本文最后更新于:2 个月前
[!WARNING] TipsspringBoot2.x 版本的项目了,最低要求 java17+spring3.x 版本,因此要想继续使用 springboot2.x 版本可以更换 SpringInitializer 服务器 url 为阿里云 的: Cloud Native App Initializer
SpringBoot 基础速成 Bean 配置 Bean 扫描 实现 Bean 扫描的注解有以下方式:
@ComponentScan:basePackages/value 接收一个包名字符串,表示扫描该包及其子包下的所有 bean 对象,将其自动注册到 IOC 容器中。@ComponentScans:value 接收多个@ComponentScan,扩展了@ComponentScan,相当于批量注册 bean 对象到 IOC 容器中。
Bean 注册 实现 Bean 注册的方式分为:本地自定义的类注册和导入的第三方包中的类的注册。
自定义类的注册
@Component:bean 基础注册注解,添加该注解的类会在 Springboot 程序启动时自动注册为 IOC 容器的 bean。@Service:业务类 bean 注册注解,一般用于业务处理的相关类,对应于包名为 service 下的 java 类。@Controller:控制器 bean 注册注解,一般用于控制层返回数据的相关类,对应于 controller 下的相关 java 类。@Repository:数据交互 bean 注册注解,一般在 mybatis 等数据库中间件较多,自己用该注解较少。···:还有如 RestController 等进一步的封装注解,也可以实现不同意义的 bean 注册。
注解
说明
位置
@Component声明 bean 的基础注解
不属于以下三类时,用此注解
@Controller@Component 的衍生注解
标注在控制器类上
@Service@Component 的衍生注解
标注在业务类上
@Repository@Component 的衍生注解
标注在数据访问类上(由于与 mybatis 整合,用的少)
第三方类的注册 如果要注册的 bean 对象来自于第三方(不是自定义的) ,是无法用@Component 及衍生注解声明 bean 的.
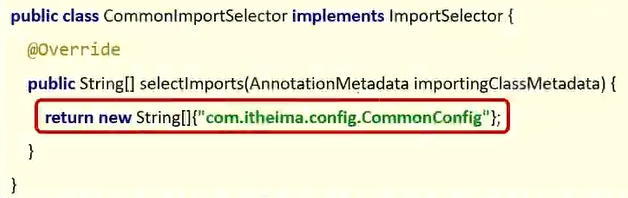
[!NOTE] @Import
导入配置类 :@Import(Xxx.class)
导入 ImportSelector 接口实现类
一般静态数据都会存储在配置文件中,要么从 application.yml 使用 spel 表达式获取,要么放在 resources 目录下其他文件里通过 io 读取资源文件中的配置进行注入。
注册条件 常用的几个注册条件如下表所示:
注解
说明
@ConditionalOnProperty配置文件中存在对应的属性,才声明该 bean
@ConditionalOnMissingBean当不存在当前类型的 bean 时,才声明该 bean
@ConditionalOnclass当前环境存在指定的这个类时,才声明该 bean
自动配置原理 遵循约定大约配置的原测,在 boot 程序启动后,起步依赖中的一些 bean 对象会自动注入到 ioc 容器。
自定义 Starter 在实际开发中,经常会定义一些公共组件,提供给各个项目团队使用。而在 Spring Boot 的项目中,一般会将这些公共组件封装为 SprinaBoot 的 starter。
Maven:org.mybatis.spring.boot:mybatis-spring-boot-autoconfigure:3.0.0 —>自动配置功能Maven:org.mybatis.spring.boot:mybatis-spring-boot-starter:3.0.0 —>依赖管理功能
需求:自定义 mybatis 的 starter
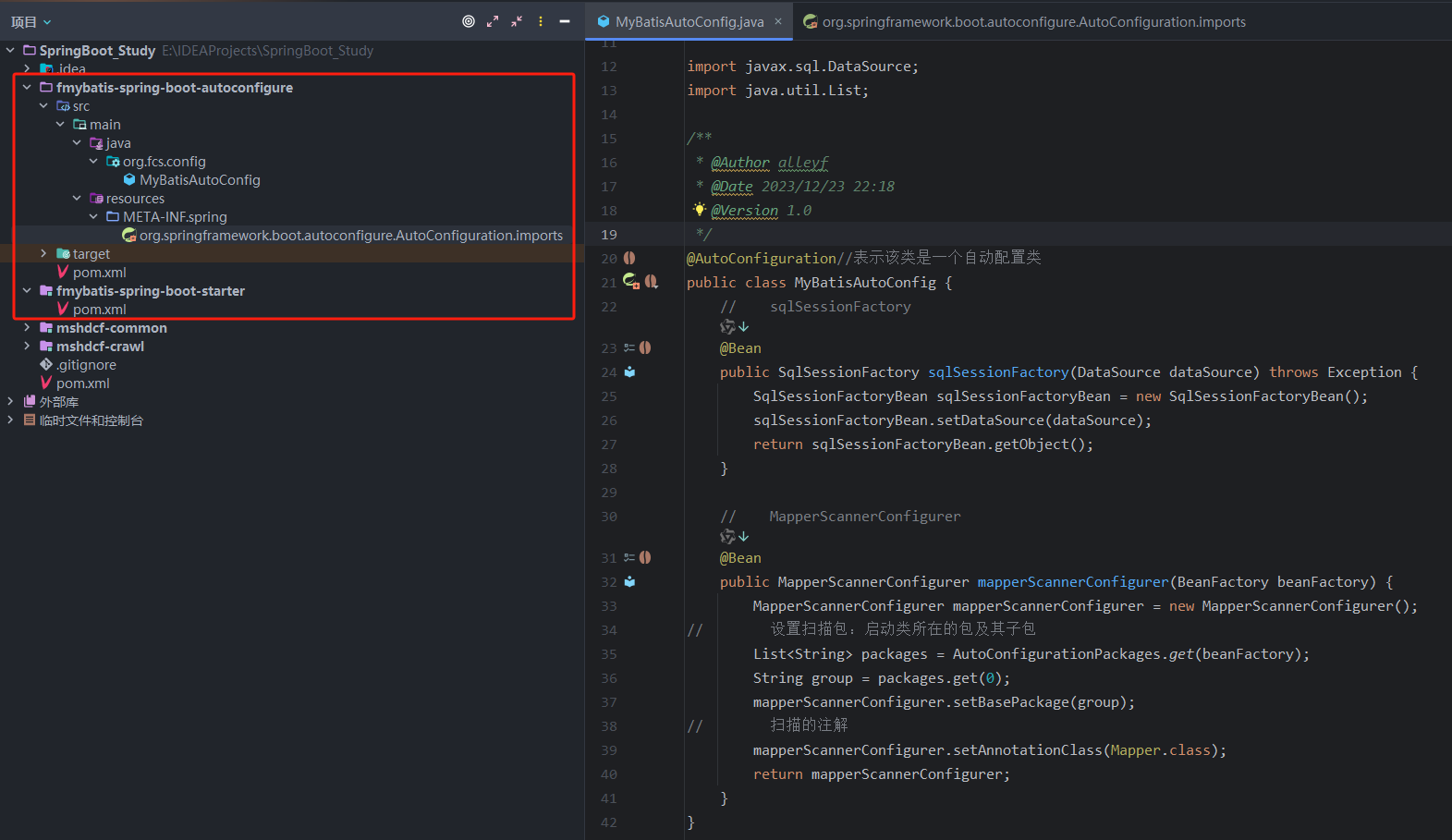
创建 fmybatis-spring-boot-autoconfigure 模块,提供自动配置功能,并自定义配置文件 META-lNF/spring/org.springframework.boot.autoconfigure.AutoConfiguration.imports
创建 fmybatis-spring-boot-starter模 块,在 starter 中引入自动配置模块
核心自动装配类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 @AutoConfiguration public class MyBatisAutoConfig {@Bean public SqlSessionFactory sqlSessionFactory (DataSource dataSource) throws Exception {SqlSessionFactoryBean sqlSessionFactoryBean = new SqlSessionFactoryBean ();return sqlSessionFactoryBean.getObject();@Bean public MapperScannerConfigurer mapperScannerConfigurer (BeanFactory beanFactory) {MapperScannerConfigurer mapperScannerConfigurer = new MapperScannerConfigurer ();String group = packages.get(0 );return mapperScannerConfigurer;
完成后的目录结构如下图所示:
走进 SpringBoot 一站式开发 前置课程: 《Spring6 核心内容》《SpringMvc6》《SpringSecurity6》《Java-9-17 新特性篇》
**提醒:好奇能不能不学 SSM 直接 SpringBoot,这里声明一下,SpringBoot 只是用于快速创建 SSM 项目的脚手架,就像是个外壳一样,离开了 SSM 核心内容就是个空壳,不要本末倒置了。
Spring Boot 让您可以轻松地创建独立的、生产级别的 Spring 应用程序,并“直接运行”这些应用程序。SpringBoot 为大量的第三方库添加了支持,能够做到开箱即用,简化大量繁琐配置,用最少的配置快速构建你想要的项目。在 2023 年,SpringBoot 迎来了它的第三个大版本,随着 SpringBoot 3 的正式发布,整个生态也迎来了一次重大革新。
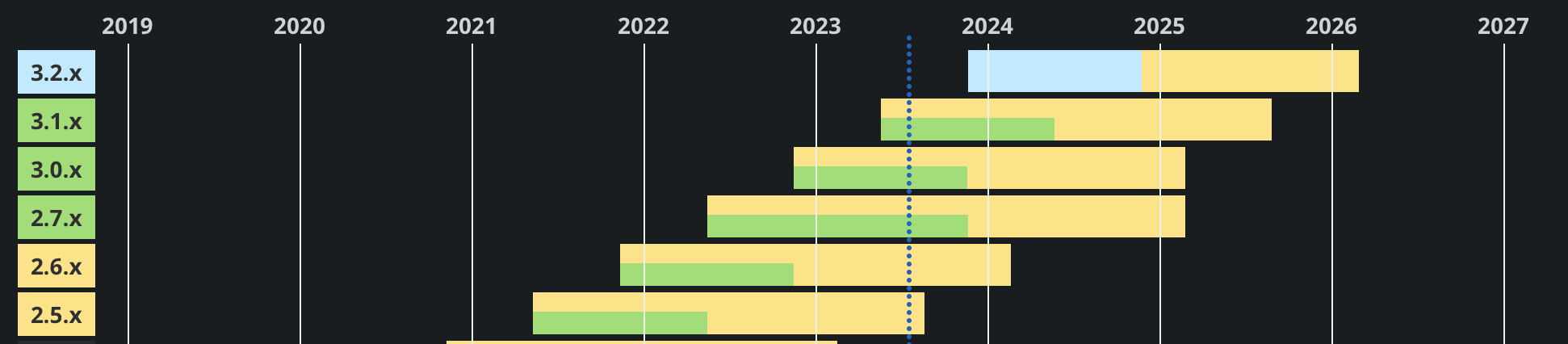
目前的最新版本以及对应的维护情况:
可以看到,曾经的 SpringBoot 2.5 版本将会在 2023 年 8 月底终止商业支持,届时将不会再对这类旧版本进行任何维护,因此,将我们的老版本 SpringBoot 项目进行升级已经迫在眉睫,目前最强的 3.1 正式版会维护到 2025 年中旬。
在3.X 之后的变化相比2.X 可以说是相当大,尤其是其生态下的 SpringSecurity 框架,旧版本项目在升级之后 API 已经完全发生改变;以及内置 Tomcat 服务器的升级,Servlet 也升级到5以上,从 javax 全新升级到 jakarta 新包名;包括在 3.X 得到的大量新特性,如支持 GraalVM 打包本地镜像运行等;并且 Java 版本也强制要求为 17 版本。迁移到新版本不仅可以享受到免费维护支持,也可以感受 Java17 带来的全新体验。
介绍了这么多,我们首先还是来看看 SpringBoot 功能有哪些:
能够创建独立的 Spring 应用程序
内嵌 Tomcat、Jetty 或 Undertow 服务器(无需单独部署 WAR 包,打包成 Jar 本身就是一个可以运行的应用程序)
提供一站式的“starter”依赖项,以简化 Maven 配置(需要整合什么框架,直接导对应框架的 starter 依赖)
尽可能自动配置 Spring 和第三方库(除非特殊情况,否则几乎不需要进行任何配置)
提供生产环境下相关功能,如指标、运行状况检查和外部化配置
没有任何代码生成,也不需要任何 XML 配置(XML 是什么,好吃吗)
SpringBoot 是现在最主流的开发框架,国内的公司基本都在使用,也是我们出去找工作一定要会的框架,它提供了一站式的开发体验,能够大幅度提高我们的开发效率。
在 SSM 阶段,当我们需要搭建一个基于 Spring 全家桶的 Web 应用程序时,我们不得不做大量的依赖导入和框架整合相关的 Bean 定义,光是整合框架就花费了我们大量的时间,但是实际上我们发现,整合框架其实基本都是一些固定流程,我们每创建一个新的 Web 应用程序,基本都会使用同样的方式去整合框架,我们完全可以将一些重复的配置作为约定,只要框架遵守这个约定,为我们提供默认的配置就好,这样就不用我们再去配置了,约定优于配置!
