Explainability for large language models A survey
本文最后更新于:2 个月前
1 📕 Meta Data
Title | Explainability for large language models: A survey |
|---|---|
Journal | |
Authors | Haiyan Zhao;Hanjie Chen;Fan Yang;Ninghao Liu;Huiqi Deng;Hengyi Cai;Shuaiqiang Wang;Dawei Yin;Mengnan Du |
Pub. date | 2023-11-28 |
DOI |
2 📜 背景 & 目的 & 贡献
2.1 📑 Background
“大型语言模型 (LLM) 在自然语言处理方面表现出了令人印象深刻的能力。然而,它们的内部机制仍然不明确,这种缺乏透明度给下游应用带来了不必要的风险。因此,理解和解释这些模型对于阐明它们的行为、局限性和社会影响至关重要”
2.2 👑Contribution
- “介绍了可解释性技术的分类法(“传统的基于微调的范式和基于提示的范式”),并提供了解释基于 Transformer 的语言模型的方法的结构化概述”
- “总结了生成单个预测的局部解释和整体模型知识的全局解释的目标和主要方法”
- “讨论了用于评估生成的解释的指标”和“如何利用解释来调试模型和提高性能”
- “研究了 LLM 时代解释技术的主要挑战和新机遇。”
3 📊 研究方法
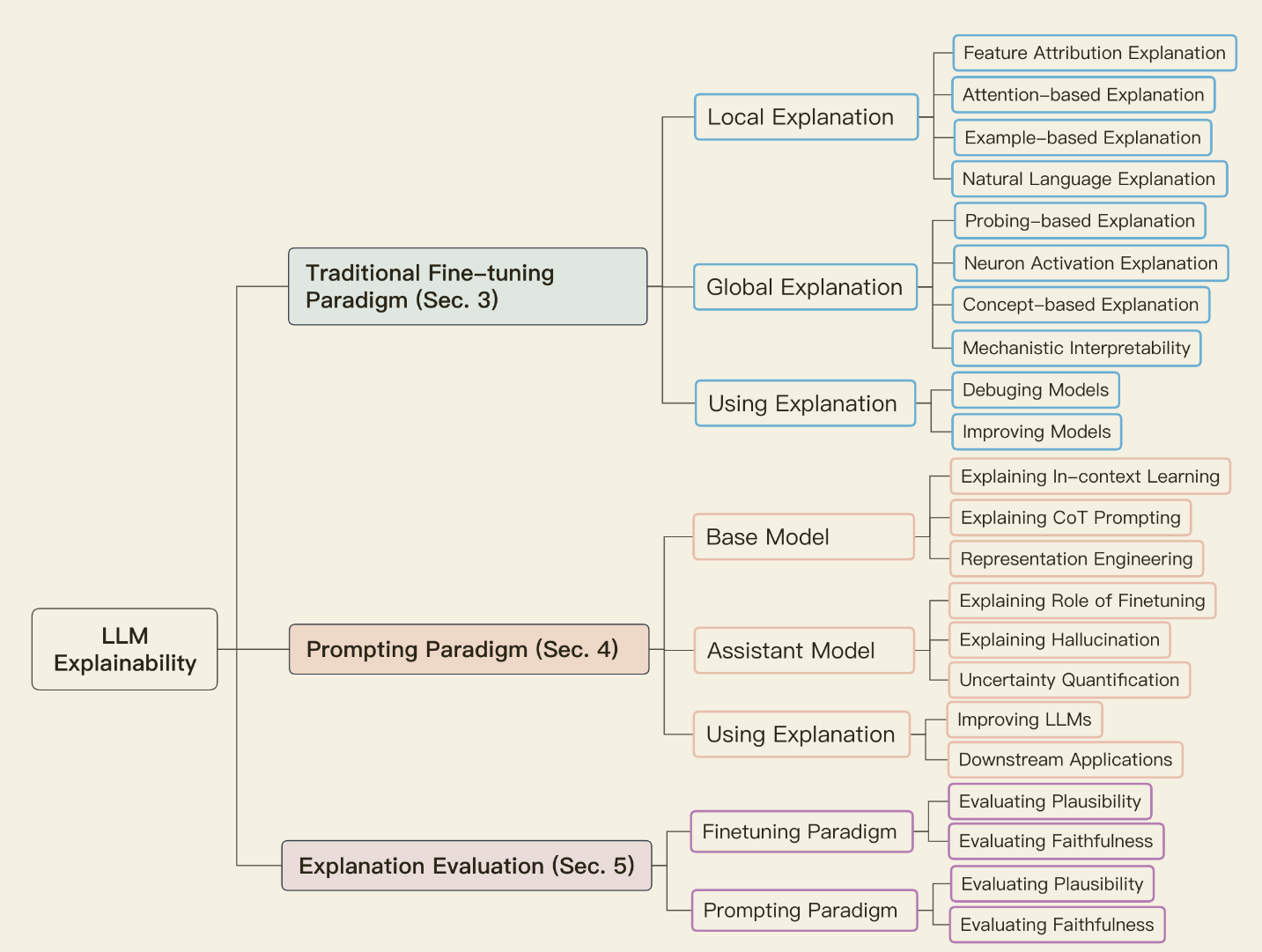
我们将 LLM 的可解释性分为两种主要范式。基于这种分类,我们总结了与这两种范式相关的 LLM 的不同可解释性技术。我们还讨论了在这两种范式下生成的解释的评估。
3.1 传统微调范式
首先在大量未标记文本数据的语料库上对语言模型进行预训练,然后在 GLUE 基准测试上对来自特定下游域的一组标记数据(例如 SST-2、MNLI 和 QQP)进行微调(Wang 等人,2019 年)。
可解释性研究焦点:
- 了解自监督预训练如何使模型获得对语言的基本理解.
- 分析微调过程如何使这些预训练模型具备有效解决下游任务的能力.
3.1.1 局部解释
本地解释旨在提供对语言模型如何对特定输入实例进行预测的理解
这一类包括生成解释的四种主要方法,包括基于特征归因的解释、基于注意力的解释、基于示例的解释和自然语言解释
