运维排忧解难
本文最后更新于:2 个月前

1 常用指令
[!NOTE] 符号说明
指令中小括号()内为选填项,<>为填充项(根据实际变量进行填充)。
1.1 Linux 指令
1.1.1 磁盘扩容
1.1.1.1 已存在磁盘(使用余量扩容分区)
1.1.1.1.1 确认剩余空间
使用 lsblk 或 fdisk -l 查看新增磁盘的设备名(如 /dev/sdb)
1 | |
查看磁盘总容量
/dev/sda总容量为 322.1GB,已分配的分区如下:/dev/sda1(启动分区):1GB/dev/sda2(LVM 物理卷):107.4GBcentos-root(根分区):53.7GBcentos-swap(交换分区):5.3GBcentos-home(用户数据分区):47.3GB
计算未使用空间
sda2的结束扇区为209715199,而/dev/sda总扇区为629145600,未分配空间约为 214.7GB(322.1GB - 107.4GB)查看文件系统
1 | |
1.1.1.1.2 扩容根目录逻辑卷
步骤 1:识别并扩展 Sda2 分区
1 | |
由于未分配空间位于 sda2 之后,需先扩展 sda2 分区以包含全部磁盘空间:
1 | |
步骤 2:扩展物理卷
将新增空间加入 LVM 物理卷:
1 | |
步骤 3:扩展逻辑卷
- 查看卷组(VG)信息
1 | |
- 扩展根逻辑卷(LV)
1 | |
步骤 4:调整文件系统
根据文件系统类型执行扩容:
- ext4 文件系统:
1 | |
- xfs 文件系统:
1 | |
1.1.1.1.3 验证结果
1 | |
1.1.1.1.4 注意事项
- 备份数据
操作前建议对重要数据备份,避免扩容失败导致数据丢失 - 文件系统类型
通过lsblk -f确认根目录文件系统类型(如 xfs 或 ext4)。 - 在线扩容
若使用 xfs 文件系统,支持在线扩容;ext4 需确保文件系统未损坏。
1.1.1.1.5 扩展场景(可选)
- 调整 home 分区空间
若无需保留home分区数据,可删除/dev/mapper/centos-home,将其空间合并到根目录:
- 备份 home 数据后卸载:
1 | |
- 扩展根逻辑卷:
1 | |
1.1.1.2 新增磁盘
1.1.1.2.1 VSphere 给虚拟机加新硬盘
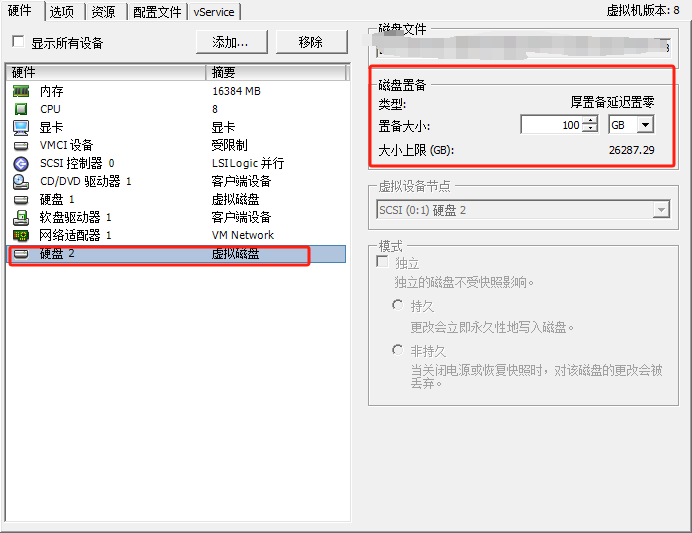
添加完成硬盘后,重启虚拟机以识别到新硬盘。
1.1.1.2.2 新硬盘创建物理卷(PV)
首先,你需要将 sdb 磁盘转化为物理卷。
1 | |
1.1.1.2.3 扩展卷组(VG)
将这个新的物理卷加入到现有的卷组中
1 | |
1.1.1.2.4 扩展逻辑卷(LV)
现在可以扩展 / 根目录所在的逻辑卷了,以增加 100GB 为例(根据实际情况调整大小)
1 | |
如果你想使用 sdb 上的所有空间
1 | |
1.1.1.2.5 扩展文件系统
最后一步是扩展文件系统以使用新增的空间。这个步骤依赖于你 / 根目录使用的文件系统类型。
如果是 Ext4 文件系统
1 | |
如果是 XFS 文件系统
1 | |
1.1.2 磁盘缩容
前提:
- 待缩小的空间必须是磁盘末尾没有被分配使用的空余空间(eg:误扩容磁盘过大;新增的磁盘等)
- 存储空间充足,足以克隆出一个原磁盘实际使用大小的容量。