而 SpringBoot 正是将这些过程大幅度进行了简化,它可以自动进行配置,我们只需要导入对应的启动器(starter)依赖即可。
完成本阶段的学习,基本能够胜任部分网站系统的后端开发工作,也建议同学们学习完 SpringBoot 之后寻找合适的队友去参加计算机相关的高校竞赛,这里有一些推荐:
项目类:
建议:按照目前国内的环境,项目类竞赛并不会注重你编码水平有多牛,也不会注重你的项目用到了多牛的技术,这些评委老师技术怎么样我不多说,他们只会在乎你项目制作的功能怎么样,展示效果怎么样,有没有什么创新点,至于其他的,哪怕代码写成一坨屎都不会管你。并且项目最好是有专利证书或者软著,尤其是企业合作项目,已经投入生产的,特别吃香。如果你是白手起家的项目,即使你再努力地去做,也不可能打得过人家强大的项目背景。
比赛名称
难度
含金量
备注
创新创业大赛
⭐️⭐️⭐️⭐️⭐️
⭐️⭐️⭐️⭐️
这比赛没点背景很难,最好是专利项目或是企业合作项目
挑战杯
⭐️⭐️⭐️⭐️⭐️
⭐️⭐️⭐️⭐️
网传这是 PPT 大赛,不知真实性如何
中国大学生计算机设计大赛
⭐️⭐️⭐️
⭐️⭐️⭐️
这个比赛相对来说比较好拿奖,项目一定要有亮点
算法类:
建议:这种竞赛越早开始培养越好,因为要背很多的题板和算法,很多人都是初中或者高中就开始打竞赛了,像团队类型的竞赛,如果自己比较菜,就去找大佬抱大腿吧,十个臭皮匠都顶不了诸葛亮;个人类型的竞赛也要多刷力扣,多背算法题,临时抱佛脚也是没有用的。
比赛名称
难度
含金量
备注
蓝桥杯
⭐️⭐️⭐️
⭐️⭐️⭐️
蓝桥杯建议参加前端/Java 组,稍微简单一点,去 C++就是找死
CCPC 天梯赛
⭐️⭐️⭐️⭐️
⭐️⭐️⭐️⭐️
不多说
ICPC ACM 大学生程序设计竞赛
⭐️⭐️⭐️⭐️⭐️
⭐️⭐️⭐️⭐️⭐️
这个难度非常大,最好是有大佬带,靠自己慢慢去学很难
打竞赛的过程是很辛苦的,付出很有可能没有回报,很多竞赛没有绝对的公平,多多少少有一些利益关系在里面,但是多参加一些竞赛哪怕没有得奖,还是可以收获到很多的,如果你通过这些比赛学到了很多,实际上得不得奖已经不重要了,自己内心的强大的才是真正的强大。
快速上手
springboot 版本和 maven 版本和 jdk 版本有一定的依赖关系 ,否则会导致扫描不到 bean,springboot 版本越高要求 maven 版本也要越高,谨记这个小 bug。maven 和 jdk 依赖关系如下:
1 2 3 url: https://maven.apache.org/docs/history.html
要感受 SpringBoot 带来的快速开发体验,我们就从创建一个项目开始。
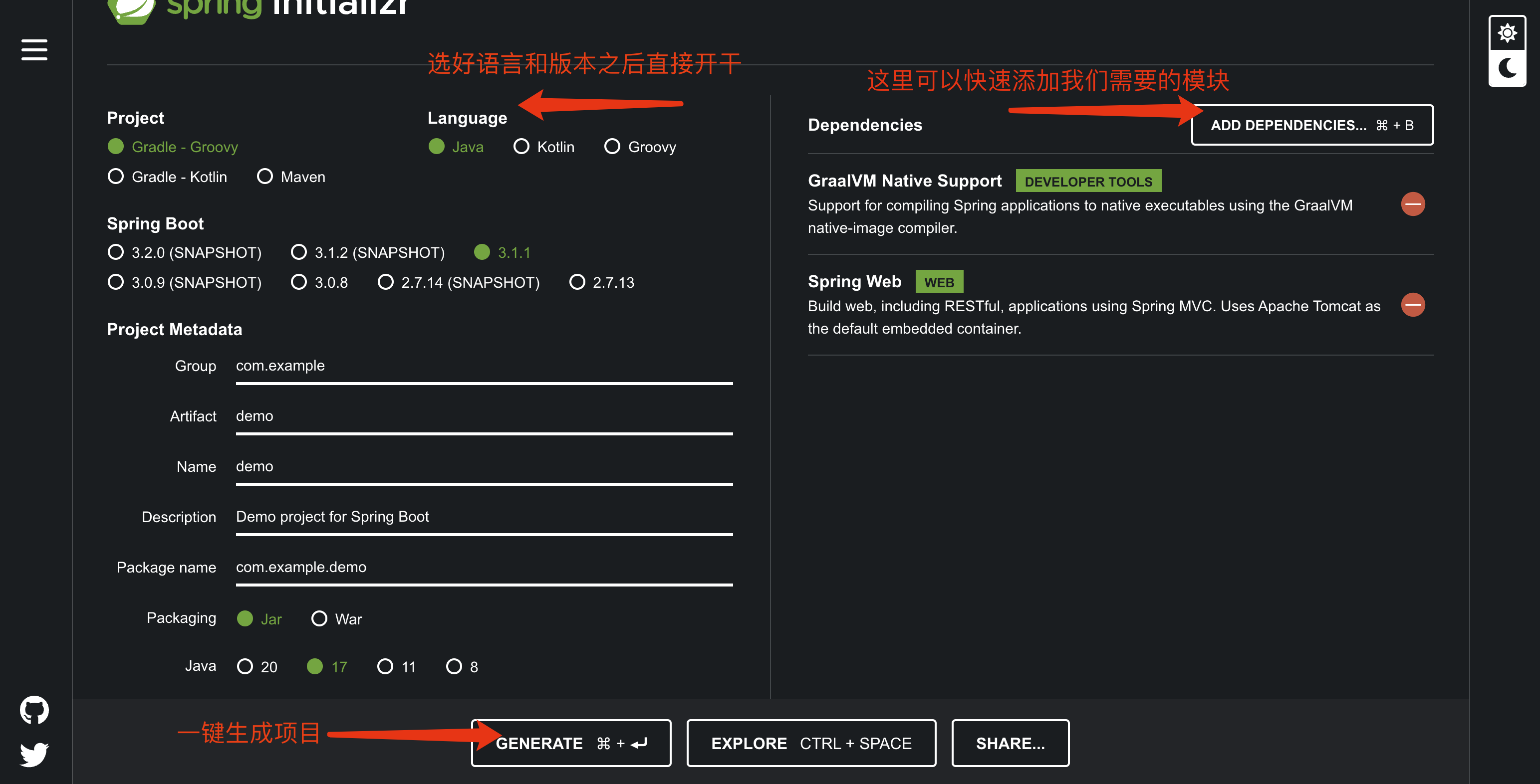
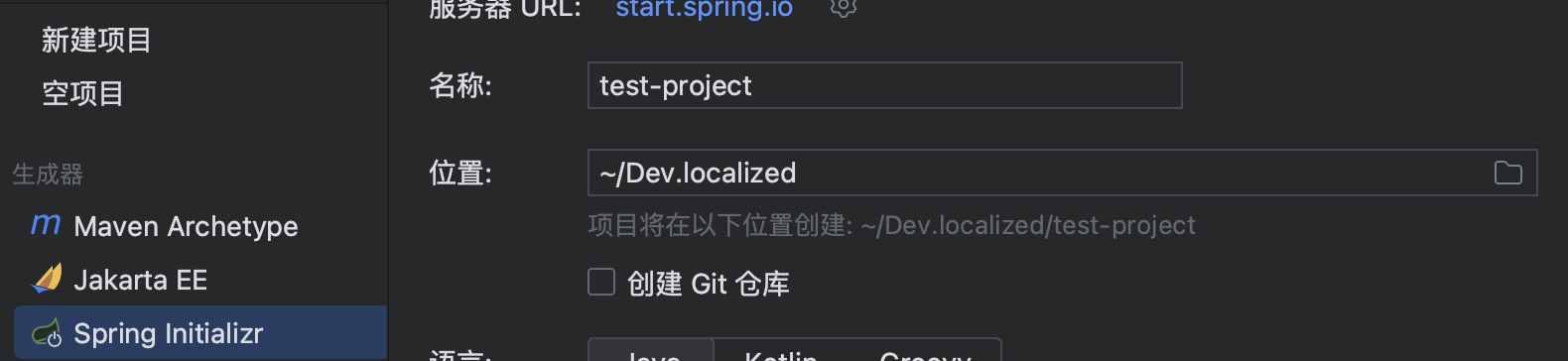
极速创建项目 在过去,我们创建一个 SSM 项目,需要先导入各种依赖,进行大量的配置,而现在,有了 SpringBoot,我们可以享受超快的项目创建体验,只需要前往官网进行少量配置就能快速为你生成一个 SpringBoot 项目模版: https://start.spring.io/
不过,为了方便,IDEA 已经将这个工具集成到内部了,我们可以直接在 IDEA 中进行创建,效果是一样的,首先在新建项目阶段,选择 Spring Initializr 类型:
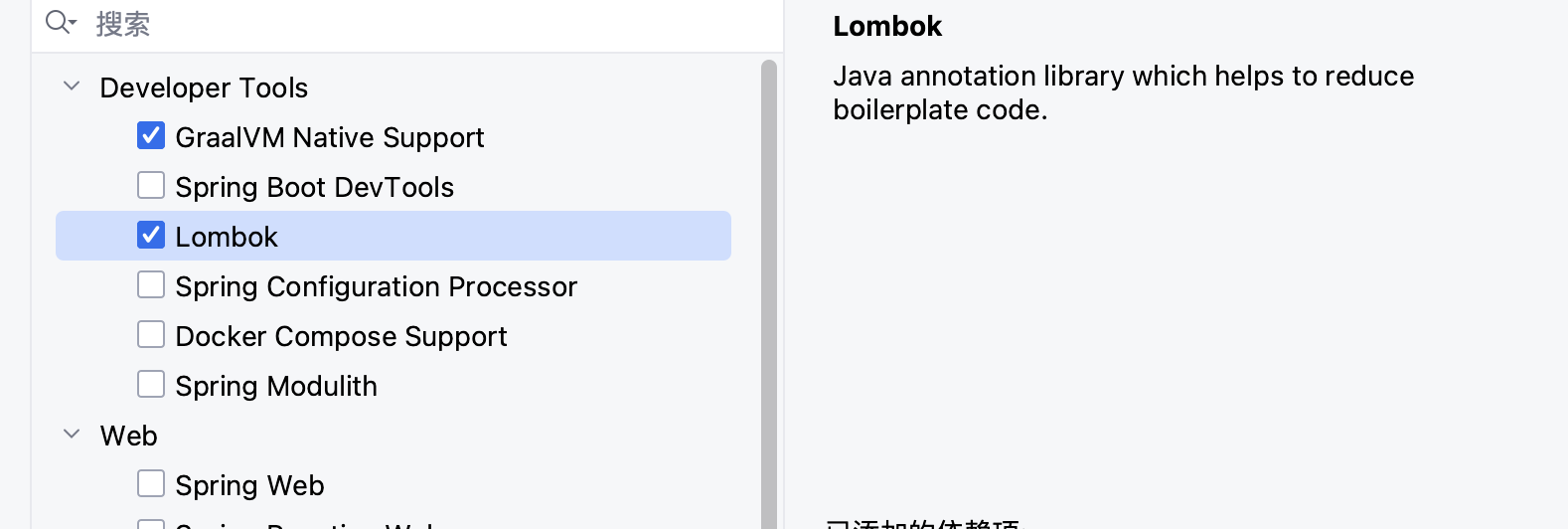
接着我们就可以配置项目的语言,并且选择项目需要使用的模块,这里我们简单选择两个依赖:
如果一开始不清楚自己需要哪些模块,我们也可以后续自己手动添加对应模块的 starter 依赖,使用非常简单。
项目自动生成之后,可以看到 Spring 相关的依赖已经全部自动导入:
并且也自动为我们创建了一个主类用于运行我们的 SpringBoot 项目:
我们可以一键启动我们的 SpringBoot 项目:
只不过由于我们没有添加任何有用的模块,也没有编写什么操作,因此启动之后项目就直接停止了。
常用模块快速整合 前面我们说了,SpringBoot 的核心思想就是约定大于配置,能在一开始默认的就直接默认,不用我们自己来进行配置,我们只需要配置某些特殊的部分即可,这一部分我们就来详细体验一下。
我们来尝试将我们之前使用过的模块进行一下快速整合,可以看到在一开始的时候,我们没有勾选其他的依赖,因此这里只导入了最基本的 spring-boot-starter 依赖:
1 2 3 4 <dependency > <groupId > org.springframework.boot</groupId > <artifactId > spring-boot-starter</artifactId > </dependency >
所有的 SpringBoot 依赖都是以 starter 的形式命名的,之后我们需要导入其他模块也是导入 spring-boot-starter-xxxx 这种名称格式的依赖。
首先我们还是从 SpringMvc 相关依赖开始。SpringBoot 为我们提供了包含内置 Tomcat 服务器的 Web 模块,我们只需要导入依赖就能直接运行服务器:
1 2 3 4 <dependency > <groupId > org.springframework.boot</groupId > <artifactId > spring-boot-starter-web</artifactId > </dependency >
我们不需要进行任何配置,直接点击启动:
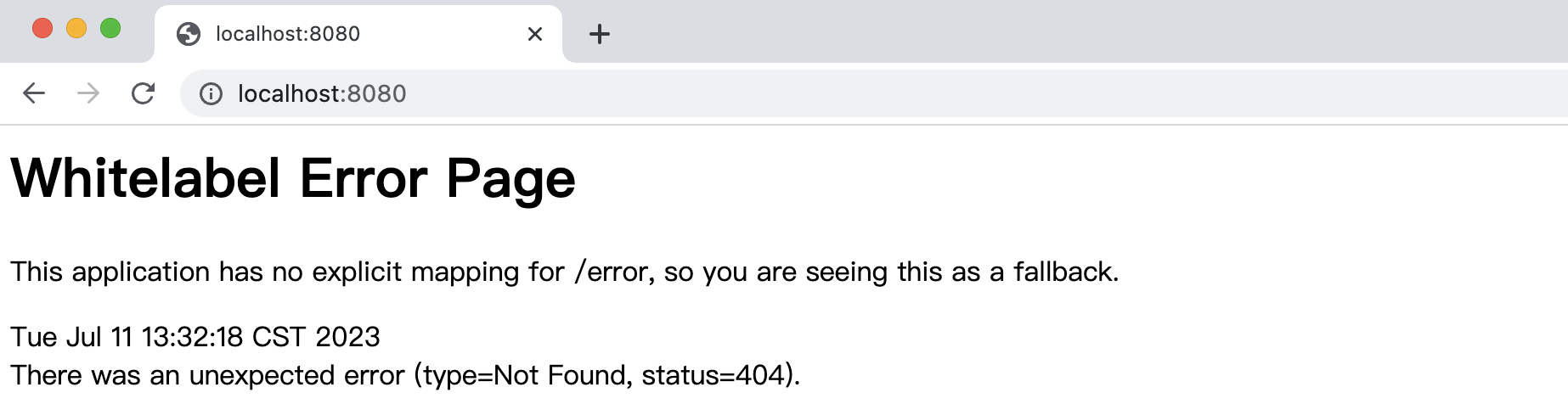
它真的做到了开箱即用,我们现在可以直接访问这个网站:
可以看到成功响应了 404 页面,相比之前的大量配置,可以说方便了很多,我们到目前为止仅仅是导入了一个依赖,就可以做到直接启动我们的 Web 服务器并正常访问。
SpringBoot 支持自动包扫描,我们不需要编写任何配置,直接在任意路径(但是不能跑到主类所在包外面去了)下创建的组件(如 Controller、Service、Component、Configuration 等)都可以生效,比如我们这里创建一个测试的 Controller 试试看:
1 2 3 4 5 6 7 8 9 @Controller public class TestController {@ResponseBody @GetMapping("/") public String index () {return "Hello World" ;
重启之后,可以看到直接就能访问到,而这期间我们只是创建了对应的 Controller 却没有进行任何配置,这真的太方便了:
包括一个对象现在也可以直接以 JSON 形式返回给客户端,无需任何配置:
1 2 3 4 5 6 @Data public class Student {int sid;
1 2 3 4 5 6 7 8 9 @ResponseBody @GetMapping("/") public Student index () {Student student = new Student ();"小明" );"男" );10 );return student;

