周会
本文最后更新于:1 个月前

1 2023-10-7(项目例会)
- 从开始就将每个任务细节想好怎么做,防止后续出现问题
- 学习任何技术,了解其特点,包括优劣势,帮助后续技术选型架构,保证针对需求最合适
- 多读论文,写论文投稿,根据反馈意见不断修改调整,提高自己撰写论文能力水平,为毕业论文打好基础
2 2023-10-13(学术例会)
2.1.1 基于实体关系对齐的知识融合
2.1.2 UIE 结合大模型基底进行信息抽取
- 法律法规知识图谱与司法案件知识图谱双图谱,探究两者之间的关系进行知识融合
- 首先,通过聆听开始两位学长的学术汇报分享以及后续各位老师和学长学姐们对国家自然科学基金项目的讨论,让我对知识图谱领域有了一定的认知和了解,为未来的学术学习和研究指明了方向。
3 2023-10-15(项目例会)
- 已学内容
- 学习 Java 初级中级和高级知识点(多态,Lambda 表达式,反射,注解,JDBC,多线程等)
- 学习 Idea 和 Navicat 的使用(熟悉 Java 程序编写和数据库软件的常见操作)
- 了解国家自然科学基金面上项目研究内容(了解研究背景,研究内容,技术路线等)
- 下周计划
- 学习 Spring 相关知识点
- 阅读实验室研究方向相关学术综述论文
- 思考感悟
- 类对象非静态方法才存在多态,类方法(即静态方法)不存在多态(被子类重写叫隐藏)。
- IO 中有很多输入输出流,包括字节流、字符流、缓存流、数据流和对象流等要注意区分。
- 泛型提高复用性,对类、方法等使用泛型可以提高泛化能力,减少重复逻辑实现。
- Lambda 表达式即匿名方法,通过作用域函数型接口代替匿名类来简化代码,通常结合 Stream 流使用提高开发效率。
- Stream 流是函数型接口的具体实践为集合类流水线的方式处理其中元素,首先将集合转换为 Stream 然后经过中间一系列筛选或转换,最后得到需要的结果。
- 多线程可以充分利用 CPU 进行多任务并行执行,但要注意线程安全,可以通过 Synchronized 和 Lock 锁实现同步效果,多线程开发中应当使用 Vector、HashTable 等线程安全的容器,内部已经实现了同步保证线程安全。
- JDBC 是实现 Java 与数据库进行交互的方式,可以在 Java 中使用 SQL 语句完成数据库的相关操作,实现持久存储的特定任务。
- 反射通过获取唯一的类对象从而创建实例或者获取类的属性和方法并对其进行操作,可以通过反射解析获取到注解中的信息,基于此他们在 Spring 框架的原理实现当中发挥着重要作用
- 指导建议:
- idea 调试方法,lambda 调试方法
- 学习过程中做 Demo
- 学习 Spring 框架,核心是 IOC 和 AOP
1 | |
图神经网络(Graph Neural Networks,GNN)综述 - 知乎
4 2023-10-20(学术例会)
4.1.1 知识图谱综述(张龙)
4.1.1.1 文章来源
标题:A Survey on Knowledge Graphs: Representation, Acquisition, and Applications
期刊:AAAI 2020
作者:Shaoxiong Ji, Shirui Pan, Erik Cambria, Pekka Marttinen, Philip S. Yu
4.1.1.2 阅读理由
阅读该论文的理由,该论文有什么值得看的价值,可以获取到哪些有用的信息,我需要从中学习到的东西(创新点、研究方向、领域背景、方法论等)
推荐理由:本文详细介绍了知识图谱表示学习、知识获取与完成、时间知识图谱、知识感知应用等方面的技术和未来的研究方向。
4.1.1.3 注意事项
- 梳理各个重点的作用,相互联系
- 绘制相应流程图
- 不需要详细阐述具体某个原理性知识,聚焦综述
- 多个参考文献则写在最后,并在文中引用
4.1.1.4 主要研究方向
知识获取
从非结构化文本和其他结构化或半结构化源中构建知识图谱- 知识图谱补全:用于扩展现有知识图谱
- 基于嵌入的排序
- 关系路径推理
- 逻辑规则推理
- 元关系学习
- 实体识别/获取/发现:用于从又本中友现面可头体的新知识。
- 实体识别
- 消除歧义
- 实体类型
- 实体对齐
- 关系提取
- 知识图谱补全:用于扩展现有知识图谱
知识表示学习
- 表示空间
- 点态空间、流形、复向量空间、高斯分布和离散空间
- 评分函数
- 基于距离和相似性匹配的评分函数
- 编码模型
- 对事实的语义交互建立模型:线性/双线性模型、因子分解和神经网络
- 嵌入辅助信息
- 外部信息:文本、视觉和类型信息
- 表示空间
时间知识图谱
知识感知应用
4.1.2 大模型数据集研究(何雨欣)
[[司法领域大模型调研一]]
4. CIFA 数据集
5. 复旦大学 DISC 数据集![]()
大模型数据集存在什么问题
4.1.3 INF
几个大部分(科学问题)
6. 知识图谱构建
7. 双图谱融合协同增强
8. 大模型与图谱双向促进
每个科学问题其中可以阐述一些应用。
5 2023-10-22(项目例会)
[!NOTE] 周会总结
- 已学内容:
- JavaWeb 相关核心知识内容(Tomcat 服务器,数据库基础,Lombok,Mybatis,Maven,Servlet,Cookie,Session 等)
- 司法大模型相关调研工作(国内研究现状和存在问题)
- 下周计划:
- 学习 Spring 核心知识(IOC、AOP)
- 继续调研完善司法大模型应用现状
- 学习感悟:
- Tomcat 服务器:他是一个 Web 应用服务器,可以快速部署我们的 Web 项目,并交由 Tomcat 进行管理,我下载了该服务器并进行了测试,需要先将应用程序打包为 war 包并放入 webapp 文件夹,在启动 tomcat 服务时会自动解压 war 包从而提供服务。常见的 web 服务器还有 apache,nginx,IIS 等。
- 数据库基础:学习了包括 DDL(数据库定义语言,建【create database repository】删【drop database repository】库,增【create table tname(fn type cons)】删【drop table】改【alter table】表等指令),DML(数据库操纵语言,增【insert into table()values()】删【delete from table】改【update table set】数据),DQL(数据库查询语言,单表多表查询【多表查询包括 inner join 返回两个表笛卡尔积交集数据、left join 返回左表所有记录和交集数据、right join 返回所有右表记录和交集数据】、排序【order by field asc|desc】聚集【count、sum、avg、max、min】分组【group by field】分页【limit (起始位置), 数量】),DCL(数据库控制语言,如创建用户并授权),索引,事务(ACID)
- Lombok:通过注解自动化生成 Java 类的样板代码,比如@Data 注解自动生成 getter、setter、equals、hashCode 和 toString 方法,达到简洁,高效的目的。
- Mybatis:它是一个 ORM 半自动框架,将关系型数据库中的数据映射到对象模型中,从而实现数据库操作与对象操作的无缝转换,使用方式:依赖注入>配置文件编写>mapper 接口(通过注解执行 sql 指令)
- Maven:它是一个项目管理工具,方便管理项目依赖、构建项目、运行测试、生成文档等,pom 全局配置文件的依赖主要由
groupId,artifactId 和 version组成,常用clean、test、package等生命周期函数清理 target 文件夹,运行测试方法,打包成 jar 包等。- Servlet:它用于动态网页响应,通过
@WebServlet进行注册,在 WebServlet 注解中配置路由,初始化参数,然后继承HttpServlet重写 doGet/doPost 等方法对请求进行处理并作出响应,还可以进行重定向和请求转发等操作,实现动态网页数据交互。其中较为关键的ServletContext对象,它是属于属于整个 Web 应用程序的,可以用于全局数据传递(set/getAttribute),请求转发(getRequestDispatcher)等。- Cookie和Session:都是在 Web 开发中用于跟踪用户状态和保持用户信息的两种常见机制。
- Cookie(HTTP Cookie)是服务器发送到用户浏览器并存储在用户本地计算机上,由浏览器管理,包含了一些关于用户的信息,例如用户的身份认证、偏好设置等。可以设置过期时间,关闭浏览器后仍然保留,并且不同页面之间共享。
- Session 是服务器端的机制,由服务器进行管理,用于在服务器上存储和跟踪用户的状态信息。当用户访问网站时,服务器会为该用户创建一个唯一的会话标识(Session ID),并将该标识存储在服务器上。然后,服务器将 Session ID 通常通过 Cookie 发送给浏览器,与 Cookie 不同的是Session 数据存储在服务器用户无法直接修改,并且浏览器关闭后会自动销毁。
- 指导建议:
- sessionID 除了浏览器不同会重新生成,还有别的方式吧
- 汇报重点做了什么有什么思考想法见解,比如学完了什么学了多少,我认为什么比较重要,进行简洁总结,根据听讲人介绍,不需要介绍知识点,范围程度理解。
6 2023-10-27(学术例会)
6.1 结构感知预训练语言模型 SAILER
汇报人:杨东波
解决方法:
- SAILER 采用编码器-解码器架构来建模和捕获事实与案例文档的其他部分之间的依赖关系。
- SAILER 利用推理和决策段落中的法律知识来增强对关键的法律要素的理解
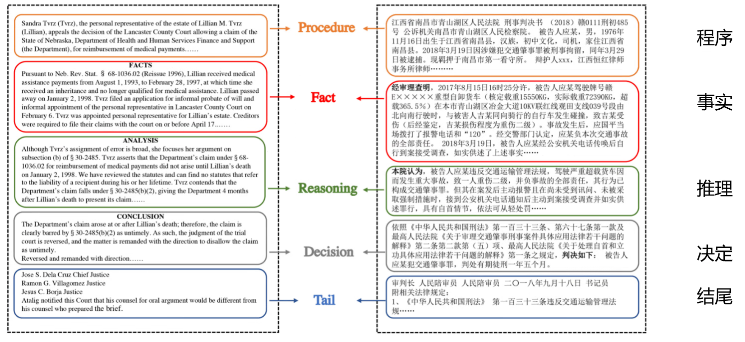
总结:
本文提出了一种新的结构感知预训练语言模型 SAILER,用于法律的案例检索。SAILER 的核心思想是充分利用法律的案例文档的结构关系进行预训练。通过重构关键法律的要素和判决结果:SAILER 生成了更好的法律的案例表征,具有更强的判别能力。通过对四个基准法律的数据集进行广泛的实验 SAILER 在低资源和全资源环境下都取得了显著的改进。在未来,我们希望探索将更多的专业知识,如法律的知识图和法律文章,纳入预先训练的语言模型,以更好地检索法律的案例。
注意:
- 汇报人,来源,作者,作者信息,期刊来源
- markdown 的需要上传到 gitlab 上直接预览讲解
6.2 LegalGNN: Legal Information Enhanced GraphNeural Network for Recommendation
汇报人:康志求
6.3 国基金讨论
- 大模型生成数据,提升数据质量。大模型生成数据作为训练数据,即便存在问题也可以说明,存在幻觉问题。
- 司法数据集已经有很多公开的数据集了,并不存在数据稀疏。

- 大模型对知识图谱数据的获取方面有哪些研究。
- 司法数据隐私安全方面,联邦学习是否可以解决。
- 数据时效性,数据动态更新问题,如何更新,更新效率,高低频案件变化问题。
- 时序知识图谱看能否运用。
7 2023-10-29(项目例会)
[!NOTE] 周会总结
- 已学内容:
- SpringIOC、AOP 和 EL 表达式等
- 调研国基金项目研究背景
- 下周计划:
- 继续学习 Spring 剩余内容,包括 springboot (含 MWC 设计思想),整合 mybatis
- 进一步调研国基金国内外研究现状部分
- 学习感悟:
- Spring 方面:Spring 框架通过模块化的设计和丰富的集成服务相较于传统的 javaweb 更加灵活、方便,易于扩展和维护,核心在于 IOC 容器代替原来直接 new 的方式实现对象的创建、依赖关系的管理和生命周期的控制,只需要更改 bean 即可修改逻辑功能避免重构原有大量代码。其次,AOP 通过代理原有的方法实现不同的增强效果,目的在于不破坏原有代码的基础上进行增强处理,例如:spring 的异步任务的实现底层就是进行了 AOP 增强添加了一个新的线程。而 SpEL 表达式则可以让我们更加灵活的使用 Spring,可以实现 bean 的属性注入、获取和管理等。
- 国基金方面:之前调研的大多是司法知识图谱构建应用方面的研究现状,对基础数据方面的现状调研的还不够全面,可以从大模型与知识图谱数据协同构建、数据隐私安全、数据时效及更新等方面展开进一步调研。
- 指导建议:
- 学习 SpringBoot 结合 Mybatis 进行学习实践
8 2023-11-03(学术例会)
8.1 事件抽取
汇报人:王忆宁![]()
8.1.1 抽取范式
- PipeLine:顺序抽取->识别触发词》触发词分类》论元识别》论元分类,即便存在误差传播,但是能够有效识别触发词,因此适用于司法领域。
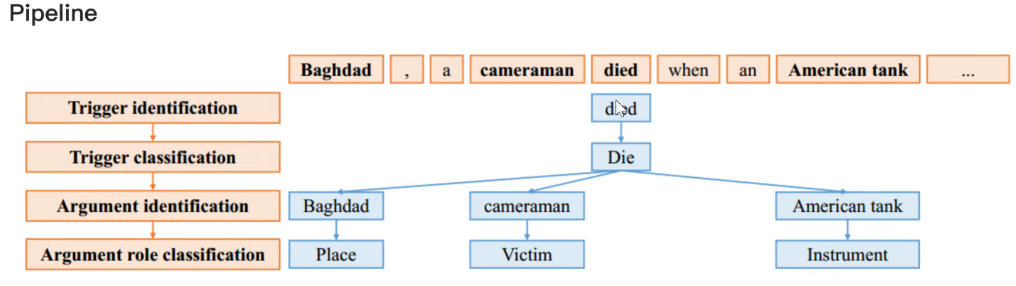
- 联合抽取:关注于抽取论元能够挖掘潜在的关系,但是容易忽略触发词,但司法领域触发词至关重要,所以该方法不适用于司法领域事件抽取。
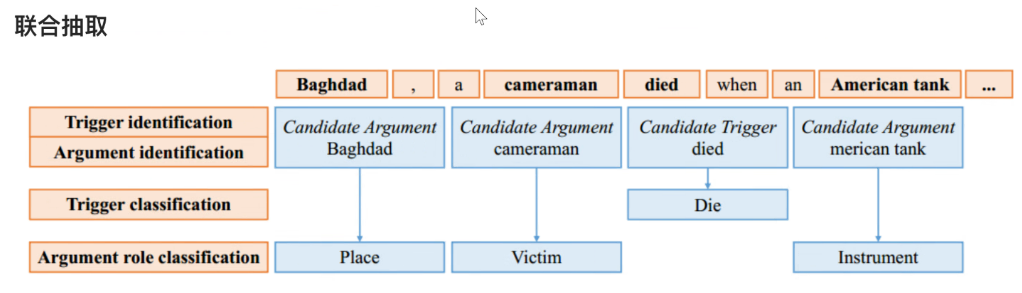
8.1.2 根据模型类型分类
- 基于 CNN
- 基于 RNN
- 基于 GNN
- 基于Transformer(目前最核心)
8.1.3 特定场景
1. 文档级别事件抽取
- 与句子级事件抽取 (SEE)相比,有两个挑战:()论元分散:一个事件的论元可能分散在文档中的多个句子中,这意味着不能从单个句子中抽取一个事件记录;()多事件:一个文档可能同时包含多个事件,这需要对事件之间的相豆依赖性进行整体建模。
2. 少样本学习 - 给定触发词,完成触发词分类
- 纯文本数据联合进行触发词识别和分类
(更接近实际应用)
3. 零样本学习 - 语义相似度
- 迁移学习(文本隐含 TE 和问答查询 QA)?
