Spring Cloud Alibaba 微服务原理与实战-阅读心得
本文最后更新于:2 个月前

第一章、微服务发展史
单体架构到分布式架构的演变
单体架构
通常来说,如果一个 war 包或者 jar 包里面包含一个应用的所有功能,则我们称这种架构为单体架构。
集群及垂直化
单体架构的局限:
- 用户量越来越大,网站的访问量不断增大,导致后端服务器的负载越来越高。
- 用户量大了,产品需要满足不同用户的需求来留住用户,使得业务场景越来越多并且越来越复杂。
优化方法:
- 通过横向增加服务器,把单台机器变成多台机器的集群。
- 按照业务的垂直领域进行拆分,减少业务的耦合度,以及降低单个 war 包带来的伸缩性困难问题。
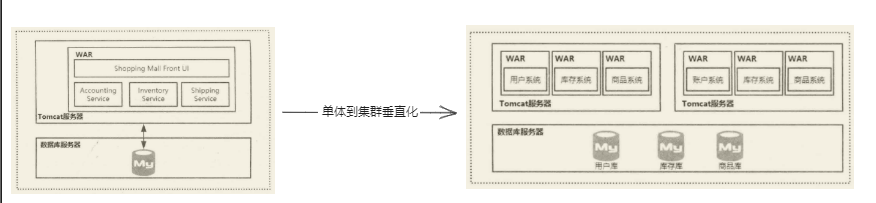
总的来说,数据库层面的拆分思想和业务系统的拆分思想是一样的,都是采用==分而治之==的思想。
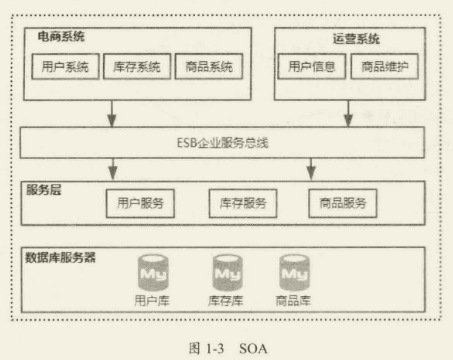
SOA
共享业务在多个场景中存在冗余维护困难,就引入了 SOA(Service-Oriented Architecture),也就是面向服务的架构,从语义上说,它和面向过程、面向对象、面向组件的思想是一样的,都是一种软件组建及开发的方式。核心目标是把一些通用的、会被多个上层服务调用的共享业务提取成独立的基础服务,这些被提取出来的共享服务相对来说比较独立,并且可以重用。所以在 SOA 中,服务是最核心的抽象手段,业务被划分为一些粗粒度的业务服务和业务流程。
解决问题:
- 信息孤岛
- 共享业务的重用
微服务架构
SOA 和微服务的关注点不同,区别如下所示:
- SOA 关注的是服务的重用性及解决信息孤岛问题。
- 微服务关注的是解耦,虽然解耦和可重用性从特定的角度来看是一样的,但本质上是有区别的,解耦是降低业务之间的耦合度,而重用性关注的是服务的复用。
- 微服务会更多地关注在 DevOps 的持续交付上,因为服务粒度细化之后使得开发运维变得更加重要,因此微服务与容器化技术的结合更加紧密。
实际上,微服务到底要拆分到多大的粒度没有统一的标准,更多的时候是需要在粒度和团队之间找平衡的,微服务的粒度越小,服务独立性带来的好处就越多,但是管理大量的微服务也会越复杂。
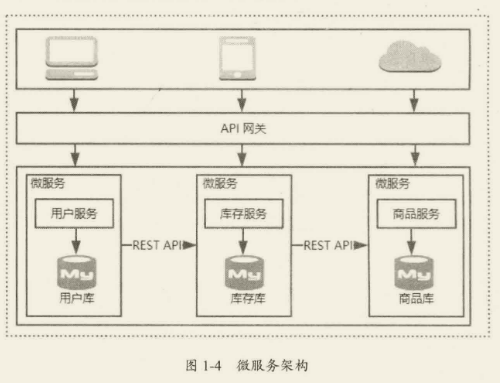
微服务架构带来的挑战
微服务架构的优点
- 复杂度可控:通过对共享业务服务更细粒度的拆分,一个服务只需要关注一个特定的业务领域,并通过定义良好的接口清晰表述服务边界。由于体积小、复杂度低,开发、维护会更加简单。
- 技术选型更灵活:每个微服务都由不同的团队来维护,所以可以结合业务特性自由选择技术栈。
- 可扩展性更强:可以根据每个微服务的性能要求和业务特点来对服务进行灵活扩展,比如通过增加单个服务的集群规模,提升部署了该服务的节点的硬件配置。
- 独立部署:由于每个微服务都是一个独立运行的进程,所以可以实现独立部署。当某个微服务发生变更时不需要重新编译部署整个应用,并且单个微服务的代码量比较小,使得发布更加高效。
- 容错性:在微服务架构中,如果某一个服务发生故障,我们可以使故障隔离在单个服务中。其他服务可以通过重试、降级等机制来实现应用层面的容错。
面临的挑战
- 故障排查:一次请求可能会经历多个不同的微服务的多次交互,交互的链路可能会比较长,每个微服务会产生自己的日志,在这种情况下如果出现一个故障,开发人员定位问题的根源会比较困难。
- 服务监控:在一个单体架构中很容易实现服务的监控,因为所有的功能都在一个服务中。在微服务架构中,服务监控开销会非常大,可以想象一下,在几百个微服务组成的架构中,我们不仅要对整个链路进行监控,还需要对每一个微服务都实现一套类似单体架构的监控。
- 分布式架构的复杂性:微服务本身构建的是一个分布式系统,分布式系统涉及服务之间的远程通信,而网络通信中网络的延迟和网络故障是无法避免的,从而增加了应用程序的复杂度。
- 服务依赖:微服务数量增加之后,各个服务之间会存在更多的依赖关系,使得系统整体更为复杂。假设你在完成一个案例,需要修改服务 A、B、C,而 A 依赖 B,B 依赖 C。在单体式应用中,你只需要改变相关模块,整合变化,再部署就好了。对比之下,微服务架构模式就需要考虑相关改变对不同服务的影响。比如,你需要更新服务 C,然后是 B,最后才是 A,幸运的是,许多改变一般只影响一个服务,需要协调多服务的改变很少。
- 运维成本:在微服务中,需要保证几百个微服务的正常运行,对于运维的挑战是巨大的比如单个服务流量激增时如何快速扩容、服务拆分之后导致故障点增多如何处理、如何快速部署和统一管理众多的服务等。
如何实现微服务架构
架构的本质是对系统进行有序化重构,使系统不断进化。在这个进化的过程中除了更好地支撑业务发展,也会带来非常多的挑战,譬如在前文中提到的微服务的挑战,为了解决这些问题就必须引入更多的技术,进而使得微服务架构的实现变得非常复杂。
微服务架构图
微服务架构图通常由多个服务组成,每个服务都是一个独立的单元,负责执行特定的业务功能。这些服务之间通过网络进行通信,并使用轻量级的传输协议(如 HTTP 或 RPC)进行交互。
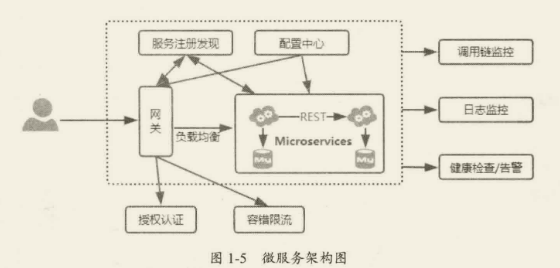
下面是一个简单的微服务架构图示例:
graph LR
A[网关] --> B[认证服务]
A --> C[用户服务]
A --> D[订单服务]
B --> E[数据库]
C --> E
D --> E
其中,网关(Gateway)是整个系统的入口,认证服务(Authentication Service)、用户服务(User Service)和订单服务(Order Service)是三个不同的微服务,它们之间通过网关进行通信。数据库(Database)用于存储数据,被认证服务、用户服务和订单服务共享。
微服务架构下的技术挑战
微服务架构主要的目的是实现业务服务的解耦。随着公司业务的高速发展,微服务组件会越来越多,导致服务与服务之间的调用关系越来越复杂。同时,服务与服务之间的远程通信也会因为网络通信问题的存在变得更加复杂,比如需要考虑重试、容错、降级等情况。那么这个时候就需要进行服务治理,将服务之间的依赖转化为服务对服务中心的依赖。除此之外,还需要考虑:
- ==分布式配置中心==。
- ==服务路由==。
- ==负载均衡==。
- ==熔断限流==。
- ==链路监控==。
第二章、微服务解决方案之 Spring Cloud
什么是 Spring Cloud
简单来说,Spring Cloud 提供了一些可以让开发者快速构建微服务应用的工具,比如配置管理、服务发现、熔断、智能路由等,这些服务可以在任何分布式环境下很好地工作。Spring Cloud 主要致力于解决如下问题:
- Distributed/versioned configuration,分布式及版化配置。
- Service registration and discovery,服务注册与发现。
- Routing,服务路由。
- Service-to-service calls,服务调用。
- Load balancing,负载均衡。
- Circuit Breakers,断路器。
- Global locks,全局锁。
- Leadership election and cluster state,Leader 选举及集群状态。
- Distributed messaging,分布式消息。
需要注意的是,Spring Cloud 并不是 Spring 团队全新研发的框架,它只是把一些比较优秀的解决微服务架构中常见问题的开源框架基于 Spring Cloud 规范进行了整合,通过 Spring Boot 这个框架进行再次封装后屏蔽掉了复杂的配置,给开发者提供良好的开箱即用的微服务开发体验。不难看出,Spring Cloud 其实就是一套规范,而 Spring Cloud Netflix、Spring Cloud Consul、Spring Cloud Alibaba 才是 Spring Cloud 规范的实现。
Spring Cloud Netflix
Spring Cloud Netflix 主要为微服务架构下的服务治理提供解决方案,包括以下组件:
- Eureka,服务注册与发现。
- Zuul,服务网关。(不在进行更新维护->Spring Cloud GateWay)
- Ribbon,负载均衡。(不在进行更新维护->Spring Cloud Loadbalancer)
- Feign,远程服务的客户端代理。
- Hystrix,断路器,提供服务熔断和限流功能。(不在进行更新维护->Resitience4j)
- Hystrix Dashboard,监控面板。(不在进行更新维护->Micrometer Monitoring System)
- Turbine,将各个服务实例上的 Hystrix 监控信息进行统一聚合。
Spring Cloud Alibaba
Spring Cloud Alibaba 主要为微服务开发提供一站式的解决方案,使开发者通过 Spring Cloud 编程模型轻松地解决微服务架构下的各类技术问题。以下是 Spring Cloud Alibaba 生态下的主要功能组件,这些组件包含开源组件和阿里云产品组件,云产品是需要付费使用的。
- Sentinel,流量控制和服务降级。
- Nacos,服务注册与发现。
- Nacos,分布式配置中心。
- RocketMO,消息驱动。
- Seate,分布式事务。
- Dubbo,RPC 通信。
- OSS,阿里云对象存储(收费的云服务)。
优势
相对于 Spring Cloud Netflix 来说,它的优势有很多,简单整理了以下两点:
- Alibaba 的开源组件在没有织入 Spring Cloud 生态之前,已经在各大公司广泛应用,所以集成到 Spring Cloud 生态使得开发者能够很轻松地实现技术整合及迁移。Dubbo 天然支持多协议,因此在迁移和改造过程中并没有投入太多的成本。
- Alibaba 的开源组件在服务治理上和处理高并发的能力上有天然的优势,相比 Spring CloudNetflix 来说,Spring Cloud Alibaba 在服务治理这块的能力更适合于国内的技术场景,同时,Spring Cloud Alibaba 在功能上不仅完全覆盖了 Spring Cloud Netflix 原生特性,而且还提供了更加稳定和成熟的实现,因此笔者很看好 Spring Cloud Alibaba 未来的发展。
组件对比
| 组件 | Spring Cloud | Spring Cloud Netflix | Spring Cloud Alibaba |
|---|---|---|---|
| 注册中心 | Service Registry Service Discovery |
Eureka 1.x Eureka 2.x(停止维护) |
Nacos |
| 配置中心 | Spring Cloud Config Git/ JDBC/ Vault… |
Archaius(停止维护) | Nacos |
| 服务容错 | Spring Cloud Circuit Breaker | Hystrix(停止维护) | Sentinel |
| 服务调用 | Spring Cloud OpenFeign RestTemplate |
Feign | Dubbo |
| 负载均衡 | Spring Cloud LoadBalancer | Ribbon(停止维护) | Dubbo |
| 服务网关 | Spring Cloud Gateway | Zuul(停止维护) | Dubbo |
| 消息队列 | Spring Cloud Stream RabbitMQ/ Kafka |
RocketMQ | |
| 链路追踪 | Spring Cloud Sleuth | ||
| 分布式事务 | Seata |
第三章、Spring Cloud 的核心之 Spring Boot
简单来说,Spring Boot 是帮助开发者快速构建一个基于 Spring Framework 及 Spring 生态体系的应用解决方案,也是 Spring Framework 对于“约定优于配置(Convention over Configuration)”理念的最佳实践。
重新认识 SpringBoot
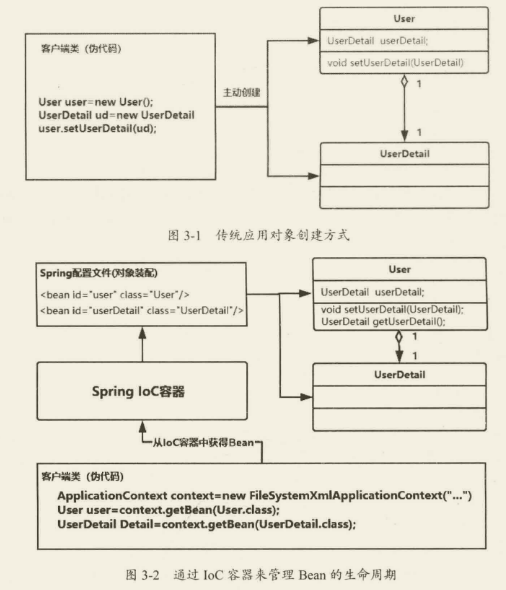
Spring IoC/DI
IoC(Inversion of Control)和 DI(Dependency Injection)的全称分别是控制反转和依赖注入。
IoC
IoC(控制反转)实际上就是把对象的生命周期托管到 Spig 容器中,而反转是指对象的获取方式被反转了,直接从 IoC 容器中获取对象而不需要 new 一个对象。
DI
DI(Dependency Inject),也就是依赖注入,简单理解就是 IoC 容器在运行期间,动态地把某
种依赖关系注入组件中。
只需要在 Spring 的配置文件中描述 Bean 之间的依赖关系,IoC 容器在解析该配置文件的时候,会根据 Ban 的依赖关系进行注入,这个过程就是依赖注入。
xml 配置 bean 和依赖关系
1 | |
依赖自动注入到 bean 对象,直接获取 bean 实例
1 | |
实现依赖注入的方法有三种,分别是接口注入、构造方法注入和 setter 方法注入。不过现在基本上都基于注解的方式来描述 Bean 之间的依赖关系,比如
@Autowired、@Inject和@Resource。
Bean 装配方式的升级
随着 JDK1.5 带来的注解支持,Spring 从 2.x 开始,可以使用注解的方式来对 Bean 进行声明和注入,大大减少了 XML 的配置量。
Spring 升级到 3.x 后,提供了 JavaConfig 的能力,它可以完全取代 XML,通过 Java 代码的方式来完成 Bean 的注入。所以,现在我们使用的 Spring Framework 或者 Spring Boot,已经看不到 XML 配置的存在了。
注解配置
基于 JavaConfig 的配置形式,可以通过@Bean 注解来将一个对象注入 IoC 容器中,默认情况下采用方法名称作为该 Bean 的 id。
1 | |
依赖注入
在 JavaConfig 中,可以这样来表述:
1 | |
其他常见配置
@ComponentScan对应 XML 形式的<context:component-scan base-package-=""/>,它会扫描指定包路径下带有@Service、@Repository、@Controller、@Component等注解的类,将这些类装载到 IoC 容器。@Import对应 XML 形式的<import resource=""/>,导入其他的配置文件。
虽然通过注解的方式来装配 Bean,可以在一定程度上减少 XML 配置带来的问题,从某一方面来说它只是换汤不换药,本质问题仍然没有解决,比如:
- 依赖过多。Spring 可以整合几乎所有常用的技术框架,比如 JSON、MyBatis、Redis、Log 等,不同依赖包的版本很容易导致版本兼容的问题。
- 配置太多。以 Spring 使用 JavaConfig 方式整合 MyBatis 为例,需要配置注解驱动、配置数据源、配置 MyBatis、配置事物管理器等,这些只是集成一个技术组件需要的基础配置,在一个项目中这类配置很多,开发者需要做很多类似的重复工作。
- 运行和部署很烦琐。需要先把项目打包,再部署到容器上。
如何让开发者不再需要关注这些问题,而专注于业务呢?好在,Spring Boot 诞生了。
Spring Boot 的价值
如何理解约定优于配置
约定优于配置(Convention Over Configuration)是一种软件设计范式,目的在于减少配置的数量或者降低理解难度,从而提升开发效率。
在 Spring Boot 中,约定优于配置的思想主要体现在以下方面(包括但不限于):
- Maven 目录结构的约定。
- Spring Boot 默认的配置文件及配置文件中配置属性的约定。
- 对于 Spring MVC 的依赖,自动依赖内置的 Tomcat 容器。
- 对于 Starter 组件自动完成装配。
Spring Boot 的核心
Spring Boot 是基于 Spring Framework 体系来构建的,所以它并没有什么新的东西,但是要想学好 Spring Boot,必须知道它的核心:
- Starter 组件,提供开箱即用的组件。
- 自动装配,自动根据上下文完成 Bean 的装配。
- Actuator,Spring Boot 应用的监控。
- Spring Boot CLI,基于命令行工具快速构建 Spring Boot 应用。
其中,最核心的部分应该是自动装配,Starter 组件的核心部分也是基于自动装配来实现的。
快速构建 SpringBoot 应用
构建 Spring Boot 应用的方式有很多,比如在 https:/start.spring.io 或者 https://start.aliyun.com/ 网站上可以通过图形界面来完成创建。如果大家使用 IntelliJ IDEA 这个开发工具,就可以直接在这个工具上来创建 Spring Boot 项目,默认也是使用 https:/start.spring.io 来构建的。
构建完成后会包含以下核心配置和类。
- Spring Boot 的启动类 SpringBootDemoApplication:
1 | |
- resource 目录,包含 static 和 templates 目录,分别存放静态资源及前端模板,以及 application.properties 配置文件。
- Web 项目的 starter 依赖包:
1
2
3
4<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
在不做任何改动的情况下,可以直接运行 SpringBootDemoApplication 中的 main 方法来启动 Spring Boot 项目。当然,由于默认情况下没有任何 URI 映射,所以看不出效果,我们可以增加一个 Controller 来发布 Restful 接口,代码如下:
1 | |
当我们运行主类的 main 方法后,Spring Boot 会自动扫描并加载所有带有@Controller 或@RestController 注解的类,并根据其注解配置创建相应的 Bean。此时,我们可以通过访问 http://localhost:8080/hello 来调用刚刚定义的接口,返回结果为”Hello World!”。
