基于 LLM 的时序知识图谱推理与可解释性增强研究
本文最后更新于:5 个月前
基于 LLM 的时序知识图谱推理与可解释性增强研究
细化选题探讨
汇报人:范财胜
所属单位:华中科技大学
汇报时间:2025-09-24
联系方式:csfan@hust.edu.cn
📕 目录
📜 导论
| Meta | Value |
|---|---|
| 标题 | 基于 LLM 的时序知识图谱推理与可解释性增强研究 |
| 研究阶段 | 选题探讨阶段(未开展具体实验) |
| 核心场景 | 通用公开数据集场景+社科科研管理数据 |
| 关键问题 | 少样本稀疏性、模型可解释性、语义-结构融合 |
| 技术方向 | 时序知识图谱(TKG)、少样本学习、大语言模型(LLM) |
| 预期价值 | 提升 TKGF 的性能表现,适用于通用场景 |
🔍 引言
📑 背景挑战
知识图谱(KG)通过”实体-关系-实体”的结构化三元组表达现实世界事实,时序知识图谱(TKG) 进一步引入时间维度(记为 (h, r, t, τ),其中 h =头实体、r =关系、t =尾实体、τ =时间戳),能够表示动态演化的世界知识,例如:可精准刻画科研项目研究周期、专家合作时序、成果产出节点等动态事实。
当前 TKG 推理面临如下三大核心挑战:
- 少样本零样本稀疏性:多数场景存在显著的”==长尾分布==”,以社科场景为例:多数新项目、青年专家的关联事实仅出现数次甚至没有,传统 TKG 模型依赖大量样本训练,难以泛化到稀疏实体/关系。
- 可解释性缺失:现有模型多为”黑盒”,推理结果缺乏透明逻辑,而科研项目结项预测、项目专家合作者推荐等场景需明确的决策依据(如”为何该项目可以正常顺利结项,为什么该项目推荐该专家合作”)。
- 复杂推理能力不足:当前的 TKGR 多数依赖于基于逻辑规则或基于 GNN 的结构化推理,没有充分融合 LLM 利用其丰富的语义信息来解决复杂 TKG 推理问题。
大语言模型(LLM)具备强大的语义理解与指令遵循能力,可以为 TKG 中少样本零样本实体或关系生成丰富的描述信息,融合图神经网络的结构信息,为弥补 TKG 结构稀疏性、生成自然语言解释、提高复杂 TKG 推理能力提供了新路径。
🎯 研究目标
1. 时序知识图谱的少样本推理
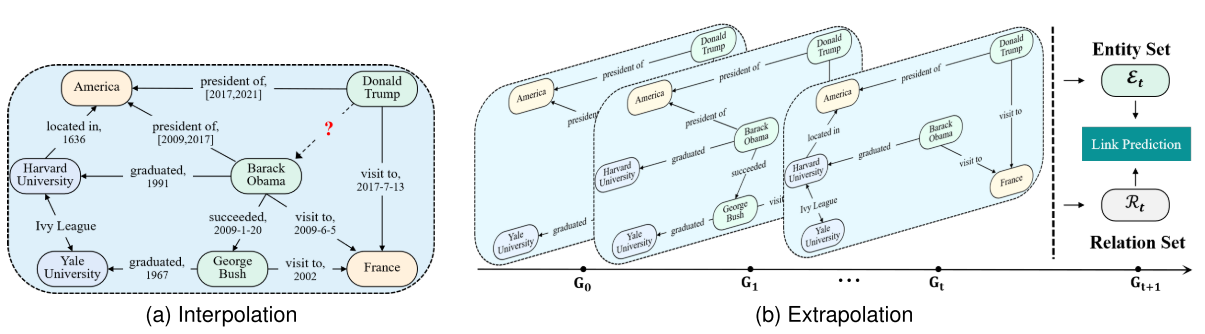
- TKG推理定义:给定不完整三元组
(h, r, ?, τ)或(?, r, t, τ),预测当前时间范围内的缺失事实(内插)或预测未来事实(外推)。 - 少样本场景界定:针对某一关系
r,若训练集中包含该关系的三元组数量≤K(通常 K=1/5/10),则属于 K-shot 推理任务——社科数据中”新项目-成果””青年专家-合作”等关系多为 1-5 shot。 - 核心挑战:如何从极少量样本中快速学习关系模式,并结合时间顺序约束(如”项目立项后 2 年产出成果并顺利结项”)进行泛化。
2. LLM 与知识图谱的融合逻辑
LLM 的优势与局限形成对 TKG 的”精准互补”:
| 维度 | 大语言模型(LLM) | 时序知识图谱(TKG) | 融合价值 |
|---|---|---|---|
| 数据形式 | 非结构化文本(语义丰富) | 结构化三元组(逻辑清晰) | 语义补全结构,结构约束语义 |
| 时序建模 | 弱(依赖上下文窗口,长时序丢失) | 强(显式时间戳,支持时序推理) | TKG 时序约束提升 LLM 的时间感知力 |
| 少样本泛化 | 强(语义迁移能力) | 弱(依赖样本数量) | LLM 语义迁移解决 TKG 稀疏问题 |
| 可解释性 | 可生成自然语言解释 | 可提供结构化推理路径 | 路径+语言形成可理解的解释 |
✨ 预期贡献
理论贡献
