BERT Pre-training of Deep Bidirectional Transformers for Language Understanding
本文最后更新于:2 个月前
BERT Pre-training of Deep Bidirectional Transformers for Language Understanding
汇报人:范财胜
所属单位:华中科技大学
汇报时间:2024-02-28 10:22:04
联系方式:alleyf@qq.com
📕 目录
📜 引言
| Meta | Value |
|---|---|
| Title | BERT: Pre-training of deep bidirectional transformers for language understanding |
| Journal | arXiv (预印本) |
| Authors | Jacob Devlin; Ming-Wei Chang; Kenton Lee; Kristina Toutanova |
| PubDate | 2019 |
| DOI | http://arxiv.org/abs/1810.04805 |
| Label | NLP, BERT, Transformers, Pre-training, Bidirectional Representations, Question Answering, Language Inference |
自然语言理解(NLU)是人工智能领域的一个重要分支,它致力于使计算机能够理解和解释人类语言。近年来,预训练语言模型在多种NLP任务中取得了显著进展,但大多数模型依赖于单向上下文信息,限制了它们对语言的全面理解。尽管传统的循环神经网络(RNN)和长短期记忆网络(LSTM)在处理序列数据方面取得了一定的成功,但它们在处理长距离依赖关系和并行计算方面存在局限性。因此,迫切需要一种新的架构来克服这些挑战。
📑 Background
⚜ Proposal
- 为了解决这一问题,文章提出了BERT(Bidirectional Encoder Representations from Transformers)模型,这是一种基于Transformer架构的深度学习模型,通过利用Transformer的自注意力机制,首次实现了在所有层中同时考虑左右上下文信息,它通过在大规模文本语料库上进行预训练,学习到深度的双向语言表示,从而显著提高了模型对语言的理解能力。
- BERT模型的核心思想是利用无标签文本数据,通过预训练任务(如Masked Language Model和Next Sentence Prediction)来捕捉丰富的语言特征,然后通过微调来适应特定的NLP任务。
- 模型不仅学习了单词左侧的上下文信息,还学习了右侧的上下文信息。这种双向上下文理解使得BERT能够更准确地捕捉语言的细微差别和复杂性。此外,BERT的设计理念是简洁而强大的,它通过预训练和微调的过程,可以轻松适应多种自然语言处理任务,如情感分析、问答系统和语言推断等,而无需对模型架构进行重大修改。