:LiQuote: 以往我们使用 Spring MVC 来构建一个 Web 项目需要很多基础操作:添加很多的 Jar 包依赖、在 web.xml 中配置控制器、配置 Spring 的 XML 文件或者 JavaConfig 等。而 Spring Boot 帮开发者省略了这些烦琐的基础性工作,使得开发者只需要关注业务本身,基础性的装配工作是由 Starter 组件及自动装配来完成的。
SpringBoot 自动装配原理
简单来说,就是自动将 Bean 装配到 IoC 容器中,接下来,我们通过一个 Spring Boot 整合 Redis 的例子来了解一下自动装配。
添加 Starter 依赖:
1
2
3
4<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>在 application.properties 中配置 Redis 的数据源:
1
2
3
4spring:
redis:
host: localhost
port: 6379在 HelloController 中使用 RedisTemplate 实现 Redis 的操作:
1
2
3
4
5
6
7
8
9
10@RestController
public class HelloController{
@Autowired
RedisTemplate<String,String> redisTemplate;
@GetMapping("/hello")
public String hello(){
redisTemplate.opsForValue().set("key","value");
return "Hello World";
}
}
在这个案例中,我们并没有通过 XML 形式或者注解形式把 RedisTemplate 注入 IoC 容器中,但是在 HelloController 中却可以直接使用@Autowired 来注入 redisTemplate 实例,这就说明,IoC 容器中已经存在 RedisTemplate,这就是 Spring Boot 的自动装配机制。
在往下探究其原理前,可以大胆猜测一下,如何只添加一个 Starter 依赖,就能完成该依赖组件相关 Bean 的自动注入?不难猜出,这个机制的实现一定基于某种约定或者规范,只要 Starter 组件符合 Spring Boot 中自动装配约定的规范,就能实现自动装配。
自动装配的实现
自动装配在 Spring Boot 中是通过 @EnableAutoConfiguration 注解来开启的,这个注解的声明在启动类注解@SpringBootApplication 内。
进入@SpringBootApplication 注解,可以看到@EnableAutoConfiguration 注解的声明。
1 | |
- @Target({ElementType.TYPE}):指定该注解可以放置在类上。
- @Retention(RetentionPolicy.RUNTIME):指定该注解的保留策略为运行时,即在编译后仍然存在。
- @Documented:指示被注解的元素应该在 API 文档中被记录。
- @Inherited:指示此注解类型是继承性的,即如果将其放置在父类上,则子类上可以省略该注解。
- @SpringBootConfiguration:指示该类是一个 Spring Boot 配置类。
- @EnableAutoConfiguration:启用自动配置功能,根据已导入的依赖和应用程序的代码来自动配置 Spring 应用程序。
- @ComponentScan:指定要扫描的组件包,以发现和注册 Bean 定义。
- excludeFilters:指定要排除的过滤器。
- @Filter:自定义过滤器。
- type = FilterType.CUSTOM:指定过滤器类型为自定义。
- classes={TypeExcludeFilter.class}:指定过滤器所实现的类为 TypeExcludeFilter。
- @Filter:自定义过滤器。
- type = FilterType.CUSTOM:指定过滤器类型为自定义。
- classes = {AutoConfigurationExcludeFilter.class}:指定过滤器所实现的类为 AutoConfigurationExcludeFilter。
这里简单和大家讲解一下@Enable 注解。其实 Spring3.I 版本就己经支持@Enable 注解了,它的主要作用把相关组件的 Bean 装配到 IoC 容器中。@Enable 注解对 JavaConfig 的进一步完善,为使用 Spring Framework 的开发者减少了配置代码量,降低了使用的难度。比如常见的@Enable 注解有@EnableWebMvc、@EnableScheduling 等。
在前面的章节中讲过,如果基于 JavaConfig 的形式来完成 Bean 的装载,则必须要使用@Configuration 注解及@Bean 注解。而@Enable 本质上就是针对这两个注解的封装,所以大家如果仔细关注过这些注解,就不难发现这些注解中都会携带一个@Import 注解,比如:
1 | |
EnableAutoConfiguration
进入@EnableAutoConfiguration 注解里,可以看到除@Import 注解之外,还多了一个 @AutoConfigurationPackage 注解(它的作用是把使用了该注解的类所在的包及子包下所有组件扫描到 Spring IoC 容器中)。并且,@Import 注解中导入的并不是一个 Configuration 的配置类,而是一个 AutoConfigurationImportSelector 类。从这一点来看,它就和其他的@Enable 注解有很大的不同。
1 | |
不过,不管 AutoConfigurationlmportSelector 是什么,它一定会实现配置类的导入,至于导入的方式和普通的 @Configuration 有什么区别,这就是我们需要去分析的。
AutoConfigurationlmportSelector
AutoConfigurationlmportSelector 实现了 ImportSelector,它只有一个 selectImports 抽象方法,并且返回一个 String 数组,在这个数组中可以指定需要装配到 IoC 容器的类,当在@Import 中导入一个 ImportSelector 的实现类之后,会把该实现类中返回的 Class 名称都装载到 IoC 容器中。
1 | |
和@Configuration 不同的是,ImportSelector 可以实现批量装配,并且还可以通过逻辑处理来实现 Bean 的选择性装配,也就是可以根据上下文来决定哪些类能够被 IoC 容器初始化。接下来通过一个简单的例子带大家了解 ImportSelector 的使用。
首先创建两个类,我们需要把这两个类装配到 IoC 容器中。
1
2public class Firstclass{}
public class Secondclass{}创建一个 ImportSelector 的实现类,在实现类中把定义的两个 Bean 加入 String 数组,这意味着这两个 Bean 会装配到 loC 容器中。
1
2
3
4
5
6public class GpImportSelector implements ImportSelector {
@Override
public String[] selectImports(AnnotationMetadata importingClassMetadata){
return new String[]{Firstclass.class.getName(), Secondclass.class.getName()};
}
}为了模拟 EnableAutoConfiguration,我们可以自定义一个类似的注解,通过@Import 导入 GpImportSelector。
1 | |
创建一个启动类,在启动类上使用@EnableAutolmport 注解后,即可通过 ca.getBean 从 IoC 容器中得到 FirstClass 对象实例。
1
2
3
4
5
6
7
8
9
10
11@SpringBootApplication
@EnableAutoImport
public class MySpringAutoConfigurationApplication {
public static void main(String[] args) {
ConfigurableApplicationContext cac = SpringApplication.run(MySpringAutoConfigurationApplication.class, args);
System.out.println(cac.getBean(Firstclass.class));
System.out.println(cac.getBean(Firstclass.class));
}
}这种实现方式相比
@Import(*Configuration.class)的好处在于装配的灵活性,还可以实现批量比如 GpImportSelector 还可以直接在 String 数组中定义多个 Configuration 类,由于一个配置类表的是某一个技术组件中批量的 Bean 声明,所以在自动装配这个过程中只需要扫描到指定路径下对应的配置类即可。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15public class GpImportSelector implements ImportSelector {
@Override
public String[] selectImports(AnnotationMetadata importingClassMetadata) {
return new String[]{FirstConfiguration.class.getName(), SecondConfiguration.class.getName()};
}
}
//测试bean自动装配
ConfigurableApplicationContext cac = SpringApplication.run(MySpringAutoConfigurationApplication.class, args);
System.out.println(cac.getBean("firstclass"));
System.out.println(cac.getBean(Firstclass.class));
System.out.println(FirstConfiguration.class.getName());
//输出结果
com.fcs.entity.Firstclass@1c32386d
com.fcs.entity.Firstclass@1c32386d
com.fcs.config.FirstConfiguration
自动装配原理分析
自动装配的核心是扫描约定目录下的文件进行解析,解析完成之后把得到的 Configuration 配置类通过 ImportSelector 进行导入,从而完成 Bean 的自动装配过程。
定位到 AutoConfigurationImportSelector 中的 selectImports 方法,它是 ImportSelector 接口的实现,这个方法中主要有两个功能:
- AutoConfigurationMetadataLoader.loadMetadata 从 META-INF/spring-autoconfigure-metadata.properties 中加载自动装配的条件元数据,简单来说就是只有满足条件的 Bean 才能够进行装配。
- 收集所有符合条件的配置类 autoConfigurationEntry.getConfigurations(),完成自动装配。
1 | |
需要注意的是,在 AutoConfigurationImportSelector 中不执行 selectImports 方法,而是通过 ConfigurationClassPostProcessor 中的 processConfigBeanDefinitions 方法来扫描和注册所有配置类的 Bean,最终还是会调用 getAutoConfigurationEntry 方法获得所有需要自动装配的配置类。这个方法应该会扫描指定路径下的文件解析得到需要装配的配置类,而这里面用到了 SpringFactoriesLoader,它要做几件事情如下:
- getAttributes 获得@EnableAutoConfiguration 注解中的属性 exclude、excludeName 等。
- getCandidateConfigurations 获得所有自动装配的配置类,后续会重点分析。
- removeDuplicates 去除重复的配置项。
- getExclusions 根据@EnableAutoConfiguration 注解中配置的 exclude 等属性,把不需要自动装配的配置类移除。
- fireAutoConfigurationlmportEvents 广播事件。
- 最后返回经过多层判断和过滤之后的配置类集合。
1 | |
总的来说,它先获得所有的配置类,通过去重、exclude 排除等操作,得到最终需要实现自动装配的配置类。这里需要重点关注的是 getCandidateConfigurations,它是获得配置类最核心的方法。
1 | |
SpringFactoriesLoader 是 Spring 内部提供的一种约定俗成的加载方式,类似于 Java 中的 SPI。简单来说,它会扫描 classpath 下的 META-INF/spring.factories 文件,spring.factories 文件中的数据以 Key-Value 形式存储,而 SpringFactoriesLoader.loadFactoryNames 会根据 Key 得到对应的 value 值。因此,在这个场景中,Kcy 对应为 EnableAutoConfiguration,Value 是多个配置类,也就是 getCandidateConfigurations 方法所返回的值。
打开 RabbitAutoConfiguration,可以看到,它就是一个基于 JavaConfig 形式的配置类。
1 | |
除了基本的@Configuration 注解,还有一个@ConditionalOnClass 注解,这个条件控制机制在这里的用途是,判断 classpath 下是否存在 RabbitTemplate 和 Channel 这两个类,如果是,则把当前配置类注册到 IoC 容器。另外,@EnableConfigurationProperties 是属性配置,也就是说我们可以按照约定在 application.properties 中配置 RabbitMQ 的参数,而这些配置会加载到 RabbitProperties 中。实际上,这些东西都是 Spring 本身就有的功能。
自动装配的原理的核心过程:
- 通过@Import(AutoConfigurationlmportSelector)实现配置类的导入,但是这里并不是传统意义上的单个配置类装配。
- AutoConfigurationlmportSelector 类实现了 ImportSelector 接口,重写了方法 selectlmports,它用于实现选择性批量配置类的装配。
- 通过 Spring 提供的 SpringFactoriesLoader 机制,扫描 classpath 路径下的 META-NF/spring,factories,读取需要实现自动装配的配置类。
- 通过条件筛选的方式,把不符合条件的配置类移除,最终完成自动装配。
@Conditional 条件装配
@Conditional 是 Spring Framework 提供的一个核心注解,这个注解的作用是提供自动装配的
条件约束,一般与@Configuration 和@Bean 配合使用。
简单来说,Spring 在解析@Configuration 配置类时,如果该配置类增加了@Conditional 注解,
那么会根据该注解配置的条件来决定是否要实现 Bean 的装配。
@Conditional 的使用
@Conditional 的注解类声明代码如下,该注解可以接收一个 Condition 的数组。
1 | |
Condition 是一个函数式接口,提供了 matches 方法,它主要提供一个条件匹配规则,返回 true 表示可以注入 Bean,反之则不注入。
1 | |
自定义 Condition
自定义一个 Condition,逻辑很简单,如果当前操作系统是 Windows,,则返回 true,否则返回 false。
1 | |
1 | |
1 | |
在 Windows 环境中运行,将会输出 Firstclass 这个对象实例。在 Linux 环境中,会出现如下错误:
以上就是@Conditional 注解的使用方法,为 Bean 的装载提供了上下文的判断。
Spring Boot 中的 @Conditional
在 Spring Boot 中,针对@Conditional 做了扩展,提供了更简单的使用形式,扩展注解如下:
- ConditionalOnBean/ConditionalOnMissingBean:容器中存在某个类或者不存在某个 Bean 时进行 Bean 装载。
- ConditionalOnClass/ConditionalOnMissingClass:classpath 下存在指定类或者不存在指定类时进行 Bean 装载。
- ConditionalOnCloudPlatform:只有运行在指定的云平台上才加载指定的 Bcan。
- ConditionalOnExpression:基于 SpEl 表达式的条件判断。
- ConditionalOnJava:只有运行指定版本的 Java 才会加载 Bean。
- ConditionalOnJndi:只有指定的资源通过 JNDI 加载后才加载 Bean。
- ConditionalOn WebApplication/ConditionalOnNot WebApplication:如果是 Wcb 应用或者不是 Web 应用,才加载指定的 Bean。
- ConditionalOnProperty:系统中指定的对应的属性是否有对应的值。
- ConditionalOnResource:要加载的 Bcan 依赖指定资源是否存在于 classpath 中。
- ConditionalOnSingleCandidate:只有在确定了给定 Bean 类的单个候选项时才会加载 Bean.
