研究思路
本文最后更新于:8 个月前

1 大方向
1.1 时序知识图谱
1.1.1 核心定义
TKG 是含时间戳的有向多关系图,形式化为**G=(E, R, T, F)**:
- E:实体集(如 Barack Obama、Iran)
- R:关系集(如 make statement、provide military aid)
- T:时间戳集(如 2014-6-19)
- F:事实集(四元组 (h, r, t, τ),代表 “h 在 τ 时刻通过 r 关联 t”)
1.1.2 核心问题
静态 KG 缺陷:无法建模动态演化(如奥巴马对伊朗政策随时间变化)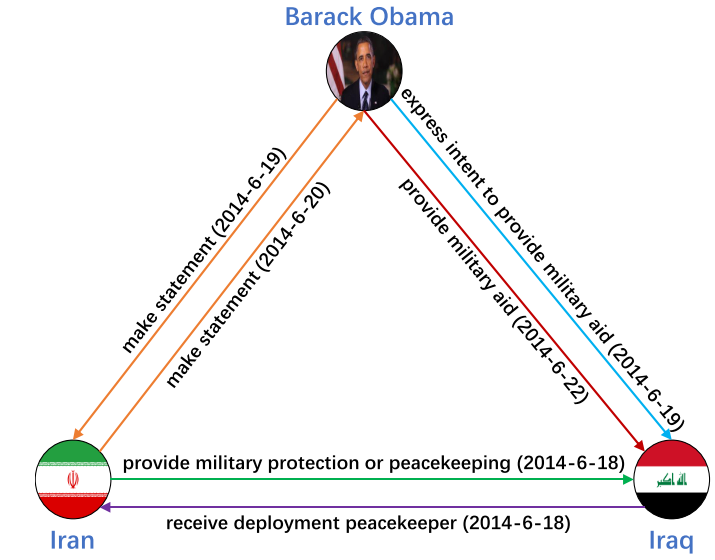
1.1.3 现存问题
数据构建与表示- 非结构化数据转化困难:从文本提取结构化TKG依赖专家知识,缺乏自动化流程和统一标准
- 时间粒度差异:处理年/月/日等多粒度时间表示和对齐难题
- 长尾分布问题:实体覆盖率低,罕见事件预测能力弱
模型预测与推理- 新事件/实体预测能力不足:现有模型过度依赖历史数据,对”开放世界”问题预测能力有限
- 未见时间预测挑战:对未来时间或缺失时间的预测能力弱
- 数据稀疏与冷启动:特定领域数据稀疏,新实体/关系缺乏历史交互数据
可解释性与效率- 黑盒模型问题:高风险领域需要透明可追溯的推理过程
- 计算复杂度高:时间信息融合显著增加计算负担
- 大规模数据处理困难:当前TKG数据集规模远小于真实世界
时间建模方法- 时间表示选择:离散vs连续时间建模的平衡
- 时间依赖捕获:有效捕捉长期和短期时间依赖关系
- 信息融合效率:在不显著增加复杂度情况下有效融合时间信息
1.1.4 现有方法
1.1.4.1 表示方法
| 分类 | 核心思想 | 优势 | 局限 | 代表模型 |
|---|---|---|---|---|
| 基于变换 | 时间作为变换操作(平移/旋转) | 适配静态 KG 方法,易实现 | 部分模型难以建模对称关系 | TTransE, HyTE, ChronoR, RotateQVS |
| 基于分解 | 张量分解提取低维表示 | 数学基础扎实,可解释性较强 | 高维张量计算复杂 | TComplEx, TuckERT, T-SimplE |
| 基于 GNN | 利用结构+时间聚合邻居信息 | 捕捉全局结构依赖 | 对长时序建模能力有限 | TEA-GNN, TREA, DEGAT |
| 基于胶囊网络 | 胶囊结构建模复杂关系模式 | 抗空间变换干扰 | 训练成本高 | TempCaps, BiQCap, DuCape |
| 基于自回归 | 建模图演化过程预测未来 | 擅长预测未来事实 | 依赖固定时间间隔,忽略非连续事件 | RE-NET, RE-GCN, TiRGN |
| 基于时序点过程 | 建模事件发生的连续时间 | 适配不规则时间间隔 | 强度函数设计复杂 | Know-Evolve, GHNN, EvoKG |
| 基于可解释性 | 提供推理路径与解释 | 结果可靠,便于落地 | 推理效率较低 | xERTE, CluSTeR, TITer |
| 基于语言模型 | 利用 LLM 增强语义理解 | 增强语义表达,适配零样本场景 | 依赖预训练数据,计算开销大 | ICLTKG, zrLLM, ECOLA |
| 基于少样本学习 | 解决新实体/关系稀疏问题 | 数据效率高 | 元学习框架设计复杂 | MetaTKG, TR-Match, MTKGE |
| 其他(几何 / ODE 等) | 复制机制、几何建模、微分方程 | 适配连续 / 复杂结构 | 模型通用性较弱 | CygNet, TANGO, BoxTE |
1.1.4.2 补全方法(内插)