- 明确 LLM 在”结构稀疏 TKG”中的语义补全价值,提出”时序结构嵌入+文本语义嵌入”的双模态融合理论。
- 建立”==少样本推理-可解释性增强==”的协同机制,证明解释性提升与推理精度可正向循环。
方法贡献
- 设计轻量级、插拔式的少样本 TKG 推理框架,兼容公开数据集与社科私有数据,解决长尾分布问题。
- 提出
混合式可解释性方案,结合注意力定位(神经方法)与自然语言生成(符号方法),平衡解释精度与可读性。
应用贡献
- 针对社科科研管理场景,定制 “项目状态预测””专家合作推荐” 两大任务的落地方案,提升数据驱动决策的效率与可信度。
🏗️ 研究框架设计
🛠️ 技术层—稠密场景下结构语义混合增强的复杂 TKGF 增强研究
研究关键点 1-复杂多跳推理
- 核心目标:通过历史链分步探索与 LLM-图模型的动态融合,充分利用高阶历史信息,解决复杂 TKGR 任务中因高阶历史信息利用不足导致的推理性能受限问题,提升复杂场景下未来事件的预测准确性。
- 技术范式:通过历史链分步探索,并采用 LLM 生成时序逻辑规则,再结合图模型推理的融合框架(如 GenTKG 的时间逻辑规则检索策略 TLR),通过 LLM 从历史数据中挖掘时序规则(如“Consult (T0) → Make_phonecall (T1)”),并基于规则检索相关事实,借助图模型的结构推理能力验证规则有效性,实现高阶历史信息的深度利用。
- 参考文献:COH:历史链分步探索 + LLM 与图模型「插拔式融合」,解决高阶历史信息利用不足的复杂 TKGR 问题。
研究关键点 2-可解释性(密集场景推理路径多才有意义,稀疏场景历史候选路径太少别无选择)
- 核心目标:生成“结构化路径(时序规则序列)+自然语言解释(规则语义)”的双视角结果,解决复杂推理中规则提取模糊、可解释性差的痛点,为预测结果提供可追溯的逻辑依据。
- 技术范式:利用 LLM 分析历史数据生成时序逻辑规则(结构化路径),并通过图模型推理验证规则的应用过程;同时将规则的语义(如规则触发的因果关系)和推理步骤(如规则匹配的具体事实)转化为自然语言描述,形成“规则-推理-解释”的全链路可解释输出。
- 参考文献:LLM-DA:LLM 生成动态更新的时序规则+图模型双推理融合,无需微调解决规则提取难+可解释性差问题。
graph LR
A[时序知识图谱] --> B[历史链采样]
B --> C[LLM生成规则]
C --> D[规则检索事实]
D --> E[图模型推理]
E --> F[预测未来事件]
F --> G{反馈}
G -->|更新| C
🛠️ 技术层—稀疏场景下基于 LLM 语义增强的少/零样本 TKGF 增强研究
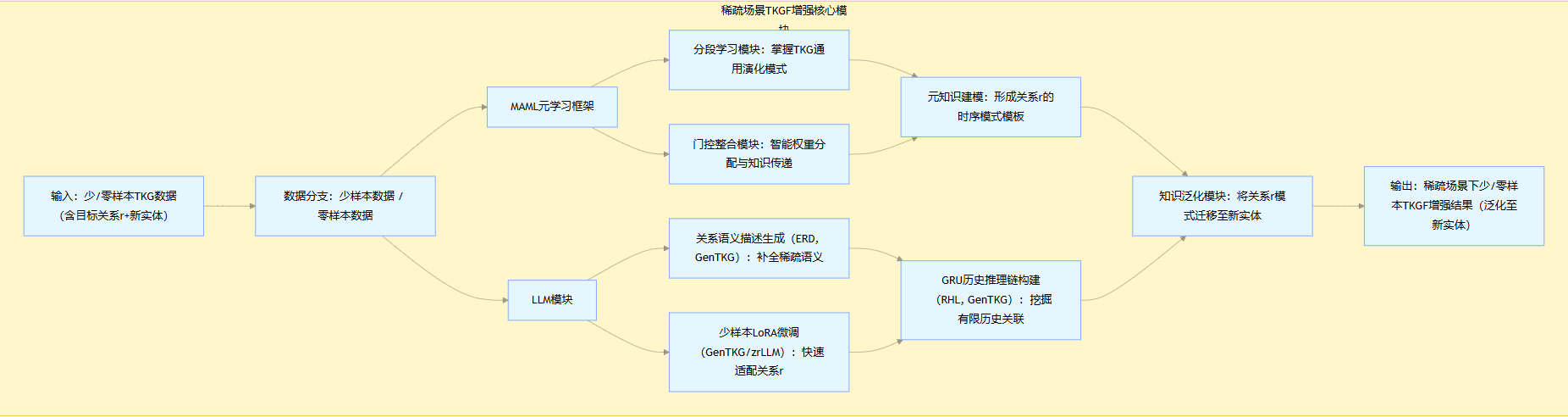
研究关键点 3-少样本零样本
- 核心目标:从 K 个样本中快速学习关系
r的时序模式,泛化到新实体。 - 技术范式:采用MAML(模型无关元学习) 框架,结合 LLM 生成语义描述或 few shot lora 微调。
- ==参考文献==
- MAML 元学习:元学习分段学习掌握 TKG 演化模式+门控整合模块智能权重分配传递知识,解决少样本 TKGF。
- GenTKG/zrLLM:LLM 生成关系描述(ERD)+GRU 构建历史推理链(RHL),解决零样本 TKGF;时序规则检索+少样本微调(lora),解决少样本 TKGF。
💡 应用层—面向社科场景的任务落地
基于上述模型,针对社科科研管理设计两大核心任务:
- 学科热点演化与预测:
- 任务描述:任务旨在基于历史TKG预测学科热点的时序演化。输入包括时序文献语料(如ISWC 2017-2019摘要),通过实体提取和本体链接生成TKG(如三元组“ontology - related_to - RDF”带时间戳)。过程分为:(1)生成时序子图;(2)分析演化(如使用度中心性追踪概念邻居变化);(3)预测未来热点(如基于多LSTM的趋势模型,输出Top-K主题列表+解释路径)。扩展到LLM时,可融入语义规则增强推理,处理如“ontologies”从2017年主导到2019年衰退的模式。 输出:热点演化序列+自然语言解释(如“因关联概念增加,导致热度上升”)。。
- 时间敏感性:需捕捉关键词频率的突变点(如政策文件发布后的关键词激增)。
- 评估指标:
- MRR:平均倒数排名,评估预测热点的排名质量。
- Hits@K (K=1,3,10):前K位命中率,衡量正确热点比例。
- 中心性指标:如度中心性(normalized degree)、特征向量中心性(eigenvector centrality)和介数中心性(betweenness centrality),用于演化分析。
- 研究意义:科学文献的爆炸式增长使得追踪领域热点变得日益复杂。以计算机科学为例,国际语义网会议(ISWC)等会议的论文集记录了知识的演化,但手动分析效率低下。TKG作为扩展的知识表示形式,将事实以四元组(主体、关系、客体、时间戳)形式存储,捕捉动态变化。 早期工作如KGen工具用于从生物医学文本生成KG,现扩展到计算机科学领域,通过本体如CSO链接实体,实现时序分析。相关研究包括基于LSTM的热点预测模型,以及使用图卷积网络(GCN)的多LSTM框架,用于计算主题热度和趋势。 TKG的引入解决了静态KG的局限性,能处理如“SPARQL查询”从兴起到衰退的演化过程。文献显示,这一任务源于复杂网络理论,结合时序数据处理不确定性,如政策变化对热点的外部影响。这一任务在社科科研管理中具有战略价值,能帮助资助机构(如国家社科基金)识别新兴趋势,支持资源优化分配。例如,预测情报科学领域的热点(如“智能教育”)可指导项目立项,避免重复研究。 对于LLM增强的TKG模型,其可解释性(如中心性路径可视化)能提升决策透明度,揭示热点演化的因果链条。同时,在全球科研竞争中,这一任务促进跨领域融合,但需注意争议,如数据偏差可能放大某些领域的热点,忽略边缘学科。
- 科研合作网络演化预测:
- 任务描述:预测未来1-2年可能形成的跨机构合作(如“2026年A大学与B研究所将联合申请国家社科重大项目”)。任务从时序交互流构建TKG(如用户-项目图),预测未来链接。过程:(1)计算协作指标(如Jaccard相似性);(2)使用时序图网络更新表示(如事件级RNN);(3)联合训练演化损失和推荐损失。输入:时序快照图;输出:Top-K链接预测+理由。 LLM增强可添加对比学习,处理噪声。
- 时间敏感性:需捕捉合作关系的时序模式(如“2020-2023年A与B每两年联合发表3篇以上论文”)。
- 数据支撑:项目合作申请记录、论文合著时间、机构共现网络的历史快照(如每年构建一张网络)。
- 评估指标:使用多步预测设置,指标包括MRR和Recall以及Top-K合作预测命中率(K=10/50)。 网络特定:链接预测AUC、F1-score;可解释性:Faithfulness。。
- 研究意义:科研合作网络源于社会网络理论,节点为研究者、边为合著关系。早期研究聚焦静态属性,如度分布和聚类系数,现扩展到时序演化,使用TKG捕捉如合著事件的动态。 数据源如Lattes Platform提供巴西研究者信息,覆盖信息科学和生物学领域。TCGC框架引入时序协作感知,处理事件级(短期交互)和历史级(长期聚合)动态。 背景包括链接预测问题,结合拓扑(如共同邻居)和领域属性(如机构编码),解决网络稀疏性和不平衡。预测合作演化能优化团队组建、提升科研效率,尤其在生物学的高密度网络中(平均度更高)。 对于LLM模型,可解释性增强揭示合作偏好(如时间衰减权重),支持公平推荐,避免偏差。意义还包括监测影响者、促进多样化合作,但争议在于属性重要性(如优先附着 vs. 共同邻居),不同算法可能产生分歧。