这些注解只需要添加到 @Configuration 配置类的类级别或者方法级别,然后根据每个注解的作用来传参就行。下面演示几种注解类的使用。
@ConditionalOnProperty1
2
3
4@ConditionalOnProperty
@Configuration
@ConditionalOnProperty(value="gp.bean.enable",havingvalue="true",matchIfMissing=true)
public class ConditionConfig{}
在 application.properties 或 application.yml 文件中当 gp.bean.enable-true 时才会加载 ConditionConfig 这个 Bean,如果没有匹配上也会加载,因为 matchIfMissing=true,默认值是 false。
@ConditionalOnBean 和 @ConditionalOnMissingBean
1 | |
当 Spring IoC 容器中存在 GpBean 时,才会加载 ConditionConfig。
@ConditionalOnResource
1 | |
在 classpath 中如果存在 gp.properties,则会加载 ConditionConfig
这些条件配置在 Spring Boot 的自动装配配置类中出现的频率非常高,它能够很好地为自动装配提供上下文条件判断,来让 Spring 决定是否装载该配置类。
spring-autoconfigure-metadata
除了@Conditional 注解类,在 SpringBoot 中还提供了 spring-autoconfigure.properties 文件来实现批量自动装配条件配置。
它的作用和@Conditional 是一样的,只是将这些条件配置放在了配置文件中。下面这段配置来自 spring-boot-autoconfigure.jar 包中的/META-NF/spring-autoconfigure-.metadata.properties 文件。
同样,这种形式也是“约定优于配置”的体现,通过这种配置化的方式来实现条件过滤必须要遵循两个条件:
- 配置文件的路径和名称必须是
/META-INF/spring-autoconfigure-metadata.properties - 配置文件中 key 的配置格式:自动配置类的类全路径名.条件=值
这种配置方法的好处在于,它可以有效地降低 Spring Boot 的启动时间,通过这种过滤方式可
以减少配置类的加载数量,因为这个过滤发生在配置类的装载之前,所以它可以降低 Spring Boot 启动时装载 Bean 的耗时。
手写一个 Starter
从 Spring Boot 官方提供的 Starter 的作用来看,Starter 组件主要有三个功能:
- 涉及相关组件的 Jar 包依赖。
- 自动实现 Bean 的装配。
- 自动声明并且加载 application.properties 文件中的属性配置。
Starter 的命名规范
Starter 的命名主要分为两类,一类是官方命名,另一类是自定义组件命名。这种命名格式并
不是强制性的,也是一种约定俗成的方式,可以让开发者更容易识别。
。官方命名的格式为:spring-boot-starter-模块名称,比如 spring-boot-starter-web。
。自定义命名格式为:模块名称-spring-boot-starter,比如 mybatis-spring-boot-starter。
简单来说,官方命名中模块名放在最后,而自定义组件中模块名放在最前面。
实现基于 Redis 的 Starter
我们可以基于前面学到的思想实现一个基于 Redis 简化版本的 Starter 组件。
- 创建一个工程,命名为:
redis-spring-boot-starter。 - 添加 Jar 包依赖,Redisson 提供了在 Java 中操作 Redis 的功能,并且基于 Redis 的特性封装了很多可直接使用的场景,比如分布式锁。
1 | |
- 定义属性类,实现在 application.properties 中配置 Redis 的连接参数,由于只是一个简单版
本的 Demo,所以只简单定义了一些必要参数。另外@ConfigurationProperties这个注解的
作用是把当前类中的属性和配置文件(properties/yml)中的配置进行绑定,并且前缀是 fcs.redisson。
1 | |
- 定义需要自动装配的配置类,主要就是把 RedissonClient 装配到 IoC 容器,值得注意的是
@ConditionalOnClass,它表示一个条件,在当前场景中表示的是:在 classpath 下存在 Redisson 这个类的时候,RedissonAutoConfiguration 才会实现自动装配。另外,这里只演示了一种单机的配置模式,除此之外,Redisson 还支持集群、主从、哨兵等模式的配置,有兴趣的话可以基于当前案例去扩展,建议使用 config.fromYAML 方式,直接加载配置完成不同模式的初始化,这会比根据不同模式的判断来实现配置化的方式更加简单。
1 | |
- 在 resources 下创建META-INF/spring.factories文件,使得 Spring Boot 程序可以扫描到该文件完成自动装配,key 和 value 对应如下:
1 | |
- 最后一步,使用阶段只需要做两个步骤:添加 Starter 依赖、设置属性配置:
1 | |
在 application.yml 中配置相应属性,这个属性会自动绑定到 RedissonProperties 中定义的属性上。
1 | |
- 编写测试方法测试自己实现的 redisson 是否可用:
1 | |

成功设置并获取到 test 键的值为 “123456”
小结
本章主要分析了 Spring Boot 中的自动装配的基本原理,并且通过实现一个自定义 Starter 的方式加深了我们对于自动装配的理解。由于 Spring Cloud 生态中的组件,都是基于 Spring Boot 框架来实现的,了解 Spring Boot 的基本原理将有助于大家对后续内容的理解,工欲善其事必先利其器,读者我感悟到,比了解技术的基本使用方法更重要的是了解技术产生的背景及核心原理。
第四章、微服务架构下的服务治理
Dubbo 的产生就是为了解决以下问题:
- 如何协调线上运行的服务,以及保障服务的高可用性。
- 如何根据不同服务的访问情况来合理地调控服务器资源,提高机器的利用率。
- 线上出现故障时,如何动态地对故障业务做降级、流量控制等。
- 如何动态地更新服务中的配置信息,比如限流阈值、降级开关等。
- 如何实现大规模服务集群所带来的服务地址的管理和服务上下线的动态感知。
如何理解 Apache Dubbo
Apache Dubbo 是一个分布式服务框架,主要实现多个系统之间的高性能、透明化调用,简单
来说它就是一个 RPC 框架,但是和普通的 RPC 框架不同的是,它提供了服务治理功能,比如服
务注册、监控、路由、容错等。
Apache Dubbo 架构图如下图所示:

Spring Boot 集成 Apache Dubbo
dubbo 可以基于 XML 形式进行服务发布和服务消费,但是配置 xml 文件比较烦琐,而且在发布的服务接口比较多的情况下,配置会非常复杂,所以 Apache Dubbo 也提供了对注解的支持,基于 Spring Boot 集成 Apache Dubbo 实现零配置的服务注册与发布。
服务提供者开发流程
创建一个普通的 Maven 工程 springboot-provider,并创建两个模块:sample-api 和 sample-provider ,其中 sample-provider 模块是一个 Spring Boot 工程。
在 sample-api 模块中定义一个接口,并且通过 mvn install 安装到本地私服。
1
2
3public interface IHelloService {
String sayHello(String name);
}在 sample-provider 中引入以下依赖,其中 dubbo-spring-boot-starter 是 Apache Dubbo 官方提供的开箱即用的组件。
1
2
3
4
5
6
7
8
9
10
11
12
13
14<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.apache.dubbo</groupId>
<artifactId>dubbo-spring-boot-starter</artifactId>
<version>2.7.6</version>
</dependency>
<dependency>
<groupId>com.gupaoedu.book.dubbo</groupId>
<version>1.0-SNAPSHOT</version>
<artifactId>sample-api</artifactId>
</dependency>在 sample-provider 中实现 IHelloService,并且使用
Dubbo 中提供的@Service注解发布服务。1
2
3
4
5
6
7
8
9@Service
public class HelloServiceImpl implements IHelloService {
@Value("${dubbo.application.name}")
private String serviceName;
@Override
public String sayHello(String name){
return String.format("[%s]:Hello,%s",serviceName,name);
}
}在 application.properties 文件中添加 Dubbo 服务的配置信息。
1
2
3
4
5spring.application.name=springboot-dubbo-demo
dubbo.application.name=springboot-provider
dubbo.protocol.name=dubbo
dubbo.protocol.port=20880
dubbo.registry.address=N/A启动 Spring Boot,需要注意的是,需要在启动方法上添加
@DubboComponentScan注解,它的作用和 Spring Framework 提供的@ComponetScan 一样,只不过这里扫描的是Dubbo 中提供的@Service注解。1
2
3
4
5
6@DubboComponentScan
@SpringBootApplication
public class ProviderApplication
public static void main(String[]args){
SpringApplication.run(ProviderApplication.class,args);
}
服务调用者的开发流程
服务调用者引入 api 模块作为依赖,调用该接口方法,该接口被调用时会被自动代理执行服务供给者所实现的方法。
创建一个 Spring Boot 项目 springboot-consumer,添加 Jar 包依赖。
1
2
3
4
5
6
7
8
9
10<dependency>
<groupId>org.apache.dubbo</groupId>
<artifactId>dubbo-spring-boot-starter</artifactId>
<version>2.7.6</version>
</dependency>
<dependency>
<groupId>com.gupaoedu.book.dubbo</groupId>
<version>1.0-SNAPSHOT</version>
<artifactId>sample-api</artifactId>
</dependency>在 application.properties 中配置项目名称。
dubbo.application.name=springboot-consumer在 Spring Boot 启动类中,使用 Dubbo 提供的 @Reference 注解来获得一个远程代理对象。
1 | |
调用链路结果如下图所示:
服务供给者:
服务消费者:
相比基于 XML 的形式来说,基于 Dubbo-Spring-Boot-Starter 组件来使用 Dubbo 完成服务发布和服务消费会使得开发更加简单。另外,官方还提供了 Dubbo-Spring-Boot-Actuator 模块,可以实现针对 Dubbo 服务的健康检查;还可以通过 Endpoints 实现Dubbo 服务信息的查询和控制等,为生产环境中对 Dubbo 服务的监控提供了很好的支持。
前面的两个案例中,主要还是使用 Dubbo 以点对点的形式来实现服务之间的通信,Dubbo 可以很好地集成注册中心来实现服务地址的统一管理。早期大部分公司采用的是 ZooKeeper 来实现注册,接下来将学习一下 ZooKeeper,然后基于前面演示的案例整合 ZooKeeper 实现服务的注册和发现。
快速上手 ZooKeeper
ZooKeeper 是一个高性能的分布式协调中间件,所谓的分布式协调中间件的作用类似于多线程环境中通过并发工具包来协调线程的访问控制,只是分布式协调中间件主要解决分布式环境中各个服务进程的访问控制问题,比如访问顺序控制。所以,在这里需要强调的是,ZooKeeper 并不是注册中心,只是基于 ZooKeeper 本身的特性可以实现注册中心这个场景而已。
分布式锁
用过多线程的应该都知道锁,比如 Synchronized 或者 Lock,它们主要用于解决多线程环境下共享资源访问的数据安全性问题,但是它们所处理的范围是线程级别的。在分布式架构中,多个进程对同一个共享资源的访问,也存在数据安全性问题,因此也需要使用锁的形式来解决这类问题,而==解决分布式环境下多进程对于共享资源访问带来的安全性问题的方案就是使用分布式锁==。锁的本质是排他性的,也就是避免在同一时刻多个进程同时访问某一个共享资源。
实现分布式锁
分布式锁常见的有三种实现方式 :
- 基于 Redis 实现分布式锁.
- 基于 Zookeeper 实现.
- 基于数据库 实现.
Master 选举
Master 选举是分布式系统中非常常见的场景,在分布式架构中,为了保证服务的可用性,通常会采用集群模式,也就是当其中一个机器宕机后,集群中的其他节点会接替故障节点继续工作。这种工作模式有点类似于公司中某些重要岗位的 AB 角,当 A 请假之后,B 可以接替 A 继续工作。在这种场景中,就需要==从集群中选举一个节点作为 Master 节点,剩余的节点都作为备份节点随时待命。当原有的 Master 节点出现故障之后,还需要从集群中的其他备份节点中选举一个节点作为 Master 节点继续提供服务==。

Apache Dubbo 集成 ZooKeeper 实现服务注册
大规模服务化之后,在远程 RPC 通信过程中,会遇到两个比较尖锐的问题:
- 服务动态上下线感知。
- 负载均衡。
服务动态上下线感知,就是服务调用者要感知到服务提供者上下线的变化。按照以往传统的形式,服务调用者如果要调用服务提供者,必须要知道服务提供者的地址信息及映射参数。以 Webservice 为例,服务调用者需要在配置文件中维护一个http:ip:port/service?wsdl地址,但是如果服务提供者是一个集群节点,那么服务调用者需要维护多个这样的地址。问题来了,一旦服务提供者的 P 故障或者集群中某个节点下线了,服务调用者需要同步更新这些地址,但是这个操作如果人工来做是不现实的,所以需要一个第三方软件来统一管理服务提供者的 URL 地址,服务调用者可以从这个软件中获得目标服务的相关地址,并且第三方软件需要动态感知服务提供者状态的变化来维护所管理的 URL,进而使得服务调用者能够及时感知到变化而做出相应的处理。
负载均衡,就是当服务提供者是由多个节点组成的集群环境时,服务调用者需要通过负载均衡算法来动态选择一台目标服务器进行远程通信。负载均衡的主要目的是通过多个节点的集群来均衡服务器的访问压力,提升整体性能。实现负载均衡的前提是,要得到目标服务集群的所有地址,在服务调用者端进行计算,而地址的获取也同样依赖于第三方软件。
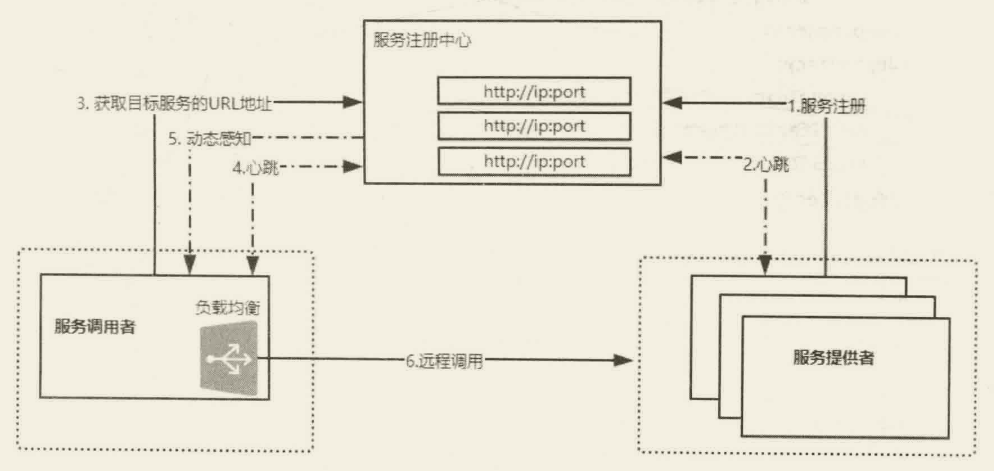
当 Dubbo 服务启动时,会去 Zookeeper 服务器上的/dubbo/com.gupaoedu.book.dubbo.IHelloService/providers 目录下创建当前服务的 URL,其中 com.gupaoedu.book.dubbo.IHelloService 是发布服务的接口全路径名称,providers 表示服务提供者的类型,dubbo:/ip:port 表示该服务发布的协议类型及访问地址。其中,URL 是临时节点,其他皆为持久化节点。在这里使用临时节点的好处在于,如果注册该节点的服务器下线了,那么这个服务器的 URL 地址就会从 ZooKeeper 服务器上被移除。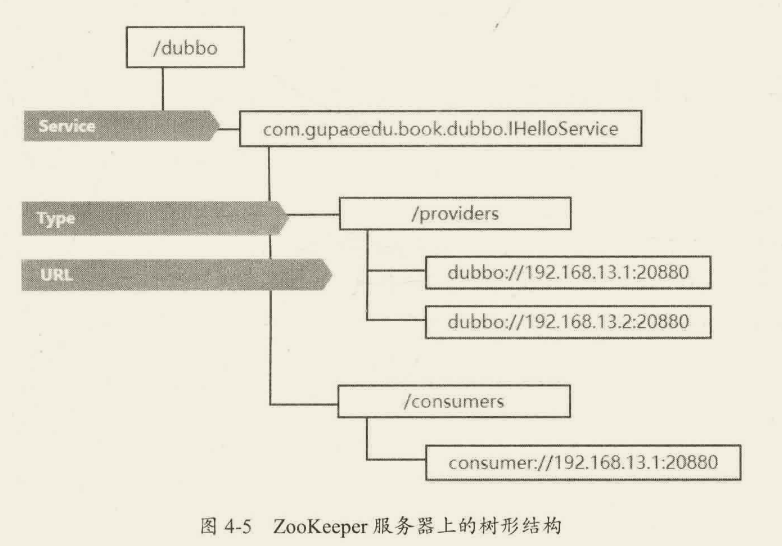
当 Dubbo 服务消费者启动时,会对/dubbo/com.gupaoedu.book.dubbo.HelloService/providers 节点下的子节点注册Watcher 监听,这样便可以感知到服务提供方节点的上下线变化,从而防止请求发送到已经下线的服务器造成访问失败。同时,服务消费者会在 dubbo/com.gupaoedu.book,dubbo.HelloService/consumers 下写入自己的 URL,这样做的目的是可以在监控平台上看到某个 Dubbo 服务正在被哪些服务调用(链路追踪)。最重要的是,Dubbo 服务的消费者如果需要调用 IHelloService 服务,那么它会先去/dubbo/.com.gupaoedu.book.dubbo.IHelloService/providers 路径下==获得所有该服务的提供方 URL 列表,然后通过负载均衡算法计算出一个地址进行远程访问==。
- 基于临时节点的特性,当服务提供者宕机或者下线时,注册中心会自动删除该服务提供者的信息。
- 注册中心重启时,Dubbo 能够自动恢复注册数据及订阅请求。
- 为了保证节点操作的安全性,ZooKeeper 提供了 ACL 权限控制,在 Dubbo 中可以通过 dubbo.registry.username/dubbo.registry.password 设置节点的验证信息。
- 注册中心默认的根节点是/dubbo,如果需要针对不同环境设置不同的根节点,可以使用 dubbo.registry.group 修收根节占名称。
实战 Dubbo Spring Cloud
在服务治理方面,Apache Dubbo 有着非常大的优势,并且在 Spring Cloud 出现之前,它就已经被很多公司作为服务治理及微服务基础设施的首选框架。Dubbo Spring Cloud 的出现,使得 Dubbo 既能够完全整合到 Spring Cloud 的技术栈中,享受 SpringCloud 生态中的技术支持和标准化输出,又能够弥补 Spring Cloud 中服务治理这方面的短板。
实现 Dubbo 服务提供方
创建一个普通的 Maven 工程,并在该工程中创建两个模块:spring-cloud-dubbo-sample-api、spring-cloud-dubbo-sample-provider。其中 spring-cloud-dubbo-sample-api 是一个普通的 Maven 工程,spring-cloud-dubbo-sample-provider 是一个 Spring Boot 工程。对于服务提供者而言,都会存在一个 API 声明,因为服务的调用者需要访问服务提供者声明的接口,为了确保契约的一致性,Dubbo 官方推荐的做法是把服务接口打成 Jar 包发布到仓库上。服务调用者可以依赖该 Jar 包,通过接口调用方式完成远程通信。对于服务提供者来说,也需要依赖该 Jar 包完成接口的实现。
注意:当前案例中使用的 Spring Cloud 版本为 Greenwich.SR2,Spring Cloud Alibaba 的版本为 2.2.2.RELEASE,Spring Boot 的版本为 2.1.11.RELEASE。
在 spring-cloud-dubbo-sample-api 中声明接口,并执行 mvn install 将 Jar 包安装到本地仓库。
1
2
3public interface IHelloService {
String sayHello(String name);
}在 spring-cloud-dubbo-sample-provider 中添加依赖:
1 | |
需要注意的是,上述依赖的 artifact 没有指定版本,所以需要在父 pom 中显式声明 dependencyManagement.