4. 增量学习 - 解决灾难性遗忘问题(学习系统在适应新类型时,通常会在旧类型上出现显著的性能下降):通过提出的知识整合网络解决了灾难性遗忘和语义模糊问题,在增量 ED 上实现了有效的性能。
8.1.4 结论
- 深度学习优于机器学习和模式匹配
- BERT 的突出效果(上下文信息的语义关联/文档级别)
- 外部资源提升效果
- 联合抽取和 pipeline 抽取的优劣
8.2 Exploring the Feasibility of ChatGPT for Event Extraction
8.2.1 面临场景
without fine-tuning, zero-shot 场景,主要关注事件检测任务
8.2.2 实验结果
![]()
结果显示,EEQA 在 F 1 中表现最好,而 ChatGPT 则落后于 Text 2 Event 和 EEQA。ChatGPT 的 Recall 与 Text 2 Event (t 5 基)相当,但其精度明显较低。作者观察到 ChatGPT 提取了更多的事件触发器,这可能是因为它缺乏对某些事件定义的清晰理解。
8.2.3 结论
在长尾和复杂场景中,ChatGPT 的平均性能仅为特定于任务的模型(如 EEQA)的 51.04%。可用性测侧试实验表明,ChatGPT 不够健壮,提示符的持续改进并不能带来稳定的性能改进,这可能会导致糟糕的用户体验。此外,ChatGPT 对不同的提示样式非常敏感。
8.3 LegalGNN: Legal Information Enhanced Graph Neural Network for Recommendation
汇报人:康志求
8.3.1 模型结构
![]()

8.3.2 结论
将节点和内部之间的结构关系联合起来
8.4 国基金项目
- 将各个关键点搜索相关文献进行总结。
- 调研关于司法领域的 KG 与 LLM 相互作用的文献,有则加之,无责阐述与司法相关的关系作为创新点。
9 2023-11-05(项目例会)
[!NOTE] 周会总结
- 已学内容:
- 学习 SpringBoot(SpringMVC、拦截器、Swagger、Json 格式化、日志、JPA、MyBatisPlus)
- 下周计划:
- 学习 SpringBoot 剩余部分内容(SpringSecurity、Jwt)并做相应的 Demo
- 学习感悟:
- SpringBoot 相当于是把 Spring 框架里的很多依赖和 Web 容器(Tomcat)整合了起来,原来 Spring 需要写很多配置文件,而 SpringBoot 直接提供了默认的配置,按需修改即可,大大简化应用开发流程。为了解耦应用程序不同模块的逻辑功能,使用 MVC 思想进行设计,分为模型、视图和控制层,各司其职保证程序具有较强的可读、可扩展、可维护性。
- 在 SpringBoot 中可以很方便的使用各种中间件,比如数据库、消息队列、缓存和搜索引擎等,从而满足各种客制化需求。
- 指导建议:
- 根据学长给的 demo 完成相应项目的实践
10 2023-11-10(学术例会)
10.1 Contrastive Data and Learning for Natural Language
Processing
汇报人:林广生
10.1.1 联合抽取和流水线抽取
抽取方式优点缺点研究热度
流水线抽取模块化设计;实现简单
错误传播;上下文信息利用不足
联合抽取
减少错误传播;上下文利用;效率提升
模型复杂
10.2 ERICA: Improving Entity and Relation Understanding for Pre-trained Language Models via Contrastive Learning
10.3 Legal Elements Extraction via Label Recross Attention and Contrastive Learning
10.4 对比学习
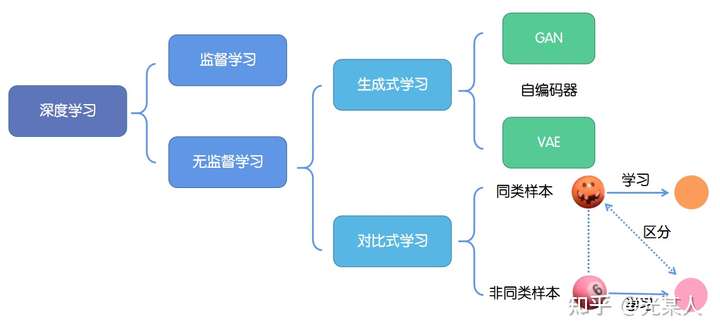
对比式学习着重于学习同类实例之间的共同特征,区分非同类实例之间的不同之处。
与生成式学习比较,对比式学习不需要关注实例上繁琐的细节,只需要在抽象语义级别的特征空间上学会对数据的区分即可,因此模型以及其优化变得更加简单,且泛化能力更强。
对比学习的目标是学习一个编码器,此编码器对同类数据进行相似的编码,并使不同类的数据的编码结果尽可能的不同。
10.5 LawBench: Benchmarking Legal Knowledge of Large Language Models
汇报人:胥岚林

10.6 思维链




10.7 IF
存在问题:
25. 仅有现状的罗列,没有阐述现存什么问题,目前的解决方法或是解决了什么问题,还存在什么问题,我们拟研究解决哪些问题。
26. 对现有内容进行总结,总分结构,阐述清楚各个部分的逻辑关系。
27. 行文结构:
- 现领域存在什么关键问题
- 介绍那些国内外学者研究解决了哪些问题
- 还存在什么问题有待解决,我们拟研究解决哪些问题
11 2023-11-12 (项目例会)
[!NOTE] 周会总结
- 已学内容:
- 学习 SpringSecurity,并且进行 SpringBoot+Vue 的项目实战(SpringSecurity、Redis、Mybatis、RabbitMQ,项目不含用户管理、权限管理、菜单管理、日志管理等)已完成 80%
- 下周计划:
- 继续完成未完成的项目实战并学习 Java 高级特性(Concurrent、NIO、Lambda、Stream、Optional 等)或 SpringCloud。
- 学习感悟:
- 通过项目实战的实践练习,让我了解了一般项目的基本结构组成,并且熟练了前面学习的 SpringSecurity、SpringMVC、Mybatis、Mail、Slf 4 j、Swagger 等组件的联合运用,但是由于是首次使用还不是很熟练,有很多配置要想都配置全面实际上还是比较复杂,要注意 bean 之间的不能循环依赖、Mybatis 的 DTO 的属性名必须与数据表的字段名一致之类的小坑,后面需要多加练习巩固已学的知识才能更熟练灵活的运用。一些 java 高级特性比如 Concurrent、NIO、Lambda、Stream、Optional 等在项目开发中还是非常有用的,所以不知道接下来是先学习熟悉这些还是直接学 SpringCloud。
- 指导建议:
- 学习 SpringCloud,在学习过程中运用到哪些高级特性就去顺便学习了
12 2023-11-17 (学术例会)
12.1 CPEE:Civil Case Judgment Prediction Centering on the Trial Mode of Essential Elements
主讲人:xzt
民事案件判决预测
解决思路:
graph LR;
A[1案由预测]-->B;
B[2法条预测]-->C;
C[3判决预测]-->A;


本文提出了一种基于法律要素的民事案件判决预测方法 CPEE(Civil Case Judgment Prediction centering on the Trial Mode of Essential Elements)。该方法主要包括三个步骤:案由预测、法条预测和判决预测。
在案由预测中,作者使用了一个双向 LSTM 模型来根据案件事实描述来预测案由。在法条预测中,作者使用了一个基于注意力机制的 LSTM 模型来根据案件事实描述和相关法律规定来预测适用的法条。在判决预测中,作者使用了一个多任务学习模型来预测判决结果。
为了评估 CPEE 方法的性能,作者使用了一个包含真实民事案件数据的数据集进行实验。实验结果表明,CPEE 方法在案由预测、法条预测和判决预测方面都取得了较好的性能。同时,作者还进行了对比实验,并展示了 CPEE 与其他方法相比的优势。
总之,本文提出的 CPEE 方法可以有效地进行民事案件判决预测,并具有一定的实际应用价值。但是仍然存在一些改进空间,例如进一步优化模型结构和算法以提高性能,并考虑更多因素对判决结果的影响。
12.2 Boosting Factual Correctness of Abstractive Mmarization with Knowledge Graph
(Microsoft Cognitive Services Group,NAACL 2021)
主讲人:hwx
现状与问题:
28. 生成式摘要的一个突出问题是事实不一致。它指的是摘要有时歪曲或捏造文章中
的事实的幻觉现象。(生成幻觉)
29. 另外大多数现有的生成式模型在训练以及评估的过程中都采用关注摘要的 token 级
准确性,而忽略了摘要与原文之间语义级的一致性。因此,生成的摘要在 ROUG
这样的 token 级别度量中可能评分很高,但缺乏事实一致性。(衡量摘要效果,评估)
解决方案:
1.1 事实感知模型
1.2 事实纠正模型
除开构建事实感知模型,为了更好地利用现有的摘要系统,提出了一个事实校正模型 FC,以提
高生成式摘要模型生成的任何摘要的事实一致性。FC 将修正过程定义为一个 seq2seq 问题:给定一篇文章和一个候选摘要,模型生成一个修正后的摘要,与文章更加一致。
利用现有摘要模型,通过正负样本训练纠正幻觉摘要
2.1 衡量事实准确度
采用了 FactCC(Evaluating the factual consistency of abstractive text summarization,EMNLP2020,该模型是训练出来的),一个基于 0t 的事实一致性评估器,该模型输出 0 到 1 之间的分数(二分类模型),分数越高表示输入文章和摘要之间的一致性越好。
实验结果
检查 FASum 模型是否仅仅通过复制文章的更多部分来提高事实一致性。FASUM 达到了与参考摘要最接近的新颖 n-gram 比率,并且高于 BOTTOMUP 和 UNILM。表明 FASUM 可以在确保事实一致性的同时生成高度生成式的摘要。
2.2 无模型事实一致性衡量(不采用 FCC 模型进行评估,无需训练评估模型)
12.3 G-Eval:NLG Evaluation Using GPT-4 with Better Human Alignment
(Microsoft Cognitive Services Research,arXiv:2303.16634,2023)
主讲人:hwx
该模型用于评估 NLG 自然语言生成模型生成结果,相较于 BLUE,ROUGE 评估方法更合理准确。
现状与问题:
- 传统的一些文本评价指标,如 BLUE,ROUGE 与人类判断的相关性相对较低,特别是对于开放式生成任务。
- 此外,这些指标需要相关的参考输出,为新任务收集这些输出的成本很高。
- 考虑 LLM 作为无参考的 NLG 评估者。其想法是在假设 LLM 已经学会为高质量和流畅的文本分配更高的慨率的情况下,在没有任何参考目标的情况下使用 LLM 根据候选输出的生成概率对其进行评分。

实验结果:
12.4 IF
修改建议:
1. 更加精简,把前后几部分逻辑关系梳理清楚,语言更加贴切。
13 2023-11-19 (项目例会)
[!INFO] 周会总结
- 已学内容:
- 完成 SpringBoot 项目实战,学习 SpringCloud(SpringCloud-Netflix 的 Eureka、LoadBalancer、Hystrix、Gateway、Config 以及 SpringCloud-Alibaba 的 Nacos、Sentinel)
- 下周计划:
- 继续学习 SpringCloud(Seata、OAuth2、Redis 与分布式、Mysql 分布式、消息队列与消息组件),学习 Git 用法。
- 学习感悟:
- 通过学习了解到 Springcloud 可以将复杂的单体服务进行拆分解耦为多个简单的微服务分布式部署,可以缓解单机服务压力,横向扩展服务提高服务的可用性与可拓展性。然而拆分为多个微服务后服务的注册、发现、配置、负载均衡、降级熔断、路由网关、分布式等需要通过各种对应的中间件来协调配合完成,保证服务完整一致可用。
- 指导建议:
- 继续按照进度学习,要单独学 Dubbo,可以看看 SpringCloud-Alibaba 实战
14 2023-11-24 (学术例会)
14.1 1.类案检索
汇报人:pjc
Prompt-Based Effective Input Reformulation for Legal Case Retrieval
引言
法律案件检索(Legal case retrieval,LCR)的目的是在给定查询案件的情况下检索相关案件。本质上就是一种特殊类型的信息检索(Information Retrieval,IR)。
从法律的角度来看,先例是指在法律事实和法律问题两个确定方面与给定案件相似的历史案例。
在英美法系中,判决的司法理由是批判性地以相关案例为依据的,这也被称为“先例主义”。
在大陆法系中,虽然判决是不一定要以以前的相关案例为依据,但仍然强烈建议法官和律师从这些相关案例中获取法律信息。
现状
信息检索技术在方法上可以分为基于传统统计的方法和基于神经网络的方法两大类:
基于传统统计的方法:以关键词检索和基于规则匹配为主,这类方法原理简单易用,并且执行起来非常高效。
基于神经网络的方法:以文本语义理解为主,通过基于交互式和基于表征式的检索模型实现信息检索。
相关挑战
法律特征对齐:法律领域的关联对关键法律要素非常敏感。即使是关键法律要素的细微差异也会显著影响相关性的判断。使用整个案例文本作为输入,通常会包含冗余和噪声信息,因为从法律角度来看,相关案例的==决定因素是关键法律特征的对齐,而不是整个文本的匹配==。
法律语境保留:此外,由于现有文本编码模型的输入长度限制通常比案例短,因此需要对整个案例文本进行==截断或分段,从而失去了法律信息的全局语境==。
现有输入重构
定义
bm25 算法原理