最后浏览器能够直接得到 application/json 的响应数据,就是这么方便,这都得归功于 SpringBoot 对应的 start 帮助我们自动将处理 JSON 数据的 Converter 进行了配置,我们不需要再单独去配置 Converter 了。不过 SpringBoot 官方默认使用的是 Jackson 和 Gson 的 HttpMessageConverter 来进行配置,不是我们之前教程中使用的 FastJSON 框架。
我们最后来看看这个 Start 包含了哪些依赖:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 <dependencies > <dependency > <groupId > org.springframework.boot</groupId > <artifactId > spring-boot-starter</artifactId > <version > 3.1.1</version > <scope > compile</scope > </dependency > <dependency > <groupId > org.springframework.boot</groupId > <artifactId > spring-boot-starter-json</artifactId > <version > 3.1.1</version > <scope > compile</scope > </dependency > <dependency > <groupId > org.springframework.boot</groupId > <artifactId > spring-boot-starter-tomcat</artifactId > <version > 3.1.1</version > <scope > compile</scope > </dependency > <dependency > <groupId > org.springframework</groupId > <artifactId > spring-web</artifactId > <version > 6.0.10</version > <scope > compile</scope > </dependency > <dependency > <groupId > org.springframework</groupId > <artifactId > spring-webmvc</artifactId > <version > 6.0.10</version > <scope > compile</scope > </dependency > </dependencies >
里面包含了以下内容:
spring-boot-starter 基础依赖 starter
spring-boot-starter-json 配置 JSON 转换的 starter
spring-boot-starter-tomcat 内置 Tomcat 服务器
spring-web、spring-webmvc 不用多说了吧,之前已经讲过了
如果需要像之前一样添加 WebMvc 的配置类,方法是一样的,直接创建即可:
1 2 3 4 5 6 7 8 9 10 11 12 13 @Configuration public class WebConfiguration implements WebMvcConfigurer {@Override public void addInterceptors (InterceptorRegistry registry) {new HandlerInterceptor () {@Override public boolean preHandle (HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {return HandlerInterceptor.super .preHandle(request, response, handler);
我们在 SSM 阶段编写的大量配置,到现在已经彻底不需要了。
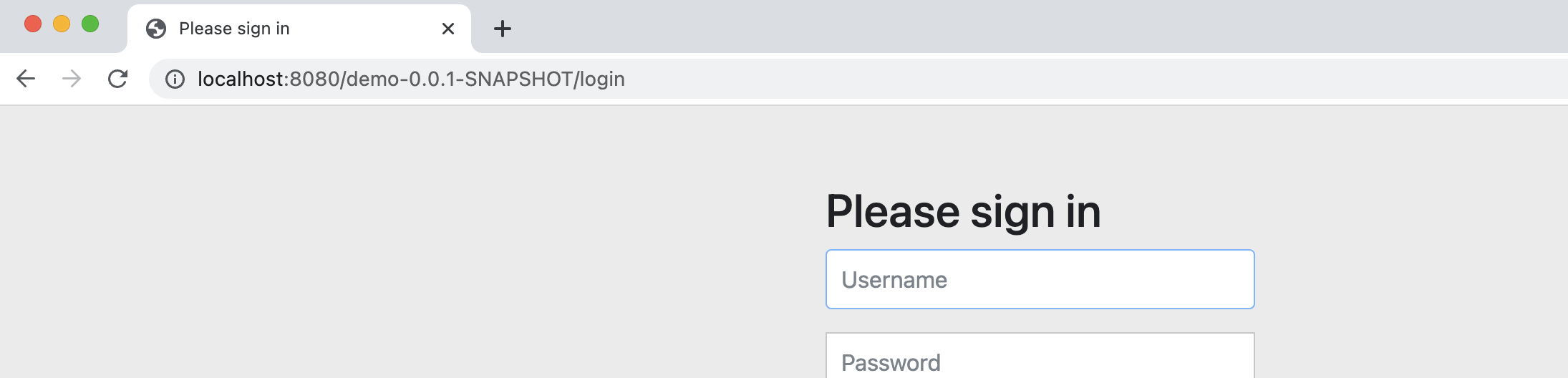
同样的,我们来看看 SpringSecurity 框架如何进行整合,也是非常简单,我们只需要直接导入即可:
1 2 3 4 <dependency > <groupId > org.springframework.boot</groupId > <artifactId > spring-boot-starter-security</artifactId > </dependency >
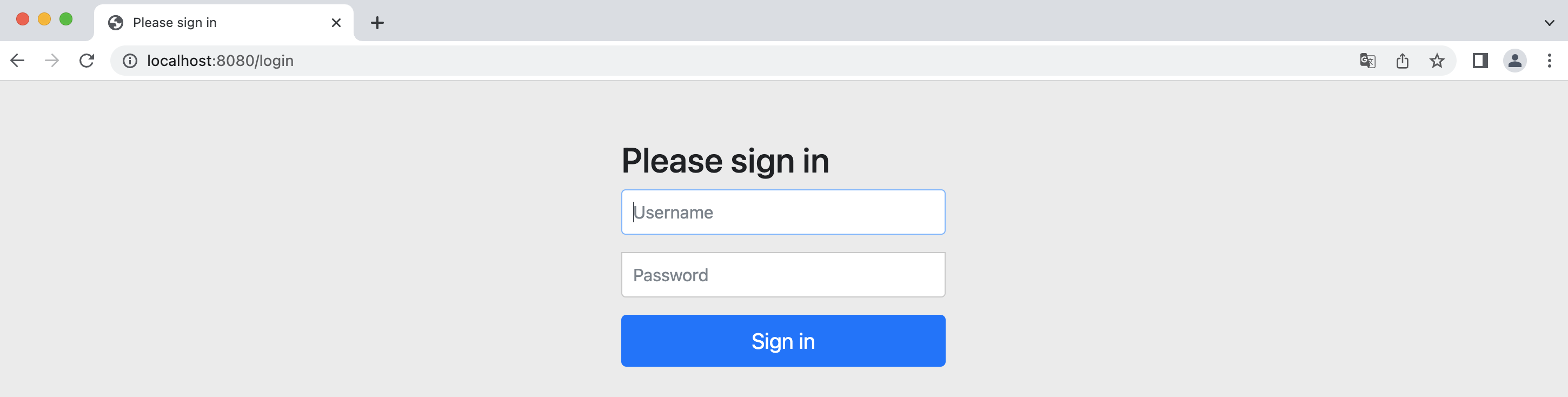
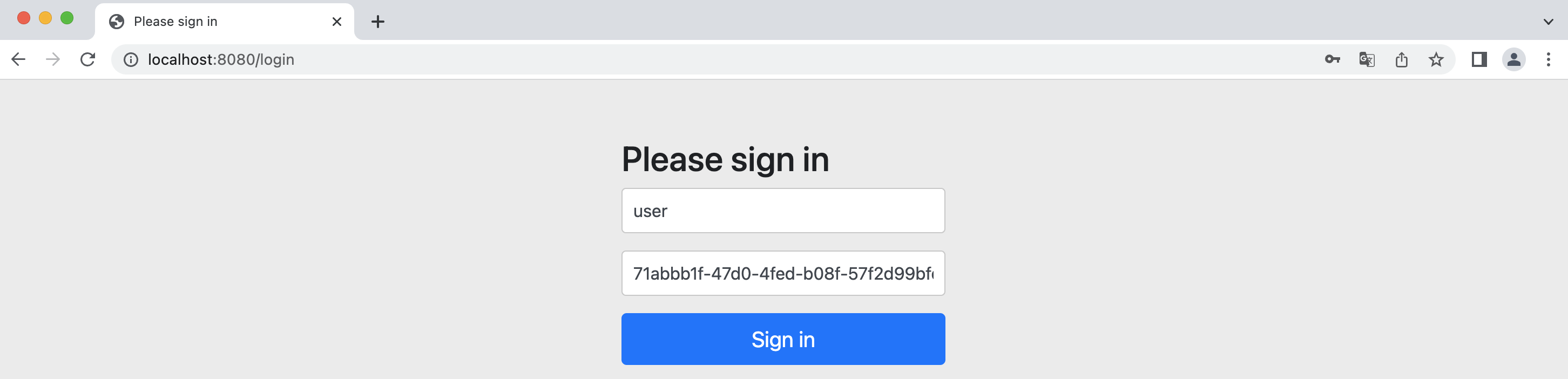
导入完成后,再次访问网站,就可以看到熟悉的登录界面了:
我们没有进行任何配置,而是对应的 Starter 帮助我们完成了默认的配置,并且在启动时,就已经帮助我们配置了一个随机密码的用户可以直接登录使用:
密码直接展示在启动日志中,而默认用户名称为 user 我们可以直接登录:
同样没有进行任何配置,我们只需要添加对应的 starter 就能做到开箱即用,并且内置一套默认配置,自动帮助我们创建一个测试用户,方便我们快速搭建项目,同样的,如果要进行额外配置,我们只需要直接添加配置类即可:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 @Configuration public class SecurityConfiguration {@Bean public SecurityFilterChain filterChain (HttpSecurity http) throws Exception {return http"/login" );"/doLogin" );"/" );
同样的,我们也可以快速整合之前使用的模版引擎,比如 Thymeleaf 框架,直接上对应的 Starter 即可:
1 2 3 4 <dependency > <groupId > org.springframework.boot</groupId > <artifactId > spring-boot-starter-thymeleaf</artifactId > </dependency >
在默认情况下,我们需要在 resources 目录下创建两个目录:
这两个目录是默认配置下需要的,名字必须是这个:
templates - 所有模版文件都存放在这里static - 所有静态资源都存放在这里
我们只需要按照上面的样子放入我们之前的前端模版,就可以正常使用模版引擎了,同样不需要进入任何的配置,当然,如果各位小伙伴觉得不方便,我们后续也可以进行修改。
我们不需要在 controller 中写任何内容,它默认会将 index.html 作为首页文件,我们直接访问服务器地址就能展示首页了:
1 2 3 4 @Controller public class TestController {