1.1.2.1 参考文献
ESXi手动缩小vmdk虚拟机硬盘大小
配置ssh连接Esxi、ESXi 收缩虚拟硬盘文件(.vmdk) 大小(回收ESXi thin磁盘空间)
1.1.2.2 准备工作
备份数据:操作前务必对虚拟机进行完整备份(快照)
确认工具:
- Windows:磁盘管理器/DiskGenius
- Linux:GParted Live 镜像
用 GParted 调整分区,注意:
- 保持/boot 分区起始位置不变
- 空闲空间必须移至磁盘末尾vmkfstools 压缩空白空间:需要先填充 0
1 | |
1.1.2.3 分区调整
- SSH 连接 ESXi 主机
1 | |
- **修改 vmdk 描述文件
- 调整
RW参数值(计算公式:目标 GB 数×1024³/512)
1 | |
- 更新
ddb.geometry.cylinders(参考值):
1 | |
- 克隆重建磁盘
1 | |
- 修正文件引用
- 再次编辑src.vmdk,确保指向
src-flat.vmdk - 删除可能存在的
deletable行
- 再次编辑src.vmdk,确保指向
1.1.2.4 最终处理
- 在 ESXi 界面执行【虚拟机→快照→整合硬盘】
- 重启虚拟机验证数据完整性
注意事项
- 操作前确保虚拟机已关闭
- 大容量磁盘处理耗时较长(建议低峰期操作)
- 若出现错误,立即还原备份文件
1.1.3 检查磁盘空间并清理
你的系统根分区 /dev/mapper/centos-root 已 100% 满了(196G 已用完,仅剩 104K),必须立即清理,否则系统可能崩溃、服务宕机、无法登录。
1.1.3.1 🔍 第一步:快速定位大目录(按大小排序)
运行以下命令,从根目录开始,找出占用空间最大的目录:
1 | |
✅ 输出示例:
2
3
4
5150G /var
30G /usr
10G /home
5G /opt
...
重点关注 /var、/tmp、/home、/root、/usr 等目录。
1.1.3.2 🧹 第二步:重点清理常见“临时/日志”目录
1.1.3.2.1 清理系统日志(通常在 /var/log)
1 | |
1.1.3.2.2 清理临时目录
1 | |
1.1.3.2.3 清理 YUM 缓存(如果是 CentOS/RHEL)
1 | |
1.1.3.2.4 清理 Docker(如果你用了 Docker)
1 | |
1.1.3.2.5 清理旧内核(如果 /boot 也满,但你这里 /boot 只用了 5%)
1 | |
1.1.3.3 🔎 第三步:查找大文件(>100MB)
1 | |
常见“罪魁祸首”:
- 日志文件:
*.log、journal、catalina.out(Tomcat) - 数据库 dump 文件:
*.sql、*.bak - 临时下载文件:
/root/*.zip、/tmp/*.tar.gz - 应用缓存:
/home/*/.cache、/var/lib/*
1.1.3.4 💡 第四步:紧急释放空间(如果上述不够)
1.1.3.4.1 方案 A:临时扩容(如果用了 LVM)
但你的 df -h 显示是 LVM(/dev/mapper/centos-root),可检查是否有未分配空间:
1 | |
如果有剩余,可扩容(但需先清理出一点空间才能操作)。
1.1.3.4.2 方案 B:删除无用大文件(谨慎!)