侧重于估计现有时间边界内的未知知识。
- 基于张量分解
- 将 TKG 视为 4 维张量(实体 × 关系 × 实体 × 时间戳),通过分解学习低维表示,天然融入时间信息。
- CP 分解(Lin & She (2020)、Lacroix et al. (2020));Tucker 分解(Shao et al. (2021) )
- 基于时间增强型变换
- 将时间戳视为 “变换函数”,将实体 / 关系的静态表示映射为时间依赖的动态表示。
- 合成时间依赖关系(Radstok & Chekol (2021)、García-Durán et al. (2018)、Wang et al. (2020));线性变换(超平面投影(Dasgupta et al., 2018)、复空间旋转(Xu et al., 2020a)、多分辨率编码(Leblay et al., 2020))。
- 基于动态嵌入模型
- 直接建模实体 / 关系的时序演化规律,表示随时间动态变化且存在依赖关系(如 “出生→工作→死亡” 不可逆)。
- 时间函数建模(分解式(Xu et al., 2020b)、双曲空间(Han et al., 2020a)、历时嵌入(静态段 + 时间依赖段)Goel et al. (2020);RNN 编码(结构化门控(Wu et al., 2020)、连续时间建模(Han et al., 2021))
- 基于知识图谱快照学习
- 将 TKG 拆分为按时间排序的快照序列$G_1,G_2,…,G_{|T|}$,建模快照间的演化关系。
- 马尔可夫过程模型(Xu et al. (2021b)、Liao et al. (2021));自回归模型(Recurrent Event Network(图卷积+GRU Jin et al., 2019))、NODEs 整合 Li et al., 2021b)。
- 基于历史上下文推理
- 利用 “时间戳揭示的事实先后顺序”,通过历史相关事实推理缺失链接。
- 注意力基相关性(时序关系图注意力 Han et al. (2020b)、时间位移编码 Jung et al. (2021));启发式基相关性(倾向性评分 Bai et al. (2021)、复制-生成混合 Zhu et al. (2021))。
1.1.4.3 预测方法(外推)
侧重于通过从历史模式中学习来预测未来事件。
- 基于嵌入表示
- 利用嵌入表示捕捉实体和关系的时序演化,通过学习历史嵌入模式来外推预测未来事实,常涉及动态嵌入函数或时间依赖表示,以处理未知时间戳的链接预测。
- DE-SimplE(Xu et al., 2020b);BoxTE(Messner et al., 2022);DyERNIE(Han et al., 2020a)。
- 基于逻辑规则
- 应用逻辑规则进行时间推理的方法,通过从历史事实中提取时序逻辑规则(如随机游走或可微分学习),实现可解释的多跳推理和未来事件预测。
- LLM-DA (NeurIPS 2024);TLogic(Liu et al., 2022);TPRG(Park et al., 2023);TILP(Xiong et al., 2022)。
- 基于图神经网络
- 使用GCN、GAT和Transformer建模结构和时间依赖的方法,将TKG视为历史快照序列,通过图卷积或注意力机制捕捉时空动态,实现未来链接的外推预测。
- RE-NET(Jin et al., 2019);RE-GCN(Li et al., 2021a);TiRGN(Li et al., 2021b);TANGO(Han et al., 2021);rGalT(Xu et al., 2022)。
- 基于元学习