BM25(Best Match 25)是一种用于信息检索的算法,它在搜索引擎中被广泛应用。BM25 算法是一种基于概率模型的非常有效的排序算法,它考虑了查询词项的频率、文档长度以及文档中词项的分布情况。
BM25 算法的原理如下:
30. 首先,计算查询词项在文档中出现的频率(term frequency,TF)和查询词项在整个文集中出现的频率(document frequency,DF)。这些频率信息将用于衡量一个文档与查询的相关性。
31. 然后,计算一个调整因子(inverse document frequency,IDF),来衡量一个词项对于整个文集来说有多重要。IDF 值越大表示该词项越重要且稀有。
32. 接着,计算一个得分公式(score),该公式综合考虑了 TF、DF 和 IDF 等因素。具体而言,得分公式为:score = IDF * (k1 + 1) * TF / (k1 * (1 - b + b * docLength / avgDocLength) + TF),其中 k1 和 b 是两个可调参数,docLength 是文档长度,avgDocLength 是平均文档长度。
33. 最后,对所有文档进行排序,并返回与查询最相关的前几个结果。
总结起来,BM25 算法通过计算 TF、DF 和 IDF 等因素来衡量一个文档与查询的相关性,并通过得分公式对文档进行排序。它是一种非常有效的排序算法,可以提高搜索引擎的检索质量。
解决方案
1.在深入研究法律视角下相似案例定义的基础上,提出了具有法律事实和法律问题两个决定性法律特征的输入表示,以有效地获取案件中的代表性法律信息,而不是使用整个案件。(解决法律特征对齐问题)
2.在提取法律事实和法律问题之后,基于提示的方式对案件进行重构。(解决法律语境保留问题)
方法过程
框架
相关数据集
- COLIEE
数据集主要由加拿大联邦法院的判例法组成,并以包含 4415 个文档的案例池的形式提供。 - LeCaRD
Legal Case Retrieval Dataset(LeCaRD)包含 107 个查询用例和 10,700 个候选用例。查询和结果均来自中最高人民法院公布的刑事案件。
法律事实和法律问题
区别: - 焦点不同:法律事实关注具体事件,而法律问题关注法律规则和原则的适用。
- 证明和解释:法律事实通常需要证据来证明,而法律问题需要解释和适用法律规则。
- 具体与抽象:法律事实是案件中的具体情况,而法律问题是更为抽象的概念,涉及对法律原则的理解和运用。
举例说明:
在一起合同纠纷中,合同的签订和履行过程(法律事实)可能需要通过证据来证明。然而,法院在解决法律问题时可能需要考虑合同法规定的原则,如合同的成立条件、解释规则、违约后的救济等(法律问题)。
评估
无排序的度量指标:精度(P),召回率(R),微观 F1(Mi-F1),宏观 F1(Ma-F1)
信息检索系统常用的度量指标:平均平均精度(MAP),平均倒数秩 MRR),归一化贴现累积增益(NDCG)
可以仅考虑一定数量的顶级推荐 k,,而不是通常的精度和召回率。这样,该指标就不会关心排名较低的结果。根据所选的 k 值,相应的度量分别表示为 precision@k (“k 处的精度”)和 recall(@k(“k 处的召回率”)。
DCG(贴现累计增益指标):
1 | |
Conversation with Claude-instant-100k on Poe
结果
通过对案例输入进行适当的重新表述,集成到基线中来评估 PromptCase,其显著提高检索的性能。
对于传统的 BM2 方法,使用 PromptCasel 比使用整个 case 作为输入的性能更好。改进后的性能表明,重新表述的输入可以捕获决定性的法律特征,并适当强调术语频率,而不会受到冗长和嘈杂的案例文本的影响。
对于以全 case 作为输入的预训练 BERT,在两个数据集上的性能都不如 BM2 和 SAILER。然而 BERT+PromptCase 在 LeCaRD 上优于 BM25+PromptCase 和 SAILER 基线模型,这表明 BERT 是一个语义 LM,可以更好地理解和表示使用。
14.2 2.知识图谱融合理解与论文分享
汇报人:lsm
个人体会
知识融合,即合并两个知识图谱(本体),不同的图谱对同一个实体的描述,会有差异。通过知识融合可以将不同知识图谱中的只是进行互补融合。知识融合的关键步骤是实体对齐。实体对齐就是研究如何将不同图谱中表示同一事物的实体找出来并合并。
常见的实体对齐原理:给定两个知识图谱,给出图谱中一部分已经对齐的实体(称为种子实体对或先验对齐数据),依据这些已经对齐的实体,通过邻居关系等方式找到其他未被对齐的实体,最终完成知识图谱的触合。
目前的主要挑战
计算复杂度挑战,进行两个知识库实体匹配的时候,为了发现所有的匹配对,需要将个知识库中所有实体与另一个知识库中所有的实体进行比较。
数据质量挑战,主要由于不同的知识库的构建目的和构建方式不同:相同实体有不同的名字,相同的名字指代不同的实体,相同的属性在不同知识库中具有不同的判别能力,相同类别的实体在不同知识库中具有不同数量的属性。
先验对齐数据的获取挑战,先验对齐数据也称为训练数据,在知识库实体对齐过程中具有重要的作用,无论是对匹配的准确度还是算法的收敛速度都会产生重要影响。
论文分享
Liu Z,Cao Y,Pan L,et al.Exploring and evaluating attributes,values,and structures for entity alignment[J].arXiv preprint arXiv:2010.03249,2020.
探索和评估实体对齐的属性、值与结构 ENLP2020 新加坡国立大学
引言
知识图谱中的三元组:
关系三元组(h,r,t)头实体-关系-尾实体
属性三元组(e,a,v)实体-属性-值
传统知识对齐方案:基于关系三元组,对关系三元组结构进行建模。
提出新模型:
关系三元组和属性三元组同时对知识图谱建模,考虑属性的重要程度。
核心假设:
等价的实体在知识图谱中不仅拥有相似的实体间关系,还拥有相似的属性及属性值。
目前实体对齐算法存在的挑战:
1、不同知识图谱的实体属性合并:
- 预先使用独立的网络学习关系三元组和属性三元组,然后同时建模关系三元组和属性三元组,将关系三元组中的对齐信号通过属性三元组传递到实体上。
- 学习不同属性的重要性,如图(c)城市实体,属性 Name 较为重要,而属性 Time Zone 则不重要。
2、数据集偏差:
实体对齐数据集中的 Name 属性表述方式存在差异,许多实体会被通过名称“简单等效”,会导致实体对齐模型的性能被高估,如数据集 DBP15k 中约有 60%-80%的种子等价实体可以通过属性 Name 进行对齐。
贡献 - 提出包含属性的图神经网络 Attributed Graph Neural Network(AttrGNN):来统一学习属性三元组和关系三元组,能够动态的学闷属性和值的重要度。
- 属性值编码器:在 AGNN 中加入了属性值编码器,对属性和值进行选择和聚合,并将属性相似的信息传递给邻居实体。
- 划分子图:不同类型的属性有不同的相似度度量方式,将整个知识图谱划分成 4 个子图,然后利用 GNN 分别学习表示方式,最后将 4 个子图的表示集成在一起。
研究方案
1、图划分:负责将输入的图谱按照属性和值分为 4 个子图(仅含 name 属性、字符串属性、数字属性和无属性)。
2、子图编码器:利用多通道图神经网络,分别学习 4 个子图,其中每个通道是由 L 层属性值编码器和均值聚合器堆叠而成。属性值编码器聚合属性和值以生成实体嵌入,属性均值均聚合器按照图结构将实体特征传播给相邻节点。
3、图对齐,将两个知识图谱对应通道的向量统一表示到同一个向量空间。
4、通道集成,将不同通道输出的相似度集成在一起,用于最终预测结果。
结论
结论 1:在困难测试集中,文字通道和结构通道的性能接近名称通道。这证明了探索非名称特性(包括其他属性和关系)对于实际实体对齐的重要性。
结论 2:子图划分策略取得了很好的改进,原因是子图划分使模型能够以不同的方式度量不同属性的相似性。
结论 3:完整模型效果明显优于仅考虑结构、仅考虑关系/属性的模型,这证明了在实体对齐中同时考虑关系三元组和属性三元组的必要性。
实体抽取工具调研
主要实现方法和工具:
(1)DeepDive-斯坦福大学开源知识抽取工具(三元组抽取):从更少的结构化数据和统计推断中提取结构化的知识而无需编写任何复杂的机器学习代码。
(2)FudanNLP:主要是为中文自然语言处理而开发的工具包,也包含为实现这些任务的机器学习算法和数据集。可以实现中文分词,词性标注,实体名识别,句法分析,时间表达式识别,信息检索,文本分类,新闻聚类等
(3)NLPR 分词(中科院):主要功能包括中文分词;英文分词;词性标注;命名实体识别;新词识别;关键词提取;支持用户专业词典与微博分析。NLPR 系统支持多种编码、多种操作系统、多种开发语言与平台。
(4)LTP(哈工大):语言技术平台(Language Technology Platform,LTP)提供了一系列中文自然语言处理工具,用户可以使用这些工具对于中文文本进行分词、词性标注、句法分析等等工作。
关系抽取工具调研
1.实体间关系抽取,拿到知识图谱最小单元三元组,比较经典算法的就是 Piece.-Wise-CNN 和 LSTM+Attention。
2.DeepKE:基于深度学习的开源中文关系抽取工具 GitHub 地址&&OpenKG.发布地址
3.DeepDive.是斯坦福大学开发的信息抽取系统,能处理文本、表格、图表、图片等多种格式的无结构数据,从中抽取结构化的信息。系统集成了文件分析、信息提取、信息整合、概率预测等功能。Deepdive 的主要应用是特定领域的信息抽取,系统构建至今,已在交通、考古、地理、医疗等多个领域的项目实践中取得了良好的效果;在开放领域的应用 Deepdive 在 OpenKG.CN 上有一个中文的教程:中文教程斯坦福地址:DeepDive GitHub 地址: https://github.com/HazyResearch/deepdive 支持中文的提取:支持中文的 deepdive:斯坦福大学的开源知识抽取工具(三元组抽取)
4.Reverb:开放三元组抽取 http://reverb.cs.washington.edu Reverb 是华盛顿大学研发的开放三元组抽取工具,可以从英文句子中抽取形如(augument1,relation,argument2)的三元组。它不需要提前指定关系,支持全网规模的信息抽取。
COT 的生成方法
基于手动构建:
- 手工 COT 的集成方法 Active Prompting with Chain-of-Thought for Large Language Models
- 零样本 COT,LLM 自主生成提问的中间步骤,再加入到 rompt 中形成 COT Zero–shot-CoI
基于自动构建:
核心思想都是基于手工构建的 COT,让模型自动生成更多的 COT 模板然后进行选择。 - Synthetic Prompting:Generating Chain-of-Thought Demonstrations for Large Language Models
- Automatic Prompt Augmentation and Selection with Chain-of-Thought from Labeled Data
COT 的综述: https://browse.arxiv.org/abs/2310.04959
14.3 3.IF
- 研究内容聚焦 LLM 与 KG 融合
- 继续修改压缩研究背景内容到两页左右.
15 2023-11-26 (项目例会)
[!NOTE] 周会总结
- 已学内容:
- 学习 SpringCloud-Alibaba(包括 Seata、Dubbo、RabbitMQ 、Stream、Bus 等中间件),以及 OAuth2 单点登录、Redis 用法(已完成 70%)和 Git 基本用法(45%)
- 下周计划:
- 继续完成 Redis 分布式、MySql 分布式、ShardingJDBC 和 Git 学习,并学习 Pig 项目
- 学习感悟:
- SpringCloud 其实就是使用多种中间件来协调配合多个 SpringBoot 服务,实现微服务之间连通、可用且完整,从而将一个庞大的项目根据不同功能不同粒度进行拆分解耦充分利用集群的优势横向扩展。OAuth2 是微服务应用的一种鉴权方式,实现单点登录效果。
- 指导建议:
16 2023-12-01 (学术例会)
16.1 1.潜在自适应结构感知的生成式信息抽取
汇报人:zkh
引言
将句法结构信息融入到大模型帮助其更好地捕获句法成分之间的依赖关系进行生成式信息抽取。
关键问题
语言模型能够经过大量语料的预先训练,可以捕获到结构性句法信息,但这种自动学习的结构表征
很弱
主要贡献
34. 结构诱导器+结构广播器->将句法结构信息融入到模型中
35. 面向任务的结构微调机制->何法结构自适应调整
句法分析
- 依存句法分析:用于识别句子中词汇与词汇之间的相互依存关系,着重于揭示词法单元之间的依赖关系
- 成分句法分析:基于成分结构理论,将句子分解为更小的片段或短语,这些片段或短语具有特定的功能和关系
任务原型分解
三阶段训练过程
36. stage1: Pre-training
37. stage2: Unsupervised Structure-aware Post-training

38. stage3: Fine-turning
- 在依赖结构中,剪除琐碎的词与词之间的联系,并调整依赖路径的范围
- 在成分结构中,细化短语的宽度和粒度
思考
39. BERT 证明 encoder 的表层信息特征在底层网络,句法信息特征在中间层网络,语义信息特征
在高层网络。为什么 LasUlE 用的底层网络学习句法特征?
40. 模型速度如何?