1 | |
⚠️ 切勿删除你不认识的文件! 尤其是
/bin、/sbin、/lib下的文件。
1.1.3.5 ✅ 第五步:预防措施
设置 logrotate(自动轮转日志)
1
sudo vi /etc/logrotate.d/your_app监控磁盘使用
1
2
3
4# 安装监控工具
sudo yum install -y ncdu
# 交互式查看目录大小
sudo ncdu /定期清理脚本
1
2# 添加 cron 任务
echo "0 2 * * 0 /usr/bin/yum clean all" | sudo crontab -
1.1.3.6 🚨 紧急操作建议
你现在 必须立即清理至少 1~2GB 空间,否则:
systemd可能无法写日志- SSH 可能拒绝新连接
- 数据库可能 crash
优先执行:
1 | |
然后再次运行:
1 | |
确认 / 分区 Use% 降到 95% 以下。
完成清理后,建议用 ncdu 工具深入分析:
1 | |
它会交互式显示目录大小,方便你精准定位“空间吞噬者”。
1.1.4 Ssh 连接
-p 指定端口,默认不带则为 22 端口
1 | |
1.1.5 Glusterfs 文件挂载
1 | |
卷名通过 rancher 里找到对应的 volume 查看。
1.1.6 文件传输
通过 ssh 协议用于在本地计算机和远程计算机之间安全地复制文件
- 本地到远程
1 | |
- 远程到本地
1 | |
1.1.7 查看路由表
1 | |
1.1.8 查看资源
查看所有资源占用情况,降序排列,top 默认会实时更新显示的信息,通常每秒刷新一次。
1 | |
- 排序:
- 按 CPU 使用率排序:按
P键。 - 按内存使用率排序:按
M键。 - 按执行时间排序:按
T键。
- 按 CPU 使用率排序:按
- 搜索进程:
- 输入
u键,然后输入用户名,可以显示该用户的所有进程。 - 输入
p键,然后输入进程 ID(PID),可以快速定位到特定进程。
- 输入
- 过滤进程:
- 输入
U键,然后输入用户名,可以过滤显示该用户的进程。 - 输入
P键,然后输入进程 ID(PID),可以过滤显示该 PID 的进程。
- 输入
- 杀死进程:
- 输入
k键,然后输入进程 ID 和要发送的信号(默认是 SIGTERM,即 15),可以杀死进程。
- 输入
1.1.9 查看进程
ps 命令在 Unix-like 系统中用于显示当前进程的状态。
1 | |
参数说明
USER:进程所有者的用户名。PID:进程的 ID。%CPU:进程占用的 CPU 百分比。%MEM:进程占用的内存百分比。VSZ:虚拟内存大小(Virtual Size)。RSS:实际内存大小(Resident Set Size)。TTY:进程终端类型。STAT:进程状态。START:进程启动时间。TIME:进程占用 CPU 的时间。COMMAND:启动进程的命令。
常见组合
- ps aux (–sort=-%mem/cpu): 显示所有进程(按照内存/CPU 使用率降序排列进程)
- ps -ef:显示所有进程的完整信息。
- ps -p PID:显示特定进程的详细信息。
1.1.10 查看内存
以人类可读的方式展示内存使用状态。
1 | |
1.1.11 查看硬盘
以人类可读的方式展示磁盘分配状态。
1 | |
1.1.12 查看系统日志
journalctl 是 systemd 系统服务管理器的一部分,用于查询和显示日志消息。它提供了一种方便的方式来查看系统日志,特别是与特定服务或单元相关的日志。
1 | |
查看系统日志
1 | |
查找 cpu 相关日志:
1 | |
1.1.13 查看编辑文件
1.1.13.1 搜索文件
按照关键词搜索含有关键词的文件
1 | |
1 | |
1 | |
搜索指定文件名的文件
1 | |
1.1.13.2 查看文件数量
1 | |
1.1.13.3 查看目录
列出当前目录下的文件和文件夹
1 | |
常见搭配