3.1.2 全局解释
全局解释旨在提供对 LLM 整体运作方式的广泛理解。
与旨在解释模型的个体预测的局部解释不同,全局解释提供了对语言模型内部运作的见解。全局解释旨在理解各个组件(神经元、隐藏层和更大的模块)编码的内容并解释各个组件学到的知识/语言属性。我们研究了 9 种全局解释的三种主要方法:分析模型表示和参数的探测方法、确定模型对输入的响应性的神经元激活分析以及基于概念的方法和机制可解释性。
3.1.3 局限
随着语言模型规模的扩大,基于提示的模型表现出新兴的能力,需要新的视角来阐明其潜在机制。然而,模型规模的急剧激增使得传统的解释方法不再适用。例如,基于提示的模型依赖于推理能力(Wei et al., 2023b),这使得本地化或特定示例的解释意义不大。此外,在数千亿个或更多参数的规模上,计算要求较高的解释技术很快变得不可行。此外,基于提示的模型复杂的内部运作和推理过程过于复杂,无法通过简化的代理模型有效捕获。
3.2 提示范式
提示范式涉及使用提示(例如带有空格的自然语言句子供模型填充)来实现零样本或少样本学习,而无需额外的训练数据
两种类型:
- 基本模型:其中一种能力是通过提示进行小样本学习。这种类型适合参数超过十亿的大模型(
GPT3、OPT、LLaMA-1&2、Falcon),无需额外的人类偏好对齐。
可解释性焦点:了解模型如何学习利用其预先训练的知识来响应提示。
存在问题:(1)他们无法遵循用户指令,因为训练前数据包含的指令响应示例很少,并且 (2) 它们往往会产生有偏见和有毒的内容。 - 辅助模型:通过监督微调进一步对基础模型进行微调,以实现人类水平的能力,例如开放域对话。关键思想是使模型的响应与人类的反馈和偏好保持一致。
典型方法:通过(提示、响应)演示对和来自人类反馈的强化学习 (RLHF) 进行指令调整。模型通过自然语言反馈执行复杂多轮对话。(GPT3.5&4、Claude、LLaMA-2-Chat、Alpaca、Vicuna)
可解释性焦点:了解模型如何从对话中学习开放式交互行为。

3.2.1 方法
- 思想链(CoT)解释
- 传统微调范式的全局解释技术(基于概念的解释和基于模块的解释)
3.2.2 基本模型的可解释性
研究目的:
- 了解这些大型语言模型如何从有限的示例中快速掌握新任务,这有助于最终用户解释模型的推理
- 解释 CoT 提示和表示工程
研究方法:
- 情景学习的可解释性
- CoT 提示的可解释性
- 表示工程