41. 是否还有其他句法结构可以融入进去?
结果

42. M2-M5 或 M9-M12->融入句法结构的优势(注入外部句法结构特征
43. M2 和 M9->统一建模的优势
结论
44. 成分句法对 poundary recognition 帮助较大,依存句法对 relation detection 帮助较大
45. 融入两种句法结构,所有任务得到最大提升
16.2 2.面向节点聚类的图嵌入机制
汇报人:zyz
聚类 vs 分类
聚类和分类是机器学习中常用的两种技术。虽然它们都是将数据分组为不同的类别,但是它们有一些不同之处。
聚类是一种无监督学习技术,它试图在数据中发现隐藏的模式或结构,并将相似的数据点分组在一起形成簇。聚类算法通常根据数据点之间的相似性度量来确定簇的数量和形状。聚类算法不需要已知的标签或类别信息,因此可以用于探索性数据分析和发现潜在的模式。
分类则是一种有监督学习技术,它基于已知的标签或类别信息来构建一个预测模型。分类算法通过学习训练集中的样本特征与其对应标签之间的关系,并根据这些关系对新样本进行预测分类。分类算法需要有带有正确标签的训练数据集来进行模型训练。
总结而言,聚类和分类之间主要区别在于:
46. 监督学习 vs 无监督学习:分类是一种监督学习技术,需要已知标签或类别信息进行模型训练;而聚类是一种无监督学习技术,不需要任何已知的标签或类别信息。
47. 预测模型 vs 数据探索:分类算法构建一个预测模型,可以对新样本进行分类预测;聚类算法通过发现数据中的模式和结构,用于数据探索和发现潜在的模式。
48. 样本标签 vs 簇:分类算法通过样本标签将数据分为不同的类别;聚类算法

K-means 聚类
K-means 聚类是一种常用的无监督学习算法,用于将一组数据点划分为 K 个不同的簇。它的目标是使得每个数据点与其所属簇的质心之间的距离最小化。
K-means 算法的步骤如下:
- 随机选择 K 个数据点作为初始质心。
- 将每个数据点分配给距离最近的质心,形成 K 个簇。
- 根据每个簇中的数据点重新计算质心位置。
- 重复步骤 2 和步骤 3,直到质心不再发生变化或达到最大迭代次数。
K-means 算法使用欧氏距离来度量数据点之间的相似性。在每次迭代中,通过计算每个数据点与所有质心之间的距离,将其分配给最近的质心。然后更新每个簇的质心位置为该簇中所有数据点的平均值。
K-means 算法有几个优缺点:
优点:
- 简单、易于实现。
- 可以处理大规模数据集。
- 对于各向同性和凸形状簇效果较好。
缺点:
- 对于非凸形状、大小差异较大的簇效果不佳。
- 对于初始质心的选择敏感,可能会陷入局部最优解。
- 需要事先确定簇的数量 K。
K-means 算法在实际应用中广泛用于图像分割、文本聚类、推荐系统等领域。
DBSCAN 聚类
DBSCAN(Density-Based Spatial Clustering of Applications with Noise)是一种基于密度的聚类算法,它能够从数据中发现具有相似密度的样本群集,并将其划分为不同的簇。与其他聚类算法相比,DBSCAN 不需要预先指定簇的数量,也能够处理任意形状的簇。
DBSCAN 算法的基本思想是通过定义一个半径ε内的邻域来衡量样本点之间的距离,并以此来判断样本点是否属于核心点、边界点还是噪音点。具体步骤如下:
- 随机选择一个未被访问过的样本点 P。
- 如果 P 的ε-邻域内包含至少 minPts 个样本点,则创建一个新簇 C,并将 P 添加到 C 中。然后访问 P 的所有ε-邻域内未被访问过的样本点,并将它们添加到 C 中。
- 如果 P 没有ε-邻域内包含至少 minPts 个样本点,则将 P 标记为噪音点。
- 重复步骤 1~3,直到所有样本点都被访问过。
最终,DBSCAN 算法会输出若干个簇以及一些噪音点。其中,核心点是位于某个簇内部并且周围有足够多样本点的点,边界点是位于某个簇边界上的点,噪音点是不属于任何簇的点。
DBSCAN 算法的优点包括能够发现任意形状的簇、不需要预先指定簇的数量、能够处理噪音等。然而,它也有一些缺点,如对于具有不同密度的簇效果较差、对于高维数据效果较差、对于数据集中的离群点敏感等。
聚类算法的演进过程
graph LR
A[聚类算法] --> B[k-means算法]
A --> C[层次聚类算法]
A --> D[密度聚类算法]
A --> E[谱聚类算法]
B --> F[改进的k-means算法]
C --> G[凝聚层次聚类算法]
C --> H[分裂层次聚类算法]
D --> I[DBSCAN算法]
D --> J[HDBSCAN算法]
E --> K[标准化谱聚类算法]
F --> L[CNN-k-means算法]
G --> M[GNN-凝聚层次聚类算法]
H --> N[GNN-分裂层次聚类算法]
在演进过程中,聚类算法从最早的 k-means 算法开始,然后引入了层次聚类、密度聚类和谱聚类等方法。随着研究的深入,各种方法都有了改进和扩展。例如,k-means 算法的改进版本可以提高其收敛性能;层次聚类有凝聚和分裂两种不同的策略;密度聚类有 DBSCAN 和 HDBSCAN 等更先进的方法;谱聚类也有标准化谱聚类等改进版本。这些演进过程使得各种聚类方法在不同场景下都能够取得更好的效果。
摘要
传统的节点聚类方法存在局限性,即 GN 只关注节点嵌入的生成,而不考虑聚类的最终目标。为了解决这个问题,这篇文章提出了一种名为“深度聚类”的新技术,该技术集成了节点嵌入和聚类阶段。这需要通过同时最小化 GN 损失和聚类损失来定义一个新的损失函数。提出的损失函数不仅包含聚类内的距离,还通过应用轮廓系数来整合聚类之间的距离,这使得能够获得更好的聚类结果。在本文中,我们提出了一种基于轮廓的 GNN 深度聚类(SDCG),通过迭代训练嵌入模型来生成具有改进聚类结果的嵌入向量,从而更有效地对图中的节点进行聚类。
总之,本文提出了一种名为深度聚类的新技术 SDCG,在节点嵌入和聚类阶段集成起来,并通过定义新的损失函数来优化聚类结果。实验证明,SDCG 优于传统独立执行嵌入和聚类的方法,在图中节点聚类任务上表现更好。
16.3 3.IF
指导意见:
49. 继续修改申报书
50. 和师兄讨论应该采集哪些网站的司法数据
17 2023-12-03 (项目例会)
[!NOTE] 周会总结
- 已学内容:
- 学习 Redis 分布式、Mysql 分布式、ShardingJDBC 和 Git 学习,以及 Jdk8 到 17 的常用新特性,并且看了 Spring Cloud Alibaba 微服务原理与实战书籍的前两章(微服务发展史、SpringCloud 微服务解决方案)。
- 下周计划:
- 继续阅读学习 Spring Cloud Alibaba 微服务原理与实战书籍后续内容(SpringCloudAlibaba 相关中间件),学习 SpringBoot 技术栈较全的开源项目。
- 学习感悟:
- 指导建议:
- 参与项目组项目研究
- 扩展原 demo 项目或者学习技术栈较全面有一定体量的开源项目
- 调研爬虫解决方案,有哪些爬虫框架,比较各自优缺点,根据数据源选择合适框架
- 数据采集要求,数据采集后的存储的格式。
18 2023-12-08 (学术例会)
18.1 IF
- 研究目标在数据集方面不够精确
- 研究司法大模型具体目标,主要研究司法大模型的基础能力而不是应用实践层面的表现
19 2023-12-10 (项目例会)
[!NOTE] 周会总结
- 已学内容:
- 学习 SpringBoot 若依脚手架的使用,了解脚手架项目结构,主要分析了岗位模块的功能逻辑以及代码生成器的用法等,还阅读了 Spring Cloud Alibaba 微服务原理与实战的三四章 springboot 和服务治理。
- 下周计划:
- 继续阅读 Spring Cloud Alibaba 微服务原理与实战书籍,并学习爬虫
- 学习感悟:
- 指导建议:
- 学习 java 爬虫框架,尽可能爬取较多司法数据,实现高度相关条件爬取,实现多源数据源汇集处理管理平台
20 2023-12-22(学术例会)
20.1 KG-GPT:使用大型语言模型进行知识图推理的通用框架
汇报人:zl
来源:EMNLP(NLP 顶会)Findings 韩国科学技术院 2023.10.17
贡献
- 提出了 KG-GPT,一种利用大语言模型进行知识图的任务的多用途框架
- KG-GPT 相对其他完全监督模型表现出了强大的竞争力与稳健性
- 迈出了在 LLMs 领域实现结构/非结构化数据处理的重要一步
基本思路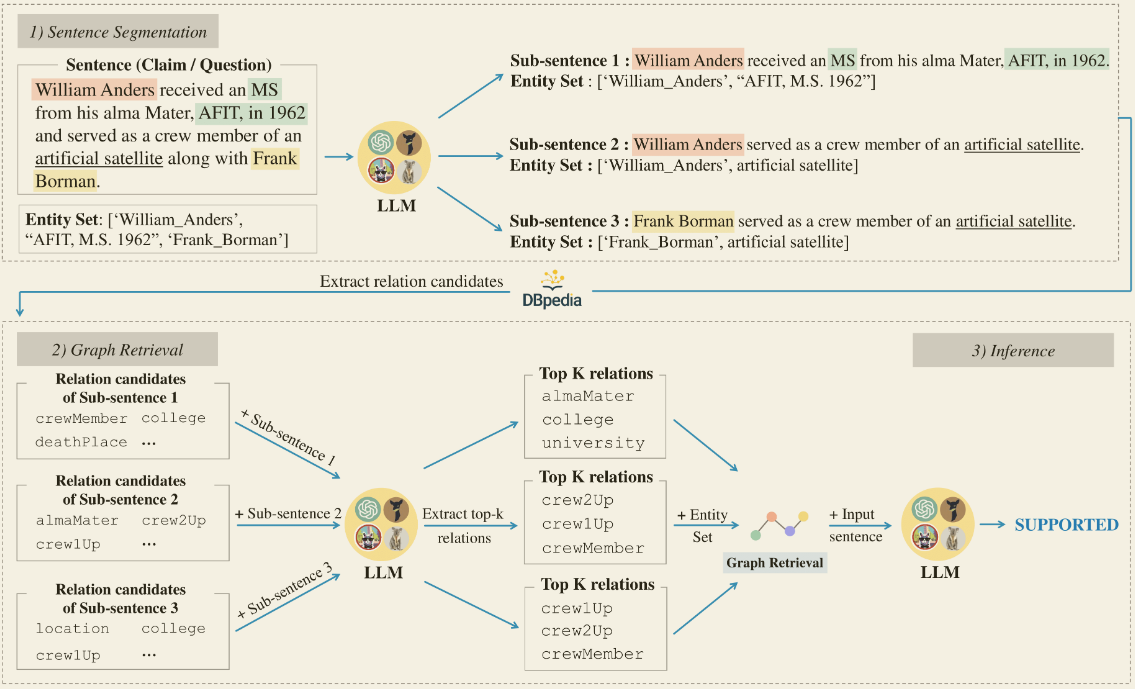
KG - GPT 包括三个步骤:(1)句子(索赔/问题)切分(2) 图检索(3)推理。
在句子切分过程中,一个句子被切分为离散的子句,每个子句与一个三元组(即[头、关系、尾])对齐。随后的步骤,即图检索,检索出一个潜在的关系池,可以桥接子句中识别的实体。然后,利用检索到的关系和实体集合得到候选置信图池(即 sub - KG)。在最后一步,利用得到的图导出一个逻辑结论,例如验证给定的声明或回答给定的问题。
20.2 基于统一语义匹配的通用信息抽取框架 USM
汇报人:hyx
来源: https://doi.org/10.48550/arXiv.2301.03282
背景
传统方法:设计针对特定任务的模型,严重依赖标注数据,难以推广到新模式中;通用信息抽取:2022 年《Unified Structure Generation for Universal Information Extraction》一文,提出了通用信息提取(UlE)的概念,旨在使用一个通用模型来解决多个信息提取任务,提出了一种 Seq2Seq 的生成模型,以结构化模式提示器+文本内容作为输入,直接生成结构化抽取语言,最终获取信息提取内容;
待解决的问题:由于 Seq2Seq 的生成模型的黑盒特性,信息片段和模式之间的所有关联都是隐式,导致无法判断跨任务或跨模式的迁移在什么情况下会成功或者失败
开始讲论文方法实现的细节之前,首先要说明该实验的目标结果和言简意赅的思路过程,点名实验目的和基本思路有个概述了解,然后再不钻牛角尖的阐述实现的细节。
21 2023-12-24(项目例会)
[!NOTE] 周会总结
- 已学内容:
- 阅读学习了 Spring Cloud Alibaba 微服务原理与实战的 Nacos 和 RocketMQ 的部分内容,黑马 SpringBoot3+Vue3 基础内容,以及 Scrapy 爬虫框架。
- 下周计划:
- 学习黑马 SpringBoot3+Vue3 视频教程,继续学习爬虫爬取 openlaw 上的数据
- 学习感悟:
- 指导建议:
- 把相关案例也爬取存储起来
- 爬取多个司法网站的数据
- 将法律法规也根据字段特点提取出来
- 数据可视化尽量在系统内部呈现,不要跳转到别的系统再导入数据可视化。
- 数据采集还是用 crawlab 平台进行采集
- 多个数据源对于司法案例和法律法规都放在对应的一张表里,表字段尽可能全面
22 2023-12-29 (学术例会)
- 阅读深度学习论文按照以下思路进行:
- CNN
- RNN
- LSTM
- Transformer
- BERT
- ···
23 2024-01-02 (项目例会)
[!tip] 周会总结
- 已学内容:
- 黑马 SpringBoot3+Vue3 大事件实战篇后端已经完成,并借助 Scrapy 补充爬取司法案例的相关案例,以及编写爬取法律法规爬虫部分内容。
- 下周计划:
- 完成黑马大事件实战篇前端部分,并进一步完善 openlaw 的司法案例和法律法规爬虫。
- 学习感悟:
- 指导建议:
- 将法律法规按照章和条进行分节,细化全文存储
24 2024-01-05(学术例会)
24.1 IF
[!error] 问题
- 研究现状首先综述
- 司法大数据更新数据现状时间
- 表述问题,cot 是否可以用于解决模型可解释性,解决可解释性调研司法领域可解释性各种可行方法
25 2024-01-07 (项目例会)
[!NOTE] 周会总结
- 已学内容:
- 黑马 SpringBoot3+Vue3 大事件实战项目已经完成,初步学习 Tennis 项目源代码,完善爬虫尝试爬取裁判文书网数据(不太可行)。
- 下周计划:
- 跑通 Tennis 项目进行深入学习, 尝试其他司法数据相关网站的数据爬取.
