《历史链推理:让LLM像侦探一样破解时序知识图谱!高阶信息+分步推理=预测开挂》
本文最后更新于:4 个月前
0.1.1 📋 论文元信息速览表
| 项目 | 内容 |
|---|---|
| 标题 | Chain-of-History Reasoning for Temporal Knowledge Graph Forecasting |
| 作者 | Yuwei Xia, Ding Wang, Qiang Liu, Liang Wang, Shu Wu, Xiaoyu Zhang |
| 机构 | 中科院信息工程研究所、自动化所 |
| 核心问题 | 时序知识图谱(TKG)预测中,LLM无法有效利用高阶历史信息 |
| 解决方案 | 提出Chain-of-History(CoH)分步推理框架 |
| 三大痛点 | 1️⃣ 一阶历史信息不足 2️⃣ 历史信息过载时LLM推理崩盘 3️⃣ 纯LLM的结构推理能力弱 |
| 杀手锏 | 历史链分步探索 + LLM与图模型「插拔式融合」 |
| 效果 | 在ICEWS三大数据集上全面碾压基线,Hit@10最高提升7.36% |
0.1.2 🕵️♂️ 一、背景:TKG预测的「历史困局」
时序知识图谱(TKG) 记录实体关系随时间的变化(如_德国2023年签署协议_)。预测未来事件时,现有方法面临两大派系斗争:
图神经网络(GNN)派:擅长捕捉结构信息,但看不懂语义(像会算账但不懂合同的会计)。
LLM派:语义理解强,但存在三大致命伤(见图1👇):
信息饥饿:只用一阶历史(德国→丹麦),忽略高阶链条(德国→俄罗斯→乌克兰)。
信息过载:历史太长时LLM性能暴跌(见图2👇,历史长度超阈值后MRR断崖下跌)。
结构盲:LLM看不懂图谱拓扑关系(比如分不清“俄罗斯”和“俄罗斯武装”的区别)。
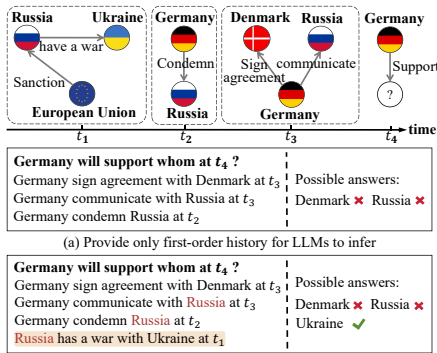
💡 学术裁缝灵感1:历史信息不是越多越好! 图2证明LLM处理长历史时会「CPU过载」,这启示我们设计历史信息压缩算法可能比堆数据更有效。
0.1.3 🧩 二、CoH核心创新:历史链推理「三步走」
CoH的核心理念:像侦探破案一样,分阶段梳理线索链,避免信息过载。具体流程见图3👇:
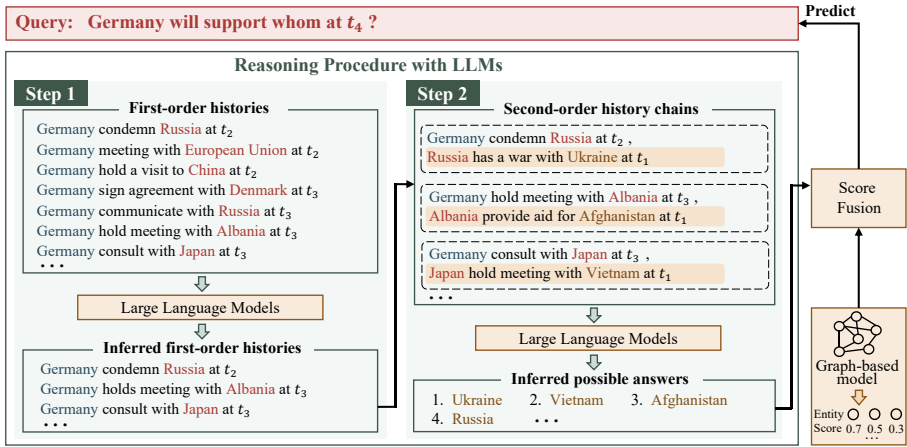
0.1.3.1 Step 1:一阶历史「海选」
操作:喂给LLM 100条一阶历史(如_德国谴责俄罗斯_),让它挑出Top 30重要事件。
玄机:用Prompt控制输出格式(见表1),强制LLM只返回事件ID,避免废话。
1 | |
0.1.3.2 Step 2:高阶历史链「深度挖掘」
操作:用Step 1的输出(如_德国谴责俄罗斯_)关联二阶历史(如_俄罗斯与乌克兰战争_),构建历史链
德国→俄罗斯→乌克兰。关键技巧:时间匿名化!把
2023-06-02转成第153天,防止LLM用先验知识作弊。
0.1.3.3 终极大招:LLM+图模型「插拔式融合」
LLM输出处理:将答案序号转为指数衰减得分(公式1),序号越小得分越高:
S_LLM = 1 / (1 + e^(α·序号))融合公式:动态加权图模型得分与LLM得分:
最终得分 = w·S_图模型 + (1-w)·S_LLM