这都是得益于约定大于配置的思想,开箱即用的感觉就是这么舒服,不过肯定有小伙伴好奇那现在要怎么才能像之前一样自己写呢,这个肯定还是跟之前一样的呗,该怎么写就怎么写。
我们最后再来看看 Mybatis 如何进行整合,同样只需要一个 starter 即可,这里顺便把 MySQL 的驱动加上:
1 2 3 4 5 6 7 8 9 10 <dependency > <groupId > org.mybatis.spring.boot</groupId > <artifactId > mybatis-spring-boot-starter</artifactId > <version > 3.0.2</version > </dependency > <dependency > <groupId > com.mysql</groupId > <artifactId > mysql-connector-j</artifactId > <scope > runtime</scope > </dependency >
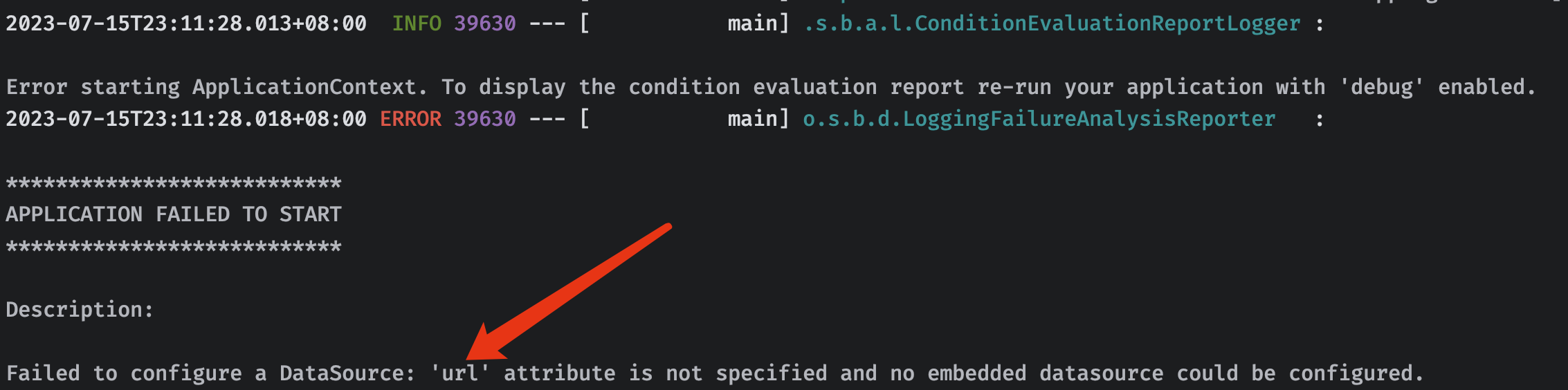
注意这里的 mybatis-spring-boot-starter 版本需要我们自己指定,因为它没有被父工程默认管理。
启动服务器时,我们发现这里出现了问题,导致无法启动。这是因为我们没有配置数据源导致的,虽然 SpringBoot 采用约定大于配置的思想,但是数据库信息只有我们自己清楚,而且变化多样,根本没有办法提前完成约定,所以说这里我们还是需要再配置文件中编写,至于如何编写配置文件我们会在下一节中进行讲解。
自定义运行器 在项目中,可能会遇到这样一个问题:我们需要在项目启动完成之后,紧接着执行一段代码。
我们可以编写自定义的 ApplicationRunner 来解决,它会在项目启动完成后执行:
1 2 3 4 5 6 7 @Component public class TestRunner implements ApplicationRunner {@Override public void run (ApplicationArguments args) throws Exception {"我是自定义执行!" );
当然也可以使用 CommandLineRunner,它也支持使用@Order 或是实现 Ordered 接口来支持优先级执行。
这个功能比较简单,不多做介绍了。
配置文件介绍 前面我们已经体验了 SpringBoot 带来的快捷开发体验,不过我们发现有些东西还是需要我们自己来编写配置才可以,不然 SpringBoot 项目无法正常启动,我们来看看如何编写配置。我们可以直接在 application.properties 中进行配置编写,它是整个 SpringBoot 的配置文件,比如要修改服务器的默认端口:
这些配置其实都是各种 Starter 提供的,部分配置在 Starter 中具有默认值,我们即使不配置也会使用默认值,比如这里的 8080 就是我们服务器的默认端口,我们也可以手动修改它,来变成我们需要的。
除了配置已经存在的选项,我们也可以添加自定义的配置,来方便我们程序中使用,比如我们这里创建一个测试数据:
我们可以直接在程序中通过 @Value 来访问到(跟我们之前 Spring 基础篇讲的是一样的)
1 2 3 4 5 @Controller public class TestController {@Value("${test.data}") int data;
配置文件除了使用 properties 格式以外,还有一种叫做 yaml 格式,它的语法如下:
1 2 3 4 5 6 7 8 一级目录: 二级目录: 三级目录 1: 值 三级目录 2: 值 三级目录 List: - 元素 1 - 元素 2 - 元素 3
我们可以看到,每一级目录都是通过缩进(不能使用 Tab,只能使用空格)区分,并且键和值之间需要添加冒号+空格来表示。
SpringBoot 也支持这种格式的配置文件,我们可以将 application.properties 修改为 application.yml 或是 application.yaml 来使用 YAML 语法编写配置:
现在我们来尝试为之前的数据源进行一下配置,这样才能正常启动我们的服务器:
1 2 3 4 5 6 spring:123456
配置完成后,我们就可以正常启动服务器了。
这里我们接续来测试一下 MyBatis 的配置,想要在 SpringBoot 中使用 Mybatis 也很简单,不需要进行任何配置,我们直接编写 Mapper 即可,这里我们随便创建一个表试试看:
1 2 3 4 5 6 7 @Data public class User {int id;
注意,在 SpringBoot 整合之后,我们只需要直接在配置类上添加 @MapperScan 注解即可,跟我们之前的使用方法是一样的:
1 2 3 4 @Configuration @MapperScan("com.example.mapper") public class WebConfiguration implements WebMvcConfigurer {
不过,为了方便,我们也可以直接为需要注册为 Mapper 的接口添加 @Mapper 注解,来表示这个接口作为 Mapper 使用:
这样,即使不配置 MapperScan 也能直接注册为 Mapper 正常使用,是不是感觉特别方便?
1 2 3 4 5 @Mapper public interface UserMapper {@Select("select * from user where id = #{id}") findUserById (int id) ;
1 2 3 4 5 @ResponseBody @GetMapping("/test") public User test () {return mapper.findUserById(1 );
访问接口测试一下:
最后,我们再来介绍一下常见的配置项,比如 SpringSecurity 和 SpringBootMvc 配置:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 spring: mvc: static-path-pattern: /static/** security: filter: order: -100 user: name: 'admin' password: '123456' roles: - admin - user
更多的配置我们可以在后续的学习中继续认识,这些配置其实都是由 Starter 提供的,确实极大程度简化了我们对于框架的使用。
轻松打包运行 前面我们介绍了一个 SpringBoot 如何快捷整合其他框架以及进行配置编写,我们接着来看如何打包我们的 SpringBoot 项目使其可以正常运行,SpringBoot 提供了一个非常便捷的打包插件,能够直接将我们的项目打包成一个 jar 包,然后使用 java 命令直接运行,我们直接点击 Maven 中的:
点击之后项目会自动打包构建:
打包完成之后,会在 target 目录下出现一个打包好的 jar 文件:
我们可以直接在命令行中运行这个程序,在 CMD 中进入到 target 目录,然后输入:
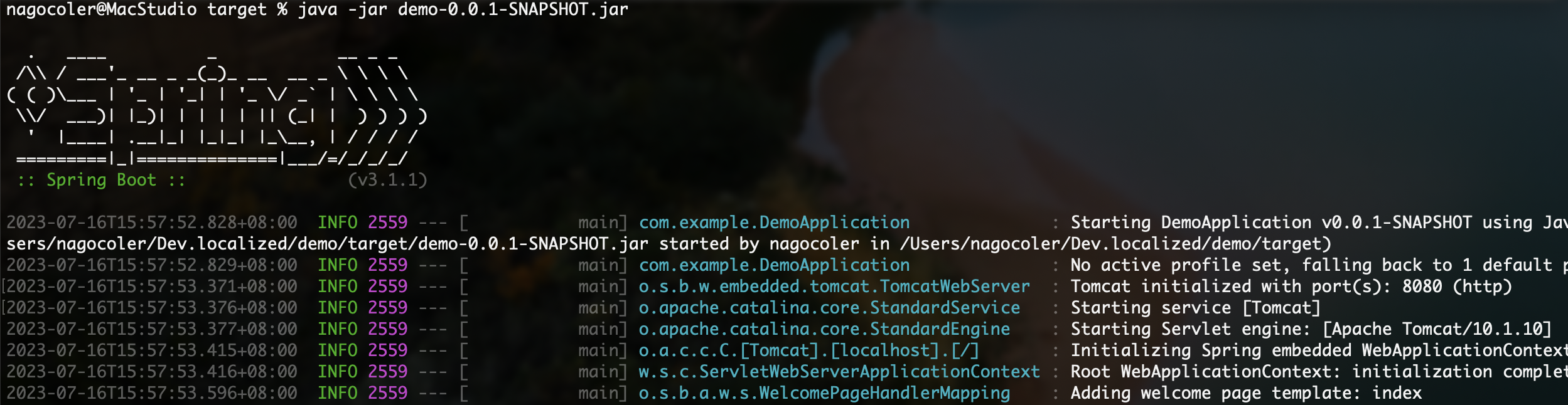
1 java -jar demo-0.0.1-SNAPSHOT.jar
这样就可以直接运行了:
现在,我们的 SpringBoot 项目就可以快速部署到任何计算机了,只要能够安装 JRE 环境,都可以通过命令一键运行。
当然,可能也会有小伙伴好奇,怎么才能像之前一样在我们的 Tomcat 服务器中运行呢?我们也可以将其打包为 War 包的形式部署到我们自己环境中的 Tomcat 服务器或是其他任何支持 Servlet 的服务器中,但是这种做法相对比较复杂,不太推荐采用这种方式进行项目部署,不过我们这里还是介绍一下。
首先我们需要排除掉 spring-boot-starter-web 中自带的 Tomcat 服务器依赖:
1 2 3 4 5 6 7 8 9 10 <dependency > <groupId > org.springframework.boot</groupId > <artifactId > spring-boot-starter-web</artifactId > <exclusions > <exclusion > <groupId > org.springframework.boot</groupId > <artifactId > spring-boot-starter-tomcat</artifactId > </exclusion > </exclusions > </dependency >
然后自行添加 Servlet 依赖:
1 2 3 4 5 <dependency > <groupId > jakarta.servlet</groupId > <artifactId > jakarta.servlet-api</artifactId > <scope > provided</scope > </dependency >
最后将打包方式修改为 war 包:
1 <packaging > war</packaging >
接着我们需要修改主类,将其继承 SpringBoot 需要的 Initializer(又回到 SSM 阶段那烦人的配置了,所以说一点不推荐这种部署方式)
1 2 3 4 5 6 7 8 9 10 11 12 @SpringBootApplication public class DemoApplication extends SpringBootServletInitializer { public static void main (String[] args) {@Override protected SpringApplicationBuilder configure (SpringApplicationBuilder builder) {return builder.sources(DemoApplication.class);
最后,我们再次运行 Maven 的 package 指令就可以打包为 war 包了:
我们可以直接将其部署到 Tomcat 服务器中(如何部署已经在 JavaWeb 篇介绍过了)
接着启动服务器就能正常访问了:
如果各位小伙伴需要在 IDEA 中进行调试运行,我们需要像之前一样配置一个 Tomcat 运行环境:
这样就可以跟之前一样使用外部 Tomcat 服务器了:
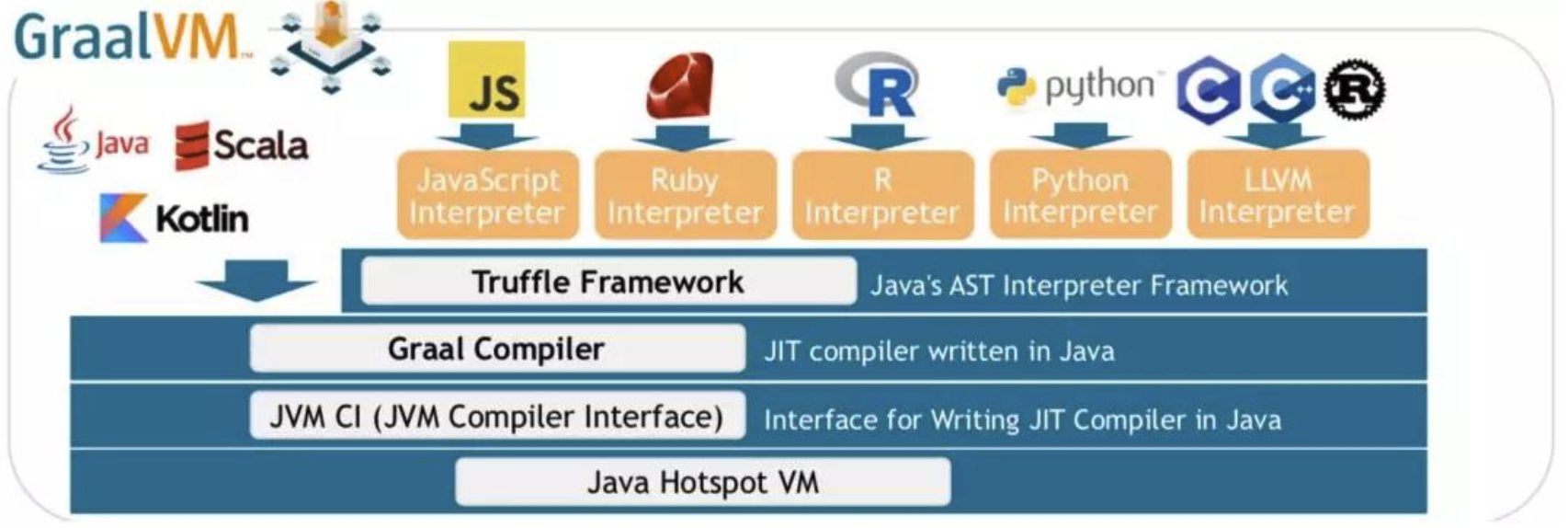
最后,我们需要特别介绍一下新的特性,在 SpringBoot3 之后,特别对 GraalVM 进行了支持:
GraalVM 是一种通用的虚拟机,最初由 Oracle 开发。它支持多种编程语言(例如 Java、JavaScript、Python 等),可以在不同的环境中运行,并提供高性能和低内存消耗。
GraalVM 的核心是一个即时编译器,它能够将各种语言的代码直接编译成本地机器码,以获得更高的性能。此外,GraalVM 还提供了一个强大的运行时环境,包括垃圾回收器、即时编译器、线程管理器等,可以提供更好的性能和可扩展性。
GraalVM 的一个重要特性是它的跨语言互操作性。GraalVM 可以使不同语言之间的互操作更加容易。例如,你可以在 Java 代码中直接调用 JavaScript 函数,或者在 JavaScript 代码中直接调用 Java 类。这使得在不同语言之间共享和复用代码变得更加容易。
总的来说,GraalVM 是一个开创性的技术,可以提供出色的性能和灵活性,同时也为多语言开发提供了更好的支持。它是一个非常有潜力的工具,可以用于构建高效的应用程序和解决方案。
简而言之,我们的 SpringBoot 项目除了打包为传统的 Jar 包基于 JVM 运行之外,我们也可以将其直接编译为操作系统原生的程序来进行使用(这样会大幅提升程序的运行效率,但是由于编译为操作系统原生程序,这将无法支持跨平台)
首先我们需要安装 GraalVM 的环境才可以,这跟安装普通 JDK 的操作是完全一样的,下载地址: https://github.com/graalvm/graalvm-ce-builds/releases/tag/jdk-17.0.7
下载好对应系统架构的 GraalVM 环境之后,就可以安装部署了,首先我们需要为 GraalVM 配置环境变量,将 GRAALVM_HOME 作为环境变量指向你的安装目录的 bin 目录下,接着我们就可以开始进行打包了(注意,SpringBoot 项目必须在创建的时候添加了 Native 支持才可以,否则无法正常打包)
注意,一定要将 GRAALVM_HOME 配置到环境变量中,否则会报错:
一切无误后,我们直接在 IDEA 中或是命令行中输入:
1 mvn -Pnative -DskipTests native:compile
接着会自动安装 native-image 组件,然后进行本地镜像的编译(建议挂梯,不然卡一天都下不动)
编译过程中比较消耗资源,建议 CPU 选择 6 核及以上,不然速度会很慢,编译完成之后如下图:
这样一个系统原生的 SpringBoot 项目就打包好了,我们可以直接运行这个程序:
不过由于 Mybatis 目前不支持 Native-Image,所以只能期待有朝一日这些框架都能够完整支持原生镜像,让我们的程序运行效率更上一层楼。
至此,关于 SpringBoot 的快速上手教程就全部结束了,其实只要 SSM 阶段学的扎实,到了 Boot 阶段之后也是轻轻松松,下一部分我们将隆重介绍一下 SpringBoot 的日志模块。
日志系统介绍 SpringBoot 为我们提供了丰富的日志系统,它几乎是开箱即用的。我们在之前学习 SSM 时,如果不配置日志,就会报错,但是到了 SpringBoot 阶段之后似乎这个问题就不见了,日志打印得也非常统一,这是为什么呢?
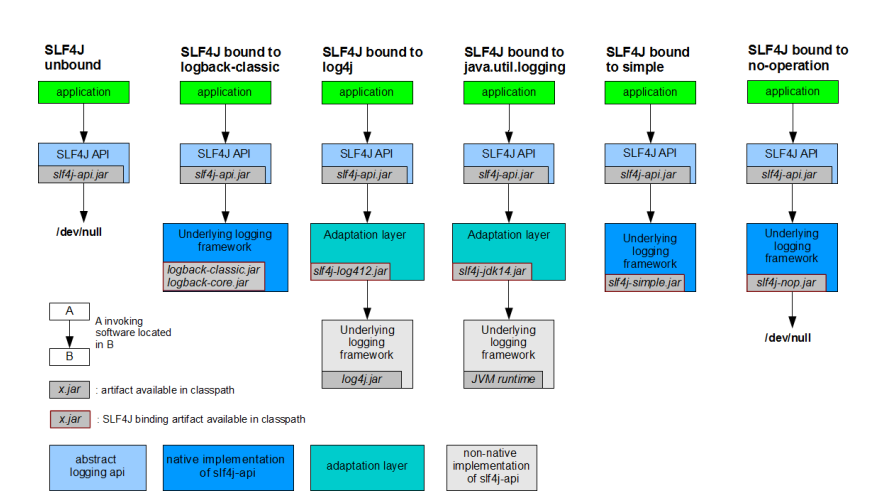
日志门面和日志实现 我们首先要区分一下,什么是日志门面(Facade)什么是日志实现,我们之前学习的 JUL 实际上就是一种日志实现,我们可以直接使用 JUL 为我们提供的日志框架来规范化打印日志。