- ls -lh:组合使用
-l和-h选项,以易读的格式显示文件大小。 - ls -l:以长列表格式显示文件详细信息,包括权限、所有者、大小和最后修改时间。
- ls -lt:以修改时间排序,最新修改的文件排在最前面。
- ls -lS:以文件大小排序。
- ls -a:显示所有文件,包括以点(
.)开头的隐藏文件。 - ls -R:递归地列出所有子目录的内容。
- ls -F:在每个文件名后添加一个字符以指示文件类型,例如,
/表示目录,*表示可执行文件。 - ls -o:显示文件所有者和组,但不显示组名。
- ls –color:使用颜色来区分不同类型的文件。
- ls *.txt:列出当前目录下所有的
.txt文件。
- ls -lh:组合使用
参数解释:
drwxr-xr-x 10 root root 4.0K Feb 22 21:41 clash- d:目录/文件
- rwx:文件所有者的权限,
r代表可读(read),w代表可写(write),x代表可执行(execute) - r-x:文件所有者同组的用户(group)的权限,可读可执行但不可写
- r-x:其他用户(others)的权限,可读可执行但不可写
- 10:硬链接指向这个目录的个数,目录至少为 2(一个是
.表示当前目录,另一个是..表示父目录),加上目录下文件和子目录的数量。 - root root:文件所有者和组的名称。
- 4.0K:目录占用空间大小(不包括子文件和子目录)。
- Feb 22 21:41:目录最后修改的日期和时间。
- clash:目录名称。
1.1.13.4 查看内容
查看文件内容,打印在控制台
1 | |
1.1.13.5 新建文件
新增一个文件,或写入内容到文件中
1 | |
1.1.13.6 编辑内容
使用 Vim 编辑器编辑文件
1 | |
- 常见操作:
- i:进入插入写模式
- esc:退出当前模式
- :指令模式
- :q:直接退出
- :wq:保存退出
1.2 K8s 和 Docker 相关指令
1.2.1 K8s
1.2.1.1 集群
获取 prod 集群中所有节点信息
1 | |
1.2.1.2 节点
获取指定命名空间下的所有 pod
1 | |
获取指定 pod 的详情(可根据 event 排查 pod 的错误信息)
1 | |
条件查询指定命名空间下指定状态的 pod 并批量删除
1 | |
eg:
1 | |
强制删除 pod
1 | |
1.2.1.3 Pod
启动定时任务
1 | |
启动定时任务并查看日志
1 | |
1.2.1.4 Deployment
1.2.1.4.1 查看 Deployment 的标签
1 | |
1.2.1.4.2 实时查看控制台日志
1 | |
1.2.1.5 复制文件
1 | |
1.2.1.6 创建 Configmap
- 命令创建
通过参数
--from-literal直接指定键值对。这种方式比较适用于临时测试使用,而且不适合配置很多的情况。
1 | |
- 文件创建
通过参数
--from-file来指定文件。查看内容如下:
1 | |
1.2.2 Docker
1.2.2.1 配置镜像
为镜像仓库配置下载源,查看 /etc/docker/daemon.json 文件来确定当前配置的镜像源,如果该文件不存在或为空,则默认使用 Docker 官方镜像源。
- 查看镜像源配置
1 | |
- 修改配置
多个镜像源以逗号分隔
1 | |
常见镜像源:
- public-image-mirror
- ISCAS 开源镜像站
- docker.rainbond.cc
- 网易云镜像源
- icu紧急镜像源
- 阿里云镜像源
- 上海交大镜像站
- 南京大学镜像站
- DockerHub国内镜像源列表-20240618
- 从 Docker Hub 拉取镜像受阻?这些解决方案帮你轻松应对
- 国内无法拉取Docker镜像了?这些方法拯救你的Docker-腾讯云开发者社区-腾讯云
测速(测速前先移除本地的镜像!)
