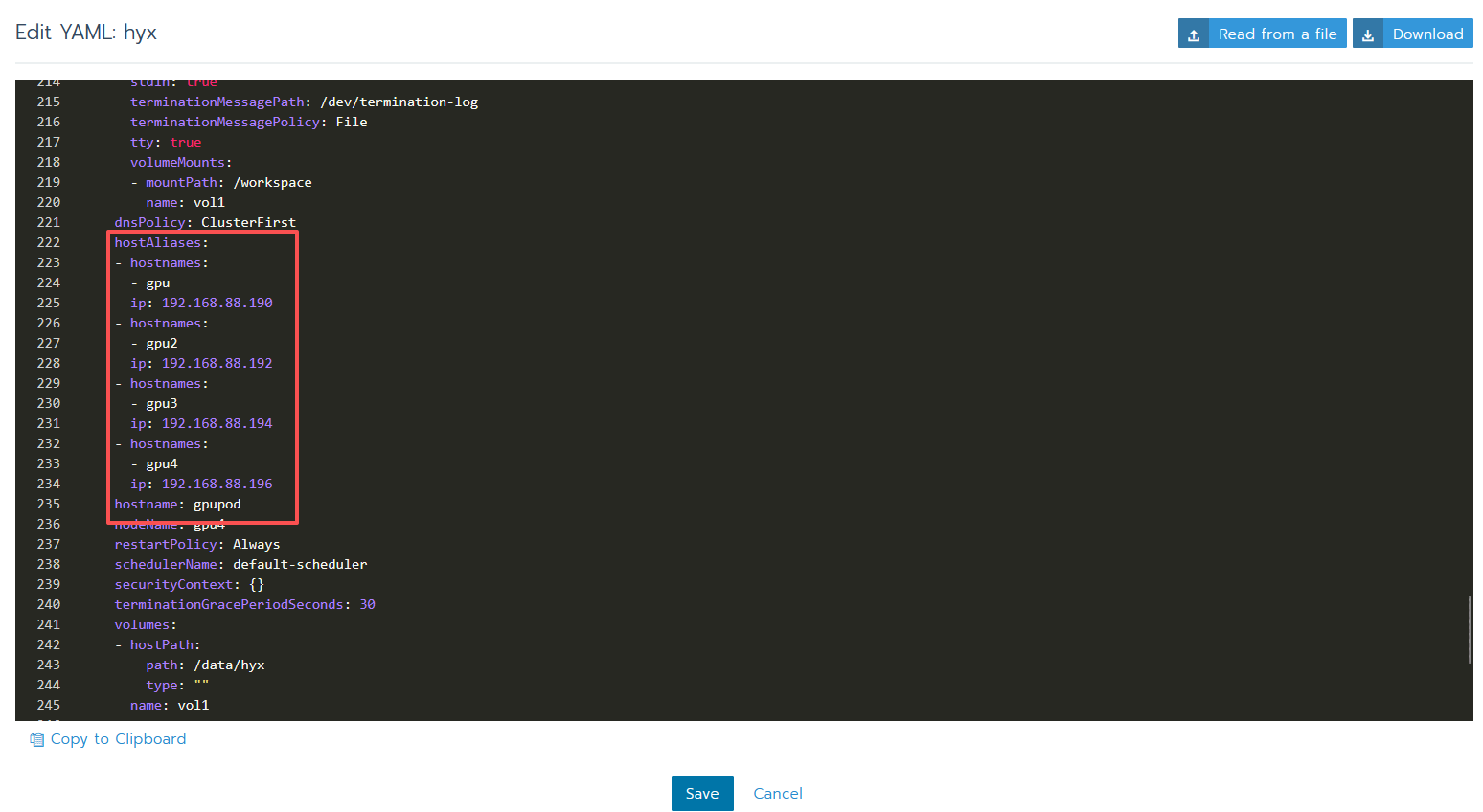
1 | |
6 开启 ssh 登录
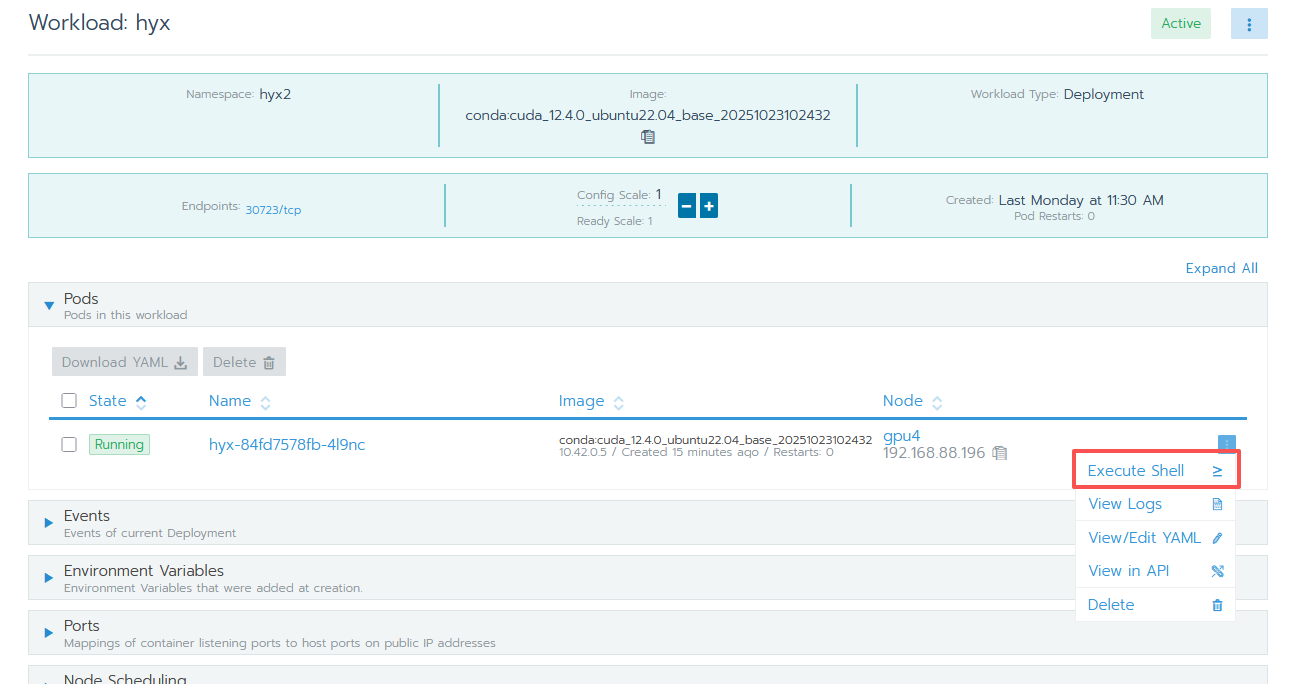
点击 Execute Shell 进入 pod 控制台,执行以下命令启动 ssh 服务:
1 | |
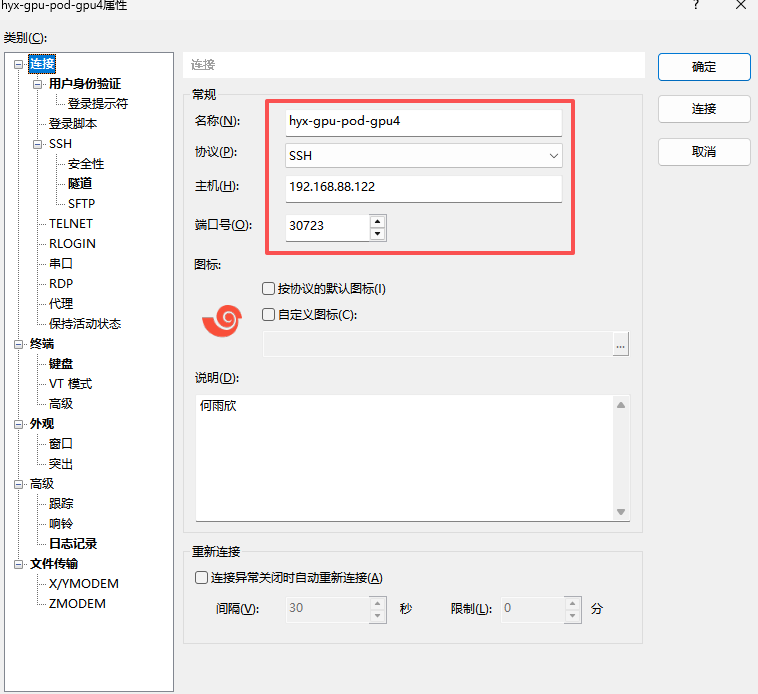
7 通过 xshell 或其他 ssh 工具访问 pod