- 学习感悟:
- 指导建议:
- 对毕设技术选型,数据库设计,系统架构进行规划.
26 2024-01-12 (学术例会)
26.1 IF
- 小标题修改
- 知识图谱研究现状部分的构建不提融合更新,否则与后面融合更新重合冗余
27 2024-01-14 (项目例会)
[!NOTE] 周会总结
- 已学内容:
- 学习 tennis 系统管理模块,设计毕设系统架构,数据库表设计,搭建后端基础框架,调研可行数据源(OpenLaw & 把手案例(需登录);12309 中国检察网 & 国家行政法规库(无需登录))以及爬取方案(设计 feapder 数据采集逻辑、集成 Crawlab/feaplat 爬虫管理系统)。
- 下周计划:
- 针对可行数据源设计特定爬虫,结合异构数据特征完善数据表设计,进行前端原型设计。
- 学习感悟:
- 指导建议:
28 2024-01-19 (学术例会)
28.1 IF
- 研究现状总结没有突出研究意义,前面现状简单总结突出各个研究内容的结果意义。
- 3.3 研究方法和技术路线,研究方法介绍具体用了哪些方法,技术路线要用图阐述技术路线,关键技术部分对用到的核心技术详细说明(包括公式、原理等)。
29 2024-01-21 (项目例会)
[!NOTE] 周会总结
- 已学内容:
- 学习 ruoyi-cloud-plus v1.8.2 脚手架,使用 feapder 重写 openlaw、国家行政法规库爬虫,进行前端原型设计。
- 下周计划:
- 继续学习 ruoyi-cloud-plus 脚手架,思考设计毕设需要的定制模块功能,完善补充优化爬虫。
- 学习感悟:
- 指导建议:
- 了解学习 seata 改进型雪花 id 算法
30 2024-01-26 (学术例会)
30.1 IF
- 摘要、研究目标、研究内容、关键科学问题几个部分,并把这几个部分的要点作出相应修改,更好地体现学术深度。
- 研究内容思路:研究主题(挑战+思路+研究内容)
31 2024-01-28 (项目例会)
[!NOTE] 周会总结
- 已学内容:
- 根据师兄推荐的视频学习若依脚手架(完成 80%),利用该框架搭建毕设系统实现司法案例与法律法规的基本管理,学习脚手架认证鉴权模块尝试改写。
- 下周计划:
- 继续按照视频学习脚手架并改写认证鉴权模块,实现毕设系统数据处理统计分析功能。
- 学习感悟:
- 指导建议:
- 发消息一定要及时回复
32 2024-02-02 (学术例会)
32.1 IF
[!tip] 重点
- 科学问题(研究的问题)不是科学难题(研究方法工具)
- 研究方法中的图转换过程中需要明确给出方法,输入输出清晰
33 2024-02-18 (学术和项目例会)
[!NOTE] 周会总结
- 已学内容:
- 完成系统管理模块通行证的基本管理。
- 完成毕业设计统计分析业务基本功能。
- 下周计划:
- 完成系统管理模块账户的基本管理。
- 撰写毕业设计开题报告,完成毕业设计的数据处理业务功能。
- 学习感悟:
- 指导建议:
34 2024-02-25 (项目例会)
[!NOTE] 周会总结
- 已学内容:
- 撰写毕业设计开题报告 40%,完成毕业设计的数据处理业务功能 60%。
- 完成 etms 系统管理模块账户的基本管理和注册基本功能。
- 下周计划:
- 完成毕业设计开题报告和数据处理业务功能。
- 完成 etms 系统管理模块账户的登录基本功能。
- 学习感悟:
- 指导建议:
35 2024-03-03 (项目例会)
[!NOTE] 周会总结
- 已学内容:
- 毕业设计开题报告撰写完成,完善毕业设计的系统的数据处理和消息推送业务功能。
- 完成 etms 登录认证和系统管理模块账户管理的基本功能。
- 下周计划:
- 查询并翻译毕设要求的文献,继续完善系统其他功能和爬虫设计。
- 学习感悟:
- 指导建议:日报每天都要写
36 2024-03-10 (项目例会)
[!NOTE] 周会总结
- 已学内容:
- 完成毕业设计文献翻译
- 实现 etms 手机号和邮箱注册登录功能,并完善用户管理相关功能
- 完成中间件环境和系统迁移
- 下周计划:
- 将本地爬虫云端部署,处理数据智能处理 bug,撰写阶段性报告,起草毕业设计论文大纲
- 调整 etms 角色权限业务逻辑,进行直播功能开发
- 学习感悟:
- 指导建议:
- 添加实名认证接口,修改用户身份证信息,将身份认证标识置 1;获取登录用户信息要包含是否已经实名认证(已完成)
- 实现手机号+验证码直接注册,手机号验证码先伪造假数据
- 实现创建人和更新人 id 转化为名字(通过翻译注解实现)
- 调研数据资产评估和管理的相关理论和方法,整理相关文献资料,可以分为评估和管理两大块来进行
- 辅助学术:
- 界面:一个搜索框,一个提交,一个重置按钮;输入事件(如果是段落则分段为句子进行事件检测)提交后返回检测结果,包含各个事件{events:[{“offset”,”trigger”,”type”},···],text};原始事件放在左边,触发词高亮,悬浮显示事件类型;右边一个表格列出各个事件的序号、事件类型、相关触发词、事件类型解释(悬浮有示例)、相同案件(遍历 redis 案例库包含事件类型相同的案件)和相似案件(相同案件进行相似度对比得到最相似的 rankN 案件)
- 搭建司法能力服务平台基础架构
- 任务梳理:
- 毕业设计(⭐⭐⭐⭐⭐):
- etms(⭐⭐⭐⭐⭐):
- 国重点(⭐⭐⭐):
- 学术汇报(⭐⭐⭐⭐):
- 落地辅助(⭐⭐⭐⭐):
- 司法服务平台基建(⭐⭐⭐⭐⭐):
- 个人生活(⭐⭐⭐⭐⭐没时间了):矫正牙齿,考驾照,锻炼身体
37 2024-03-15 (学术例会)
38 2024-03-17 (项目例会)
[!NOTE] 周会总结
- 已学内容:
- 下周计划:
- 开始开发毕业设计数据分析和 redis 监控功能,撰写第二次阶段性报告;
- 调整直播相关数据库表设计,开发直播课程增删改查基本操作接口;
- 配合师兄搭建司法服务平台基础架构
- 学习感悟:
- 指导建议:
- 总体任务:
- 毕业设计(⭐⭐⭐⭐⭐):测试本地爬虫云端部署,处理数据智能处理 bug,撰写阶段性报告,起草毕业设计论文大纲
- etms(⭐⭐⭐⭐⭐):账户管理处添加实名认证接口,实现手机号+验证码直接注册;实现直播频道、角色、分类和配置的增删改查基本操作
- 国重点(⭐⭐⭐):调研数据资产评估的相关理论和方法,整理相关文献资料
- 学术汇报(⭐⭐⭐⭐):
- 落地辅助(⭐⭐⭐⭐):
- 司法 AI 能力中心基建(⭐⭐⭐⭐⭐):
- 个人生活(⭐⭐⭐⭐⭐没时间了):矫正牙齿,考驾照,锻炼身体
39 2024-03-22 (学术例会)
- kpi,eiofs:踏实做好每一件事情,结果水到渠成
40 2024-03-24 (项目例会)
[!NOTE] 周会总结
- 已学内容:
- 完成毕业设计基础数据分析和 redis 监控功能,撰写第二次阶段性报告;
- 调整直播相关数据库表设计,开发直播课程增删改查等基本操作接口;
- 选择 AICC 基础架构,搭建基本项目工程
- 下周计划:
- 补充毕业设计数据处理方法并检测修复存在的 bug,撰写毕业设计论文绪论部分。
- 修改配置 AICC 平台依赖的中间件,辅助师兄毕业设计功能落地。
- 学习感悟:
- 指导建议:
- 爬虫能爬多少爬取多少([128193,1892,793699,352047,38308])
- 增加多个数据源,除了 openlaw,还要添加其他的
- 请假的人,主管要问清楚代其汇报工作内容
- 总体任务:
- 毕业设计(⭐⭐⭐⭐⭐):
- etms(⭐⭐⭐⭐⭐):
- 国重点(⭐⭐⭐):对数据资产的评价(通用信息度量+领域信息度量);精细化管理【对多方面实践服务具体如何体现(结合任务反向思考应该设计哪些指标)】
- 学术汇报(⭐⭐⭐⭐):
- 落地辅助(⭐⭐⭐⭐):
- 司法服务平台基建(⭐⭐⭐⭐⭐):
- 个人生活(⭐⭐⭐⭐⭐没时间了):矫正牙齿,考驾照,锻炼身体
41 2024-03-29 (学术例会)
- 学术汇报论文先用通俗易懂的语言把论文核心思想引言思路讲清楚,先让听者快速把我论文核心思想内容,了解背景目的,可以写好前沿介绍后用大模型用高中生能理解的话说清楚。
42 2024-03-31 (项目例会)
[!NOTE] 周会总结
已学内容:
- 直播课程功能按照原型设计和飞书要求进行调整(支持单场直播新建)
- 毕业设计论文整体格式规划与修改
- 爬取更多司法数据,爬取司法案例数量为 18w 左右
下周计划:
- 撰写论文第二章相关技术理论部分
- 阅读论文并整理
- 尝试爬取人民法院案例库
- 完善 aicc 落地功能
学习感悟:
指导建议:
- 完成阿里云手机号注册登录修改
- 完成直播互动(连麦,举手,发言,聊天)
- 完成直播视频回访录制并保存
- 直播用保利威自带的直播系统,还是单独自己的
- 直播课程回放用保存的 180 天的录制视频(看不到白板和课件,只能看到直播者头像和声音,无法对观看数据进行统计),还是用回访列表或点播列表(点播列表可添加点播视频,按照点播配置计费)
- 如何将直播或者回放的观众与学员关联,实现学员观看数据统计
- 外部授权需要回调接口,获取系统用户并授权观看直播
总体任务:
- 毕业设计(⭐⭐⭐⭐⭐):
- etms(⭐⭐⭐⭐⭐):
- 国重点(⭐⭐⭐):
- 学术汇报(⭐⭐⭐⭐):
- 落地辅助(⭐⭐⭐⭐):
- 司法服务平台基建(⭐⭐⭐⭐⭐):
- 个人生活(⭐⭐⭐⭐⭐没时间了):矫正牙齿,考驾照,锻炼身体
43 2024-04-06 (项目例会)
[!NOTE] 周会总结
- 已学内容:
- 撰写毕业设计论文第二章关键技术概述 60%
- 爬取人民法院案例库 3000 余条数据
- 直播录制回放和数据统计工具类封装
- 下周计划:
- 继续撰写毕业设计论文第二章关键技术概述和第三章平台系统设计内容
- 修改完善毕设系统(检索展示,首页面板)
- 开发直播回放录制保存播放相关接口
- 学习 TypeScript
- 学习感悟:
- 指导建议:
- 总体任务:
- 毕业设计(⭐⭐⭐⭐⭐):
- etms(⭐⭐⭐⭐⭐):
- 国重点(⭐⭐⭐):
- 学术汇报(⭐⭐⭐⭐):
- 落地辅助(⭐⭐⭐⭐):
- 司法服务平台基建(⭐⭐⭐⭐⭐):
- 个人生活(⭐⭐⭐⭐⭐没时间了):矫正牙齿,考驾照,锻炼身体
44 2024-04-14 (项目例会)
[!NOTE] 周会总结
- 已学内容:
- 毕业设计论文第三章平台系统设计撰写 50%
- 修复毕业设计系统检索展示和其他已知 bug
- 开发直播外嵌的访问授权、查询直播或回放视频、添加点播视频到直播播放列表接口
- 下周计划:
- 继续撰写设计论文第三章平台系统设计和第四章
- 毕业设计系统添加案件知识图谱构建功能(不一定做)
- 调研现有数据资产综合效能评估指标体系,分门别类汇总梳理。
- 直播课程根据原型图和需求进行检查补充没做的接口(课程课件的查询展示,给出课件链接)
- 观看 DDD 相关视频
- 调整 id 对应的具体附加内容查询展示
- 查询项目所有的直播课程,根据项目 id 查询其所有的直播课程
- 学习感悟:
- 指导建议:
- 总体任务:
- 毕业设计(⭐⭐⭐⭐⭐):
- etms(⭐⭐⭐⭐⭐):
- 国重点(⭐⭐⭐):
- 学术汇报(⭐⭐⭐⭐):
- 落地辅助(⭐⭐⭐⭐):
- 司法服务平台基建(⭐⭐⭐⭐⭐):
- 个人生活(⭐⭐⭐⭐⭐没时间了):矫正牙齿,考驾照,锻炼身体
45 2024-04-19 (学术例会)
[!NOTE] 周会总结
- 已学内容:
- 毕业设计论文第三章和第四章(60%)撰写
- 毕业设计系统修改完善(修复并补充消息推送业务)
- 直播课程接口完善(直播课程关联的课程、项目、课件和专家等的增删改查)及测试(回调授权)完成 70%
- 下周计划:
- 按照需求开发 AICC 前后端功能
- 继续撰写毕业设计论文第四章平台系统设计和第五章
- 查询所有学科列表,课程讨论,课程大纲,补充附件的格式、大小
- 添加课程使用频次字段,当项目添加课程时频次+1;除此以外根据飞书 Docs 数据表头里的课程数据补全现有课程数据表字段
- 学习感悟:
- 指导建议:
- 分节整理评价指标:指标定义,实施方法,评价结果
- 基础指标,借鉴其他领域指标,司法特色指标
- 总体任务:
- 毕业设计(⭐⭐⭐⭐⭐):
- etms(⭐⭐⭐⭐⭐):
- 国重点(⭐⭐⭐):
- 学术汇报(⭐⭐⭐⭐):
- 落地辅助(⭐⭐⭐⭐):
- 司法服务平台基建(⭐⭐⭐⭐⭐):
- 个人生活(⭐⭐⭐⭐⭐没时间了):矫正牙齿,考驾照,锻炼身体
46 2024-05-17(项目例会)
[!NOTE] 周会总结
- 已学内容:
- 撰写毕业设计论文第四章和第五章(85%)并重新入库毕业设计系统的数据库表
- 直播课程业务代码优化与完善(补充课程表相关字段、查询课程学科树并优化查询课程速度)及测试
- 下周计划:
- 撰写完毕业设计初稿内容(参考文献)
- 完善毕业设计系统完整功能测试(下周要进行演示)
- 完善系统管理的双 token 授权和刷新、密码登录改为非对称加密(待商量)
- 添加学员选课相关接口,多选多个课程(必修、选修)
- 联调测试并修改直播课程相关业务接口功能
- 开发 AICC 事件抽取落地的文书管理业务接口
- 整理撰写 GLED 论文实验部分
- 调研国重点(综合指标、服务审判执行指标、服务廉洁司法指标、服务社会经济发展指标、服务人民群众指标,目前应用指标属于数据本身统计指标不是数据资产评价的指标),继续调研和梳理数据资产评价指标以及评价方法,从五个维度探究,基础维度、质量维度、应用维度、成本维度、风险维度,各维度细分一级指标和二级指标等,先确定指标和简单的方法描述
- 问题记录:
- oss 上传服务有问题?