docker rmi nginx:latest
time docker pull nginx:latest
- 重启服务更新配置
1 | |
1.2.2.2 保存镜像
将指定本地镜像保存为 tar 压缩包
1 | |
1.2.2.3 加载镜像
根据指定镜像压缩包加载镜像到本地
1 | |
1.2.2.4 删除镜像
删除所有未使用的镜像,容器和存储卷。
1 | |
1.2.2.5 更新镜像
对已有的变更环境进行保存以便于 pod 重启后维持最新环境
1 | |
OPTIONS-a或--author:设置镜像的作者字段。-c或--change:应用 Dockerfile 指令来创建镜像。-m或--message:提交时的说明信息。-p或--pause:提交时暂停容器运行(默认为 true)。
CONTAINER是你要提交的容器的 ID 或名称。REPOSITORY是新创建镜像的仓库名称。TAG是可选的,用于给镜像指定一个标签,如果不指定,默认标签是latest。
1.3 MySQL 指令
1.3.1 找到配置文件位置
1 | |
1.3.2 查看日志所在位置
1 | |
2 常见问题
[!warning] Tips
- 重启(物理机、虚拟机、服务、pod 等) 可能是
最直接常见的办法,但不是最有效的办法,具体问题具体分析,重在根据问题逐步搜索的排查思路,自顶向下排查,自底向上解决。- 遇到问题不要慌,众里寻它先百度,属是不行再问路,先思考后动脑,多学多看多实践,能力日益节节高。
2.1 镜像无法拉取
- 原因:由于国内防火墙导致国外官方镜像仓库被墙无法拉取镜像,本地镜像库缓存导致拉取时没有找到最新镜像,docker 网络问题,系统网络问题
- 办法:
- 出国旅游:windosw 开启魔法拉取镜像后通过 docker save 和 load 转移镜像,并 push 到本地私有镜像仓库留存。
- 取而代之:寻找国内镜像源仓库,直接拉取国内镜像仓库的镜像到本地,并推送到本地私有仓库留存。(国内镜像仓库不稳定,可能会清除镜像)
- 重启 docker:docker pull 卡在 waiting 则可能是网络问题,将 pod 所在节点的 docker 进行重启。
- 检查 hosts 添加记录:
cat /etc/hosts记录格式:ip domain - 重启系统网络:
sudo systemctl restart NetworkManager
2.2 内存/硬盘满载/溢出
- 原因:随着时间的累积和负载变化,内存或硬盘资源可能会不够,虚拟机负载过大,无法提供正常响应。
- 办法:
- 内存:清理无用进程(kill),重启虚拟机(reboot),扩容内存(vcenter 扩大虚拟机内存)
- 硬盘:查看磁盘分区和挂载情况(df -h),清理无用文件(rm -rf),转移文件(mv),硬盘扩容(分配更多分布式存储容量,添加一块磁盘并进行磁盘分区)
2.3 挂载卷存储满载
- 原因:挂载的数据卷存储容量有限,当满载后无法在挂载目录下新增目录或文件。
- 办法:
- 清理挂载目录下无用的文件,腾出可用空间
- 对挂载卷进行扩容,增加其存储容量。
2.4 CPU 核心过多软锁定
- 问题描述:
1 | |
- 原因:日志表明系统遇到了一个“软锁定”(soft lockup)的情况。这通常意味着某个进程或线程在 CPU 上运行了很长时间,导致系统监视器认为它可能已经冻结或卡住。
- 死锁:一个或多个进程可能陷入了死锁状态,导致 CPU 无法处理其他任务。
- 资源竞争:进程之间可能存在资源竞争,导致 CPU 长时间占用。
- 无限循环:代码中可能存在无限循环,导致 CPU 被持续占用。
- 内核问题:可能是内核本身的问题,比如驱动程序或内核补丁引起的问题。
- 高负载:系统可能由于高负载而无法及时响应。
cpu stuck 软锁定的原因有很多种,比如供电不足、虚拟机 cpu 核心数超过物理机核心数、虚拟机/物理机 cpu 太忙或磁盘 IO 太高、linux 内核 bug 等
- 办法:
- 使用
cat /var/dmesg或journalctl查看内核日志。 - 查看核心数是否过多(eg:32),关机减少核心数(eg:12);所有虚拟机的虚拟 cpu 加起来可能会超过物理机实际 cpu 线程数,但单个虚拟机的虚拟 cpu 处理器数不能超过物理机线程数,一般虚拟 cpu 个数和物理机 cpu 个数保持一致,总处理器数设为物理机的一半。(参考:虚拟机如何选择处理器和内核数量,实现最佳性能_虚拟机设置cpu处理器只有处理内核数量-CSDN博客)
- 使用
2.5 内存占用虚高
vmware虚拟机内存异常占用问题一例_esxi8.0占用内存怎么处理
2.6 MySQL 故障
参考:MySQL启动报错[ERROR] InnoDB: Trying to access page number 4294967295 in space 0, space name innodb
2.6.1 K8s 集群连不上
k8s 集群 kubelet日志报错 command failed“ err=“failed to parse kubelet flag: unknown flag: –network-p_command failed” err=”failed to parse kubelet flag
kubelet 版本节点之间不一致
查看状态和日志:
1 | |
查看版本:
1 | |
版本降级:
1 | |
重启 kubelet:
1 | |
2.7 Rancher 故障