- 专为少样本学习场景设计的方法,通过元优化或匹配网络学习历史少样本事实的元知识,实现对新兴实体和关系的快速适应与未来预测。
- MetaTKGR(Park et al., 2022);FTAG(Xiong et al., 2022);MOST(Wang et al., 2022);TFSC(Chen et al., 2023)。
- 基于强化学习
- 将时间知识图谱补全框架为序列决策问题的方法,通过马尔可夫决策过程和代理探索时序路径,最大化累积奖励以预测未来缺失事实。
- DREAM(Wu et al., 2023);RLAT(Chen et al., 2023);TimeTraveler(Zhang et al., 2022)。
- 基于大语言模型
- 利用大语言模型进行TKG推理的方法,通过检索增强生成或零样本学习,将历史事实序列化为提示,实现高效的未来事件预测,尤其适用于稀疏数据场景。
- GenTKG(Park et al., 2024);zrLLM(Chen et al., 2023);ONSEP(Wang et al., 2024)。
- 基于大语言模型与图模型融合
- 融合大语言模型与图模型进行推理的方法,通过即插即用模块(如适配器或神经符号框架),结合图神经网络的结构捕捉与LLM的语义理解,提升外推预测的准确性和适应性。
- COH(Li et al., 2024);TKG-LM(Han et al., 2023);TGL-LLM(Xiong et al., 2024)。)
1.1.5 数据集
| 数据集 | 实体数 | 关系数 | 时间戳数 | 事实数 | 时间戳类型 | 应用场景 | 关键特点 |
|---|---|---|---|---|---|---|---|
| ICEWS14 | 7,128 | 230 | 365 | 90,730 | 时间点 | 知识推理 | 2014 年全球事件数据,包含政治、军事、经济等领域的事件,数据来源于新闻媒体和社交媒体,专注于危机预警系统 |
| ICEWS05-15 | 10,488 | 251 | 4,017 | 461,329 | 时间点 | 知识推理 | 2005-2015 年共 11 年全球事件数据,包含超过 46 万条事实,时间戳粒度精细,适合研究长期事件演化模式 |
| ICEWS18 | 23,033 | 256 | 304 | 468,558 | 时间点 | 知识推理 | 2018 年全球事件数据,包含 23,033 个实体和 256 种关系,是知识推理任务常用数据集 |
| ICEWS21 | - | 253 | 243 | - | 时间点 | 问答 | 2021 年全球事件数据,专门用于问答任务 |
| GDELT | 7,691 | 240 | 2,751 | 2,278,405 | 时间点 | 知识推理 | 全球社会事件数据库,每 15 分钟更新一次,覆盖全球 100 多种语言的广播、印刷和网络新闻,时间戳粒度最细,适合研究实时事件演化 |
| Wikidata (KR) | 12,554 | 24 | 232 | 669,934 | 时间点/时间区间 | 知识推理 | 协作式多语言辅助知识库,由维基媒体基金会托管,自由开放,可由人类和机器读取和编辑,许多项目具有时间信息,适合研究稀疏时间数据 |
| Wikidata (QA) | 432,715 | 814 | 1,726 | 7,224,361 | 时间点/时间区间 | 问答 | 专门用于问答任务的 Wikidata 版本,规模较大,适合复杂问答场景 |
| YAGO | 10,623 | 10 | 189 | 201,089 | 时间点/时间区间 | 知识推理 | 由德国马克斯·普朗克研究所开发的链接数据库,整合 Wikipedia、WordNet 和 GeoNames 数据,将 WordNet 的单词定义与 Wikipedia 分类系统结合,添加时空信息 |