- 指导建议:
- 总体任务:
- 毕业设计(⭐⭐⭐⭐⭐):
- etms(⭐⭐⭐⭐⭐):
- 国重点(⭐⭐⭐):
- 学术汇报(⭐⭐⭐⭐):
- 落地辅助(⭐⭐⭐⭐):
- 司法服务平台基建(⭐⭐⭐⭐⭐):
- 个人生活(⭐⭐⭐⭐⭐没时间了):矫正牙齿,考驾照,锻炼身体

47 2024-05-05(项目例会)
[!NOTE] 周会总结
- 已做内容:
- 撰写完毕业设计初稿内容
- 修改密码登录改为非对称加密,优化并测试直播课程新增和修改等接口
- 开发 AICC 的文书管理业务接口
- 下周计划:
- 根据建议修改毕业设计初稿内容和系统
- 联调优化直播课程相关接口
- 开发完善 AICC 文书管理的文书正文和案件事实检索,和基于案件事实的同事件类型检索和类案检索(待提供第三方接口)
- 引用参考文献 30 个左右,文献近五年内的,中文占比 20%,英文一半以上,参考文献格式按照要求一个个对照。
- 爬虫换为数据采集,查看网站是否有禁止采集,查看 robots.txt 协议
- 论文格式一定要规范。
- 修改论文图片进行打码处理
- 调试 aicc 服务是否能够正常启动运行响应
- 录取调挡函等信息处理
- 撰写毕业登记表
- 学习感悟:
- 问题记录:
- 指导建议:
- 总体任务:
- 毕业设计(⭐⭐⭐⭐⭐):
- etms(⭐⭐⭐⭐⭐):
- 国重点(⭐⭐⭐):
- 学术汇报(⭐⭐⭐⭐):
- 落地辅助(⭐⭐⭐⭐):
- 司法服务平台基建(⭐⭐⭐⭐⭐):
- 个人生活(⭐⭐⭐⭐⭐没时间了):矫正牙齿,考驾照,锻炼身体
48 2024-05-10 (学术例会)
[!NOTE] 周会总结
- 已做内容:
- 下周计划:
- 对小论文实验部分检查阅读,进行修改
- 对专利进行检查修改,看代理人是否表述正确
- 学习感悟:
- 问题记录:
- 指导建议:
- 总体任务:
- 毕业设计(⭐⭐⭐⭐⭐):
- etms(⭐⭐⭐⭐⭐):
- 国重点(⭐⭐⭐):
- 学术汇报(⭐⭐⭐⭐):
- 落地辅助(⭐⭐⭐⭐):
- 司法服务平台基建(⭐⭐⭐⭐⭐):
- 个人生活(⭐⭐⭐⭐⭐没时间了):矫正牙齿,考驾照,锻炼身体
49 2024-05-12(项目例会)
[!NOTE] 周会总结
- 已做内容:
- 修改毕业设计论文;
- 修改直播课程服务调用逻辑并测试;
- 完成 AICC 基本服务流水线部署
- 下周计划:
- [ ] 根据反馈意见进一步修改完善并查重,准备答辩 PPT;
- [ ] 联调直播课程相关接口;
- [x] 开发完善 AICC 文书管理的文书正文和案件事实获取业务- 学习感悟:
- 问题记录:
- 指导建议:
- 二级指标综合起来形成两三个综合指标,以及分清正负指标,弄清楚真正有效的指标
- etms 实名认证补充完善,联调直播课程接口
- 补充统计相关接口
- 总体任务:
- 毕业设计(⭐⭐⭐⭐⭐):
- etms(⭐⭐⭐⭐⭐):
- 国重点(⭐⭐⭐):
- 学术汇报(⭐⭐⭐⭐):
- 落地辅助(⭐⭐⭐⭐):
- 司法服务平台基建(⭐⭐⭐⭐⭐):
- 个人生活(⭐⭐⭐⭐⭐没时间了):矫正牙齿,考驾照,锻炼身体
50 2024-05-17(学术例会)
[!NOTE] 周会总结
- 已做内容:
- 下周计划:
- 学习感悟:
- 问题记录:
- 指导建议:
- 范围提示,领域提示+COT 提示
- 总体任务:
- 毕业设计(⭐⭐⭐⭐⭐):
- etms(⭐⭐⭐⭐⭐):
- 国重点(⭐⭐⭐):
- 服务司法管理(政务管理、队伍建设、审判管理);
- 服务人民群众:老百姓、当事人、代理人
- 服务廉洁司法:内部监督(信访、举报、抗诉),外部公开
- 学术汇报(⭐⭐⭐⭐):
- 落地辅助(⭐⭐⭐⭐):
- 司法服务平台基建(⭐⭐⭐⭐⭐):
- 个人生活(⭐⭐⭐⭐⭐没时间了):矫正牙齿,考驾照,锻炼身体

51 2024-05-19(项目例会)
[!NOTE] 周会总结
- 已做内容:
- 联调直播课程和账户管理相关功能,修复并补充相关接口;
- 进行数据资产评价指标调研;
- 开发完善 AICC 文书管理的司法案件正文和案件事实获取功能。
- 下周计划:
- 继续联调修改直播课程和账户管理相关功能。
- 根据建议修改论文,制作毕业设计答辩 PPT
- 进行数据资产评价指标调研分析;
- 继续开发完善 AICC 事件检测落地相关功能。
- 学习感悟:
- 问题记录:
- 指导建议:
- 法院数据资产综合效能的指标,不是业务指标
- 总体任务:
- 毕业设计(⭐⭐⭐⭐⭐):
- etms(⭐⭐⭐⭐⭐):
- 国重点(⭐⭐⭐):
- 学术汇报(⭐⭐⭐⭐):
- 落地辅助(⭐⭐⭐⭐):
- 司法服务平台基建(⭐⭐⭐⭐⭐):
- 个人生活(⭐⭐⭐⭐⭐没时间了):矫正牙齿,考驾照,锻炼身体
52 2024-05-24(学术例会)
[!NOTE] 周会总结
- 已做内容:
- 下周计划:
- 学习感悟:
- 问题记录:
- 指导建议:
- 每次检测后把该案件的事件类型设计一个表(表结构需要设计,触发词,事件类型,还有位置信息,位置信息包括第几句话,偏移量)存储起来,便于后续相同事件类型的案件检索
- 学习云原生云计算相关技术,docker 和 k8s
- 总体任务:
- 毕业设计(⭐⭐⭐⭐⭐):
- etms(⭐⭐⭐⭐⭐):
- 国重点(⭐⭐⭐):
- 学术汇报(⭐⭐⭐⭐):
- 落地辅助(⭐⭐⭐⭐):
- 司法服务平台基建(⭐⭐⭐⭐⭐):
- 个人生活(⭐⭐⭐⭐⭐没时间了):矫正牙齿,考驾照,锻炼身体
53 2024-05-26(项目例会)
[!NOTE] 周会总结
- 已做内容:
- 联调修改直播课程和账户管理相关功能
- 根据建议修改论文,制作毕业设计答辩 PPT
- 进行数据资产评价指标调研分析
- 下周计划:
- 准备答辩讲稿和演示视频
- 联调修改直播课程和账户管理相关功能
- 进行数据资产评价指标调研分析
- 调研 AICC 数据库单表压力过大解决办法
- 学习感悟:
- 问题记录:
- expertName,hostName
- 直播开始结束等状态改变的回调接口
- 指导建议:
- 总体任务:
- 毕业设计(⭐⭐⭐⭐⭐):
- etms(⭐⭐⭐⭐⭐):
- 国重点(⭐⭐⭐):
- 学术汇报(⭐⭐⭐⭐):
- 落地辅助(⭐⭐⭐⭐):
- 司法服务平台基建(⭐⭐⭐⭐⭐):
- 个人生活(⭐⭐⭐⭐⭐没时间了):矫正牙齿,考驾照,锻炼身体
54 2024-06-02(项目例会)
[!NOTE] 周会总结
- 已做内容:
- 撰写答辩讲稿和录制演示视频
- 联调修改直播课程相关功能(完成 75%)
- 完成 AICC 摘要抽取和事件检测并保存接口
- 下周计划:
- 联调修改直播观看、管理和数据统计相关接口
- 联调测试 AICC 现有功能,开发相同事件类型检测接口
- 学习感悟:
- 问题记录:
- 指导建议:
- 总体任务:
- 毕业设计(⭐⭐⭐⭐⭐):
- etms(⭐⭐⭐⭐⭐):
- 国重点(⭐⭐⭐):
- 学术汇报(⭐⭐⭐⭐):
- 落地辅助(⭐⭐⭐⭐):
- 司法服务平台基建(⭐⭐⭐⭐⭐):
- 个人生活(⭐⭐⭐⭐⭐没时间了):矫正牙齿,考驾照,锻炼身体
55 2024-06-10(项目例会)
[!NOTE] 周会总结
- 已做内容:
- etms:联调修改系统管理和直播课程相关功能(用户过滤,数据权限,课程展示等)
- aicc:添加相同事件类型查询
- 下周计划:
- etms:联调修改直播课程观看,修改补充相关权限,修改飞书上提出的相关 bug。
- aicc:补充完善其他落地接口
- 学习感悟:
- 问题记录:
- 日常管理:约球,打球,场馆
- 指导建议:
- 国重点:借鉴写得好的指标体系,关联效能不够,指标不具代表性
- 总体任务:
- 毕业设计(⭐⭐⭐⭐⭐):完成终稿修订上传
- etms(⭐⭐⭐⭐⭐):从 oss 文件删除逻辑中解除与其所有的关联关系;微服务批处理;统一处理数据表结构命名规范(system 表迁移),补充数据权限和修改权限
- 国重点(⭐⭐⭐):借鉴写得好的指标体系,关联效能不够,指标不具代表性
- 学术汇报(⭐⭐⭐⭐):
- AICC(⭐⭐⭐⭐⭐):
- 个人生活(⭐⭐⭐⭐⭐没时间了):矫正牙齿,考驾照,锻炼身体
56 2024-06-16(项目例会)
[!NOTE] 周会总结
- 已做内容:
- etms:联调人员模块,系统模块和课程管理相关接口,打通用户注册登录,人员新建,账户新增,直播新增修改流程。
- aicc:联调注册登陆和文书管理接口
- 下周计划:
- etms:联调我的培训的课程学习与统计相关接口
- aicc:开发文书关系抽取和判决预测接口
- 学习感悟:
- 问题记录:
- 指导建议:
- 总体任务:
- 毕业设计(⭐⭐⭐⭐⭐):
- etms(⭐⭐⭐⭐⭐):
- 国重点(⭐⭐⭐):
- 学术汇报(⭐⭐⭐⭐):
- 落地辅助(⭐⭐⭐⭐):
- 司法服务平台基建(⭐⭐⭐⭐⭐):
- 个人生活(⭐⭐⭐⭐⭐没时间了):矫正牙齿,考驾照,锻炼身体
57 2024-06-23(项目例会)
[!NOTE] 周会总结
- 已做内容:
- etms:根据反馈修复人员模块、系统模块和直播课程管理相关问题,完善个人中心和多账号登录和切换。
- aicc:调通落地模型接口
- 下周计划:
- etms:联调我的培训的课程学习与统计相关接口
- aicc:开发文书关系抽取接口
- 学习感悟:
- 问题记录:
- 指导建议:
- 总体任务:
- 毕业设计(⭐⭐⭐⭐⭐):
- etms(⭐⭐⭐⭐⭐):
- 国重点(⭐⭐⭐):
- 学术汇报(⭐⭐⭐⭐):
- 落地辅助(⭐⭐⭐⭐):
- 司法服务平台基建(⭐⭐⭐⭐⭐):
- 个人生活(⭐⭐⭐⭐⭐没时间了):矫正牙齿,考驾照,锻炼身体
58 2024-07-07(项目例会)
[!NOTE] 周会总结
- 已做内容:
- etms:根据飞书反馈修复系统、人员和直播课程模块存在的相关问题
- etms:添加账号登录和操作日志功能
- DBA&Server:为实习生分配 cmis,ftp 账号
- DBA&Server:处理运维出现的问题,清理出无人使用的电脑
- 下周计划:
- etms:梳理完善各种删除关联关系相关功能,开发测试直播基础统计相关功能,并继续跟进修复飞书出现的问题
- DBA&Server:为重大同学分配 GPU 容器
- 学习感悟:
- 问题记录:
- 指导建议:
- 总体任务:
- 毕业设计(⭐⭐⭐⭐⭐):
- etms(⭐⭐⭐⭐⭐):
- 国重点(⭐⭐⭐):
- 学术汇报(⭐⭐⭐⭐):
- 落地辅助(⭐⭐⭐⭐):
- 司法服务平台基建(⭐⭐⭐⭐⭐):
- 个人生活(⭐⭐⭐⭐⭐没时间了):矫正牙齿,考驾照,锻炼身体
59 2024-07-21(项目例会)
[!NOTE] 周会总结
- 已做内容:
- etms:修复飞书文档和腾讯文档上提出的与人员管理,课程管理,系统管理相关问题。
- dbserv:备份 etms 数据库和 oss 文件。
- dbserv:迁移 k8s mysql 数据库到虚拟机部署主从库,恢复相关数据和定时任务。
- 下周计划:
- etms:继续跟进修复人员管理,课程管理,系统管理相关问题。
- dbserv:排查定时任务异常并修复,维护 k8s 集群正常运行。
- 学习感悟:
- 问题记录:
- 指导建议:
- 总体任务:
- 毕业设计(⭐⭐⭐⭐⭐):
- etms(⭐⭐⭐⭐⭐):
- 国重点(⭐⭐⭐):
- 学术汇报(⭐⭐⭐⭐):
- 落地辅助(⭐⭐⭐⭐):
- 司法服务平台基建(⭐⭐⭐⭐⭐):
- 个人生活(⭐⭐⭐⭐⭐没时间了):矫正牙齿,考驾照,锻炼身体
[!NOTE] 周会总结
- 已做内容:
- etms:修复并优化学员导入相关问题。