💡 学术裁缝灵感2:序号即概率! LLM输出的排序序号包含隐含置信度(表3证明打乱顺序会暴跌性能),这种低成本置信度提取法可迁移至其他排序任务。
0.1.4 🚀 三、实验结果:全面碾压基线
0.1.4.1 表2:CoH暴打一切竞争对手
| 模型类型 | 数据集 | MRR(%) | Hit@1(%) | 相对提升 |
|---|---|---|---|---|
| 纯LLM (ICL) | ICEWS14 | 31.79 | 22.38 | - |
| 纯LLM (CoH) | ICEWS14 | 34.51 | 24.20 | ↑8.56% |
| RE-GCN | ICEWS18 | 31.08 | 20.44 | - |
| RE-GCN+CoH | ICEWS18 | 32.10 | 21.75 | ↑6.41% |
✨ 关键结论:
CoH让纯LLM预测性能最高提升11.3%(ICEWS18的MRR)
作为插件可使图模型Hit@1最高提升6.41%(RE-GCN在ICEWS18)
0.1.4.2 表4:案例解读——CoH的「语义破案」能力
| 查询案例 | 图模型答案 | CoH答案 |
|---|---|---|
| 缅甸军方将与谁谈判? (正确答案:泰国) | 1.马来西亚 2.柬埔寨 5.泰国 | 1.泰国 2.泰国公民 3.泰国活动家 |
| 沙特军队攻击了谁? (正确答案:也门武装) | 1.也门 5.也门武装 | 2.也门武装 5.沙特黑帮 |
💡 学术裁缝灵感3:匿名化实验暗藏玄机!表7显示匿名数据使性能暴跌,证明LLM的静态语义知识是重要推理因子——启示我们设计知识注入模块可增强模型普适性。
0.1.5 🧪 四、致命发现:历史信息的「黄金分割点」
图2的隐藏规律:历史长度存在性能拐点!超过阈值后MRR断崖下跌:
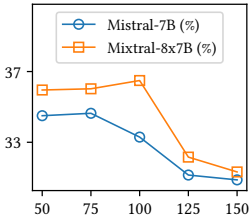
启发性结论:喂给LLM的历史信息需要精炼提纯,而非无脑堆砌!
0.1.6 💎 五、可薅的学术羊毛(创新点+迁移灵感)
分步推理框架
创新点:用CoH将高阶历史分解为多步子任务,破解LLM信息过载难题。
可薅方向:迁移至多跳问答、事理图谱推理等长链条任务,设计「推理中间件」。
动态融合机制
创新点:公式
S = w·S_图 + (1-w)·S_LLM实现结构与语义的互补。可薅方向:用于多模态融合(如图文检索)、模型集成(如BERT+GNN)。
低成本置信度提取
创新点:利用LLM输出序号生成指数衰减得分,无需额外训练。
可薅方向:适配检索排序、主动学习中的不确定性估计。
时间匿名化防作弊
创新点:将具体日期转为抽象时间,阻断LLM先验知识干扰。
可薅方向:泛化至地理位置匿名、机构名称脱敏等场景。
0.1.7 🚨 六、警钟长鸣(局限性)
推理速度:多步调用LLM导致时延高(作者建议用Mixtral-8x7B量化版缓解)
融合僵化:权重w需手动调整,未来可探索自适应融合网络(比如加个LSTM学权重?)
总结:CoH像给LLM装上了「历史显微镜」+「图模型外挂」,既解决了高阶信息利用难题,又弥补了纯LLM的结构缺陷。其分步推理、动态融合、置信度提取三把斧,堪称时序预测任务的「瑞士军刀」!研一新生可重点薅其框架设计灵感,举一反三攻破其他长链条推理任务💪