(主机填 192.168.88.122,端口号填 port 映射的 random 的最终端口,用户名为 root,密码为自己 ssh 那里设置的密码)
8 保存 pod 为镜像
(当有重大变动时最好把当前 pod 保存为一个镜像,不保存的话 pod 一旦关闭就会导致所有的操作丢失包括环境,通过宿主机即物理机下的 home 目录下的 save_docker_image.sh 脚本保存)
通过以下指令保存镜像(docker 不变,gpu4 根据自己在 Node Scheduling 中选的 gpu 节点的名字决定,运行在哪个上就用哪个名字)
1 | |
根据提示输入镜像序号(名称前缀都是 k8s_Workload名称_pod名称 )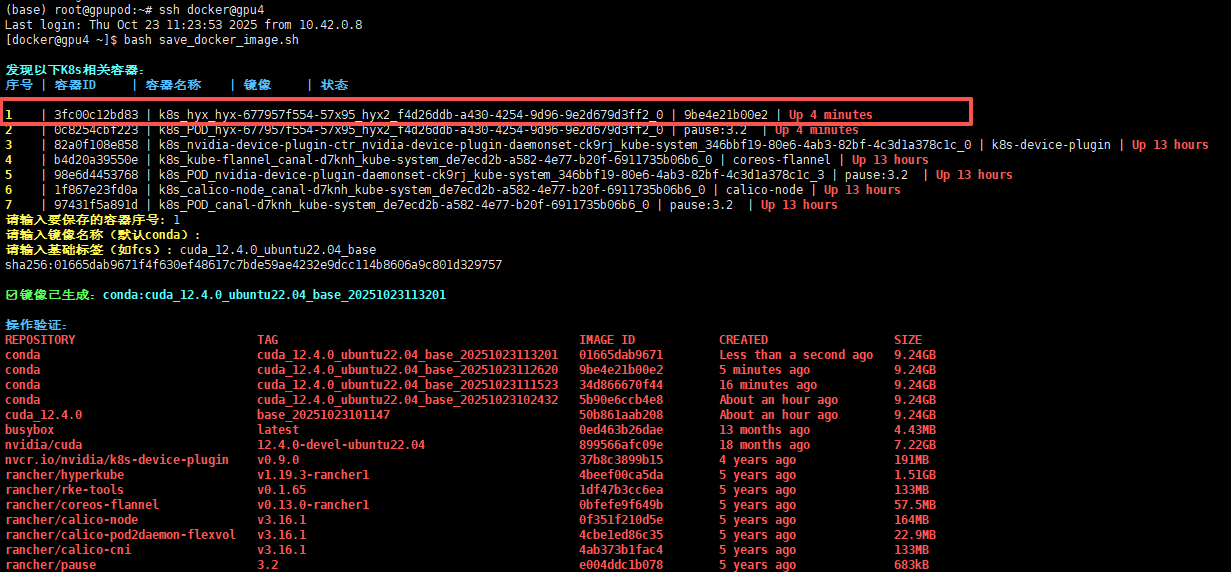
[!NOTE] 温馨提示
保存镜像后,如果更新镜像重新启动pod,ssh 服务不会默认启动,要进 shell 手动打开:service ssh start
GPU使用指南
https://alleyf.github.io/2025/10/81a09e3b6a23.html