| DICEWS | 9,517/9,537 | 247/246 | 4,017 | 307,552/307,553 | 时间点 | 实体对齐 | ICEWS 特定版本,用于实体对齐任务,适合研究跨知识图谱的实体对齐 |
| YAGO-WIKI | 49,626/49,222 | 11/30 | 245 | 221,050/317,814 | 时间点/时间区间 | 实体对齐 | YAGO 和 Wikidata 的组合数据集,用于实体对齐任务,整合了两种知识库的时空信息 |
[!NOTE] 说明:
- “KR”表示 Knowledge Reasoning(知识推理)
- 数据集中”-“表示该数据未明确提供
- 部分数据集在不同应用中有不同的统计值(如 DICEWS 和 YAGO-WIKI)
- GDELT 是时间粒度最细的数据集,每 15 分钟更新一次
- ICEWS 系列数据集主要关注全球事件,特别适用于危机预警系统
- Wikidata 和 YAGO 提供了多类型时间戳,适合研究稀疏时间数据和历史事件
- 针对不同应用场景(知识推理、实体对齐、问答),数据集的使用方式和统计特征有所不同
1.1.6 核心评估指标
- Hits@k :关注正确答案的 “覆盖概率”,真实结果进入前 k 名的比例(越接近 1 越好);
- Mean Ranking(MR):真实结果的平均排名(越小越好);
- Mean Reciprocal Ranking(MRR):关注正确答案的 “排名质量”,平均倒数排名(越接近 1 越好)。
1.1.7 具体任务
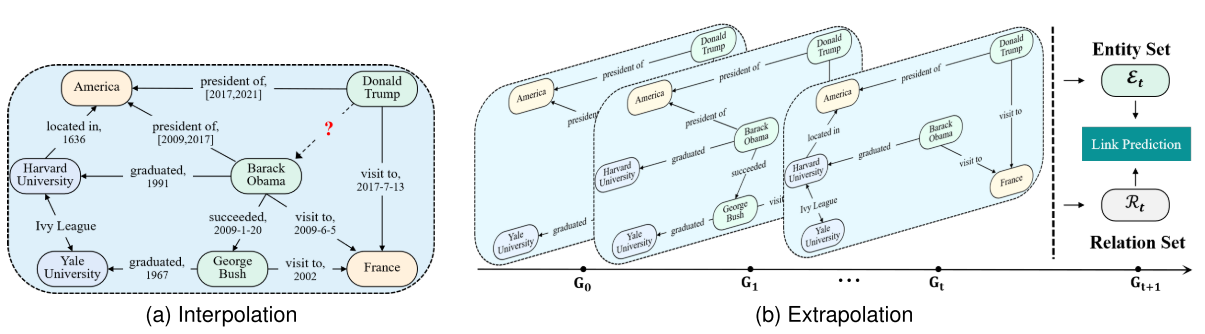
- 实体预测:
- 核心任务,含$(?, r, t, \tau)$(头实体)和$(h, r, ?, \tau)$(尾实体),不可逆推理需引入逆关系$r^-$;
- (?, 访问, 中国, 2026-03-15) → 预测谁可能访问中国?
- 关系预测
- $(h, ?, t, \tau)$,预测实体间的关系;
- (马斯克, ?, 推特, 2026-01-01) → 预测他可能做什么?
- 时间预测
- $(h, r, t, ?)$,预测事实成立的时间。
- (美国, 发射, 火星探测器, ?) → 预测下一次发射时间?
1.1.8 应用场景
1.1.8.1 时间知识图谱推理
- 任务类型:
- 插值任务(TKGC): 预测当前时间范围内的缺失事实
- 外推任务(TKGF): 预测未来事实
- 主要方法:
- 插值任务: 转换方法、分解方法、GNN 方法、胶囊网络方法
- 外推任务: 自回归方法、TPP 方法、少样本学习方法
- 可解释性方法: 提供预测证据,增强可靠性
- 增强方向:
- 语义增强技术: 利用实体和关系名称、事实关联的文本描述
- 大语言模型: 捕获实体和关系的丰富语义信息
1.1.8.2 时间知识图谱间的实体对齐
- 问题定义: 给定两个 TKG G₁和 G₂,寻找等价实体
- 主要方法:
- TEA-GNN: 首个引入时间感知注意力 GNN 的实体对齐方法
- TREA: 通过时序关系注意力 GNN 整合关系和时间特征
- STEA: 提出简单 GNN 模型,结合时间信息匹配机制
- 步骤 1: 融合结构和关系特征生成实体嵌入
- 步骤 2: 通过 GNN 聚合更新实体嵌入
- 步骤 3: 连接各层 GNN 嵌入,结合时间相似度获取对齐实体
1.1.8.3 时间知识图谱上的问答
- 问题定义: 基于 TKG 回答自然语言问题,答案通常为实体或时间戳(如 “2014 年奥巴马对伊朗发表过声明吗?”)