- dbserv:修复五个服务的相关漏洞(强密码校验,限制登陆,XSS 攻击)
- 下周计划:
- etms:解决飞书上新提出的相关问题,添加 ssl 证书。
- dbserv:恢复服务器及相关集群。
- 学习感悟:
- 问题记录:
- 指导建议:
- 总体任务:
- 毕业设计(⭐⭐⭐⭐⭐):
- etms(⭐⭐⭐⭐⭐):
- 国重点(⭐⭐⭐):
- 学术汇报(⭐⭐⭐⭐):
- 落地辅助(⭐⭐⭐⭐):
- 司法服务平台基建(⭐⭐⭐⭐⭐):
- 个人生活(⭐⭐⭐⭐⭐没时间了):矫正牙齿,考驾照,锻炼身体
60 2024-09-22 (项目例会)
[!NOTE] 周会总结
- 已做内容:
etms:
- 优化登录、注册和个人信息获取接口性能。
- 完善 ETMS 个人中心信息的修改。
- 导入北师大提供的学校和修改部分学校信息。
- 添加项目成员和项目学员学情的导出接口。
- 添加直播观看日志定时获取并更新接口。
- 实现项目邀请码宽限匹配和调整邀请码为 6 位数字。
- 完善直播统计表结构(添加观看类型,直播时长,回放时长)等字段,修改观看数据同步接口。
dbserv:
- 为五位大创实习生配置电脑
- 下周计划:
etms:
- 完成保利威直播观看日志的同步和学员观看数据的更新
- 调整外部授权回放观看接口,采用点播列表进行回放
- 排查修复通信证和账号对人员 id 错误绑定问题
- 修复内部和外部 bug 表中我的培训、人员管理、系统管理和项目管理等问题
- 学习感悟:
- 问题记录:
- 指导建议:
- 总体任务:
- 毕业设计(⭐⭐⭐⭐⭐):
- etms(⭐⭐⭐⭐⭐):
- 国重点(⭐⭐⭐):
- 学术汇报(⭐⭐⭐⭐):
- 落地辅助(⭐⭐⭐⭐):
- 司法服务平台基建(⭐⭐⭐⭐⭐):
- 个人生活(⭐⭐⭐⭐⭐没时间了):矫正牙齿,考驾照,锻炼身体
61 2024-10-07 (项目例会)
[!NOTE] 周会总结
- 已做内容:
- 调整完善项目学员学情的导出接口。
- 完善直播和点播回放日志(包括登记观看)的同步和学员观看数据的更新。
- 调整直播数据库表字段,完善直播回调接口。
- 添加项目邀请码过期时间。
- 解决内部和外部 bug 表负责的 bug。
- 下周计划:
- 着手制作伪直播。
- 添加超级管理人员直接切换通行证登录的功能。
- 继续解决工作安排表以及北师大反馈表提出的 bug。
- 学习感悟:
- 问题记录:
- 指导建议:
- 总体任务:
- 毕业设计(⭐⭐⭐⭐⭐):
- etms(⭐⭐⭐⭐⭐):
- 国重点(⭐⭐⭐):
- 学术汇报(⭐⭐⭐⭐):
- 落地辅助(⭐⭐⭐⭐):
- 司法服务平台基建(⭐⭐⭐⭐⭐):
- 个人生活(⭐⭐⭐⭐⭐没时间了):矫正牙齿,考驾照,锻炼身体
62 2024-10-13 (项目例会)
[!NOTE] 周会总结
- 已做内容:
- 优化完善学员导入异常的错误提示(去除空白符和部分符号转换)。
- 添加项目和统计微服务的健康监测端点和配置存活探针。
- 开发伪直播功能相关接口。
- 优化调整学员直播观看数据的更新方式为增量更新。
- 为新生分配 CMIS 和 FTP 账号和电脑。
- 下周计划:
- 继续开发伪直播相关接口功能。
- 按照项目学员学习模板调整学情导出接口。
- 继续解决工作安排表以及北师大反馈表提出的 bug。
- 学习感悟:
- 问题记录:
- 指导建议:
- 总体任务:
- 毕业设计(⭐⭐⭐⭐⭐):
- etms(⭐⭐⭐⭐⭐):
- 国重点(⭐⭐⭐):
- 学术汇报(⭐⭐⭐⭐):
- 落地辅助(⭐⭐⭐⭐):
- 司法服务平台基建(⭐⭐⭐⭐⭐):
- 个人生活(⭐⭐⭐⭐⭐没时间了):矫正牙齿,考驾照,锻炼身体
63 2024-10-20(项目例会)
[!NOTE] 周会总结
- 已做内容:
- 添加登录日志和操作日志相关接口。
- 修复仅有通信证没有账号的异常学员。
- 开发伪直播功能相关接口(80%)。
- 调整健康监测端点监控内存情况。
- 修改数据备份日志格式。
- 排查访问异常境外 IP。
- 下周计划:
- 完成伪直播的开发测试。
- 开发直播学情导出接口。
- 开发直播免费观看和链接分享功能。
- 跟进对接保利威优化完善数据同步接口。
- 继续解决工作安排表以及北师大反馈表提出的 bug。
- 做好攻防演练准备
- 学习感悟:
- 问题记录:
- 指导建议:
- 总体任务:
- 毕业设计(⭐⭐⭐⭐⭐):
- etms(⭐⭐⭐⭐⭐):
- 国重点(⭐⭐⭐):
- 学术汇报(⭐⭐⭐⭐):
- 落地辅助(⭐⭐⭐⭐):
- 司法服务平台基建(⭐⭐⭐⭐⭐):
- 个人生活(⭐⭐⭐⭐⭐没时间了):矫正牙齿,考驾照,锻炼身体
64 2024-10-27(项目例会)
[!NOTE] 周会总结
- 已做内容:
- 为需要的接口添加统一日志。
- 新增超级管理员用户快速账户切换功能。
- 优化直播统计功能和数据同步策略(定时每 5 分钟获取前 4 小时日志并更新)。
- 开发测试伪直播(90%)。
- 攻防演练应对(关闭除 srdb,smdb,hsas 外的外网访问,检查 EDR 安装情况)。
- 下周计划:
- 开发直播免费观看和链接分享功能。
- 开发联调机构管理相关接口。
- 开发研讨会相关功能。
- 开发项目和任务学情导出功能。
- 学习感悟:
- 问题记录:
- 指导建议:
- 总体任务:
- 毕业设计(⭐⭐⭐⭐⭐):
- etms(⭐⭐⭐⭐⭐):
- 国重点(⭐⭐⭐):
- 学术汇报(⭐⭐⭐⭐):
- 落地辅助(⭐⭐⭐⭐):
- 司法服务平台基建(⭐⭐⭐⭐⭐):
- 个人生活(⭐⭐⭐⭐⭐没时间了):矫正牙齿,考驾照,锻炼身体
65 2024-11-03(项目例会)
[!NOTE] 周会总结
- 已做内容:
- 各模块添加符合要求的日志记录。
- 完成通过手机号或者通信证快速切换账号。
- 完成伪直播开发测试。
- 添加直播观看数据日同步更新功能。
- 优化项目和统计微服务内存溢出监控逻辑。
- 下周计划:
- 开发线上教研相关功能。
- 联调直播免费观看功能。
- 开发简易注册功能。
- 继续解决工作安排表以及北师大反馈表提出的 bug。
- 学习感悟:
- 问题记录:
- 指导建议:
- 总体任务:
- 毕业设计(⭐⭐⭐⭐⭐):
- etms(⭐⭐⭐⭐⭐):
- 国重点(⭐⭐⭐):
- 学术汇报(⭐⭐⭐⭐):
- 落地辅助(⭐⭐⭐⭐):
- 司法服务平台基建(⭐⭐⭐⭐⭐):
- 个人生活(⭐⭐⭐⭐⭐没时间了):矫正牙齿,考驾照,锻炼身体
66 2024-11-10(项目例会)
[!NOTE] 周会总结
- 已做内容:
- 基础镜像加入 arthas 并更新到每个微服务中。
- 开发线上研讨相关功能(40%)。
- 开发完成用户简易注册功能。
- 下周计划:
- 继续开发线上研讨相关功能(认证授权、接口回调、数据同步)。
- 着手改造直播课程体系。
- 继续解决工作安排表以及北师大反馈表提出的 bug。
- 学习感悟:
- 问题记录:
- 指导建议:
- 总体任务:
- 课程学习(⭐⭐⭐⭐⭐):
- etms(⭐⭐⭐⭐⭐):
- 国重点(⭐⭐⭐):
- 学术汇报(⭐⭐⭐⭐):
- 个人生活(⭐⭐⭐⭐⭐没时间了):矫正牙齿,锻炼身体
67 2024-11-17(项目例会)
[!NOTE] 周会总结
- 已做内容:
- 给新生做 ETMS 后端框架整体内容概述讲解。
- 系统选项表添加 isAvailable 字段标识选项可用性。
- 实现简易注册和个人信息完善。
- 修改伪直播文件上传处理逻辑。
- 开发直播免费观看接口。
- 思考直播结构调整修改方案。
- 开发线上教研认证授权相关接口。
- 下周计划:
- 继续解决工作安排表以及北师大反馈表提出的 bug。
- 继续改造直播课程体系(一门直播课程允许包含采用不同频道号的多个排课)。
- 继续开发线上教研相关功能(接口回调、数据同步)
- 学习感悟:
- 问题记录:
- 指导建议:
- 总体任务:
- 课程学习(⭐⭐⭐⭐⭐):
- etms(⭐⭐⭐⭐⭐):
- 国重点(⭐⭐⭐):
- 学术汇报(⭐⭐⭐⭐):
- 个人生活(⭐⭐⭐⭐⭐没时间了):矫正牙齿,锻炼身体
68 2024-12-01(项目例会)
[!NOTE] 周会总结
- 已做内容:
- 开发线上教研相关功能(接口回调、数据同步,70%)。
- 完善免费直播配置和匿名用户观看。
- 补充 ETMS 的 SSL 证书的协议配置以支持更低版本。
- 完成 ETMS 一期详细设计文档撰写。
- 完善直播日志同步逻辑和数据库约束。
- 对直播课程排课体系进行改造(20%)。
- 下周计划:
- 继续开发线上研讨功能(回调授权、日志同步、数据统计等)。
- 搭建 BEMS 后端框架+中间件+数据库表+流水线。
- 继续修复 ETMS 客户提出的有关问题。
- 学习感悟:
- 问题记录:
- 指导建议:
- 总体任务:
- 毕业设计(⭐⭐⭐⭐⭐):
- etms(⭐⭐⭐⭐⭐):
- 国重点(⭐⭐⭐):
- 学术汇报(⭐⭐⭐⭐):
- 落地辅助(⭐⭐⭐⭐):
- 司法服务平台基建(⭐⭐⭐⭐⭐):
- 个人生活(⭐⭐⭐⭐⭐没时间了):矫正牙齿,考驾照,锻炼身体
69 2024-12-08(项目例会)
[!NOTE] 周会总结
- 已做内容:
- 线上教研相关功能后端开发(接口回调、数据同步待测试,90%)。
- 完成 ETMS 一期性能测试文档撰写。
- 搭建 BEMS 中间件(nacos、redis)+流水线。
- 修复群里提出的相关 bug。
- 下周计划:
- 完成线上教研联调测试。
- 部署测试库和正式库流水线。
- 继续修复 ETMS 用户提出的有关问题。
- 学习感悟:
- 问题记录:
- 指导建议:
- 总体任务:
- 毕业设计(⭐⭐⭐⭐⭐):
- etms(⭐⭐⭐⭐⭐):
- 国重点(⭐⭐⭐):
- 学术汇报(⭐⭐⭐⭐):
- 落地辅助(⭐⭐⭐⭐):
- 司法服务平台基建(⭐⭐⭐⭐⭐):
- 个人生活(⭐⭐⭐⭐⭐没时间了):矫正牙齿,考驾照,锻炼身体
70 2024-12-15(项目例会)
[!NOTE] 周会总结
- 已做内容:
- 线上教研相关功能后端开发基本完成(待联调测试)。
- OSS 添加防盗链配置。
- 修复北师大群里提出的紧急 bug(通行证删除、人员导入、直播修改、性别规整等)
- 部署 BEMS 测试库和正式库流水线和前后端项目部署。
- 下周计划:
- 联调完成线上教研相关功能。
- 对直播录播视频进行加密,防止盗用。
- 继续解决反馈的 bug。
- 分页查询完善(比如排序等,参考 etms)。
- 导入导出与模板下载(学校、教师和学生)。
- 导入 BEMS 基础数据,测试系统并发布上线。
- 学习感悟:
- 问题记录:
- 指导建议:
- 总体任务:
- 毕业设计(⭐⭐⭐⭐⭐):
- etms(⭐⭐⭐⭐⭐):
- 国重点(⭐⭐⭐):
- 学术汇报(⭐⭐⭐⭐):
- 落地辅助(⭐⭐⭐⭐):
- 司法服务平台基建(⭐⭐⭐⭐⭐):
- 个人生活(⭐⭐⭐⭐⭐没时间了):矫正牙齿,考驾照,锻炼身体
71 2024-12-22(项目例会)
[!NOTE] 周会总结
- 已做内容:
- ETMS
- 添加手机号密码登录以及手机号姓名自动注册登录。
- 联调线上教研 50%。
- 完善登录和操作日志相关接口。
- 部署完成 xxl-job 服务(统一管理定时任务)。
- BEMS
- 修改前后端整体配置,测试功能的可用性。
- 对部分数据进行规范化修正处理。
- 按照入库数据修改数据库和对齐字段。
- 设计学生、教师的导入模板,学生和教师信息导入功能。
- 完善学生、教师列表的分页查询,排序、字段补充等。
- SRDB