graph TB
subgraph 输入层
P1[项目 X<br>当前状态 + 时间戳]
P2[项目 X<br>需合作专家 + 时间戳]
end
subgraph 核心引擎
E1[稠密模型<br>复杂多跳 & 可解释]
E2[稀疏模型<br>少/零样本泛化]
end
subgraph 任务层
T1[项目状态预测<br>在研/结题/延期]
T2[专家合作推荐<br>Top-K 学者列表]
end
subgraph 输出层
O1[结构化预测 + 规则路径]
O2[NL 解释<br>“因负责人 A 曾产出 4 篇同类论文…”]
O3[专家画像 + 历史合作图谱]
O4[NL 解释<br>“B 在 2024 发表相关主题且与 A 有 3 次合作”]
end
P1 --> E1 --> T1 --> O1
T1 --> O2
P2 --> E2 --> T2 --> O3
T2 --> O4
style E1 fill:#f9f,stroke:#333,stroke-width:2px
style E2 fill:#bbf,stroke:#333,stroke-width:2px
📋 预期实验与评估设计
1. 🗃️ 数据集设置
| 数据集类型 | 具体数据集 | 用途 | 关键处理 |
|---|---|---|---|
| 公开数据集 | ICEWS系列(14、05-18、21)、GDELT、YAGO(全球新闻事件和维基百科等数据) | 通用性验证(复杂多跳推理和少样本推理性能) | 按关系采样构建 1/5/10-shot 任务,筛选跨 5 年以上的实体关系对 |
| 自制数据集 | 社科科研管理数据 | 应用场景验证 | 脱敏处理,标注”项目-状态””项目-合作”关系 |
2. 🔬 实验任务设计
[!NOTE] 基础任务:少样本链接预测
- 任务定义:
- 给定(h, r, ?, τ),预测尾实体t;给定(? ,r, t, τ),预测头实体h。
- 场景划分:
- ①常见关系的少样本场景(如”主持”关系,5-shot);
- ②长尾关系场景(如”指导青年项目”,1-shot);
- ③新实体场景(无历史数据的新项目)。
[!NOTE] 应用任务:社科场景下游任务
- 项目状态预测:
- 输入:项目实体、”状态”关系、目标时间戳(结题时间)。
- 输出:研究状态(二分类)+ 自然语言解释。
- 专家合作推荐:
- 输入:项目实体、”需要合作专家”关系、立项时间。
- 输出:Top-5 专家列表 + 每人的推荐理由。
3. 📊 评估指标
(1)推理性能指标
- Hits@k(正确答案排进前 k 名占比) :预测结果中前 k 名包含正确实体的比例(k=1,3,5,10,越高越好)。
- MRR(平均倒数排名):正确实体排名的倒数均值(越高越好)。
- MR(平均排名):正确实体的平均排名(越低越好)。
(2)可解释性指标
- 自动评估:计算解释文本与结构化路径的”语义相似度”(用 BERTScore,越高说明对齐性越好)。
4. 🆚 对比方案设计
(1)基线模型分组
- 传统少样本 TKG 模型:MetaTKGR (2022)。
- LLM+TKG 融合模型:zrLLM (2023)、GenTKG (2023)、COH (2024)。
- Ablation 实验对照组:
- 无 LLM 模块:仅用元学习+TKG 结构嵌入。
- 无元学习模块:LLM+TKG 但用传统训练(非少样本)。
- 单一解释模块:仅注意力可视化/仅 LLM 生成解释。
(2)核心对比维度