2.7.1 Rancher 连不上 Apiserver
原因:cni 上层的网络组件出现了问题,可能是网络相关的 pod(kube-system 空间下或者直接-A 查看所有涉及到网络相关的 pod)挂了,重启后拉不到镜像导致网络不可用。
解决:排查网络相关组件 pod 是否正常,不正常则根据 event 和 status 进行解决。
2.8 集群域名修改
2.8.1 修改 242nginx 域名配置
修改 admin/nginx 目录下的 nginx 域名配置。
再使用 ./config 脚本更新重启 nginx 以生效配置。
2.8.2 改 233gitlab 配置文件里的域名
配置文件位置:/etc/gitlab/gitlab.rb
修改 gitlab 配置后重启,同步修改集群内的 gitlab-runner 配置(configmap)里的域名。
2.8.3 改 102harbor 配置文件里的域名
配置文件位置:/opt/harbor_1_7/harbor.cfg
修改 harbor 配置后重启,同步修改集群内的所有镜像的仓库地址(基础设施、定时任务、应用服务等)。
2.8.4 修改 Kubelet 的配置仓库鉴权域名
配置文件位于:/var/lib/kubelet/config.json
修改里面的仓库域名。
2.9 Harbor 镜像仓库清理
- 定位清理目标项目:登录 harbor 镜像仓库(registry.csdcinfo.cn),进入需要清理的项目。
- 过滤出待删除仓库镜像:进入需要删除的仓库,按照日期升序多选选中需要删除的镜像。

- 删除选中的 tag 镜像:在仓库中删除前面选中的 tag 镜像。

- 清理磁盘空间:上述删除仅为软删除并没有释放磁盘空间,需要进入系统管理的垃圾清理点击立即清理垃圾,此时会将前面软删除的镜像实际删除释放出占用的空间。

2.10 Mongodb 启动失败
问题:Rollback failed with unrecoverable error: UnrecoverableRollbackError: not willing to roll back more than 86400 seconds of data. Have: 263733 seconds
原因:分片挂掉没有及时启动,导致数据不一致,无法启动。
解决办法:
- 关闭 mongo 集群,找到这个分片的主分片,把它的整个目录复制到无法启动的那台分片上
- 增大同步时间限制,添加环境变量 MONGODB_EXTRA_FLAGS = –setParameter=rollbackTimeLimitSecs=172800,通过以下指令验证:mongo -u username -p password –authenticationDatabase admin –eval “db.adminCommand({getParameter: 1, rollbackTimeLimitSecs: 1})”
3 常用镜像
3.1 基础设施
3.1.1 Longhorn
longhornio/csi-attacher:v2.2.1-lh1
longhornio/csi-provisioner:v1.6.0-lh1longhornio/csi-resizer:v0.5.1-lh1
longhornio/csi-snapshotter:v2.1.1-lh1
longhornio/longhorn-engine:v1.1.0
longhornio/longhorn-instance-manager:v1_20201216
longhornio/longhorn-manager:v1.1.0
longhornio/csi-node-driver-registrar:v1.2.0-lh1
longhornio/longhorn-ui:v1.1.0
3.1.2 数据库
3.1.2.1 关系型
busybox:1.32
registry.csdc.info/publish/mysql:5.7.31
mysql:5.7.31
nacos/nacos-mysql-master:latest
nacos/nacos-mysql-slave:latest
prom/mysqld-exporter
3.1.2.2 非关系型
3.1.2.2.1 Redis
registry.csdc.info/publish/redis507
registry.csdc.info/publish/redis-exporter135
oliver006/redis_exporter:v1.3.4
registry.csdc.info/publish/redisinsight:latest
3.1.2.2.2 Neo4j
neo4j:3.5
3.1.2.2.3 ELK
registry.csdc.info/publish/elasticsearch-ik-py:7.16.2
registry.csdc.info/publish/elasticsearch-ik:7.9.2
docker.elastic.co/kibana/kibana:7.16.2
registry.csdc.info/elk/logstash/logstash:7.16.2
docker.elastic.co/eck/eck-operator:1.9.1
3.1.2.2.4 Mongodb
registry.csdc.info/publish/mongodb424:latest