1 | |
- 在 spring-cloud-dubbo-sample-provider 中创建接口的实现类 HelloServiceImpl,其中@Service 是 Dubbo 服务的注解,表示当前服务会发布为一个远程服务。
1 | |
- 在 application.properties 中配置 Dubbo 相关的信息。
1
2
3
4
5
6
7
8
9
10server.port=8080
dubbo.protocol.port=20880
dubbo.protocol.name=dubbo
dubbo.registry.address=zookeeper://localhost:2181 #dubbo .registry.address=zookeeper://xxx:2181 #tip 远程地址报错
dubbo.registry.timeout=60000
dubbo.application.name=spring-cloud-dubbo-provider
spring.application.name=spring-cloud-dubbo-provider
spring.cloud.zookeeper.discovery.register=true
#spring .cloud.zookeeper.connect-string=xxx:2181
spring.cloud.zookeeper.connect-string=localhost:2181
其中 spring.cloud.zookeeper.discovery.register=true 表示服务是否需要注册到注册中心。
spring.cloud.zookeeper.connect-string 表示 ZooKeeper 的连接字符串。
- 在启动类中声明@DubboComponentScan 注解,并启动服务。
1 | |
@DubboComponentScan 扫描当前注解所在的包路径下的 @org.apache.dubbo.config.annotationService 注解,实现服务的发布。发布完成之后,就可以在 ZooKeeper 服务器上看一个/services/${project-name}节点,这个节点中保存了服务提供方相关的地址信息。
实现 Dubbo 服务调用方
Dubbo 服务提供方 spring-cloud-dubbo-.sample 已经准备完毕,只需要创建一个名为 spring-cloud-dubbo-consumer 的 Spring Boot 项目,就可以实现 Dubbo 服务调用了。
- 创建一个名为 spring-cloud-dubbo-consumer 的 Spring Boot 工程,添加如下依赖,与服务提供方所依赖的配置没什么区别。为了演示需要,增加了 spring-boot-starter-web 组件,表示这是一个 Web 项目。
1 | |
- 在 application.properties 文件中添加 Dubbo 相关配置信息。
1
2
3
4
5
6
7server.port=8081
dubbo.protocol.name=dubbo
dubbo.application.name=springboot-consumer
dubbo.cloud.subscribed-services=spring-cloud-dubbo-provider
spring.application.name=spring-cloud-dubbo-consumer
spring.cloud.zookeeper.discovery.register=false
spring.cloud.zookeeper.connect-string=localhost:2181
配置信息和 spring-cloud-dubbo-sample 项目的配置信息差不多,有两个配置需要单独说明一下:
spring.cloud.zookeeper.discovery.register=false表示当前服务不需要注册到 ZooKeeper 上,默认为 true。dubbo.cloud.subscribed.services表示服务调用者订阅的服务提供方的应用名称列表,如果有多个应用名称,可以通过“,”分割开,默认值为“*”,不推荐使用默认值。当 dubbo.cloud.subscribed.services 为默认值时,控制台的日志中会输入一段警告信息。
- 创建 HelloController 类,暴露一个/say 服务,来消费 Dubbo 服务提供者的 HelloService 服务。
1
2
3
4
5
6
7
8
9@RestController
public class HelloController{
@Reference
private IHelloService iHelloService;
@GetMapping("/say")
public String sayHello(){
return iHelloService.sayHello("Mic");
}
} - 启动 Spring Boot 服务。
1 | |
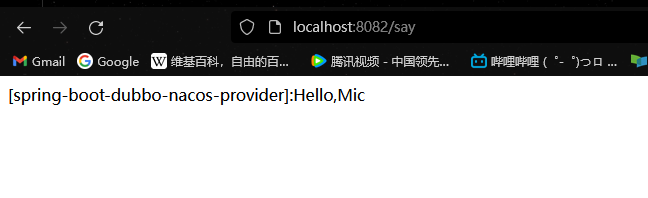
通过 curl 命令执行 HTTP GET 方法:curl http:/127.0.0.1:8080/say 响应结果为:[spring-cloud-dubbo-sample]:Hello,Mic

Apache Dubbo 的高级应用
- 支持多种协议的服务发布,默认是 dubbo://,还可以支持 rest://、webservice://、thrift://等。
- 支持多种不同的注册中心,如 Nacos、ZooKeeper、Redis,未来还将会支持 Consul、Eureka、Etcd 等。
- 支持多种序列化技术,如 avro、fst、fastjson、hessian2、kryo 等。
除此之外,Apache Dubbo 在服务治理方面的功能非常完善,比如集群容错、服务路由、负载均衡、服务降级、服务限流、服务监控、安全验证等。接下来带着大家分析一些常用的功能配置,更多的功能可以关注 Apache Dubbo 官网,相比国外的官方资料来说,它最大的优势是支持中文,所以对读者来说也能够很好地理解。
集群容错
在分布式架构的网络通信中,容错能力是必须要具备的。什么叫容错呢?从字面来看,就是服务容忍错误的能力。我们都知道网络通信中会存在很多不确定的因素导致请求失败,比如网络延迟、网络中断、服务异常等。当服务调用者(消费者)调用服务提供者的接口时,如果因为上述原因出现请求失败,那对于服务调用者来说,需要一种机制来应对。Dubbo 中提供了集群容错的机制来优雅地处理这种错误。
容错模式
Dubbo 默认提供了 6 种容错模式,默认为 Failover Cluster。如果这 6 种容错模式不能满足你的实际需求,还可以自行扩展。这也是 Dubbo 的强大之处,几乎所有的功能都提供了插拔式的扩展。
Failover Cluster,失败自动切换。当服务调用失败后,会切换到集群中的其他机器进行重试,默认重试次数为 2,通过属性 retries=2 可以修改次数,但是重试次数增加会带来更长的响应延迟。这种容错模式通常用于读操作,因为事务型操作会带来数据重复问题。Failfast Cluster,快速失败。当服务调用失败后,立即报错,也就是只发起一次调用。通常用于一些幂等的写操作,比如新增数据,因为当服务调用失败时,很可能这个请求已经在服务器端处理成功,只是因为网络延迟导致响应失败,为了避免在结果不确定的情况下导致数据重复插入的问题,可以使用这种容错机制。Failsafe Cluster,失败安全。也就是出现异常时,直接忽略异常。Failback Cluster,失败后自动回复。服务调用出现异常时,在后台记录这条失败的请求定时重发。这种模式适合用于消息通知操作,保证这个请求一定发送成功。Forking Cluster,并行调用集群中的多个服务,只要其中一个成功就返回。可以通过 forks=2 来设置最大并行数。Broadcast Cluster,广播调用所有的服务提供者,任意一个服务报错则表示服务调用失败。这种机制通常用于通知所有的服务提供者更新缓存或者本地资源信息。
配置方式
配置方式非常简单,只需要在指定服务的@Service 注解上增加一个参数即可。注意,在没有特殊说明的情况下,后续代码都是基于前面的 Dubbo Spring Cloud 的代码进行改造的。在@Service 注解中增加 cluster-=”failfast’”参数,表示当前服务的容错方式为快速失败。
1 | |
在实际应用中,查询语句容错策略建议使用默认的 Failover Cluster,而增删改操作建议使用 Failfast Cluster 或者使用 Failover Cluster(retries=”0”)策略,防止出现数据重复添加等其他问题!建议在设计接口的时候把查询接口方法单独做成一个接口提供查询。
负载均衡
负载均衡应该不是一个陌生的概念,在访问量较大的情况下,我们会通过水平扩容的方式增加多个节点来平衡请求的流量,从而提升服务的整体性能。简单来说,如果一个服务节点的 TPS 是 100,那么如果增加到 5 个节点的集群,意味着整个集群的 TPS 可以达到 500。
当服务调用者面对 5 个节点组成的服务提供方集群时,请求应该分发到集群中的哪个节点,取决于负载均衡算法,通过该算法可以让每个服务器节点获得适合自己处理能力的负载。负载均衡可以分为硬件负载均衡和软件负载均衡,硬件负载均衡比较常见的就是 F5,软件负载均衡目前比较主流的是 Nginx。
在 Dubbo 中提供了 4 种负载均衡策略,默认负载均衡策略是 random。同样,如果这 4 种策略不能满足实际需求,我们可以基于 Dubbo 中的 SPI 机制来扩展。
Random LoadBalance,随机算法。可以针对性能较好的服务器设置较大的权重值,权重值越大,随机的概率也会越大。RoundRobin LoadBalance,轮询。按照公约后的权重设置轮询比例。LeastActive LoadBalance,最少活跃调用书。处理较慢的节点将会收到更少的请求。ConsistentHash LoadBalance,一致性 Hash。相同参数的请求总是发送到同一个服务提供者。
配置方式
在@Service 注解上增加 loadbalance 参数:1
@Service(cluster "failfast",loadbalance "roundrobin")
服务降级
服务降级是一种系统保护策略,当服务器访问压力较大时,可以根据当前业务情况对不重要的服务进行降级,以保证核心服务的正常运行。所谓的降级,就是把一些非必要的功能在流量较大的时间段暂时关闭,比如在双 11 大促时,淘宝会把查看历史订单、商品评论等功能关闭,从而释放更多的资源来保障大部分用户能够正常完成交易。
降级有多个层面的分类:
- 按照是否自动化可分为自动降级和人工降级。
- 按照功能可分为读服务降级和写服务降级。
人工降级一般具有一定的前置性,比如在电商大促之前,暂时关闭某些非核心服务,如评价推荐等。而自动降级更多的来自于系统出现某些异常的时候自动触发“兜底的流畅”,比如:
- 故障降级,调用的远程服务“挂了”,网络故障或者 RPC 服务返回异常。这类情况在业务允许的情况下可以通过设置兜底数据响应给客户端。
- 限流降级,不管是什么类型的系统,它所支撑的流量是有限的,为了保护系统不被压垮,在系统中会针对核心业务进行限流。当请求流量达到阈值时,后续的请求会被拦截,这类请求可以进入排队系统,比如 12306。也可以直接返回降级页面,比如返回“活动太火爆,请稍候再来”页面。
Dubbo 提供了一种 Mock 配置来实现服务降级,也就是说当服务提供方出现网络异常无法访问时,客户端不抛出异常,而是通过降级配置返回兜底数据,操作步骤如下:
- 在 spring-cloud-dubbo-consumer 项目中创建 MockHelloService 类,这个类只需要实现自动降级的接口即可,然后重写接口中的抽象方法实现本地数据的返回。
1 | |
- 在 HelloController 类中修改@Reference 注解增加 Mock 参数。其中设置了属性 cluster=”failfast’”,因为默认的容错策略会发起两次重试,等待的时间较长。
1
2
3
4
5
6
7
8
9
10
11@RestController
public class HelloController {
@Reference(mock="com.gupaoedu.book.springcloud.springclouddubboconsumer.MockHelloService",
cluster "failfast")
private IHelloService iHelloService;
@GetMapping("/say")
public String sayHello(){
return iHelloService.sayHello("Mic");
}
} - 在不启动 Dubbo 服务端或者服务端的返回值超过默认的超时时间时,访问/say 接口得到的结构就是 MockHelloService 中返回的数据。
主机绑定规则
主机绑定表示的是 Dubbo 服务对外发布的 IP 地址,默认情况下 Dubbo 会按照以下顺序来查找并绑定主机 P 地址:
- 查找环境变量中 DUBBO IP TO BIND 属性配置的 IP 地址。
- 查找 dubbo.protocol.host 属性配置的 IP 地址,默认是空,如果没有配置或者 P 地址不合法,则继续往下查找。
- 通过 LocalHost.getHostAddress 获取本机 IP 地址,如果获取失败,则继续往下查找。
- 如果配置了注册中心的地址,则使用 Socket 通信连接到注册中心的地址后,使用 for 循环通过 socket.getLocalAddress().getHostAddress(扫描各个网卡获取网卡 IP 地址。
上述过程中,任意一个步骤检测到合法的 P 地址,便会将其返回作为对外暴露的服务 P 地址。需要注意的是,获取的 P 地址并不是写入注册中心的地址,默认情况下,写入注册中心的 IP 地址优先选择环境变量中 DUBBO IP TO REGISTRY 属性配置的 P 地址。在这个属性没有配置的情况下,才会选取前面获得的 P 地址并写入注册中心。
使用默认的主机绑定规则,可能会存在获取的 P 地址不正确的情况,导致服务消费者与注册中心上拿到的 URL 地址进行通信。因为 Dubbo 检测本地 P 地址的策略是先调用 LocalHost..getHostAddress,这个方法的原理是通过获取本机的 hostname 映射 IP 地址,如果它指向的是一个错误的 IP 地址,那么这个错误的地址将会作为服务发布的地址注册到 ZooKeeper 节点上,虽然 Dubbo 服务能够正常启动,但是服务消费者却无法正常调用。按照 Dubbo 中 IP 地址的查找规则,如果遇到这种情况,可以使用很多种方式来解决:
- 在/etc/hosts 中配置机器名对应正确的 IP 地址映射。
- 在环境变量中添加 DUBBO IP TO BIND 或者 DUBBO IP TO REGISTRY 属性,Value 值为绑定的主机地址。
- 通过 dubbo.protocol.host 设置主机地址。
除获取绑定主机 P 地址外,对外发布的端口也是需要注意的,Dubbo 框架中针对不同的协议都提供了默认的端口号: - Dubbo 协议的默认端口号是 20880。
- Webservice 协议的默认端口号是 80。
在实际使用过程中,建议指定一个端口号,避免和其他 Dubbo 服务的端口产生冲突。
Apache Dubbo 核心源码分析
Apache Dubbo 的源码需要理解以下几个核心点:
- SPI 机制
- 自适应扩展点
- IoC 和 AOP
- Dubbo 如何与 Spring 集成
Dubbo 的核心之 SPI
在 Dubbo 的源码中,很多地方会存下面这样三种代码,分别是自适应扩展点、指定名称的扩展点、激活扩展点:
1 | |
这种扩展点实际上就是 Dubbo 中的 SPI 机制。在分析 Spring Boot 自动装配的时候提到过 SpringFactoriesLoader,它也是一种 SPI 机制。
Java SPI 扩展点实现
SPI 全称是 Service Provider Interface,原本是 JDK 内置的一种服务提供发现机制,它主要用来做服务的扩展实现.SPI 机制在很多场景中都有运用,比如数据库连接,JDK 提供了 java.sql.Driver 接口,这个驱动类在 DK 中并没有实现,而是由不同的数据库厂商来实现,比如 Oracle、MySQL 这些数据库驱动包都会实现这个接口,然后 JDK 利用 SPI 机制从 classpath 下找到相应的驱动来获得指定数据库的连接。这种插拔式的扩展加载方式,也同样遵循一定的协议约定。比如所有的扩展点必须要放在 resources//META-NF/services 目录下,SPI 机制会默认扫描这个路径下的属性文件以完成加载。
创建一个普通的 Maven 工程 Driver,定义一个接口。这个接口只是一个规范,并没有实现,由第三方厂商来提供实现。
1
2
3public interface Driver{
String connect();
}创建另一个普通的 Maven 工程 Mysql-Driver,添加 Driver 的 Maven 依赖。
1
2
3
4
5<dependency>
<groupId>org.fcs.spi</groupId>
<artifactId>Driver</artifactId>
<version>1.0-SNAPSHOT</version>
</dependency>创建 MysqlDriver,实现 Driver 接口,这个接口表示一个第三方的扩展实现。
1
2
3
4
5
6public class MysqlDriver implements Driver{
@Override
public String connect(){
return"连接 ysql 数据库";
}
}在 spi 实现类的
resources/META-INF/services目录下创建一个以 Driver 接口全路径名命名的文件 org.fcs.spi.Driver,在里面填写这个 Driver 的实现类扩展。1
org.fcs.spi.MysqlDriver创建一个测试类,使用 ServiceLoader 加载对应的扩展点。从结果来看,MysqlDriver 这个扩展点被加载并且输出了相应的内容。
1
2
3
4
5
6public class SpiMain {
public static void main(String[]args){
ServiceLoader<Driver>serviceLoader=ServiceLoader.load(Driver.class);
serviceLoader.forEach(driver->System.out.println(driver.connect()));
}
}

Dubbo 自定义协议扩展点
Dubbo 或者 SpringFactoriesLoader 并没有使用 JDK 内置的 SPI 机制,只是利用了 SPI 的思想根据实际情况做了一些优化和调整。Dubbo SPI 的相关逻辑被封装在了 ExtensionLoader 类中,通过 ExtensionLoader 我们可以加载指定的实现类。
Dubbo 的 SPI 扩展有两个规则:
- 和 JDK 内置的 SPI 一样,需要在 resources 目录下创建任一目录结构:META-INF/dubbo、META-INF/dubbo/internal、META-INF/services,在对应的目录下创建以接口全路径名命名的文件,Dubbo 会去这三个目录下加载相应扩展点。
- 文件内容和 JDK 内置的 SPI 不一样,内容是一种Key 和 Value形式的数据。Key 是一个字符串,Value 是一个对应扩展点的实现,这样的方式可以按照需要加载指定的实现类。
实现步骤如下:
在一个依赖了 Dubbo 框架的工程中,创建一个扩展点及一个实现。其中,扩展点需要声明@SPI 注解。
1
2
3
4
5
6
7
8
9
10
11
12//org.fcs.spi.dubbo
@SPI //依赖于 dubbo 依赖
public interface Driver{
String connect();
}
//org.fcs.spi.dubbo.impl
public class MysqlDriver implements Driver {
@Override
public String connect() {
return "连接 Mysql 数据库";
}
}在 resources/META-INF/dubbo 目录下创建以 SPI 接口命名的文件 com.gupaoedu.book.dubbo.spi.Driver.
1
mysqlDriver=org.fcs.spi.dubbo.impl.MysqlDriver创建测试类,使用 ExtensionLoader.getExtensionLoader.getExtension(“mysqlDriver”)获得指定名称的扩展点实现。
1
2
3
4
5
6
7@Test
public void connectTest(){
ExtensionLoader<Driver>
extensionLoader=ExtensionLoader.getExtensionLoader(Driver.class);
Driver driver=extensionLoader.getExtension("mysqlDriver");
System.out.println(driver.connect());
}

Dubbo SPI 扩展点源码分析
ExtensionLoader.getExtensionLoader
这个方法用于返回一个 ExtensionLoader 实例,主要逻辑如下:
- 先从缓存中获取与扩展类对应的 ExtensionLoader.
- 如果缓存未命中,则创建一个新的实例,保存到 EXTENSION LOADERS 集合中缓存起来
- 在 ExtensionLoader 构造方法中,初始化一个 objectFactory,后续会用到,暂时先不管。
无处不在的自适应扩展点
自适应(Adaptive)扩展点也可以理解为适配器扩展点。简单来说就是能够根据上下文动态匹配一个扩展类。它的使用方式如下:
1 | |
自适应扩展点通过@Adaptive 注解来声明,它有两种使用方式:
@Adaptive 注解定义在类上面,表示当前类为自适应扩展类。
1
2
3
4@Adaptive
public class AdaptiveCompiler implements Compiler{
//省略
}AdaptiveCompiler 类就是自适应扩展类,通过 ExtensionLoader.getExtensionLoader
(Compiler.class).getAdaptiveExtension();可以返回 AdaptiveCompiler 类的实例。@Adaptive 注解定义在方法层面,会通过动态代理的方式生成一个动态字节码,进行自适应匹配。
1
2
3
4
5
6
7
8
9@SPI("dubbo")
public interface Protocol{
int getDefaultPort();
@Adaptive
<T> Exporter<T> export(Invoker<T> invoker) throws RpcException;
@Adaptive
<T> Invoker<T> refer(Class<T> type,URL url) throws RpcException;
//省略部分代码
}
Protocol 扩展类中的两个方法声明了@Adaptive 注解,意味着这是一个自适应方法。在 Dubbo 源码中很多地方通过下面这行代码来获得一个自适应扩展点:
1 | |
但是,在 Protocol 接口的源码中,自适应扩展点的声明在方法层面上,所以它和类级别的声明不一样。这里的 protocol 实例,是一个动态代理类,基于 javassist 动态生成的字节码来实现方法级别的自适应调用。简单来说,调用 export 方法时,会根据上下文自动匹配到某个具体的实现类的 export 方法中。
基于 Protocol 的自适应扩展点方法 ExtensionLoader.getExtensionLoader(Protocol.class).getAdaptiveExtension()来分析它的源码实现。从源码来看,getAdaptiveExtension 方法非常简单,只做了两件事:
- 从缓存中获取自适应扩展点实例。
- 如果缓存未命中,则通过 createAdaptiveExtension 创建自适应扩展点。
Dubbo 中的 IoC 和 AOP
IoC 中一个非常重要的思想是,在系统运行时,动态地向某个对象提供它所需要的其他对象,这种机制是通过 Dependency Injection(依赖注入)来实现的。
injectExtension 就是依赖注入的实现,整体逻辑比较简单:
- 遍历被加载的扩展类中所有的 set 方法。
- 得到 st 方法中的参数类型,如果参数类型是对象类型,则获得这个 set 方法中的属性名称。
- 使用自适应扩展点加载该属性名称对应的扩展类。
- 调用 set 方法完成赋值。
AOP 全称为 Aspect Oriented Programming,意思是面向切面编程,它是一种思想或者编程范式。它的主要意图是把业务逻辑和功能逻辑分离,然后在运行期间或者类加载期间进行织入。这样做的好处是,可以降低代码的复杂性,以及提高重用性。
1 | |
其中分别用到了依赖注入和 AOP 思想,AOP 思想的体现是基于 Wrapper 装饰器类实现对原有的扩展类 instance 进行包装。
Dubbo 和 Spring 完美集成的原理
在 Spring Boot 集成 Dubbo 这个案例中,服务发布主要有以下几个步骤:
- 添加 dubbo-spring-boot-starter 依赖。
- 定义 @org.apache.dubbo.config.annotation.Service 注解。
- 声明@DubboComponentScan,用于扫描@Service 注解。
基于前面的分析,其实不难猜出它的实现原理。@Service 与 Spring 中的@org.springframework,stereotype.Service,用于实现Dubbo 服务的暴露。与它相对应的是 @Reference ,它的作用类似于 Spring 中的@Autowired。
而@DubboComponentScan 和 Spring 中的@ComponentScan 作用类似,用于扫描@Service、@Reference 等注解。
本章小结
前面部分的内容比较好理解,源码部分需要稍微花点时间。笔者建议我们结合本书上的几个关键点,去官网下载源码逐步解读。在笔者看来,看源码不是目的,它是一种思想上的交流,好的设计和好的思想在合适的时机我们是可以直接借鉴过来的。
第五章、服务注册与发现
在微服务架构下,一个业务服务会被拆分成多个微服务,各个服务之间相互通信完成整体的功能。另外,为了避免单点故障,微服务都会采取集群方式的高可用部署,集群规模越大,性能也会越高,如图 5-1 所示。

服务消费者要去调用多个服务提供者组成的集群。首先,服务消费者需要在本地配置文件中维护服务提供者集群的每个节点的请求地址。其次,服务提供者集群中如果某个节点下线或者宕机,服务消费者的本地配置中需要同步删除这个节点的请求地址,防止请求发送到已宕机的节点上造成请求失败。为了解决这类的问题,就需要引入服务注册中心,它主要有以下功能:
- 服务地址的管理
- 服务注册
- 服务动态感知
能够实现这类功能的组件很多,比如 ZooKeeper、Eureka、Consul、Etcd、Nacos 等。
Alibaba Nacos 概念
Ncos 致力于解决微服务中的统一配置、服务注册与发现等问题。它提供了一组简单易用的特性集,帮助开发者快速实现动态服务发现、服务配置、服务元数据及流量管理,Nacos 的关键特性如下。
服务发现和服务健康监测
Nacos 支持基于 DNS 和基于 RPC 的服务发现。服务提供者使用原生 SDK、OpenAPI 或一个独立的 Agent TODO 注册 Service 后,服务消费者可以使用 DNS 或 HTTP&API 查找和发现服务。
Nacos 提供对服务的实时的健康检查,阻止向不健康的主机或服务实例发送请求。Nacos 支持传输层(PING 或 TCP)和应用层(如 HTTP、MySQL、用户自定义)的健康检查。对于复杂的云环境和网络拓扑环境中(如 VPC、边缘网络等)服务的健康检查,Nacos 提供了agent 上报和服务端主动检测两种健康检查模式。Nacos 还提供了统一的健康检查仪表盘,帮助用户根据健康状态管理服务的可用性及流量。动态配置服务
业务服务一般都会维护一个本地配置文件,然后把一些常量配置到这个文件中。这种方式在某些场景中会存在问题,比如配置需要变更时要重新部署应用。而动态配置服务可以以中心化、外部化和动态化的方式管理所有环境的应用配置和服务配置,可以使配置管理变得更加高效和敏捷。配置中心化管理让实现无状态服务变得更简单,让服务按需弹性扩展变得更容易。
另外,Nacos 提供了一个简洁易用的 UI(控制台样例 Demo)帮助用户管理所有服务和应用的配置。Nacos 还提供了包括配置版本跟踪、金丝雀发布、一键回滚配置及客户端配置更新状态跟踪在内的一系列开箱即用的配置管理特性,帮助用户更安全地在生产环境中管理配置变更,降低配置变更带来的风险。动态 DNS 服务
动态 DNS 服务支持权重路由,让开发者更容易地实现中间层负载均衡、更灵活的路由策略、流量控制,以及数据中心内网的简单 DNS 解析服务。服务及其元数据管理
Nacos 可以使开发者从微服务平台建设的视角管理数据中心的所有服务及元数据,包括管理服务的描述、生命周期、服务的静态依赖分析、服务的健康状态、服务的流量管理、路由及安全策略、服务的 SLA 及最重要的 metrics 统计数据。
Nacos 基本用法
本地直接部署和 docker 部署 nacos 方式详见各种环境配置.