3.2.3 辅助模型的可解释性
研究目的:
1)阐明对齐微调的作用
2)分析幻觉的原因
3)不确定性量化
研究方法:
微调作用的可解释性
总的来说,这些研究强调了基础模型的重要作用,强调了预训练的重要性。研究结果表明,助理模型的知识主要是在预训练阶段获取的。随后的指令微调有助于激活这些知识,为最终用户提供有用的输出。此外,强化学习可以进一步使模型与人类价值观保持一致。
幻觉的可解释性
产生原因: 1)缺乏相关数据,2) 重复数据。
解决方法:1)扩大语料库规模,提高模型参数 2)使用更高质量的数据集
缓解措施可以通过数据侧实施,例如改进微调数据集并添加合成数据干预(Wⅰ等人,2023a),也可以在模型侧实施,例如不同的优化方法。
不确定性量化
逻辑量化和非逻辑量化(基于一致性的不确定性估计)
3.3 可解释性评估
反映模型的推理过程仍然是一个挑战。我们将评估大致分为两类:传统微调范式的局部解释评估和提示范式的自然语言 CoT 解释评估
评估指标:合理性和忠诚度
3.4 面临的挑战
没有基本事实的解释
LLM 的基本事实解释通常是难以获得的。例如,目前没有基准数据集来评估 LLM 捕获的各个组件的全局解释。这提出了两个主要挑战。首先,很难设计准确反映 LLM 决策过程的解释算法。其次,缺乏基本事实使得评估解释的可信度和保真度变得困难。新兴能力的来源
哪些具体的模型架构赋予了法学硕士令人印象深刻的新兴能力? 在不同的语言任务中实现强大性能所需的最低模型复杂性和规模是多少?两种范式对比
下游微调范式和提示范式可以表现出明显不同的分布内和分布外(OOD)性能。这表明这两种方法依赖于不同的推理来进行预测。然而,微调和提示之间的解释仍然缺乏全面的比较。需要进一步的研究来更好地阐明这些范式之间的解释性差异。捷径学习
对于两种范式语言模型在进行预测时经常采取捷径,对于首尾信息的推理性能较中间信息更好。
4 总结
[!TIP]
大语言模型的可解释性研究目前主要聚焦在传统微调范式和提示范式上。而传统微调范式并不适用于规模激增的新兴模型,存在计算复杂度高、无法通过简化的代理模型有效捕获等问题;尽管提示范式中例如 CoT 和基于概念的解释等方法让模型具备了一定的可解释性能力,但是由于提示样例过少大规模语料库中缺乏指令响应示例,因此模型推理过程并不一定严格遵循提示模板,仍会导致输出结果的不可靠,鲁棒性差等问题。此外,大语言模型解释通常缺乏基础事实,这使得评估解释的真实性和可信度也成了一个问题。