Large Language Models for Generative Information Extraction A Survey
本文最后更新于:2 个月前
Large Language Models for Generative Information Extraction A Survey
汇报人:范财胜
所属单位:武汉理工大学
汇报时间:2024-06-10 18:51:45
联系方式:alleyf@qq.com
📕 目录
📜 引言
| Meta | Value |
|---|---|
| 标题 | Large Language Models for Generative Information Extraction: A Survey |
| 期刊/会议 | arxiv |
| 作者 | 徐德荣, 陈伟, 彭文俊等 |
| 来源 | 中国科学技术大学-认知智能国家重点实验室; 香港城市大学; 腾讯优图实验室; |
| 日期 | 2023-12-29-v1;2024-06-04-v2 |
| 原文链接 | [2309.13249] A Survey of Document-Level Information Extraction |
| 相关仓库 | GitHub - quqxui/Awesome-LLM4IE-Papers: Awesome papers about generative Information Extraction (IE) using Large Language Models (LLMs) |
| 标签 | 信息抽取, 大规模语言模型, 生成式学习, 自然语言处理 |
📑 背景
通过系统性回顾,探讨了大规模语言模型在信息抽取(IE)领域的最新进展。信息抽取旨在从自然语言文本中提取结构化知识,是自然语言处理的关键领域。近年来,生成式大规模语言模型展现了卓越的文本理解和生成能力,推动了基于生成范式的 IE 任务研究。文章首先概述了各种 IE 子任务和技术分类下的工作,随后实证分析了先进方法,并揭示了使用 LLMs 进行 IE 任务的新兴趋势。
👑 贡献
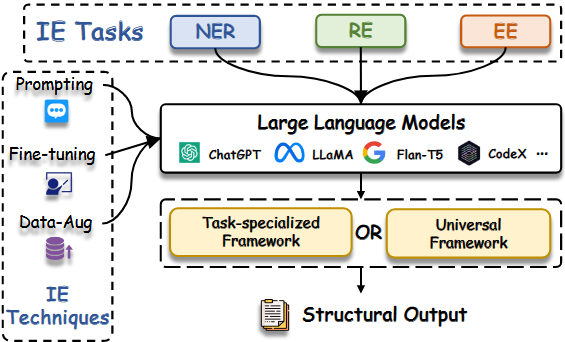
本文综述了利用大规模语言模型(LLMs)进行生成式信息抽取的研究进展,对生成 IE 的 LLM 进行了全面的探索,如上图所示。分析了LLMs在不同子任务和领域的应用技术,评估了最新方法,并指出了未来研究方向。
✨ 相关概念
信息抽取(IE):信息提取是自然语言处理(NLP)中的一个关键领域,它将纯文本转换为结构化知识(例如实体、关系和事件),并作为各种下游任务的基础。
**命名实体识别(Named Entity Recognition, NER)*:命名实体识别是信息抽取的一个子任务,目标是从文本中 识别出具有特定意义的实体,如人名、地名、组织名、时间、数量*等,并将其 分类到预定义的类别(本体)中。
**关系抽取(Relation Extraction, RE)*:关系抽取则是 识别和提取文本中实体之间的语义关系。这包括但不限于实体之间的亲属关系、组织隶属关系、时间关系*等。关系抽取可以进一步细分为 关系分类、关系三元组抽取和严格关系抽取,分别对应于识别关系类型、同时识别关系类型及实体头尾跨度,以及提供关系类型、实体头尾跨度及其类型的任务。
*事件抽取(Event Extraction, EE)*:事件抽取专注于识别文本中描述的事件及其组成部分。它被划分为两个主要子任务:事件检测(或称为事件触发词抽取)和 事件论元抽取。事件检测目的是找出代表事件发生的触发词及其类型*,而事件论元抽取则涉及识别与事件相关的各个角色*,比如参与者、时间、地点等,并对其进行分类。
📊 研究现状
生成式信息抽取当前两大研究工作:
多任务的通用框架:除了在个别 IE 任务中表现出色之外,LLMs 还拥有以通用格式有效建模各种 IE 任务的卓越能力。这是通过使用指导性提示捕获任务间依赖性来进行的,并实现一致的性能。
少样本场景下的前沿学习技巧:不仅可以通过微调从 IE 训练数据中学习,而且可以在少样本甚至零样本中提取信息。仅依赖上下文中的示例或说明来捕获场景。
🔬研究方法
🚩 研究结论
💡 感想 & 疑问
致谢
感谢各位老师和师兄师姐们的聆听,如有不当敬请批评指正!
后期目标:学习 pytorch 框架的使用,继续阅读基础经典论文与前沿价值论文。