Nacos 集成 Spring Boot 实现服务注册与发现
单模块打包方式为 jar,多模块打包方式为 pom
1 | |
spring-boot 版本为 2.6.13,spring-cloud-alibaba 版本为 2021.0.5.0,本节将使用该版本实现简单的 nacos 服务注册
- 新建 nacos 的 springboot 项目,设置 pom 配置文件。
父项目对依赖进行版本管理,其配置文件如下:子项目实现 nacos 服务注册,其配置文件如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42<?xml version="1.0" encoding="UTF-8"?>
<project xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns="http://maven.apache.org/POM/4.0.0"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.fcs</groupId>
<artifactId>SpringCloud_Alibaba</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>SpringCloud_Alibaba</name>
<description>SpringCloud_Alibaba</description>
<packaging>pom</packaging>
<modules>
<module>nacos</module>
</modules>
<properties>
<java.version>1.8</java.version>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
<spring-boot.version>2.6.13</spring-boot.version>
<spring-cloud-alibaba.version>2021.0.5.0</spring-cloud-alibaba.version>
</properties>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-dependencies</artifactId>
<version>${spring-boot.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-alibaba-dependencies</artifactId>
<version>${spring-cloud-alibaba.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
</project>1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75<?xml version="1.0" encoding="UTF-8"?>
<project xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns="http://maven.apache.org/POM/4.0.0"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>com.fcs</groupId>
<artifactId>SpringCloud_Alibaba</artifactId>
<version>0.0.1-SNAPSHOT</version>
</parent>
<artifactId>nacos</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>nacos</name>
<description>nacos</description>
<packaging>jar</packaging>
<properties>
<java.version>1.8</java.version>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.8.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
<encoding>UTF-8</encoding>
</configuration>
</plugin>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<version>${spring-boot.version}</version>
<configuration>
<mainClass>com.fcs.NacosApplication</mainClass>
<skip>true</skip>
</configuration>
<executions>
<execution>
<id>repackage</id>
<goals>
<goal>repackage</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
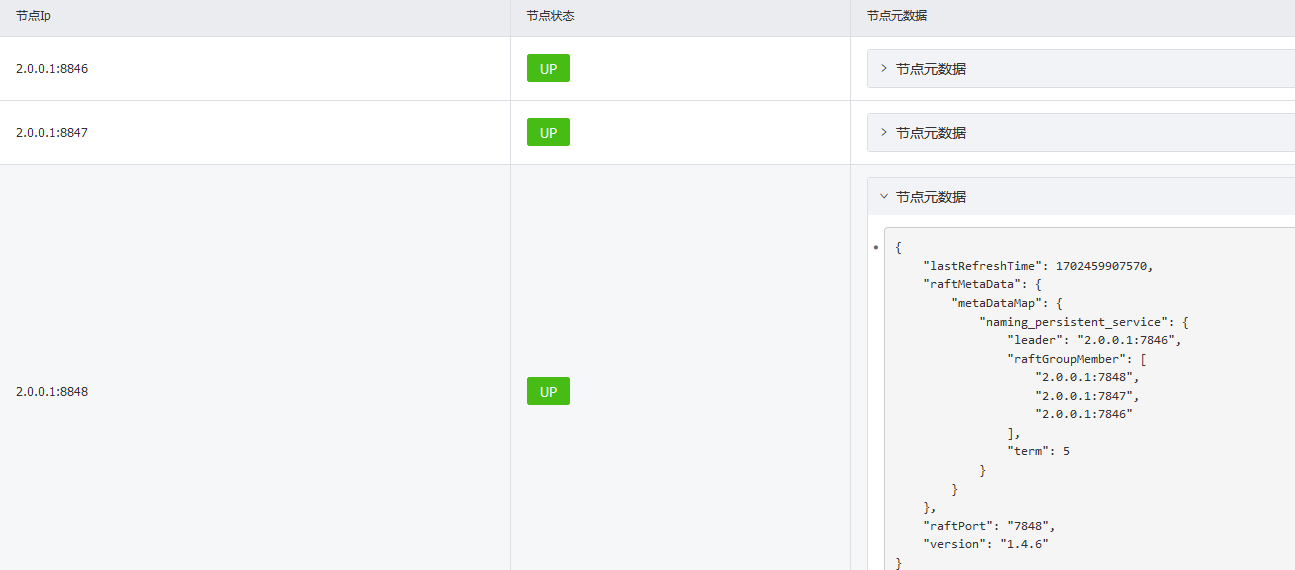
Nacos 的高可用部署
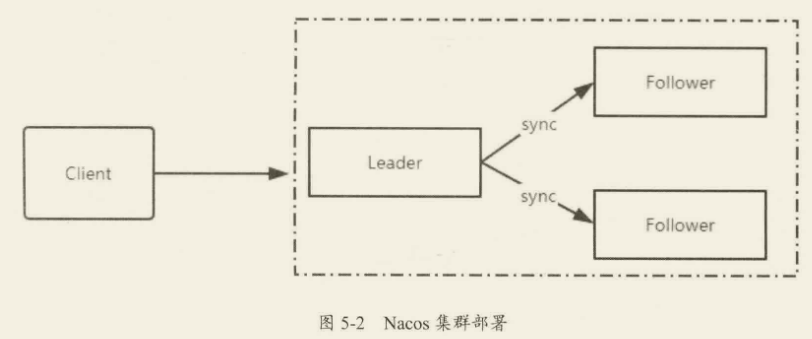
在分布式架构中,任何中间件或者应用都不允许单点存在,所以开源组件一般都会自己支持高可用集群解决方案。如图 5-2 所示,Nacos 提供了类似于 ZooKeeper 的集群架构,包含一个 Leader 节点和多个 Follower 节点。和 ZooKeeper 不同的是,它的数据一致性算法采用的是 Raft,同样采用了该算法的中间件有 Redis Sentinel 的 Leader 选举、Etcd 等。
安装环境要求
请确保在环境中安装使用:
- 64 bit OS Linux/UNIX/Mac,推荐使用 Linux 系统。
- 64 bit JDK1.8 及以上,下载并配置。
- Maven3.2.x 及以上,下载并配置。
- 3 个或 3 个以上 Nacos 节点才能构成集群。
- MySQL 数据库。
安装包及环境准备
准备 3 台服务器,笔者采用的是 Centos 7.x 系统。
- 下载安装包,分别进行解压:tar-zxvf nacos-server-1.1.4.tar.gz 或者 unzip nacos-server-1.1.4.zip。
- 解压后会得到 5 个文件夹:bin(服务启动/停止脚本)、conf(配置文件)、logs(日志)、data(derby 数据库存储)、target(编译打包后的文件)。
集群配置
在 conf 目录下包含以下文件。
- application.properties: Spring Boot 项目默认的配置文件。
- cluster.conf.example:集群配置样例文件。
- nacos-mysql.sql:MySQL 数据库脚本。Nacos 支持 Derby 和 MySQL 两种持久化机制,默认采用 Derby 数据库。如果采用 MySQL,需要运行该脚本创建数据库和表。
- nacos-logback.xml:Nacos 日志配置文件。
配置 Nacos 集群需要用到 cluster.conf 文件,我们可以直接重命名提供的 example 文件,修改该配置信息如下:
1 | |
这 3 台机器中的 cluster.conf 配置保持一致。由于这 3 台机器之间需要彼此通信,所以在部署的时候需要防火墙对外开放 8848 端口。
具体配置由各种环境配置中的 nacos 部分可见,连接外部数据库时新建的 nacos 用户的密码要用 mysql_native_password,否则会报错连不上外部数据库。
集群部署结果如下图所示:
Dubbo 使用 Nacos 实现注册中心
Nacos 作为 Spring Cloud Alibaba 中服务注册与发现的核心组件,可以很好地帮助开发者将服务自动注册到 Nacos 服务端,并且能够动态感知和刷新某个服务实例的服务列表。使用 SpringCloud Alibaba Nacos Discovery 可以基于 Spring Cloud 规范快速接入 Nacos,实现服务注册与发现功能。
在本节中,我们通过将 Spring Cloud Alibaba Nacos Discovery 集成到 Spring Cloud AlibabaDubbo,完成服务注册与发现的功能。
Dubbo 可以支持多种注册中心,比如在前面章节中讲的 ZooKeeper,以及 Consul、Nacos 等。本节主要讲解如何使用 Nacos 作为 Dubbo 服务的注册中心,为 Dubbo 提供服务注册与发现的功能,实现步骤如下。
服务端
- 创建一个普通 Maven 项目 spring-boot-dubbo-nacos-sample,添加两个模块:nacos-sample-api 和 nacos-sample-provider。其中,nacos-sample-provider 是一个 Spring Boot 工程。
- 在 nacos-sample-api 中声明接口。
1 | |
- 在 nacos-sample-provider 中添加依赖。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29<dependencies>
<!-- spring-cloud-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter</artifactId>
</dependency>
<!-- dubbo-alibaba-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-dubbo</artifactId>
</dependency>
<!-- nacos-discovery-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
</dependency>
<!--lombok-->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<!-- sample-api-->
<dependency>
<groupId>org.fcs</groupId>
<artifactId>sample-api</artifactId>
<version>0.0.1-SNAPSHOT</version>
</dependency>
</dependencies>
上述依赖包的简单说明如下:
- spring-cloud-starter: Spring Cloud 核心包。
- spring-cloud-starter-dubbo,Dubbo 的 Starter 组件,添加 Dubbo 依赖。
- spring-cloud-starter-alibaba-nacos-discovery,基于 Nacos 的服务注册与发现。
- nacos-sample-api,接口定义类的依赖。
- 创建 HelloServicelmpl 类,实现 IHelloService 接口。
1 | |
- 修改 application.yml 配置。仅将 dubbo.registry.address 中配置的协议改成了
spring-cloud://${spring.cloud.nacos.discovery.server-addr},基于 Nacos 协议1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26server:
port: 8081
spring:
main:
allow-bean-definition-overriding: true #Spring Boot 2.1 需要设定,允许覆盖bean
application:
name: spring-boot-dubbo-nacos-provider
cloud:
nacos:
discovery:
server-addr: 8.130.88.159:8848
dubbo:
scan:
base-packages: com.fcs.service # 指定要扫描远程调用接口实现类的包路径
registry:
address: spring-cloud://${spring.cloud.nacos.discovery.server-addr}
timeout: 60000
protocol:
name: dubbo
port: -1
application:
# name: ${spring.application.name} #dubbo服务名称供消费者订阅
name: spring-boot-dubbo-nacos-provider #dubbo服务名称供消费者订阅
qos-enable: false #dubbo运维服务是否开启
consumer:
check: false # 消费者是否检查版本
以上配置的简单说明如下。
- dubbo.scan.base-packages:功能等同于@DubboComponentScan,指定 Dubbo服务实现类的扫描包路径。
- dubbo.registry.address:Dubbo 服务注册中心的配置地址,它的值 spring-cloud://localhost 表示挂载到 Spring Cloud 注册中心,不配置的话会提示没有配置注册中心的错误。
- spring.cloud.nacos.discovery.server-addr:Nacos 服务注册中心的地址。
- 运行 Spring Boot 启动类,注意需要声明 DubboComponentScan。
1
2
3
4
5
6
7
8
9@SpringBootApplication
@DubboComponentScan
@EnableDubbo
@EnableDiscoveryClient
public class SampleProviderApplication {
public static void main(String[] args) {
SpringApplication.run(SampleProviderApplication.class, args);
}
}
服务启动成功之后,访问 Ncos 控制台,进入“服务管理”→“服务列表”,如图下图所示,可以看到所有注册在 Nacos 上的服务。


细心的读者会发现,基于 Spring Cloud Alibaba Nacos Discovery 实现服务注册时,元数据中发布的服务接口是 com.alibaba.cloud.dubbo.service.DubboMetadataService。那么消费者要怎么去找到 IHelloService 呢?别急,进入 Nacos 控制台的“配置列表”,可以看到如图 5-8 所示的配置信息。