而日志门面,如 Slf4j,是把不同的日志系统的实现进行了具体的抽象化,只提供了统一的日志使用接口,使用时只需要按照其提供的接口方法进行调用即可,由于它只是一个接口,并不是一个具体的可以直接单独使用的日志框架,所以最终日志的格式、记录级别、输出方式等都要通过接口绑定的具体的日志系统来实现,这些具体的日志系统就有 log4j、logback、java.util.logging 等,它们才实现了具体的日志系统的功能。
日志门面和日志实现就像 JDBC 和数据库驱动一样,一个是画大饼的,一个是真的去做饼的。
但是现在有一个问题就是,不同的框架可能使用了不同的日志框架,如果这个时候出现众多日志框架并存的情况,我们现在希望的是所有的框架一律使用日志门面(Slf4j)进行日志打印,这时该怎么去解决?我们不可能将其他框架依赖的日志框架替换掉,直接更换为 Slf4j 吧,这样显然不现实。
这时,可以采取类似于偷梁换柱的做法,只保留不同日志框架的接口和类定义等关键信息,而将实现全部定向为 Slf4j 调用。相当于有着和原有日志框架一样的外壳,对于其他框架来说依然可以使用对应的类进行操作,而具体如何执行,真正的内心已经是 Slf4j 的了。
所以,SpringBoot 为了统一日志框架的使用,做了这些事情:
直接将其他依赖以前的日志框架剔除
导入对应日志框架的 Slf4j 中间包
导入自己官方指定的日志实现,并作为 Slf4j 的日志实现层
打印项目日志信息 SpringBoot 使用的是 Slf4j 作为日志门面 ,Logback(Logback 是 log4j 框架的作者开发的新一代日志框架,它效率更高、能够适应诸多的运行环境,同时天然支持 SLF4J)作为日志实现,对应的依赖为:
1 2 3 4 <dependency > <groupId > org.springframework.boot</groupId > <artifactId > spring-boot-starter-logging</artifactId > </dependency >
此依赖已经被包含了,所以我们如果需要打印日志,可以像这样:
1 2 3 4 5 6 7 @ResponseBody @GetMapping("/test") public User test () {Logger logger = LoggerFactory.getLogger(TestController.class);"用户访问了一次测试数据" );return mapper.findUserById(1 );
因为我们使用了 Lombok,所以直接一个注解也可以搞定哦:
1 2 3 4 5 6 7 8 9 10 11 12 @Slf4j @Controller public class MainController {@ResponseBody @GetMapping("/test") public User test () {"用户访问了一次测试数据" );return mapper.findUserById(1 );
日志级别从低到高分为TRACE < DEBUG < INFO < WARN < ERROR ,SpringBoot 默认只会打印 INFO 以上级别的信息,效果如下,也是使用同样的格式打印在控制台的:
只需要添加 @Slf4j 注解即可直接使用 log.info/debug/warn 等进行控制台日志打印
配置 Logback 日志 Logback 官网:https://logback.qos.ch
和 JUL 一样,Logback 也能实现定制化,我们可以编写对应的配置文件,SpringBoot 推荐将配置文件名称命名为 logback-spring.xml 表示这是 SpringBoot 下 Logback 专用的配置,可以使用 SpringBoot 的高级 Profile 功能,它的内容类似于这样:
1 2 3 4 <?xml version="1.0" encoding="UTF-8" ?> <configuration > </configuration >
最外层由 configuration 包裹,一旦编写,那么就会替换默认的配置,所以如果内部什么都不写的话,那么会导致我们的 SpringBoot 项目没有配置任何日志输出方式,控制台也不会打印日志。
我们接着来看如何配置一个控制台日志打印,我们可以直接导入并使用 SpringBoot 为我们预设好的日志格式,在 org/springframework/boot/logging/logback/defaults.xml 中已经帮我们把日志的输出格式定义好了,我们只需要设置对应的 appender 即可:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 <included > <conversionRule conversionWord ="clr" converterClass ="org.springframework.boot.logging.logback.ColorConverter" /> <conversionRule conversionWord ="wex" converterClass ="org.springframework.boot.logging.logback.WhitespaceThrowableProxyConverter" /> <conversionRule conversionWord ="wEx" converterClass ="org.springframework.boot.logging.logback.ExtendedWhitespaceThrowableProxyConverter" /> <property name ="CONSOLE_LOG_PATTERN" value ="${CONSOLE_LOG_PATTERN:-%clr(%d{${LOG_DATEFORMAT_PATTERN:-yyyy-MM-dd HH:mm:ss.SSS}}){faint} %clr(${LOG_LEVEL_PATTERN:-%5p}) %clr(${PID:- }){magenta} %clr(---){faint} %clr([%15.15t]){faint} %clr(%-40.40logger{39}){cyan} %clr(:){faint} %m%n${LOG_EXCEPTION_CONVERSION_WORD:-%wEx}}" /> <property name ="CONSOLE_LOG_CHARSET" value ="${CONSOLE_LOG_CHARSET:-${file.encoding:-UTF-8}}" /> <property name ="FILE_LOG_PATTERN" value ="${FILE_LOG_PATTERN:-%d{${LOG_DATEFORMAT_PATTERN:-yyyy-MM-dd HH:mm:ss.SSS}} ${LOG_LEVEL_PATTERN:-%5p} ${PID:- } --- [%t] %-40.40logger{39} : %m%n${LOG_EXCEPTION_CONVERSION_WORD:-%wEx}}" /> <property