registry.csdc.info/publish/mongodb-exporter:latest
3.1.2.3 OSS
minio/minio:RELEASE.2022-03-17T06-34-49Z
3.1.3 反向代理
nginx:stable
nginx:1.7.9
nginx:1.15
3.1.4 微服务中间件
3.1.4.1 Nacos
nacos/nacos-server:0.9.0
registry.csdc.info/publish/nacos/nacos-server:0.9.0
nacos/nacos-server:2.0.3
registry.csdc.info/publish/nacos221:latest
3.1.4.2 RabbitMQ
docker.io/bitnami/rabbitmq:3.11.6-debian-11-r0
3.1.4.3 Seata
docker.io/seataio/seata-server:latest
registry.csdc.info/etms/seata-server:latest
3.1.5 Gitlab
registry.csdc.info/publish/docker:stable-dind
gitlab/gitlab-runner:alpine-v13.7.0
gitlab/gitlab-runner-helper:x86_64-943fc252
3.1.6 Harbor
harbor.newershoe.com:8443/library/etcd
3.1.7 监控看板
3.1.7.1 Grafana
rancher/grafana-grafana:7.1.5
rancher/prometheus-auth:v0.2.1
grafana/loki:2.4.2
grafana/grafana:8.3.5
grafana/promtail:2.1.0
3.1.7.2 Prometheus
rancher/prom-prometheus:v2.18.2
rancher/coreos-prometheus-config-reloader:v0.39.0
rancher/jimmidyson-configmap-reload:v0.3.0
rancher/mirrored-library-nginx:1.19.9-alpine
3.1.8 SSH
registry.csdc.info/publish/panubo-sshd:latest
panubo/sshd
3.1.9 其他
registry.csdc.info/publish/dingtalk-chatbot:1.0.3
registry.csdc.info/publish/databasetools:0.0.2
registry.csdc.info/publish/rsync-ssh:latest
rancher/rancher-agent:v2.5.8
rancher/fleet:v0.3.1
rancher/gitjob:v0.1.8
rancher/nginx-ingress-controller-defaultbackend:1.5-rancher1
rancher/nginx-ingress-controller:nginx-0.35.0-rancher1
rancher/calico-kube-controllers:v3.16.1
rancher/calico-cni:v3.16.1
rancher/calico-pod2daemon-flexvol:v3.16.1
rancher/calico-node:v3.16.1
rancher/coreos-flannel:v0.13.0-rancher1
rancher/coredns-coredns:1.7.0
rancher/cluster-proportional-autoscaler:1.8.1
rancher/metrics-server:v0.3.6
rancher/hyperkube:v1.19.3-rancher1
registry.csdc.info/publish/k8s-sidecar:1.15.1
registry.csdc.info/publish/kube-state-metrics:v2.2.4
quay.io/prometheus/alertmanager:v0.23.0
jimmidyson/configmap-reload:v0.5.0
quay.io/prometheus/node-exporter:v1.3.0
prom/pushgateway:v1.4.2
quay.io/prometheus/prometheus:v2.31.1
rancher/rancher-operator:v0.1.3
registry.csdc.info/publish/tomcat:7
registry.csdc.info/elk/filebeat:7.9.2
registry.csdc.info/publish/locust-tasks
registry.csdc.info/publish/kubectl:v1.14
3.1.10 Research
conda:fus
centos:latest
nvidia/cuda:10.1-devel-ubuntu18.04
nvidia/cuda:10.1-cudnn7-devel-centos7
4 数据备份
4.1 备份清单
4.1.1 数据库备份
应用数据库备份(每天):
- K8s 内备份:
- srdb: mysql,mongodb
- smdb: mysql
- hsas: mysql
- cweb(每月):mysql
- dbServ(220)上备份:
- cmis:mysql(auth),oracle
4.1.2 文件备份
应用文件备份:
- K8S 内备份(每天):
- srdb
- smdb
- hsas
- cmis
- cweb(每月)
FTP 文件备份:
210 上备份(每早上 8 点):autosync_push.sh
GitLab 代码备份(每周天):autobackup.sh
4.2 注意事项
oracle 数据库定时任务无法备份如下报错:
ORA-31634: 作业已存在
ORA-31664: 如果采用默认值, 将无法构造唯一的作业名
参考:ORA-31634: 作业已存在
原因:job 队列满了。
解决:
1. 先查询出所有未运行的 Jobs:SELECT 'DROP TABLE ' || OWNER_NAME ||'.'|| JOB_NAME ||';' FROM DBA_DATAPUMP_JOBS WHERE STATE='NOT RUNNING';
2. 删除查询到的定时任务计划表:DROP TABLE CMIS.SYS_EXPORT_SCHEMA_xx;
5 应用部署
5.1 新建项目
5.1.1 Gitlab
在 gitlab 新建一个要开发部署的项目
5.1.2 Harbor
在 harbor 镜像仓库新建一个私有项目,后续该应用的所有镜像都存储在该镜像仓库,便于后续上传和拉取应用镜像。
[!NOTE] 注意
harbor 以 docker 容器化部署的,重启 102 虚拟机或者 docker 后需要启动所有相关的容器才能恢复正常。
6 宿主机 IP 更换
将 ESXi 主机置于维护模式。(可跳过)
使用 ESXi 主机 UI Client 或 KVM 或 ssh 直接连接。(可跳过)
更改 IP 地址并更新 DNS 服务器。
1
2
3cp /etc/vmware/esx.conf.backup /etc/vmware/esx.conf #备份宿主机配置文件
esxcli network ip interface ipv4 set -i vmk0 -I 192.168.88.206 -N 255.255.255.0 -t static #修改ip
esxcli network ip interface ipv4 get #查看是否生效将 ESXi 主机取消维护模式,迁移原虚拟机回来。(可跳过)
编辑虚拟机网络状态为已连接,否则 ping 不通。
[!NOTE] 注意
重启 harbor,openrestry。
7 RKE 调整集群节点
- 到目标集群的 etcd0 节点上,一般在 home/root 目录或者/home/docker 目录下有 rke 及 cluster.yml 配置文件。
- 修改
cluster.yml配置文件,对节点或其他配置进行修改。 - 通过
rke up --update-only --config cluster.yml指令更新集群配置。
- 注意所有节点的 docker 版本要和 rke 支持的版本对应,RKE 1.2.1 仅支持 Docker 1.13.x ~ 19.03.x。
RKE 1.3.24 支持 Docker 20.10.x ~ 26.x,不对应就降低 docker 版本。- 如果是新增节点按照下面详细过程配置添加,如果是移除节点重新添加则 cluster.yml 文件先注释掉节点配置,更新集群一遍后再取消注释逐步加 role(先加 worker 再加 controller 或 etcd 等)。
7.1 详细过程
- 所有 etcd 和 master 和 worker 节点的
/etc/hosts添加上所有节点名称和 ip 对应解析。
1 | |
vim /etc/sysctl.conf
1 | |
刷新配置
1 | |
- 关闭防火墙
1 | |
- 关闭 selinux
1 | |
- 主机 swap 分区设置
1 | |
- 时间同步
1 | |
- 添加 rancher 用户
使用 CentOS 时,不能使用 root 账号,因此要添加专用的账号进行 docker 相关操作。重启系统以后才能生效,只重
的!重启后,rancher 用户也可以直接使用 docker ps 命令
1 | |
- 复制 ssh 证书
从 rke 二进制文件安装主机上复制,如果已经复制,则可不需要重复性复制。
- 复制证书
1 | |
- 验证 ssh 证书是否可用
在 rke 二进制文件安装主机机测试连接其它集群主机,验证是否可使用 docker ps 命令即可。
1 | |
8 Ack 集群 Arthas 调试方法
1 | |
9 手动调整专网默认缺省路由
1 | |
9.1 创建 Systemd 服务固化路由配置
适用于使用 Systemd 的现代 Linux 系统(CentOS 7+, Ubuntu 16.04+)
- 创建服务文件:
1 | |
- 写入以下内容:
1 | |
- 启用并启动服务:
1 | |
10 Glusterfs 常用操作
10.1 查看容量
1 | |
10.2 扩容
在 170 主节点上执行以下命令
1 | |
11 K8s 静态路由配置
本地 Windows 如果需要能够访问 k8s 的内部网络,需要做静态路由:
- 测试环境
1 | |
- 正式环境
1 | |
- 研究环境
1 | |
- 查看静态路由表
1 | |