实际上这里把发布的接口信息存储到了配置中心,并且建立了映射关系,从而使得消费者在访问服务的时候能够找到目标接口进行调用。至此,服务端便全部开发完了,接下来我们开始消费端的开发。
消费端开发
创建一个 Spring Boot 项目 spring-cloud-nacos-consumer。
添加相关 Maven 依赖。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- spring-cloud-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter</artifactId>
</dependency>
<!--lombok-->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-dubbo</artifactId>
</dependency>
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
</dependency>
<!-- sample-api-->
<dependency>
<groupId>org.fcs</groupId>
<artifactId>sample-api</artifactId>
<version>0.0.1-SNAPSHOT</version>
</dependency>
</dependencies>在 application.yml 中添加配置信息。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25server:
port: 8082
spring:
main:
allow-bean-definition-overriding: true #Spring Boot 2.1 需要设定,允许覆盖bean
application:
name: spring-boot-dubbo-nacos-consumer
cloud:
nacos:
discovery:
server-addr: 8.130.88.159:8848
dubbo:
registry:
address: spring-cloud://${spring.cloud.nacos.discovery.server-addr}
timeout: 60000
protocol:
name: dubbo
port: -1
application:
name: spring-boot-dubbo-nacos-consumer #dubbo服务名称供消费者订阅
qos-enable: false #dubbo运维服务是否开启
consumer:
check: false # 消费者是否检查版本
cloud:
subscribed-services: spring-boot-dubbo-nacos-provider定义 HelloController,用于测试 Dubbo 服务的访问。
1 | |
- 启动服务
1 | |
调用结果如下图所示:

与第 4 章中 Dubbo Spring Cloud 的代码相比,除了注册中心从 ZooKeeper 变成 Nacos,其他基本没什么变化,因为这两者都是基于 Spring Cloud 标准实现的,而这些标准化的定义都抽象到了 Spring-Cloud-Common 包中。在后续的组件集成过程中,会以本节中创建的项目进行集成。
Nacos 实现原理分析
Nacos 架构图
Nacos 官方提供的架构图如下所示,我们简单来分析一下它的模块组成。
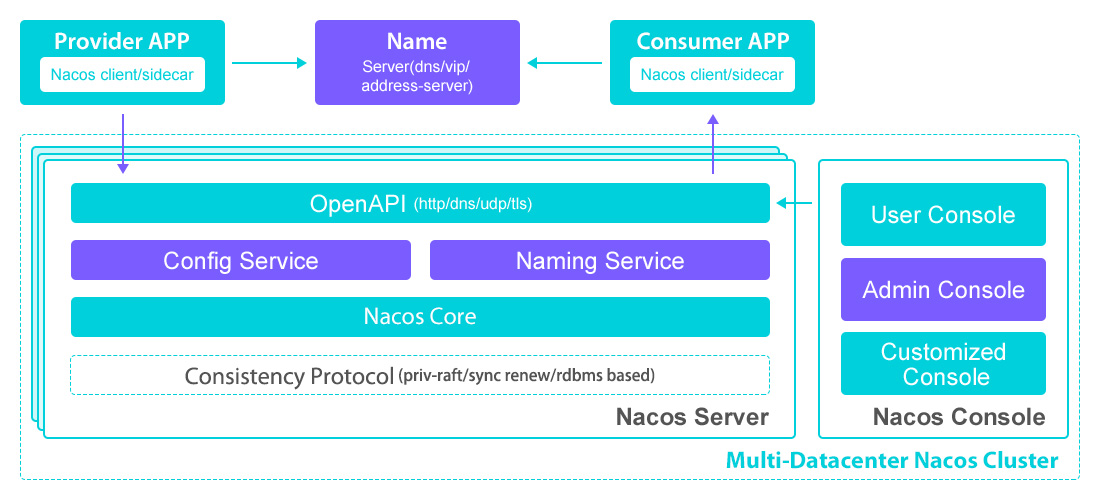
- Provider APP:服务提供者。
- Consumer APP:服务消费者。
- Name Server:通过 VIP(Vritual IP)或者 DNS 的方式实现 Nacos 高可用集群的服务路由。
- Nacos Server:Nacos 服务提供者,里面包含的 Open API 是功能访问入口,Config Service、Naming Service 是 Nacos 提供的配置服务、名字服务模块。Consistency Protocol 是一致性协议,用来实现 Nacos 集群节点的数据同步,这里使用的是 Raft 算法(使用类似算法的中间件还有 Etcd、Redis 哨兵选举)。
- Nacos Console:Nacos 控制台。
整体来说,服务提供者通过 VIP(Virtual IP)访问 Nacos Server 高可用集群,基于 Open API 完成服务的注册和服务的查询。Nacos Server 本身可以支持主备模式,所以底层会采用数据一致性算法来完成从节点的数据同步。服务消费者也是如此,基于 Open API 从 Nacos Server 中查询服务列表。
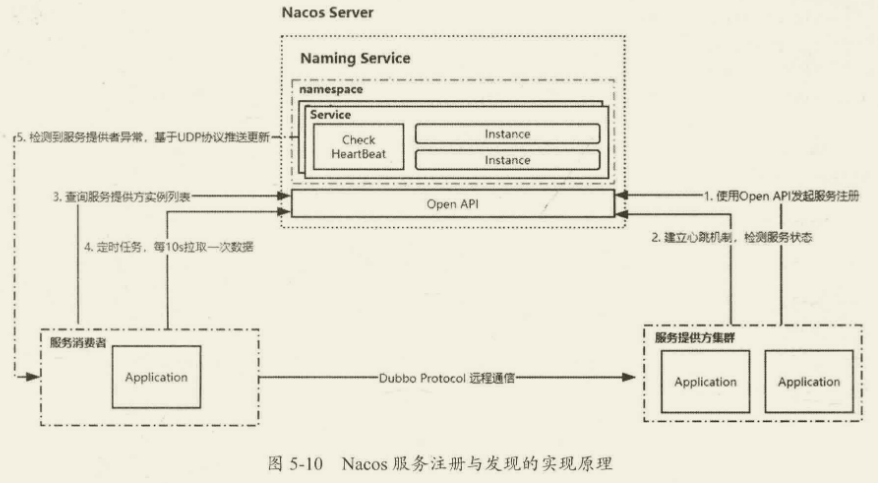
注册中心的原理
服务注册的功能主要体现在:
- 服务实例在启动时注册到服务注册表,并在关闭时注销。
- 服务消费者查询服务注册表,获得可用实例。
- 服务注册中心需要调用服务实例的健康检查 API 来验证它是否能够处理请求。
Nacos 服务注册与发现的实现原理如下图所示:
深入解读 Nacos 源码
Nacos 源码部分,我们主要阅读三部分:
- 服务注册。
- 服务地址的获取。
- 服务地址变化的感知。
服务注册
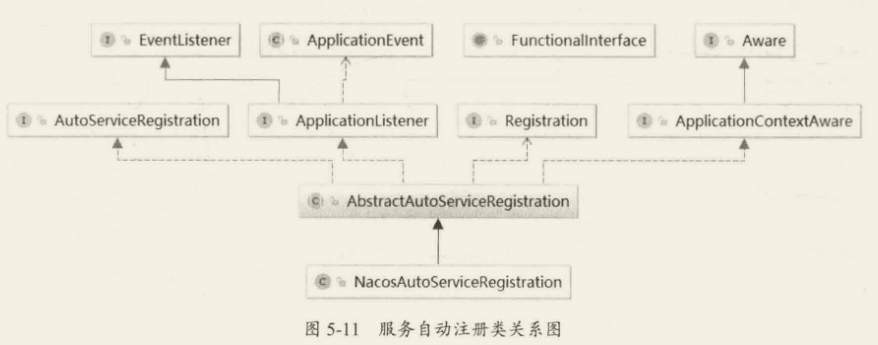
无论如何最终都是由 NacosAutoServiceRegistration.register 实现服务注册,而实际上用的是 namingService 的 register 去进行服务注册,注册的同时会开启心跳检测机制。
心跳机制就是客户端通过 schedule 定时向服务端发送一个数据包,然后启动一个线程不断检测服务端的回应,如果在设定时间内没有收到服务端的回应,则认为服务器出现了故障。Nacos 服务端会根据客户端的心跳包不断更新服务的状态。
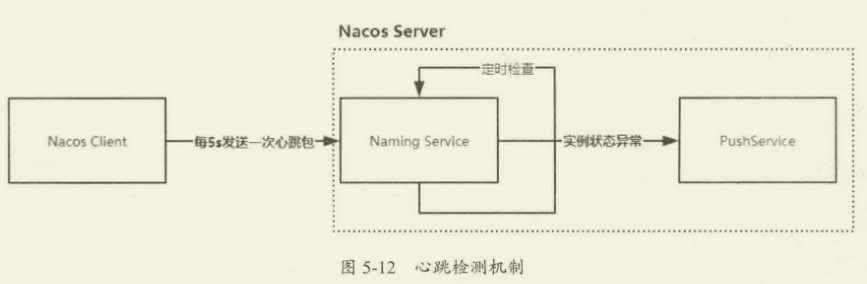
简单总结一下服务注册的完整过程:
- Nacos 客户端通过 Open API 的形式发送服务注册请求。
- Nacos 服务端收到请求后,做以下三件事:
- 构建一个 Service 对象保存到 ConcurrentHashMap 集合中。
- 使用定时任务对当前服务下的所有实例建立心跳检测机制。
- 基于数据一致性协议将服务数据进行同步。
服务供给
- 根据 namespaceld、serviceName 获得 Service 实例。
- 从 Service 实例中基于 srvIPs 得到所有服务提供者的实例信息。
- 遍历组装 JSON 字符串并返回。
服务感知
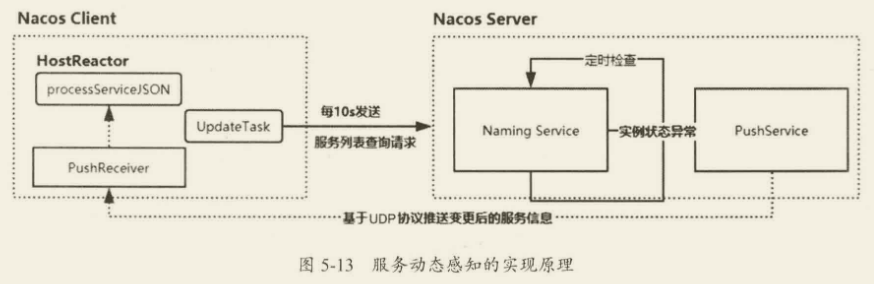
- 客户端发起事件订阅后,在 HostReactor 中有一个 UpdateTask 线程,每
10s发送一次 Pull 请求,获得服务端最新的地址列表。- 对于服务端,它和服务提供者的实例之间维持了心跳检测,一旦服务提供者出现异常,则会发送一个 Push 消息给 Nacos 客户端,也就是服务消费者。
- 服务消费者收到请求之后,使用 HostReactor 中提供的
processServiceJSON解析消息,并更新本地服务地址列表。
第六章、Nacos 实现统一配置管理
在 Spring Boot 项目中,默认会提供一个 application.properties 或者 application.yml 文件,我们可以把一些全局性的配置或者需要动态维护的配置写入该文件,比如数据库连接、功能开关、限流阈值、服务器地址等。为了解决不同环境下服务连接配置等信息的差异,Spring Boot 还提供了基于 spring.profiles.active={profile}的机制来实现不同环境的切换。随着单体架构向服务化架构及微服务架构的演进,各个应用自己独立维护本地配置的方式开始显露出它的不足之处:
- 配置的动态更新:在实际应用中会有动态更新配置的需求,比如修改服务连接地址、限流的配置等。在传统模式下,需要手动修改配置文件并且重启应用才能生效,这种方式效率太低,重启也会导致服务暂时不可用。
- 配置集中式管理:在微服务架构中,某些核心服务为了保证高性能会部署上百个节点,如果在每个节点中都维护一个配置文件,一旦配置文件中的某个属性需要修改,可想而知,工作量是巨大的。
- 配置内容的安全性和权限:配置文件随着源代码统一提交到代码库中,容易造成生产环境配置信息的数据泄露。
- 不同部署环境下配置的管理:前面提到过通过 profile 机制来管理不同环境下的配置,这种方式对于日常维护来说比较烦琐。
统一配置管理就是弥补上述不足的方法,简单来说,最基本的方法是把各个应用系统中的某些配置放在一个第三方中间件上进行统一维护。然后,对于统一配置中心上的数据的变更需要推送到相应的服务节点实现动态更新。所以在微服务架构中,配置中心也是一个核心组件。
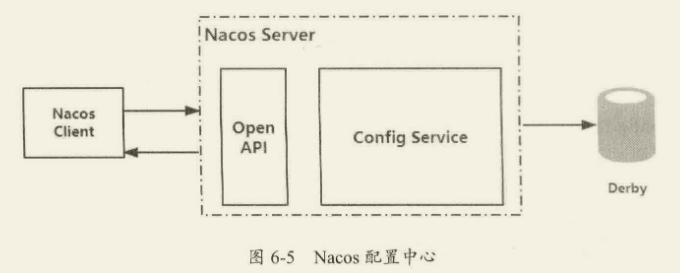
Nacos 配置中心简介
配置中心的开源解决方案很多,比如 ZooKeeper、Disconf、Apollo、Spring Cloud Config、QConf、Nacos 等。同样,不管是哪一种解决方案,它的核心功能是不会变的。
Nacos 是 Alibaba 开源的中间件,前面针对 Nacos 实现服务注册与发现功能进行了详细的分析。在 Nacos 的架构图中有两个模块,分别是 Config Service 和 Naming Service。其中 Config Service 就是 Nacos 用于实现配置中心的核心模块,它实现了对配置的 CRUD、版本管理、灰度管理、监听管理、推送轨迹、聚合数据等功能。我们主要围绕 Nacos 中的 Config Service 模块实现配置中心的功能进行深度的分析。
Nacos 集成 Spring Boot 实现统一配置管理
项目准备
首先,创建一个基于 Spring Boot 的项目,并集成 Nacos 配置中心,操作步骤如下。
创建一个 Spring Boot 工程 spring-boot-nacos-config。
添加 Nacos Config 的 Jar 包依赖。
1
2
3
4
5<dependency>
<groupId>com.alibaba.boot</groupId>
<artifactId>nacos-config-spring-boot-starter</artifactId>
<version>0.2.4</version>
</dependency>在 application.properties 中添加 Nacos Server 的地址。
1
nacos.config.server-addr=127.0.0.1:8848创建 NacosConfigController 类,用于从 Nacos Server 动态读取配置。
1
2
3
4
5
6
7
8
9
10
11@NacosPropertySource(dataId = "example", autoRefreshed = true)
@RestController
public class NacosConfigController {
@NacosValue(value = "${info:Local Hello World}", autoRefreshed = true)
private String info;
@GetMapping("/config")
public String get() {
return info;
}
}
@NacosPropertySource:用于加载 dataId 为 example 的配置源,autoRefreshed 表示开启自动更新。@NacosValue:设置属性的值,其中 info 表示 key,而 Local Hello World 代表默认值。也就是说,如果 key 不存在,则使用默认值。这是一种高可用的策略,在实际应用中,我们需要尽可能考虑到在配置中心不可用的情况下如何保证服务的可用性。
启动 Nacos Server
直接进入${NACOS_HOME}\bin 目录,执行 sh startup.sh 启动 Nacos Server 即可。
创建配置
创建配置有两种方式:
- 在 Nacos 控制台上创建
- 使用 Open API 方式创建
打开 nacos 控制台新建一个配置进行测试:
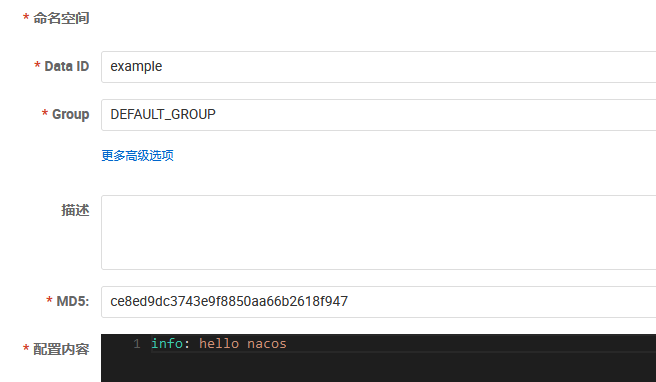
- Data ID: 表示 Nacos 中某个配置集的 ID,通常用于组织划分系统的配置集。
- Group: 表示配置所属的分组。
- 配置格式: 当前配置内容所遵循的格式。
启动服务并测试
执行 Spring Boot 项目的启动类:
1 | |
访问接口地址可以获得如下返回结果:Nacos Server Data: Hello World
Spring Cloud Alibaba Nacos Config
用过 Spring Cloud 的同学应该都知道,Spring Cloud Config 是 Spring Cloud 生态中的统一配置管理的组件,它为外部化配置提供了服务端和客户端支持,包含 Config Server 和 Config Client 两部分。而 Spring Cloud Alibaba Nacos Config 是 Config Server 和 Client 的替代方法。下面将演示如何基于 Spring Cloud 生态来集成 Nacos 实现配置中心。
Nacos Config 的基本应用
- 创建 Spring Boot 项目,添加 spring-.cloud-starter 依赖。
- 添加 Jar 包依赖。
1
2
3
4
5<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-config</artifactId>
<version>2.1.1.RELEASE</version>
</dependency> - 创建
bootstrap.properties/yml文件,并在 bootstrap.properties 中添加Nacos Server 的连接地址。1
2
3spring.application.name=spring-cloud-nacos-config-sample
spring.cloud.nacos.config.server-addr=127.0.0.1:8848
spring.cloud.nacos.config.prefix=example
[!NOTE] 配置说明
- spring.cloud.nacos.config.prefix 表示 Nacos 配置中心上的 Data ID 的前缀。
- spring.cloud.nacos.config.server-addr 设置 Nacos 配置中心的地址。如果地址是域名,配置的方式应该是域名:port,即便监听的端口是 80,也需要将 80 端口带上。