👑 Contribution
BERT模型在多个NLP任务上取得了新的最先进结果,包括文本分类、问答和语言推断等。它不仅提高了模型的性能,还简化了模型的微调过程,减少了对任务特定架构修改的需求。此外,BERT的预训练策略为未来的NLP研究提供了新的方向。、
📊 研究方法
BERT模型的预训练包括两个主要任务:
Masked Language Model(MLM):MLM通过随机遮蔽输入中的单词并预测它们来训练模型Next Sentence Prediction(NSP):NSP则训练模型预测两个句子是否在原始文本中相邻。
预训练完成后,BERT可以通过添加少量的输出层进行微调,以适应各种不同的任务。
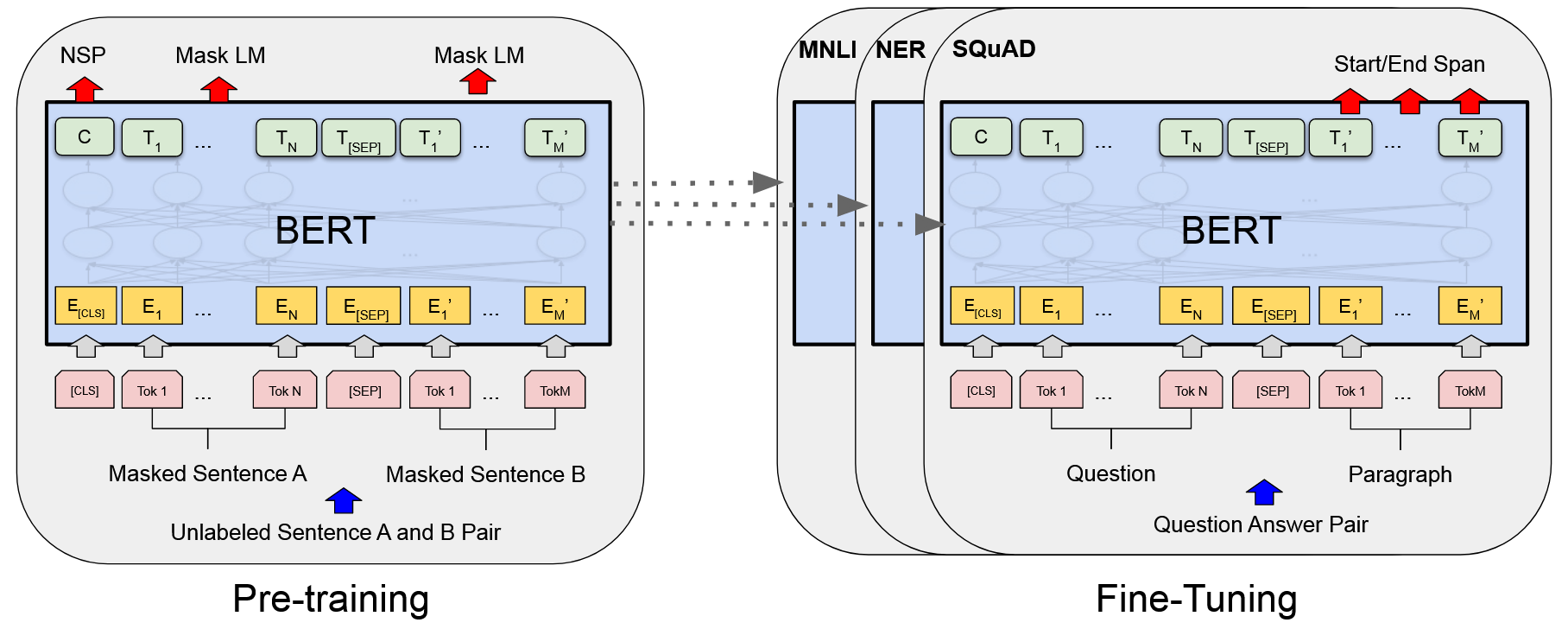
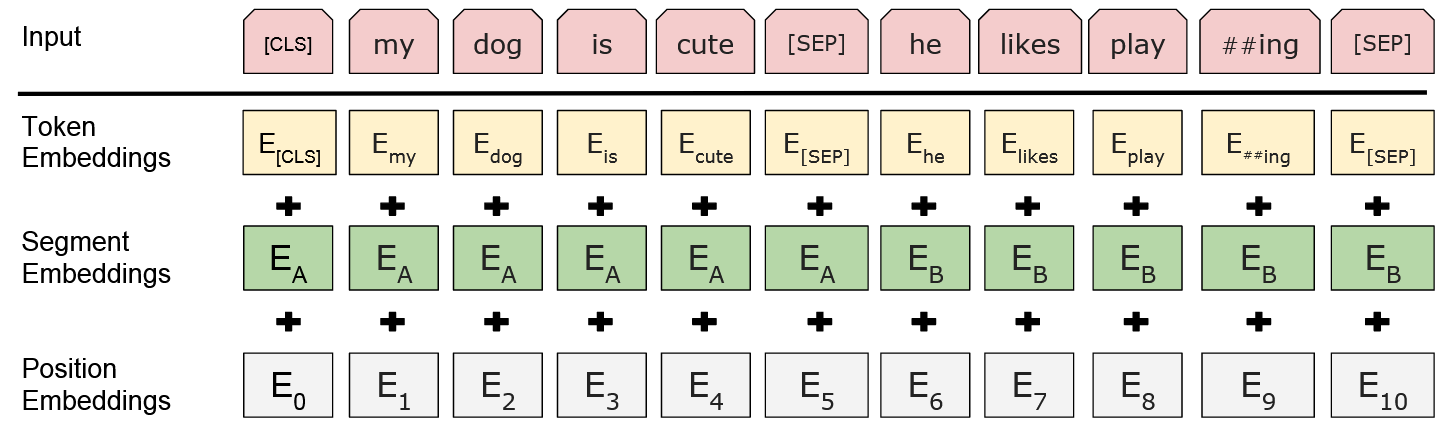
🔬 实验设计与结果
🚩 研究结论
BERT通过预训练深度双向表示,使得模型能够更好地理解上下文信息,从而在多项NLP任务上取得了新的最先进结果。此外,BERT的设计理念简单,使得它能够轻松适应各种不同的任务,而无需进行大量的架构修改。尽管存在一些潜在的局限性,如计算成本高和可能的偏见问题,但BERT无疑为未来的研究提供了一个强大的基础。
📌 创新点
- 双向上下文理解:BERT是首个在所有层中同时考虑左右上下文信息的预训练模型。
- 简化的微调过程:BERT模型可以通过添加少量的输出层进行微调,适应不同的任务,而无需对架构进行大量修改。
- 广泛的应用:BERT在多个NLP任务上取得了显著的性能提升,证明了其强大的泛化能力。
💡 感想 & 疑问
BERT模型是如何同时处理文本的左右上下文的,与传统的单向模型有何不同?
BERT模型使用Transformer架构,其中包括多个编码器层,每个编码器层都能够同时处理文本的左右上下文。这种架构使得BERT能够利用整个句子的信息来预训练模型,从而更好地理解句子中单词之间的关系。
相比传统的单向模型,如LSTM或GRU,BERT能够在预训练阶段同时考虑到文本中的双向信息,因此可以更好地捕捉文本中单词之间的关联性和语境。这种双向编码方式使得BERT在各种自然语言处理任务中表现出色,并成为当前最先进的预训练模型之一。
预训练任务中的掩码语言模型和下一句预测具体是如何操作的,它们对模型性能有何影响?
BERT模型在实际应用中的表现如何,是否存在一些特定场景下的性能瓶颈或局限性?
BERT模型的成功令人印象深刻,它不仅推动了NLP领域的发展,也为未来的研究提供了新的思路。然而,BERT模型的计算成本较高,对于资源有限的研究者和开发者来说,如何有效地降低预训练成本是一个值得探讨的问题。此外,BERT模型在处理多语言或特定领域文本时的表现如何,以及是否有可能进一步优化预训练任务以提高模型的适应性和性能,也是值得进一步研究的问题。