- 性能对比:在公开数据集上,验证本模型在1/5/10-shot场景下的 Hits@10 /MRR 是否优于基线。
- 泛化对比:在新实体场景下,验证本模型的性能下降幅度是否低于基线。
⚠️ 挑战与展望
潜在挑战
- LLM 的时序建模局限:对于跨 10 年以上的长时序关系(如”专家职业生涯的合作模式演变”),LLM 的上下文窗口可能无法覆盖,需结合时序分解技术。
- 少样本解释的准确性:当样本仅 1-2 个时,推理路径单一,LLM 生成的解释可能过于简单,需引入”领域知识图谱”补充背景逻辑。
- 数据的噪声干扰:申报书文本可能存在”夸大描述”,导致 LLM 语义嵌入偏差,需设计文本清洗与可信度评分模块。
未来展望
- 技术深化:探索”多模态 LLM”(如结合项目演示 PPT、成果 PDF)的 TKG 增强推理,进一步丰富语义信息。
- 场景拓展:将框架应用于”政策效果预测”(如”某科研政策实施后,成果产出的变化趋势”),提升研究的社会价值。
- 效率优化:针对 TKG 动态更新特点,设计增量学习机制,避免模型全量重训。
📕参考文献
[1] Wei, W., et al. “Large Language Models-guided Dynamic Adaptation for Temporal Knowledge Graph Reasoning.” NeurIPS, 2024. arXiv:2405.14170.
[2] Wang, Y., et al. “Chain-of-History Reasoning for Temporal Knowledge Graph Forecasting.” ACL Findings, 2024. arXiv:2402.14382.
[3] Li, Y., et al. “Temporal knowledge graph completion: A survey.” IJCAI, 2023. DOI:10.24963/ijcai.2023/734.
[4] Liu, Z., et al. “A survey on temporal knowledge graph: Representation learning and applications.” arXiv preprint, 2024. arXiv:2403.04782.
[5] Wang, Q., et al. “A survey on knowledge graphs: Representation, acquisition, and applications.” IEEE TNNLS, 2022. DOI:10.1109/TNNLS.2021.3070843.
[6] Chen, D., et al. “MetaTKG: Learning evolutionary meta-knowledge for temporal knowledge graph reasoning.” EMNLP, 2022. arXiv:2209.02998.
[7] Zhang, T., et al. “GenTKG: Generative forecasting on temporal knowledge graph with large language models.” arXiv preprint, 2023. arXiv:2310.07793.
[8] Zhao, K., et al. “zrLLM: Zero-shot relational learning on temporal knowledge graphs with large language models.” NAACL, 2024. arXiv:2312.15884.
🙏 致谢
感谢各位老师和师兄师姐们的聆听,如有不当敬请批评指正!