- 调整邀请成员加入专题的邮件模板。
- 排查修复专题页面相关接口的权限校验异常。- 下周计划:
- ETMS
- 联调完成线上教研相关功能。
- 对接保利威处理防盗链问题。
- BEMS
- 按照模板规范导入数据入库。
- 前后端联调。
- SMDB
- 排查重新登录验证码错误问题。
- 排查非 admin 的超级用户菜单显示和无权限显示账户详情问题。
- 排查系统日志为空和登录用户的 IP 记录异常问题。
- 学习感悟:
- 问题记录:
- 指导建议:
- 总体任务:
- 毕业设计(⭐⭐⭐⭐⭐):
- etms(⭐⭐⭐⭐⭐):
- 国重点(⭐⭐⭐):
- 学术汇报(⭐⭐⭐⭐):
- 落地辅助(⭐⭐⭐⭐):
- 司法服务平台基建(⭐⭐⭐⭐⭐):
- 个人生活(⭐⭐⭐⭐⭐没时间了):矫正牙齿,考驾照,锻炼身体
72 2024-12-29(项目例会)
[!NOTE] 周会总结
- 已做内容:
- ETMS
- 完善登录日志和操作日志结构信息。
- 完成线上教研联调测试。
- 完成防盗链配置。
- 旧平台学员数据导入。
- 修改日志清理定时任务时间。- BEMS
- 完成学生和教师数据入库。
- 按照讨论结果修改数据库和对齐字段;
- 优化完善后端学校、学生基本信息与学习信息和教师基本信息和工作信息的增删改查、导出功能;
- 修改学生、教师数据的导入逻辑与数据处理;
- 修改前端样式及字段,完成学校、学生和学生学习信息页面设计,
- 联调测试学生、学校部分;- SRDB
- 调整邮件模板的发件人为专题数据库运营人员。- 下周计划:
- ETMS
- 继续解决反馈的 bug。
- 开发直播课程和线上教研以及专家和学员相关统计报表接口。- BEMS
- 教师详情页和工作页面的设计。
- 发布正式库开放使用。- 学习感悟:
- 问题记录:
- 指导建议:
- 总体任务:
- 毕业设计(⭐⭐⭐⭐⭐):
- etms(⭐⭐⭐⭐⭐):
- 国重点(⭐⭐⭐):
- 学术汇报(⭐⭐⭐⭐):
- 落地辅助(⭐⭐⭐⭐):
- 司法服务平台基建(⭐⭐⭐⭐⭐):
- 个人生活(⭐⭐⭐⭐⭐没时间了):矫正牙齿,考驾照,锻炼身体
73 2025-01-05(项目例会)
[!NOTE] 周会总结
- 已做内容:
- ETMS
- 部署 kkFileView 实现文件预览。
- 添加直播和线上教研使用情况统计报表。
- BEMS
- 配置 OSS 存储。
- 检查入库数据的完整和对齐。
- 前后端联调学校、学生基本和学习信息,并修复后端问题。
- 编写教师基本与工作的页面(正在收尾,但是还没有调试好)
- SMDB
- 排查解决变更数据同步失败问题。- 下周计划:
- ETMS
- 开发学员、专家、课程、项目和平台各维度统计报表。
- 继续解决反馈的 bug。
- BEMS
- 优化细节部分,完成所有调试发布上线使用。
- 学习感悟:
- 问题记录:
- 指导建议:
- 总体任务:
- 毕业设计(⭐⭐⭐⭐⭐):
- etms(⭐⭐⭐⭐⭐):
- 国重点(⭐⭐⭐):
- 学术汇报(⭐⭐⭐⭐):
- 落地辅助(⭐⭐⭐⭐):
- 司法服务平台基建(⭐⭐⭐⭐⭐):
- 个人生活(⭐⭐⭐⭐⭐没时间了):矫正牙齿,考驾照,锻炼身体
74 2025-01-12(项目例会)
[!NOTE] 周会总结
- 已做内容:
- ETMS
- 添加短信发送接口限制(1min 内只能发送一次)。
- 添加项目名称唯一性校验。
- 封装异步任务工具类(携带登录信息)。
- 添加联合查询自动添加表名注解和 AOP 切面逻辑(联合 MybatisPlus 动态 SQL 和 XML 手工 SQL 的优势)。
- 优化资源管理模块相关表结构和各接口,实现临时文件存储和迁移功能,删除资源检查是否引用,开放资源分类目录。
- BEMS
- 联调优化系统,解决存在的 bug,规范数据库表结构和注释信息。
- 下周计划:
- ETMS
- 开始统计管理开发(包括学员、专家、课程、项目和平台各维度统计报表)
- BEMS
- 维护解决日常出现的问题,排查偶尔出现的 504 错误。
- 学习感悟:
- 问题记录:
- 指导建议:
- 总体任务:
- 毕业设计(⭐⭐⭐⭐⭐):
- etms(⭐⭐⭐⭐⭐):
- 国重点(⭐⭐⭐):
- 学术汇报(⭐⭐⭐⭐):
- 落地辅助(⭐⭐⭐⭐):
- 司法服务平台基建(⭐⭐⭐⭐⭐):
- 个人生活(⭐⭐⭐⭐⭐没时间了):矫正牙齿,考驾照,锻炼身体
75 2025-01-19(项目例会)
[!NOTE] 周会总结
- 已做内容:
- ETMS
- 资源管理完善(重复文件秒传,资源删除校验,列表仅显示普通文件,关联关系完善,视频转码处理)
- 补充人员和项目学员导入入库记录。
- 下周计划:
- ETMS
- 开发个人中心和后台管理的学员档案。
- 开发账号注销功能。
- 开发首页课程列表的免费、付费筛选。
- 尝试部署保利威直播前端自定义播放项目。
- 学习感悟:
- 问题记录:
- 指导建议:
- 总体任务:
- 毕业设计(⭐⭐⭐⭐⭐):
- 学术汇报(⭐⭐⭐⭐):
- 个人生活(⭐⭐⭐⭐⭐):矫正牙齿,锻炼身体
76 2025-02-16 (项目例会)
[!NOTE] 周会总结
- 已做内容:
- ETMS
- 部署完成保利威直播前端项目。
- 添加 SQL 注入过滤,防止 SQL 注入攻击。
- 实现所有列表数据是否为测试数据标识。
- 设计实现通知管理(40%)。
- HSAS
- 修复申报成果文件下载异常问题。
- DbServ
- 添加 nginx 配置及其更新的脚本,纳入到统一备份的 git 仓库进行管理。
- 修复 bems 和 srdb 的 SQL 注入和 XSS 漏洞风险,并完善其它系统存在的漏洞风险。
- 下周计划:
- ETMS
- 部署 RocketMQ 消息队列。
- 继续开发通知管理相关功能。
- DbServ
- 排查完善其他系统存在的漏洞。
- 调研多台 GPU 联合微调或推理的 DeepSeek 模型部署方案,以满足有限资源下能直接使用的性能最优的版本和可以微调的版本。
- 学习感悟:
- 问题记录:
- 指导建议:
- 总体任务:
- 毕业设计(⭐⭐⭐⭐⭐):
- 学术汇报(⭐⭐⭐⭐):
- 个人生活(⭐⭐⭐⭐⭐):矫正牙齿,锻炼身体
77 2025-02-23 (项目例会)
[!NOTE] 周会总结
- 已做内容:
- ETMS
- 部署完成 RocketMQ 消息队列。
- HSAS
- 修复申报成果提交失败,文件预览错乱和附件丢失问题。
- SMDB
- 调整项目成果变更,修复结项数据详情查看异常和结项证书也不能打印问题。
- DbServ
- 排查完善其他系统 XSS 和 SQL 注入过滤逻辑,修复相关系统引起的 bug。
- 升级3台NAS的DSM版本。
- 下周计划:
- ETMS
- 开发通知管理。
- 开发首页课例功能。
- HSAS
- 排查修复成果附件下载异常问题。
- DbServ
- 部署 DeepSeek-R1-Distill-Qwen-14B 推理模型,以及 Qwen-2.5-Instruct 微调模型。
- 制作 50 页左右的“大语言模型的发展与应用”讲座 PPT。
- 学习感悟:
- 问题记录:
- 指导建议:
- 总体任务:
- 毕业设计(⭐⭐⭐⭐⭐):
- 学术汇报(⭐⭐⭐⭐):
- 个人生活(⭐⭐⭐⭐⭐):矫正牙齿,锻炼身体
78 2025-03-02 (项目例会)
[!NOTE] 周会总结
- 已做内容:
- ETMS
- 开发通知管理(60%)。
- 调整线上教研回放为点播回放。
- HSAS
- 排查修复成果附件下载异常问题。
- DbServ
- 制作 “大语言模型的发展与应用”讲座 PPT。
- 本地化部署DeepSeek-R1-Qwen-14B推理模型(ollama成功,vllm失败)。
- 下载DeepSeek-R1-671B和70B模型权重以及华为推理部署环境镜像(下载中)。
- 下周计划:
- ETMS
- 完成通知管理后端开发。
- DbServ
- 在法院提供的华为昇腾GPU上部署私有化DeepSeek大模型,同时记录部署文档,整理形成脚本。
- 学习感悟:
- 问题记录:
- 指导建议:
- 总体任务:
- 毕业设计(⭐⭐⭐⭐⭐):
- 学术汇报(⭐⭐⭐⭐):
- 个人生活(⭐⭐⭐⭐⭐):矫正牙齿,锻炼身体
79 2025-03-09 (项目例会)
[!NOTE] 周会总结
- 已做内容:
- ETMS
- 后端基本完成通知管理开发。
- 排查修复线上服务整体瘫痪问题。
- 修复资源上传异常bug和人员删除异常bug。
- 慢SQL查询结构优化。
- DB&SERV
- 恢复nginx误删除的配置文件并完善备份文件,备份shadowsocks。
- 优化ETMS测试库和正式库备份脚本。
- 修复smas生产环境服务无法启动问题。
- 完成DeepSeek-R1-Qwen-Distill-32B和DeepSeek-R1-Qwen-Distill-70B模型权重以及华为昇腾推理环境镜像下载。
- 下周计划:
- ETMS
- 启动统计管理开发。
- 全局模糊搜索与记录功能。
- DB&SERV
- 在法院提供的华为昇腾GPU上部署私有化DeepSeek-R1-Qwen-Distill-32B模型,同时记录部署文档,整理形成脚本。
学习感悟:
问题记录:
指导建议:
- 总体任务:
- 毕业设计(⭐⭐⭐⭐⭐):
- 学术汇报(⭐⭐⭐⭐):
- 个人生活(⭐⭐⭐⭐⭐):矫正牙齿,锻炼身体
80 2025-03-16 12:27:52(项目例会)
[!NOTE] 周会总结
- 已做内容:
- ETMS
- 通知管理联调60%。
- 调整学员导入以手机号为唯一标识进行覆盖更新。
- 修复伪直播无法正常播放问题,并修正相关回放数据。
- 优化直播观看最短路径相关接口。
- 调整学员单位为非必填,以满足C端用户学习。
- 确认数据统计相关字段需求,初步启动统计管理开发。
- DB&SERV
- 所有系统发送邮件时的邮件服务器、邮箱地址后缀csdc.info统一调整为csdcinfo.cn。
- 与阿里云沟通确认满足3w,5w,10w用户在线学习的各资源配置方案。
- 下周计划:
- ETMS
- 联调完成通知管理。
- 继续开发统计管理。
- DB&SERV
- 按照阿里云给出的方案调整资源配置。
- 对接中国电信马总推进基础环境和DeepSeek-Qwen-Distill-32B模型部署。
学习感悟:
问题记录:
指导建议:
- 总体任务:
- 毕业设计(⭐⭐⭐⭐⭐):
- 学术汇报(⭐⭐⭐⭐):
- 个人生活(⭐⭐⭐⭐⭐):矫正牙齿,锻炼身体
81 2025-03-23 14:04:01(项目例会)
[!NOTE] 周会总结
- 已做内容:
- ETMS
- 修复专家课程数据权限问题。
- 部署测试库RocketMQ消息队列。
- 修复课程附件上传保利威失败问题。
- 添加日志链路追踪功能。
- 修复存在多个通行证时无法登录问题。
- DB&SERV
- 完成所有系统SSL证书更换为csdcinfo.cn的新证书。
- 调整ETMS流水线域名配置,恢复流水线正常运转。
- 对测试库节点的存储进行扩容,提高测试集群稳定性。
- 下周计划:
- ETMS
- 清理多余的异常通行证。
- 继续开发统计管理。
- DB&SERV
- 修改其他应用流水线域名配置为新域名,恢复流水线正常运转。
学习感悟:
问题记录:
指导建议:
- 总体任务:
- 毕业设计(⭐⭐⭐⭐⭐):
- 学术汇报(⭐⭐⭐⭐):
- 个人生活(⭐⭐⭐⭐⭐):矫正牙齿,锻炼身体
82 2025-04-13 16:18:11(项目例会)
[!NOTE] 周会总结