需要注意,这些配置项是需要放在 bootstrap.properties 文件中的。在 Spring Boot 中有两种上下文配置,一种是 bootstrap,另外一种是 application。bootstrap 是应用程序的父上下文,也就是说 bootstrap 加载优先于 application。由于在加载远程配置之前,需要读取 Nacos 配置中心的服务地址信息,所以 Nacos 服务地址等属性配置需要放在 bootstrap.properties 文件中。
在 Nacos Console 中创建如下配置。
DataId:example
Group:DEFAULT GROUP
配置内容:info = Nacos Server Data : Hello World在启动类中,读取配置中心的数据。
1
2
3
4
5
6
7@SpringBootApplication
public class SpringBootNacosConfigApplication {
public static void main(String[] args) {
ConfigurableApplicationContext context = SpringApplication.run(SpringBootNacosConfigApplication.class, args);
}
}启动应用程序进行测试,结果如下:
Nacos Server Data ':' Hello World
动态更新配置
配置中心必然需要支持配置的动态更新,也就是在配置中心上修改配置的值之后,应用程序需要感知值的变化。下面我们通过一段代码来演示动态更新的实现:
1 | |

基于 Data ID 配置 YAML 的文件扩展名
Spring Cloud Alibaba Nacos Config 从 Nacos Config Server 中加载配置时,会匹配 Data ID。在 Spring Cloud Nacos 的实现中,Data ID 默认规则是 ${prefix}-${spring.profile.active}.${file-extension}。
在默认情况下,会去 Nacos 服务器上加载 Data ID 以
${spring.application.name}.${file-extension:properties}为前缀的基础配置。比如在前面演示的代码中,我们在 bootstrap.properties 文件中配置了属性spring.application.name=spring-cloud-nacos-config-sample,在不通过 spring.cloud.nacos.config.prefix 指定 Data ID 前缀时,默认会读取 Nacos Config Server 中 Data ID 为 spring-cloud-nacos-config-sample.properties 的配置信息。如果明确指定了 spring.cloud.nacos.config.prefix=example 属性,则会加载 Data ID-example 的配置。
spring.profile.active 表示多环境支持,在后续的章节中会详细说明。
在实际应用中,如果大家用的是 YAML 格式的配置,Nacos Config 也提供了 YAML 配置格式的支持,执行步骤如下。在 bootstrap.properties 中声明 spring.cloud.nacos.config.file-extension=yaml。
在 Nacos 控制台上增加如下配置。
Data ID:spring-cloud-nacos-config-sample.yaml
Group: DEFAULT_GROUP
配置格式:YAML
配置内容:info: yaml config type运行启动方法,获得如下结果
不同环境的配置切换
配置加载顺序:
${spring.appliation.name}.${file-extension:properties} —> ${spring.application.name}-${profile}.${file-extension:properties}
基于 SpringBoot 项目的多环境支持配置步骤如下:
在 resources 目录下根据不同环境创建不同的配置
- application-dev.yml
- application-test.yml
- application-prod.yml
定义一个 appliaction.yml 默认配置,在该配置中通过
spring.profiles.active=${env}来指定当前使用哪个环境的配置,如果${env}的值为 prod,表示使用 application-prod.yml,也可以通过设置 VM options = -Dspring.profiles.active=prod 来指定使用的环境配置。
在 Spring Cloud Alibaba Nacos Config 中加载 Nacos Config Server 中的配置时,不仅加载了 Data ID 以 ${spring.appliation.name}.${file-extension:properties} 为前缀的基础配置,还会加载 Data ID 为 ${spring.application.name}-${profile}.${file-extension:properties} 的环境配置,这样的方式为不同环境的切换提供了非常好的支持。配置方式和 SpringBoot 相同,具体实现步骤如下:
在 bootstrap.yml 中声明 spring.profiles.active=prod,该项必须声明
在 Nacos 控制台上新增两个 Data ID 的配置项
- spring-cloud-nacos-config-sample-dev.yaml,配置内容为 info: dev env
- spring-cloud-nacos-config-sample-prod.yaml,配置内容为 info: prod env
启动应用程序进行测试,结果如下所示:
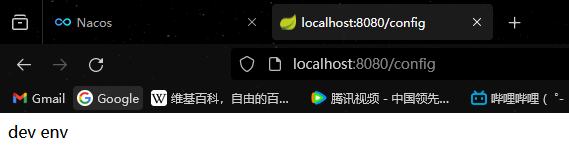
我们可以发现,基于 Nacos Config 实现不同环境的切换和本地配置的不同环境切换没有任何区别。
如果我们需要切换到测试环境,只需要修改 spring.profiles.active=test 即可。不过这个属性的配置是写死在
bootstrap.properties 文件中的,修改起来显得很麻烦。通常的做法是通过-Dspring.profiles.active=${profile}参数来指定环境,以达到灵活切换的目的。
Nacos Config 自定义 Namespace 和 Group
在前面的章节中使用 Nacos Config 时都采用默认的 Namespace:public 和 Group:DEFAULTGROUP,从名字我们基本能够猜测到它们的作用。我们看一下如图 6-2 所示的 Nacos 提供的数据模型,它的数据模型 Key 是由三元组来进行唯一确定的。
其中 Namespace 用于解决多环境及多租户数据的隔离问题,比如在多套不同的环境下,可以根据指定的环境创建不同的 Namespace,实现多环境的隔离,或者在多用户的场景中,每个用户可以维护自己的 Namespace,.实现每个用户的配置数据和注册数据的隔离。需要注意的是,在不同的 Namespace 下,可以存在相同的 Group 或 Datald。

Group 是 Nacos 中用来实现 Data ID 分组管理的机制,从图 6-2 可以看出,它可以实现不同 Service/Datald 的隔离。对于 Group 的用法,其实没有固定的规定,比如它可以实现不同环境下的 Datald 的分组,也可以实现不同应用或者组件下使用相同配置类型的分组,比如 database url。
官方的建议是,通过 Namespace 来区分不同的环境,而 Group 可以专注在业务层面的数据分组。最重要的还是提前做好规划,对 Namespace 和 Group 进行基本的定调,避免使用上的混乱。
了解了 Namespace 和 Group 的概念之后,下面讲一下 Spring Cloud Alibaba Nacos Config 如何实现自定义 Namespace 和 Group。
Namespace
- 在 Nacos 控制台的“命名空间”下,创建一个命名空间,如图 6-3 所示。
- 在 bootstrap.yml 中添加如下配置:567674b9-baf8-4a41-8e90-80c47925d527 对应的是 Namespace 中命名空间的 ID,这个值可以在如下图所示的界面获取。
1
2
3
4
5spring:
cloud:
nacos:
config:
namespace: 567674b9-baf8-4a41-8e90-80c47925d527 #test命名空间
Group
Group 不需要提前创建,只需要在创建的时候指定,配置方法如下。
- 在 Nacos 控制台的“新建配置”界面中指定配置所属的 Group,如图所示。

- 在 bootstrap.yml 中添加如下配置即可:Data ID
1
2
3
4
5spring:
cloud:
nacos:
config:
group: TEST_GROUP
Data ID 是 Nacos 中某个配置集的 ID,它通常用于组织划分系统的配置集。在前面的示例中我们都是通过配置文件的名字来进行配置的划分的,也可以通过 Java 包的全路径来划分,主要取决于 Data ID 的使用维度。
Spring Cloud Alibaba Nacos Config 同样支持自动以 Data ID 配置。在上述配置中,可以看到:1
2
3spring.cloud.nacos.config.ext-config[0].data-id=example.yml
spring.cloud.nacos.config.ext-config[0].group=DEFAULT_GROUP
spring.cloud.nacos.config.ext-config[0].refresh=true
spring.cloud.nacos.config.ext-config[n]支持多个 Data ID 的扩展配置,包含三个属性:data-id、group、refresh。
spring.cloud.nacos.config.ext-config[n].data-id 指定 Nacos Config 的 Data ID。
spring.cloud.nacos.config.ext-config[n].group 指定 Data ID 所在的组。
spring.cloud.nacos.config.ext-config[n].refresh 控制 Data ID 在配置发生变更时是否动态刷新,以感知最新的配置值。默认是 false,也就是不会实现动态刷新。
在使用过程中,有两个注意点:spring.cloud.nacos.config.ext-config[n].data-id 的值必须要带文件的扩展名,可以支持 properties、yaml、json 等。
spring.cloud.nacos.config.ext-config[n].data-id 配置多个 Data ID 时,n 的值越大,优先级越高。
通过自定义扩展的 Data Id 配置,既可以解决多个应用的配置共享问题,在支持一个应用有多个配置文件的情况。需要注意的是,在ext-config和${spring.application.name}.${file-extension:properties}都存在的情况下,优先级高的是后者。
Nacos Config 实现原理解析
在 Nacos Config 控制方面针对配置管理提供了4种操作。针对这4种操作,Nacos 提供了 SDK 及 Open API 的方式进行访问。
需要注意的是,Nacos 服务端的数据存储默认采用的是 Derby 数据库,除此之外,支持 MySQL 数据库。如果需要修改,可以参考第 5 章中关于 Nacos 集群部署部分,其中涉及 MySQL 数据库的配置。
配置自动刷新原理
一般来说,客户端和服务端之间的数据交互无非两种方式:Pull 和 Push。
- Pull 表示客户端从服务端主动拉取数据。
- Push 表示服务端主动把数据推送到客户端。
Nacos 采用的是 Pull 模式,但并不是简单的 Pull,而是一种长轮询机制,它结合 Push 和 Pull 两者的优势。客户端采用长轮询的方式定时发起 Pul 请求,去检查服务端配置信息是否发生了变更,如果发生了变更,则客户端会根据变更的数据获得最新的配置。所谓长轮询,是客户端发起轮询请求之后,服务端如果有配置发生变更,就直接返回,如下图所示。
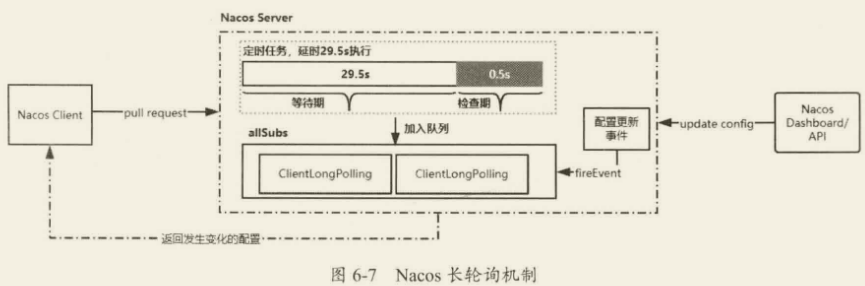
如果客户端发起 Pull 请求后,发现服务端的配置和客户端的配置是保持一致的,那么服务端会先“Hol”住这个请求,也就是服务端拿到这个连接之后在指定的时间段内一直不返回结果,直到这段时间内配置发生变化,服务端会把原来“Hold”住的请求进行返回,如上图所示,Ncos 服务端收到请求之后,先检查配置是否发生了变更,如果没有,则设置一个定时任务,延期 29.5s 执行,并且把当前的客户端长轮询连接加入 allSubs 队列。这时候有两种方式触发该连接结果的返回:
- 第一种是在等待 29.5s 后触发自动检查机制,这时候不管配置有没有发生变化,都会把结果返回客户端。而 29.5s 就是这个长连接保持的时间。
- 第二种是在 29.5s 内任意一个时刻,通过 Nacos Dashboard 或者 API 的方式对配置进行了修改,这会触发一个事件机制,监听到该事件的任务会遍历 allSubs 队列,找到发生变更的配置项对应的 ClientLongPolling 任务,将变更的数据通过该任务中的连接进行返回,就完成了一次“推送”操作。
第七章、基于 Sentinel 的微服务限流及熔断
第八章、分布式事务
第九章、RocketMQ 分布式消息通信
在微服务架构下,一个业务服务会被拆分成多个微服务,各个服务之间相互通信完成整体的功能。系统间的通信协作通常有两种。
- Http/RPC 通信:优点是通信实时,缺点是服务之间的耦合性高。
- 消息通信:优点是降低了服务之间的耦合性,提高了系统的处理能力,缺点是通信非实时。(消息不要求实时处理、一份数据多处使用(不同消费方消费速度不同)的场景)
例如,用户交易完成后发送短信通知,假设交易耗时 5ms,发短信耗时 3ms。如果是实时通信,那么用户收到返回结果耗时 8s,但发短信是非核心步骤,可以从主流程中剥离出来异步处理,那么用户收到返回结果耗时就可以从 8ms 下降到 5ms。
初识 RocketMQ