- 主要方法:
- CRONKGQA: 结合 TKG 和问题表示,使用 TComplEx 和 BERT 获取表示
- TSQA: 时序敏感问答模型,包含:
- 时序感知 TKG 编码器: 使用带时间顺序约束的 TComplEx;
- 时序敏感问答模块。
1.1.9 未来方向
1.1.9.1 TKG表示
- 可扩展性
- 现状:现有数据集规模远小于真实世界 TKG,模型难以适配亿级实体 / 关系
- 方案:分布式训练(并行处理数据)、聚类采样(减少计算量)、高效负采样(平衡训练数据)
- 可解释性
- 现状:多数模型为 “黑盒”,预测结果缺乏追溯依据
- 方案:注意力机制定位关键时序证据、交互式可视化展示推理路径
- 信息融合
- 现状:多数模型仅用结构化数据,忽略文本等非结构化信息
- 方案:多模态融合(新闻文本 + TKG 事实)、动态加权(不同时间 / 来源信息的重要性适配)
- 融合 LLMs
- 现状:TKG 的语义表达依赖人工设计,缺乏泛化性
- 方案:用 LLM 生成实体 / 关系的语义嵌入、用 LLM 扩充事实的文本描述,增强跨场景适配性
1.1.9.2 TKGC推理
- 少样本学习
- 现状:知识图谱存在长尾分布,导致实体和关系稀疏,现有的TKGC方法主要依赖转导学习假设(假设有大量训练数据),限制了实际应用中对稀有或未见实体的处理。
- 方案:开发鲁棒的方法来处理稀有或未见的实体和关系,超越转导学习假设;引入领域知识(如关系逆性)、实体类型,以及预训练语言模型(如BERT)来补充语义信息,提升模型泛化能力。
- 时间感知负采样
- 现状:现有TKGC负采样策略忽略时间维度,容易导致梯度消失问题,无法有效捕捉“事实-时间戳”的复杂交互,从而影响模型训练效果。
- 方案:建模“事实-时间戳”的复杂交互,生成更具区分性的负样本;通过时间感知的采样机制(如基于时间序列的动态调整)来优化训练过程,避免梯度消失并提升模型鲁棒性。
- 大规模知识图谱适配
- 现状:现有TKGC模型训练时间过长(从小时级到天级),无法适应亿级事实的真实大规模知识图谱,导致实际部署困难。
- 方案:研究分布式训练框架和组合嵌入方法(如使用少量共享特征构建实体/关系表示),以提高训练效率和可扩展性,适应大规模数据。
- 动态知识图谱增量学习
- 现状:真实知识图谱持续更新(包括事实的增删),现有模型需从头重训,容易导致计算开销巨大和知识遗忘问题。
- 方案:引入持续学习技术(如经验回放、知识蒸馏和正则化),解决灾难性遗忘问题,实现增量更新和高效适应图谱演化。
- 多模态时间知识图谱
- 现状:现有TKGC主要依赖单一模态(如文本),无法全面描述实体和事件的动态演化,限制了语义丰富度和下游应用效果。
- 方案:整合不同数据模态(文本、图像、音频),超越传统的符号方法,构建多模态时间知识图谱,以丰富时间知识表示并支持如视觉问答等复杂任务。
- 与大型语言模型的集成
- 现状:大型语言模型(LLM)通常在静态语料库上训练,缺乏动态时间建模能力,无法有效处理TKG的演化知识,导致参数知识与符号知识的融合不足。
- 方案:解决LLM与动态TKGC推理的结合挑战,通过参数知识和符号知识的统一框架(如提示学习或混合嵌入),提升模型对时间依赖的捕捉和泛化能力。
- 可解释性
- 现状:基于深度学习的TKGC模型大多为黑箱,推理过程不透明,限制了在高风险应用(如股价预测、医疗诊断)中的使用,用户难以理解模型决策。
- 方案:增强模型透明度,通过开发可解释机制(如路径可视化或注意力分析),提供人类可读的推理解释,特别针对时间模式,确保在高风险场景中的可靠性和信任度。
- 时间逻辑查询回答
- 现状:现有复杂查询回答方法难以处理带时间条件的查询(如时间间隔、多跳推理),尤其在演化TKG中,无法精确捕捉时间约束。
- 方案:扩展复杂查询嵌入模型,处理复杂时间约束(如间隔、持续时间和粒度),通过神经几何操作实现多跳时间推理,提升查询准确性和精确性。
[!TIPS] 关键启示
时间知识图谱表示学习和推理不仅是技术研究,更是理解动态世界的关键工具。随着大语言模型与TKG的深度融合,我们有望构建真正理解时间维度的智能系统,为决策支持、预测分析等应用提供更可靠的基础。
1.2 我的方向
少样本场景下基于大语言模型的时序知识图谱可解释性推理增强研究
1.2.1 标题
1.2.2 痛点问题
1.2.3 创新点
1.2.4 贡献
1.2.5 技术方案
1.2.6 数据集
1.2.7 实验设计
1.2.8 结论
1.2.9 参考文献
研究思路
https://alleyf.github.io/2024/08/e73efe4b2ca2.html