name ="FILE_LOG_CHARSET" value ="${FILE_LOG_CHARSET:-${file.encoding:-UTF-8}}" /> <logger name ="org.apache.catalina.startup.DigesterFactory" level ="ERROR" /> <logger name ="org.apache.catalina.util.LifecycleBase" level ="ERROR" /> <logger name ="org.apache.coyote.http11.Http11NioProtocol" level ="WARN" /> <logger name ="org.apache.sshd.common.util.SecurityUtils" level ="WARN" /> <logger name ="org.apache.tomcat.util.net.NioSelectorPool" level ="WARN" /> <logger name ="org.eclipse.jetty.util.component.AbstractLifeCycle" level ="ERROR" /> <logger name ="org.hibernate.validator.internal.util.Version" level ="WARN" /> <logger name ="org.springframework.boot.actuate.endpoint.jmx" level ="WARN" /> </included >
导入后,我们利用预设的日志格式创建一个控制台日志打印:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 <?xml version="1.0" encoding="UTF-8" ?> <configuration > <include resource ="org/springframework/boot/logging/logback/defaults.xml" /> <appender name ="CONSOLE" class ="ch.qos.logback.core.ConsoleAppender" > <encoder > <pattern > ${CONSOLE_LOG_PATTERN}</pattern > <charset > ${CONSOLE_LOG_CHARSET}</charset > </encoder > </appender > <root level ="INFO" > <appender-ref ref ="CONSOLE" /> </root > </configuration >
配置完成后,我们发现控制台已经可以正常打印日志信息了。
接着我们来看看如何开启文件打印,我们只需要配置一个对应的 Appender 即可:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 <appender name ="FILE" class ="ch.qos.logback.core.rolling.RollingFileAppender" > <encoder > <pattern > ${FILE_LOG_PATTERN}</pattern > <charset > ${FILE_LOG_CHARSET}</charset > </encoder > <rollingPolicy class ="ch.qos.logback.core.rolling.SizeAndTimeBasedRollingPolicy" > <FileNamePattern > log/%d{yyyy-MM-dd}-spring-%i.log</FileNamePattern > <cleanHistoryOnStart > true</cleanHistoryOnStart > <maxHistory > 7</maxHistory > <maxFileSize > 10MB</maxFileSize > </rollingPolicy > </appender > <root level ="INFO" > <appender-ref ref ="CONSOLE" /> <appender-ref ref ="FILE" /> </root >
配置完成后,我们可以看到日志文件也能自动生成了。
我们也可以魔改官方提供的日志格式,官方文档:https://logback.qos.ch/manual/layouts.html
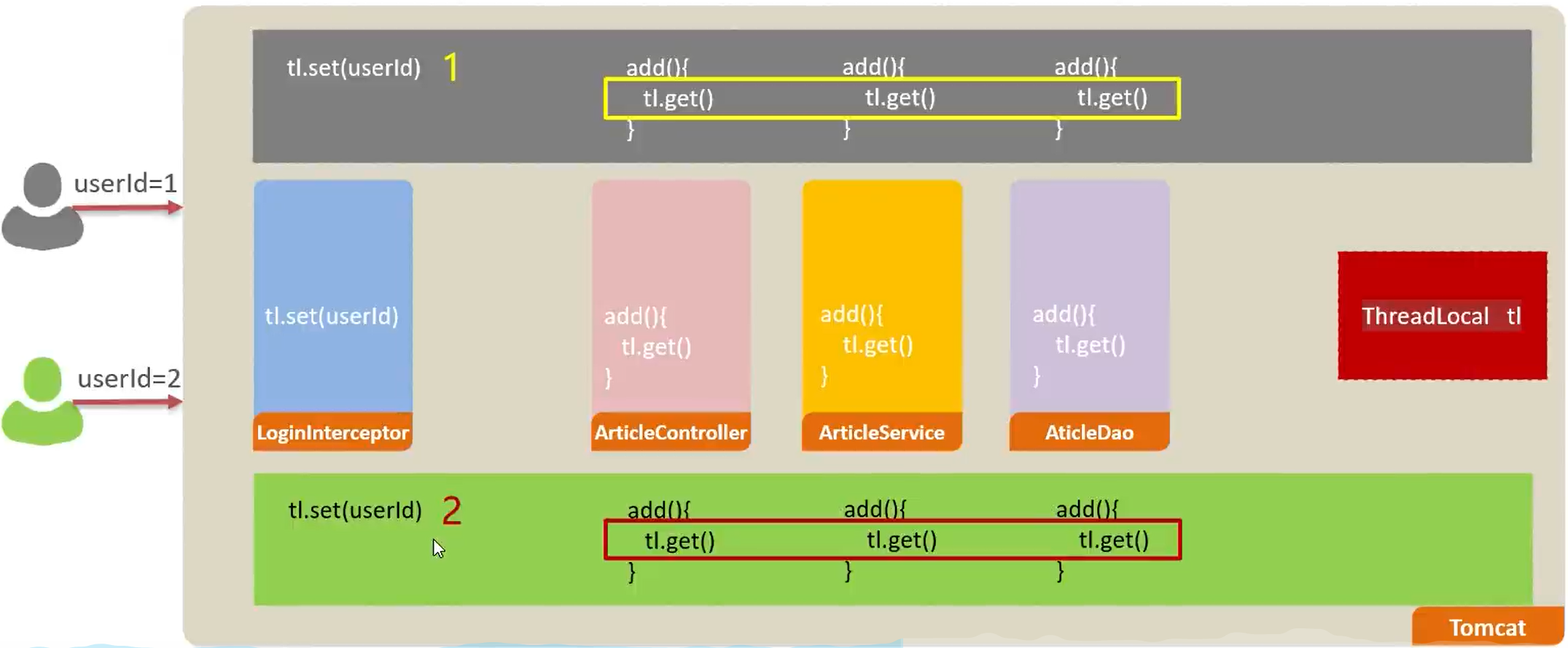
这里需要提及的是 MDC 机制,Logback 内置的日志字段还是比较少,如果我们需要打印有关业务的更多的内容,包括自定义的一些数据,需要借助 logback MDC 机制,MDC 为“Mapped Diagnostic Context”(映射诊断上下文),即将一些运行时的上下文数据通过 logback 打印出来;此时我们需要借助 org.sl4j.MDC 类。
比如我们现在需要记录是哪个用户访问我们网站的日志,只要是此用户访问我们网站,都会在日志中携带该用户的 ID,我们希望每条日志中都携带这样一段信息文本,而官方提供的字段无法实现此功能,这时就需要使用 MDC 机制:
1 2 3 4 5 6 7 @ResponseBody @GetMapping("/test") public User test (HttpServletRequest request) {"reqId" , request.getSession().getId());"用户访问了一次测试数据" );return mapper.findUserById(1 );
通过这种方式,我们就可以向日志中传入自定义参数了,我们日志中添加这样一个占位符 %X{键值},名字保持一致:
1 %clr([%X{reqId}]){faint}
这样当我们向 MDC 中添加信息后,只要是当前线程(本质是 ThreadLocal 实现)下输出的日志,都会自动替换占位符。
自定义 Banner 展示 我们在之前发现,实际上 Banner 部分和日志部分是独立的,SpringBoot 启动后,会先打印 Banner 部分,那么这个 Banner 部分是否可以自定义呢?答案是可以的。
我们可以直接来配置文件所在目录下创建一个名为 banner.txt 的文本文档,内容随便你:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 // _ooOoo_ //
可以使用在线生成网站进行生成自己的个性 Banner:https://www.bootschool.net/ascii
我们甚至还可以使用颜色代码来为文本切换颜色:
1 ${AnsiColor.BRIGHT_GREEN} //绿色
也可以获取一些常用的变量信息:
1 ${AnsiColor.YELLOW} 当前 Spring Boot 版本:${spring-boot.version}
前面忘了,后面忘了,狠狠赚一笔!