RocketMQ 是一个低延迟、高可靠、可伸缩、易于使用的分布式消息中间件(也称消息队列),经过阿里巴巴多年双 I1 的验证,是由阿里巴巴开源捐献给 Apache 的顶级项目。RocketMQ 具有高吞吐、低延迟、海量消息堆积等优点,同时提供顺序消息、事务消息、定时消息、消息重试与追踪等功能,非常适合在电商、金融等领域广泛使用。
RocketMQ 基本概念
- 生产者(Producer):也称为消息发布者,是 RocketMQ 中用来构建并传输消息到服务端的运行实体。
- 主题(Topic):Topic 是 RocketMQ 中消息传输和存储的顶层容器,用于标识同一类业务逻辑的消息;Topic 是一个逻辑概念,并不是实际的消息容器;
- 消息队列(MessageQueue):队列是 RocketMQ 中消息存储和传输的实际容器,也是消息的最小存储单元。
- 消费者(Consumer):也称为消息订阅者,是 RocketMQ 中用来接收并处理消息的运行实体。
- 消费者组(ConsumerGroup):消费者组是 RocketMQ 中承载多个消费行为一致的消费者负载均衡分组。和消费者不同,消费者组是一个逻辑概念。
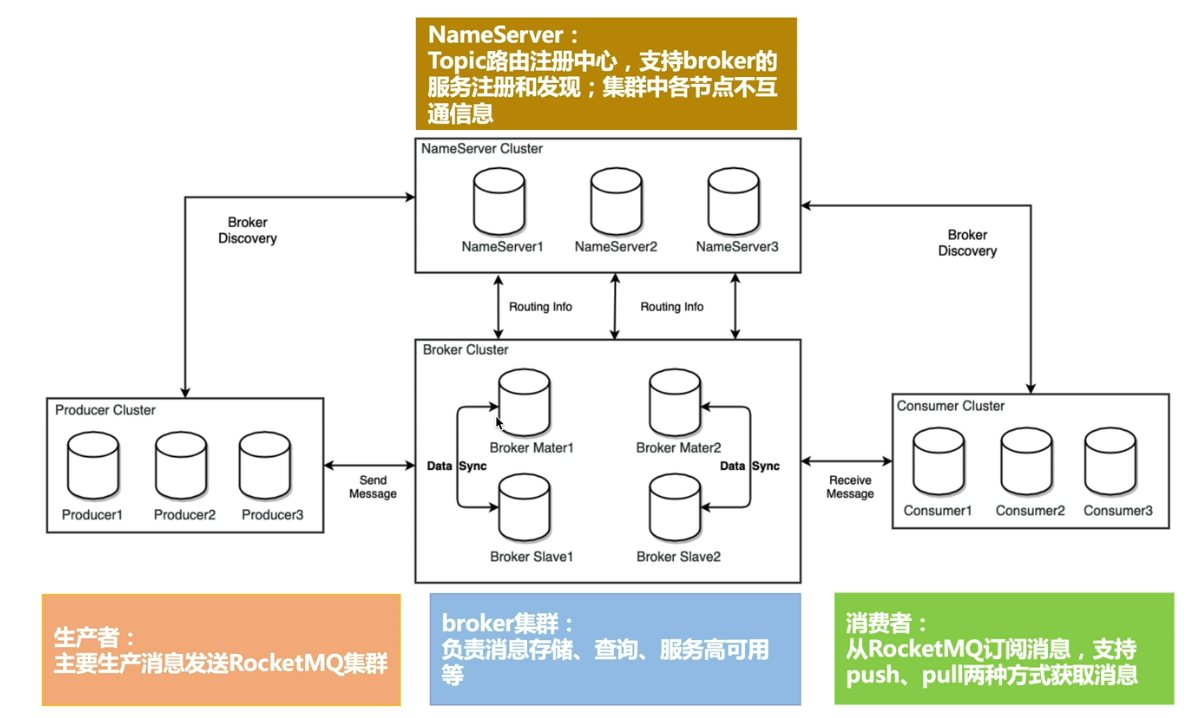
- NameServer:可以理解成注册中心,负责更新和发现 Broker 服务。在 NameServer 的集群中,NameServer 与 NameServer 之间是没有任何通信的,它是无状态的。
- Broker:可以理解为消息中转角色,负责消息的存储和转发,接收生产者产生的消息并持久化消息;当用户发送的消息被发送到 Broker 时,Broker 会将消息转发到与之关联的 Topic 中,以便让更多的接收者进行处理。
主流消息队列
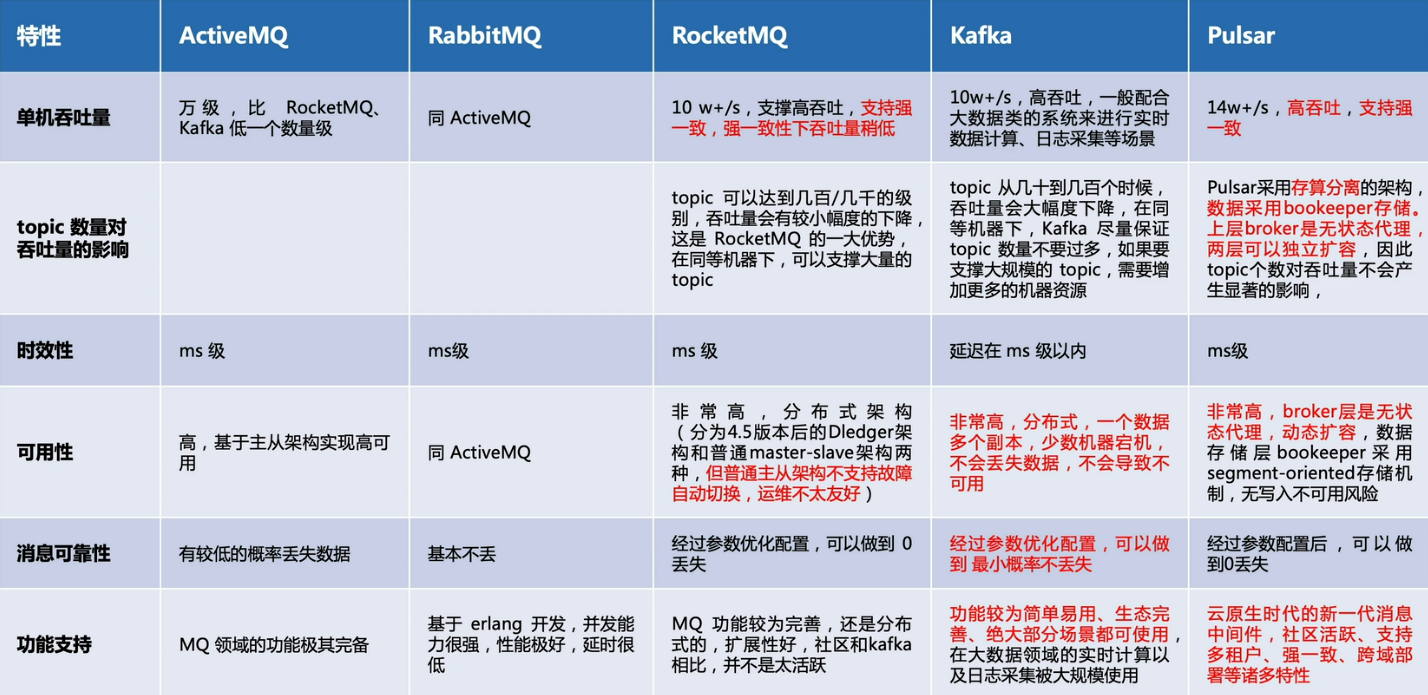
数据磁盘组织的几种模型
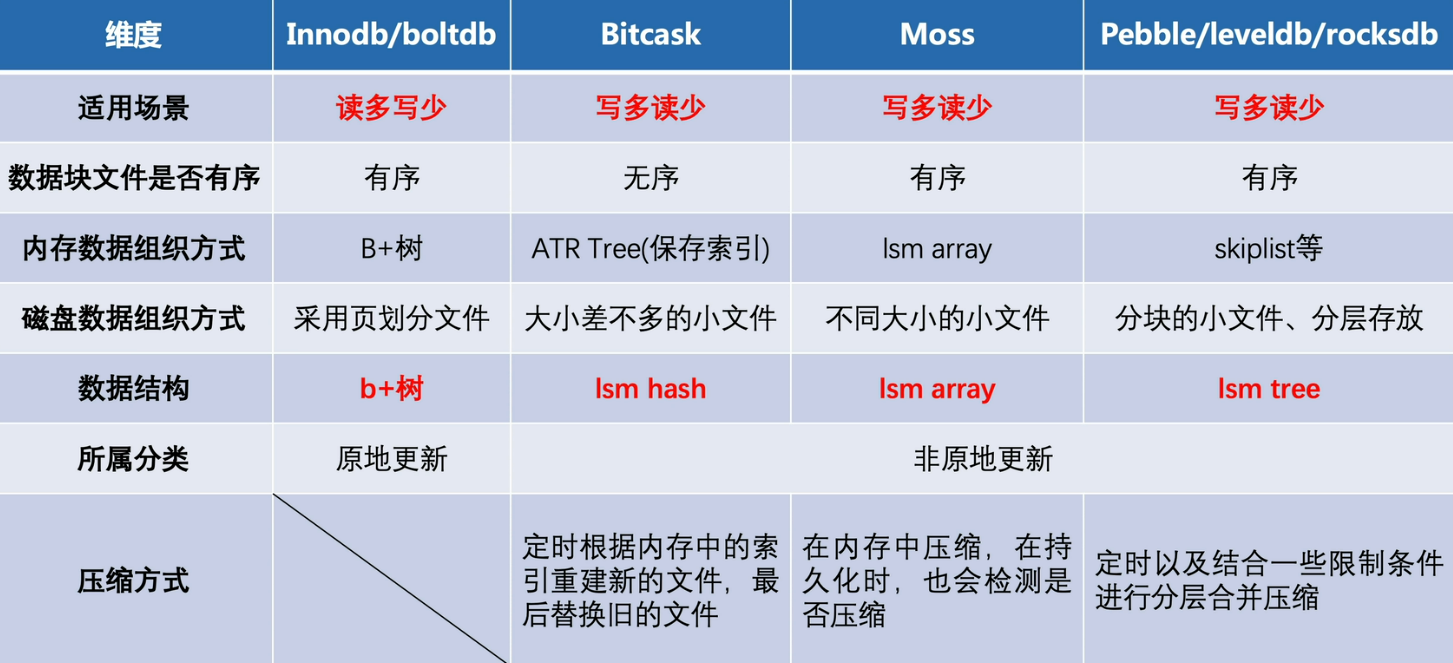
消息队列核心模型

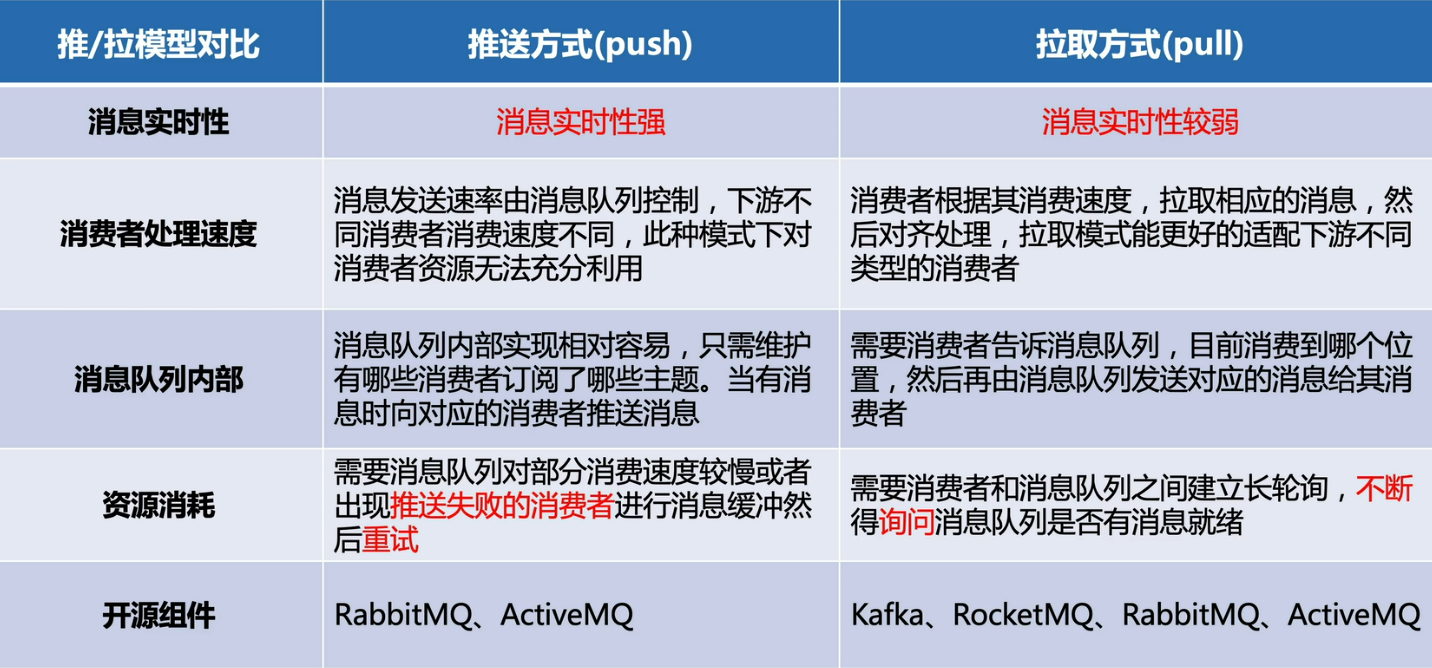
推/拉模型区别
消费者消费模型(1:N:M)
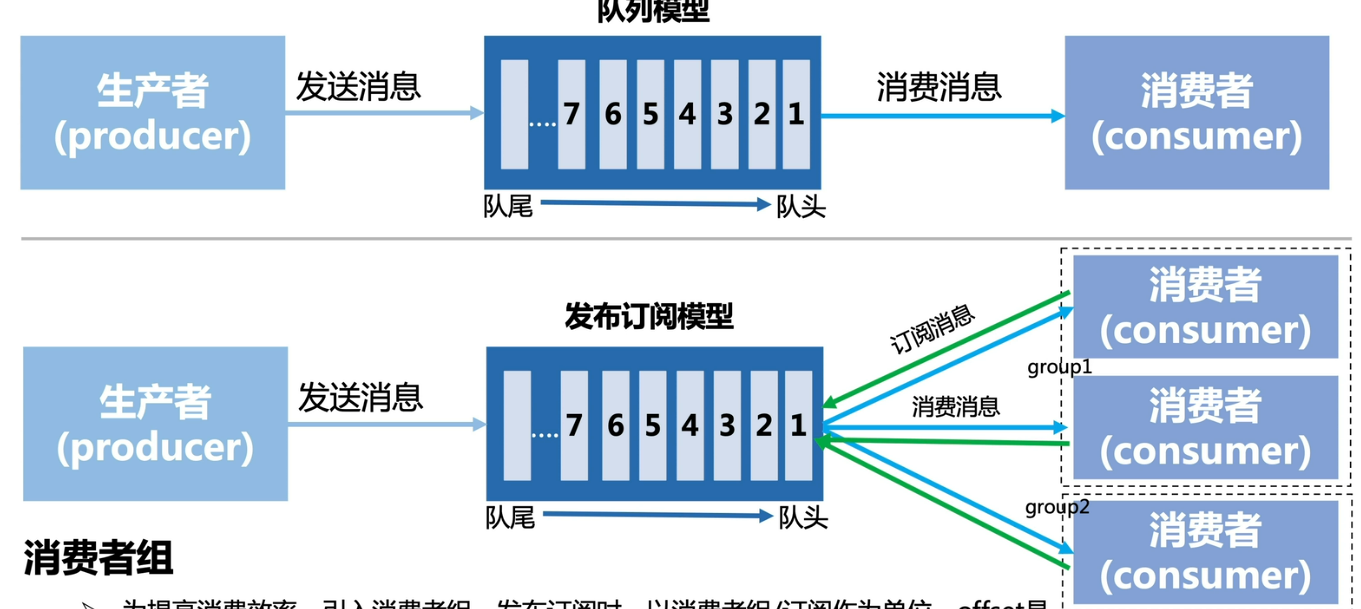
消费者组:为提高消费效率、引入消费者组,发布订阅时,以消费者组/订阅作为单位。offset 是以(group+topic+partition)为单位维护。组间广播、组内单播
kafka 和 RocketMQ 数据组织对比
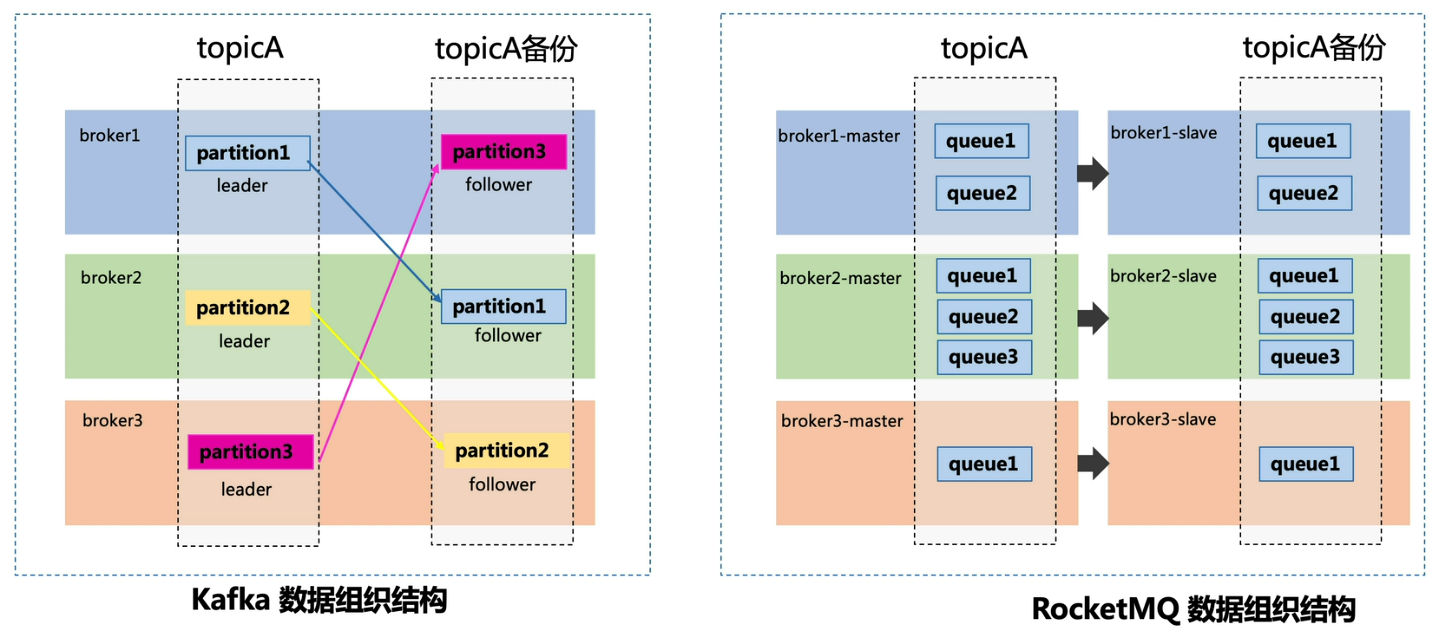
RocketMQ 的应用场景
RocketMO 的应用场景如下。
- 削峰填谷:诸如秒杀、抢红包、企业开门红等大型活动皆会带来较高的流量脉冲,很可能因没做相应的保护而导致系统超负荷甚至崩溃,或因限制太过导致请求大量失败而影响用户体验,RocketMO 可提供削峰填谷的服务来解决这些问题。
- 异步解耦:交易系统作为淘宝/天猫主站最核心的系统,每笔交易订单数据的产生会引起几百个下游业务系统的关注,包括物流、购物车、积分、流计算分析等,整体业务系统庞大而且复杂,RocketMQ 可实现异步通信和应用解耦,确保主站业务的连续性。
- 顺序收发:细数一下,日常需要保证顺序的应用场景非常多,例如证券交易过程中的时间优先原则,交易系统中的订单创建、支付、退款等流程,航班中的旅客登机消息处理等。与先进先出(First In First Out,缩写 FIFO)原理类似,RocketMQ 提供的顺序消息即保证消息的 FIFO。
- 分布式事务一致性:交易系统、红包等场景需要确保数据的最终一致性,大量引入 RocketMQ 的分布式事务,既可以实现系统之间的解耦,又可以保证最终的数据一致性。
- 大数据分析:数据在“流动”中产生价值,传统数据分析大都基于批量计算模型,无法做到实时的数据分析,利用 RocketMQ 与流式计算引擎相结合,可以很方便地实现对业务数据进行实时分析。
- 分布式缓存同步:天猫双 11 大促,各个分会场琳琅满目的商品需要实时感知价格的变化,大量并发访问会导致会场页面响应时间长,集中式缓存因为带宽瓶颈限制商品变更的访问流量,通过 RocketMQ 构建分布式缓存,可实时通知商品数据的变化。
RocketMQ 的安装
rocketmq 的安装教程由各种环境配置可见。
RocketMQ 基本用法
RocketMQ 发送消息
Spring Cloud Alibaba 已集成 RocketMQ,使用 Spring Cloud Stream 对 RocketMQ 发送和接收消息。
- 在 pom.xml 中引入 Jar 包。
1 | |
- 配置 application.yml。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18server:
port: 8081
spring:
cloud:
stream:
rocketmq:
binder:
name-server: 8.130.88.159:9876
bindings:
input:
destination: TopicTest
group: TestGroup
output:
content-type: application/json
destination: TopicTest
group: TestGroup
application:
name: rocketmq-producer
name-server 指定 RocketMQ 的 NameServer 地址,将指定名称为 output 的 Binding 消息发送到 TopicTest。
3. 使用 Binder 发送消息。
1 | |
@EnableBinding({Source.class}) 表示绑定配置文件中名称为 output 的消息通道 Binding,Source 类中定义的消息通道名称为 output。发送 HTTP 请求 http:/localhost:8081/send?msg=tcever 将消息发送到 RocketMQ 中。
在实际开发场景中会存在多个发送消息通道,可以自定义消息通道的名称,参考 Source 类自定义一个接口,修改通道名称和相关配置即可。
1 | |
修改配置文件添加 orderOutput 消息通道:
1 | |
到此,就可以添加一个自定义发送消息通道,使用 orderOutput 消息发送到 TopicOrder 中了。
RocketMQ 消费消息
RocketMQ 消费消息的步骤如下。
- pom.xml 中引入 Jar 包。
1
2
3
4
5
6
7
8<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-stream-binder-rocketmq</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency> - 配置 application.yml:
1
2
3
4
5
6
7
8
9
10
11
12
13
14server:
port: 8082
spring:
cloud:
stream:
rocketmq:
binder:
name-server: 8.130.88.159:9876
bindings:
input:
destination: TopicOrder
group: order-group
application:
name: rocketmq-consumer
name-server 指定 RocketMQ 的 NameServer 地址,destination 指定 Topic 名称,指定名称为 input 的 Binding 接收 TopicOrder 的消息。
3. 定义消息监听:
1 | |
@EnableBinding({Sink.class}) 表示绑定配置文件中名称为 input 的消息通道 Binding,Sink 类中定义的消息通道的名称为 input, @StreamListener 表示定义一个消息监听器,接收 RocketMQ 中的消息。
在实际开发场景中同样会存在多个接收消息通道,可以自定义消息通道的名称,参考 Sink 类自定义一个接口,修改通道名称和相关配置即可。
1 | |
接下来修改配置文件添加自定义的接收消息通道绑定主题和分组:
1 | |
在自定义的 InputChannel 类中定义了两个接收消息通道,使用 orderInput 会收到 TopicOrder 中的消息。
访问消息生产者的接口发送消息,消费者对指定主题的消息进行订阅监听结果如下图所示:
Spring Cloud Alibaba RocketMQ
Spring Cloud Stream 是 Spring Cloud 体系内的一个框架,用于构建与共享消息传递系统连接的高度可伸缩的事件驱动微服务,其目的是简化消息业务在 Spring Cloud 应用程序中的开发。
Spring Cloud Stream 的架构图如图下图所示,应用程序通过 Spring Cloud Stream 注入的输入通道 inputs 和输出通道 outputs 与消息中间件 Middleware 通信,消息通道通过特定的中间件绑定器 Binder 实现连接到外部代理。
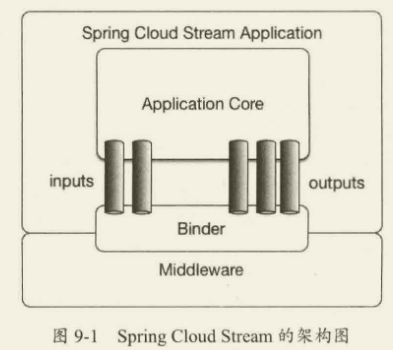
Spring Cloud Stream 的实现基于发布/订阅机制,核心由四部分构成:Spring Framework 中的 Spring Messaging 和 Spring Integration,以及 Spring Cloud Stream 中的 Binders 和 Bindings。
Spring Messaging:Spring Framework 中的统一消息编程模型,其核心对象如下。
- Message:消息对象,包含消息头 Header 和消息体 Payload。
- MessageChannel:消息通道接口,用于接收消息,提供 send 方法将消息发送至消息通道。
- MessageHandler:消息处理器接口,用于处理消息逻辑。
Spring Integration:Spring Framework 中用于支持企业集成的一种扩展机制,作用是提供一个简单的模型来构建企业集成解决方案,对 Spring Messaging 进行了扩展。 - MessageDispatcher:消息分发接口,用于分发消息和添加删除消息处理器。
- MessageRouter:消息路由接口,定义默认的输出消息通道。
- Filter:消息的过滤注解,用于配置消息过滤表达式。
- Aggregator:消息的聚合注解,用于将多条消息聚合成一条。
- Splitter:消息的分割,用于将一条消息拆分成多条。
Binders:目标绑定器,负责与外部消息中间件系统集成的组件。 - doBindProducer:绑定消息中间件客户端发送消息模块
- doBindConsumer:绑定消息中间件客户端接收消息模块。
Bindings:外部消息中间件系统与应用程序提供的消息生产者和消费者(由 Binders 创建)之间的桥梁。 - Spring Cloud Stream 官方提供了 Kafka Binder 和 RabbitMQ Binder,用于集成 Kafka 和 RabbitMQ。
- Spring Cloud Alibaba 中加入了 RocketMQ Binder,用于将 RocketMQ 集成到 Spring Cloud Stream。
Spring Cloud Alibaba RocketMQ 架构图
RocketMQ 部署模型
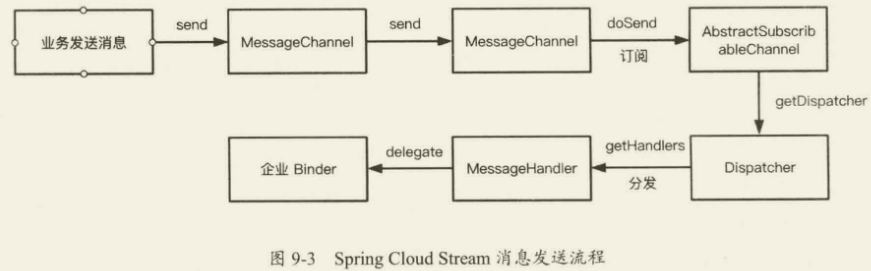
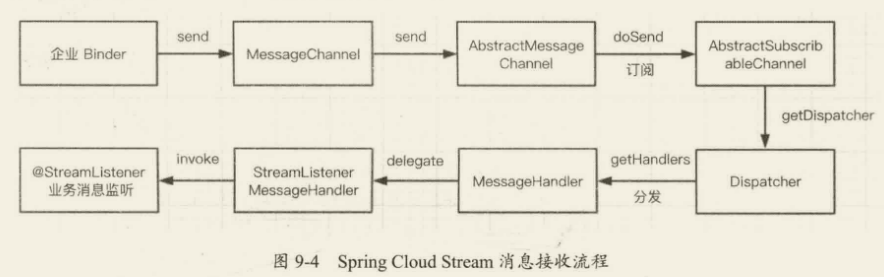
Spring Cloud Stream 消息发送和订阅流程
快速入门
RocketMQ 提供了发送多种发送消息的模式,例如同步消息,异步消息,顺序消息,延迟消息,事务消息等。
消息发送和监听的流程
消息生产者
- 创建消息生产者 producer,并制定生产者组名
- 指定 Nameserver 地址
- 启动 producer
- 创建消息对象,指定主题 Topic、Tag 和消息体等
- 发送消息
- 关闭生产者 producer
消息消费者
- 创建消费者 consumer,制定消费者组名
- 指定 Nameserver 地址
- 创建监听订阅主题 Topic 和 Tag 等
- 处理消息
- 启动消费者 consumer
消费模式
MQ 的消费模式可以大致分为两种,一种是推 Push,一种是拉 Pull。
Push 是服务端主动推送消息给客户端,优点是及时性较好,但如果客户端没有做好流控,一旦服务端推送大量消息到客户端时,就会导致客户端消息堆积甚至崩溃。
Pull 是客户端需要主动到服务端取数据,优点是客户端可以依据自己的消费能力进行消费,但拉取的频率也需要用户自己控制,拉取频繁容易造成服务端和客户端的压力,拉取间隔长又容易造成消费不及时。
Push 模式也是基于 pull 模式的,只是客户端内部封装了 api,一般场景下,上游消息生产量小或者均速的时候,选择 push 模式。在特殊场景下,例如电商大促,抢优惠券等场景可以选择 pull 模式
RocketMQ 发送同步消息
同步消息发送过后会有一个返回值,也就是 mq 服务器接收到消息后返回的一个确认,这种方式非常安全,但是性能上并没有这么高,而且在 mq 集群中,也是要等到所有的从机都复制了消息以后才会返回,所以针对重要的消息可以选择这种方式
RocketMQ 发送异步消息
异步消息通常用在对响应时间敏感的业务场景,即发送端不能容忍长时间地等待 Broker 的响应。发送完以后会有一个异步消息通知。
异步消息生产者
RocketMQ 发送单向消息
这种方式主要用在不关心发送结果的场景,这种方式吞吐量很大,但是存在消息丢失的风险,例如日志信息的发送
1 | |
RocketMQ 发送延迟消息
消息放入 mq 后,过一段时间,才会被监听到,然后消费比如下订单业务,提交了一个订单就可以发送一个延时消息,3min 后去检查这个订单的状态如果还是未付款就取消订单释放库存。
1 | |
RocketMQ 发送顺序消息
消息有序指的是可以按照消息的发送顺序来消费(FIFO)。RocketMQ 可以严格的保证消息有序,可以分为:分区有序或者全局有序。
可能大家会有疑问,mg 不就是 FIF0吗?
rocketMq 的 broker 的机制,导致了 rocketMq 会有这个问题
因为一个 broker 中对应了四个 queue
RocketMQ 发送批量消息
Rocketmq 可以一次性发送一组消息,那么这一组消息会被当做一个消息消费。
1 | |
RocketMQ 发送事务消息
RocketMQ 发送带标签的消息
参考书籍
- Spring Cloud Alibaba 微服务原理与实战 (豆瓣)
- 微信公众平台
- 消息队列专题(RabbitMQ、Kafka、RocketMQ、Pulsar)_哔哩哔哩_bilibili
- 动力节点RocketMQ全套视频教程-5小时学会rocketmq消息队列_哔哩哔哩_bilibili
1 | |
1 | |