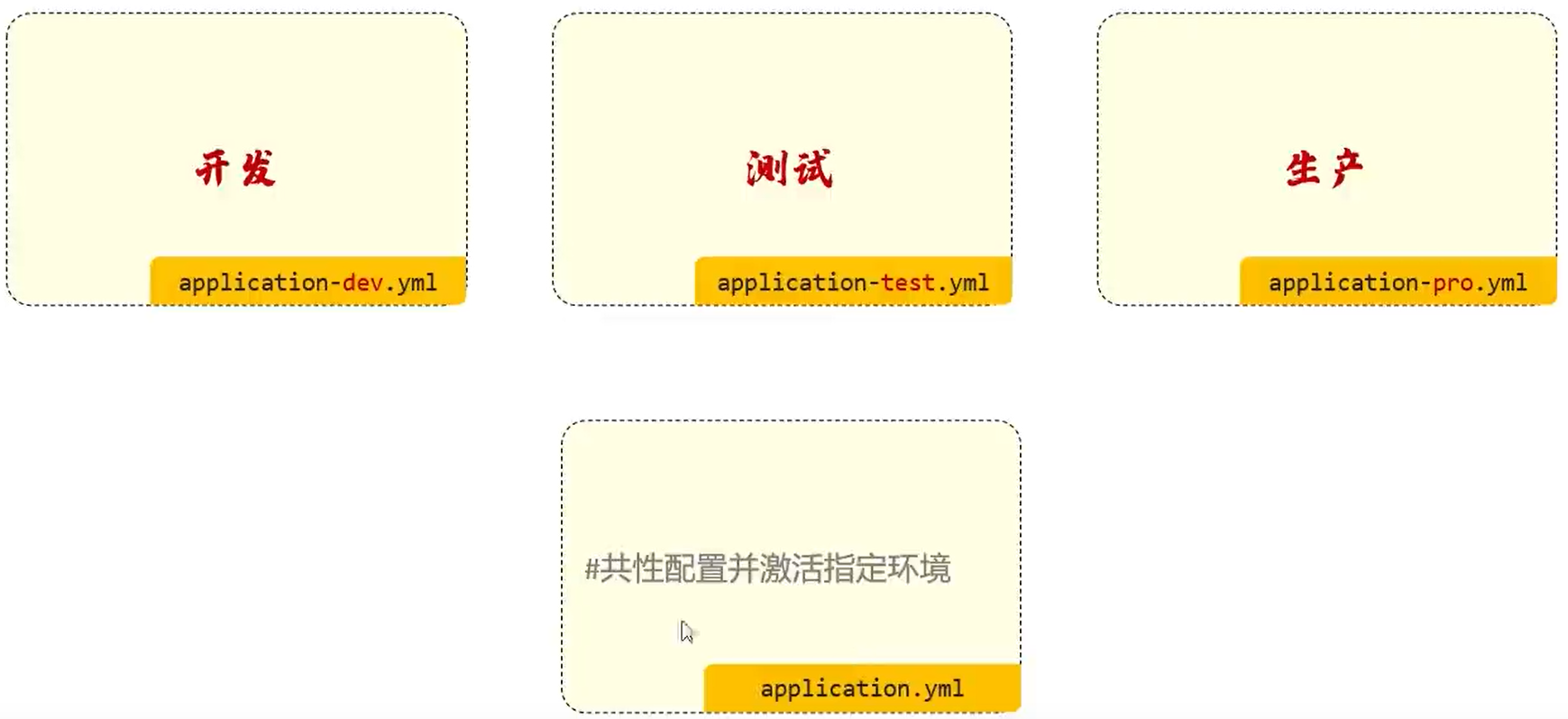
多环境配置 配置加载顺序
1、config/application.properties(项目根目录中config目录下)
在日常开发中,我们项目会有多个环境。例如开发环境(develop)也就是我们研发过程中疯狂敲代码修 BUG 阶段,生产环境(production )项目开发得差不多了,可以放在服务器上跑了。不同的环境下,可能我们的配置文件也存在不同,但是我们不可能切换环境的时候又去重新写一次配置文件,所以我们可以将多个环境的配置文件提前写好,进行自由切换。
由于 SpringBoot 只会读取 application.properties 或是 application.yml 文件,那么怎么才能实现自由切换呢?SpringBoot 给我们提供了一种方式,我们可以通过配置文件指定:
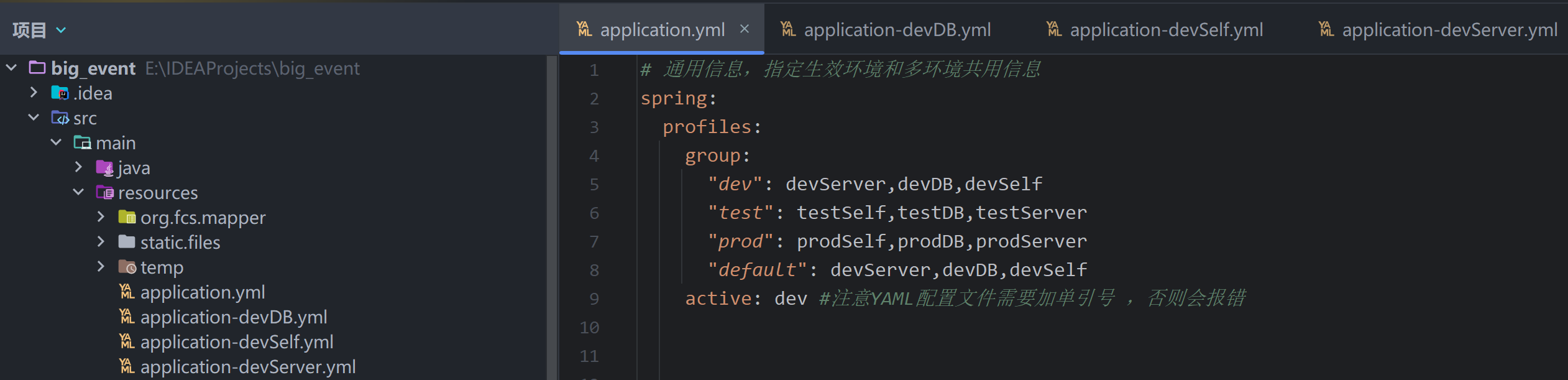
1 2 3 spring: profiles: active: dev
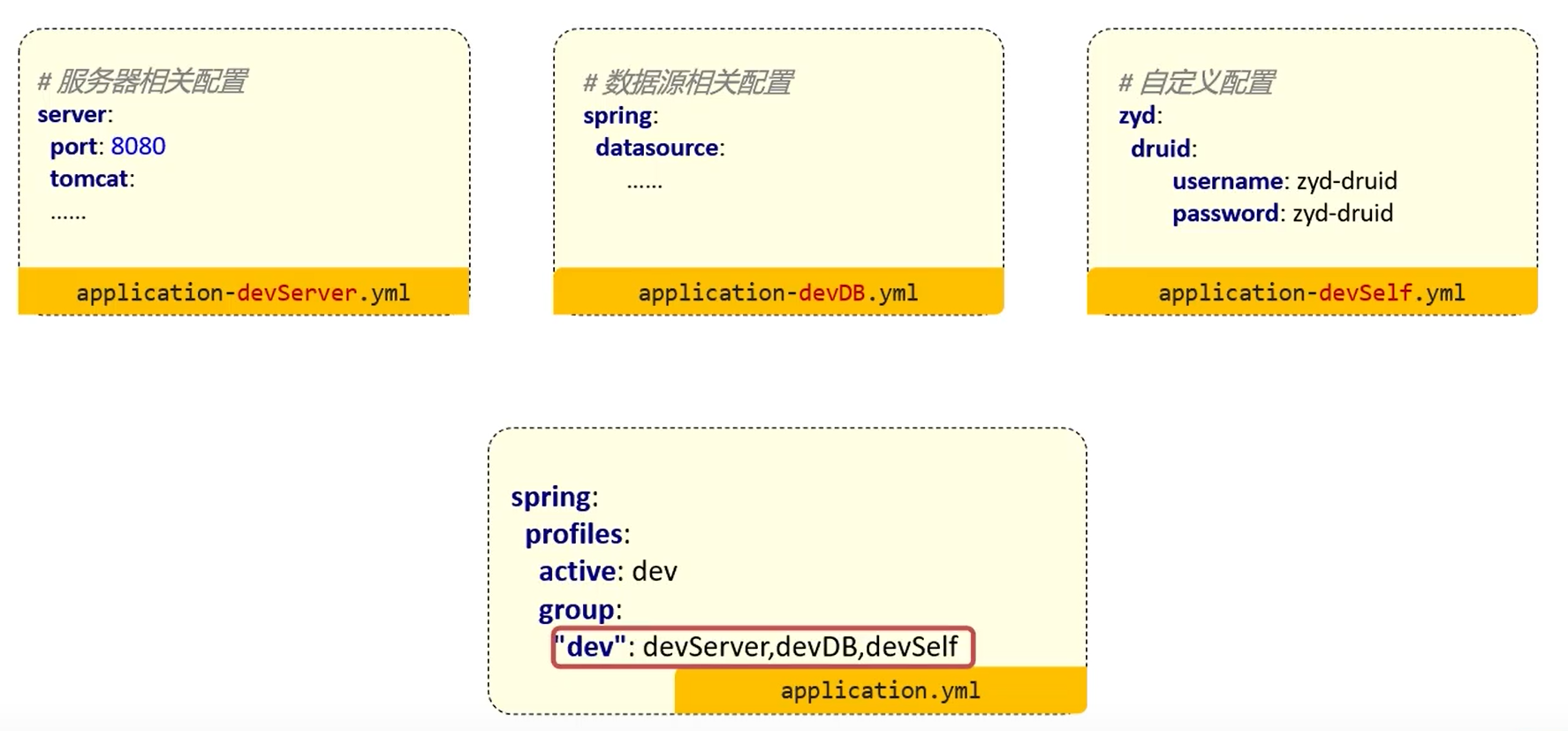
接着我们分别创建两个环境的配置文件,application-dev.yml 和 application-prod.yml 分别表示开发环境和生产环境的配置文件,比如开发环境我们使用的服务器端口为 8080,而生产环境下可能就需要设置为 80 或是 443 端口,那么这个时候就需要不同环境下的配置文件进行区分:
这样我们就可以灵活切换生产环境和开发环境下的配置文件了。
SpringBoot 自带的 Logback 日志系统也是支持多环境配置的,比如我们想在开发环境下输出日志到控制台和文件,而生产环境下只需要输出到文件即可,这时就需要进行环境配置:
1 2 3 4 5 6 7 8 9 10 11 12 <springProfile name ="dev" > <root level ="INFO" > <appender-ref ref ="CONSOLE" /> <appender-ref ref ="FILE" /> </root > </springProfile > <springProfile name ="prod" > <root level ="INFO" > <appender-ref ref ="FILE" /> </root > </springProfile >
注意 springProfile 是区分大小写的!
那如果我们希望生产环境中不要打包开发环境下的配置文件呢,我们目前虽然可以切换开发环境,但是打包的时候依然是所有配置文件全部打包,这样总感觉还欠缺一点完美,因此,打包的问题就只能找 Maven 解决了,Maven 也可以设置多环境:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 <profiles > <profile > <id > dev</id > <activation > <activeByDefault > true</activeByDefault > </activation > <properties > <environment > dev</environment > </properties > </profile > <profile > <id > prod</id > <activation > <activeByDefault > false</activeByDefault > </activation > <properties > <environment > prod</environment > </properties > </profile > </profiles >
接着,我们需要根据环境的不同,排除其他环境的配置文件 :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 <resources > <resource > <directory > src/main/resources</directory > <excludes > <exclude > application*.yml</exclude > </excludes > </resource > <resource > <directory > src/main/resources</directory > <filtering > true</filtering > <includes > <include > application.yml</include > <include > application-${environment}.yml</include > </includes > </resource > </resources >
接着,我们可以直接将 Maven 中的 environment 属性,传递给 SpringBoot 的配置文件,在构建时替换为对应的值:
1 2 3 spring: profiles: active: '@environment@'
这样,根据我们 Maven 环境的切换,SpringBoot 的配置文件也会进行对应的切换。
最后我们打开 Maven 栏目,就可以自由切换了,直接勾选即可,注意切换环境之后要重新加载一下 Maven 项目 ,不然不会生效!
[!NOTE] 日志和环境配置总结
SpringBoot 统一使用SLFJ 日志门面结合 logback 日志实现进行打印,只需要添加 @Slf4j 注解 即可进行 log 打印
编写 logback-spring.xml 文件进行日志信息自定义配置,可配置日志样式、类型、有效期、大小 等。
编写 banner.txt 文件可自定义程序启动时的banner 样式
多环境配置需要编写 application.yml 设置spring->profiles->active 属性进行环境切换,按需添加不同环境(dev、prod 等)
多环境下可以按照不同环境配置日志打印规则,选择控制台或文件 记录日志。
可以通过配置 pol.xml 文件的profiles 和 build 下的 resources 设置多环境下根据当前使用环境打包对应配置文件过滤其他文件
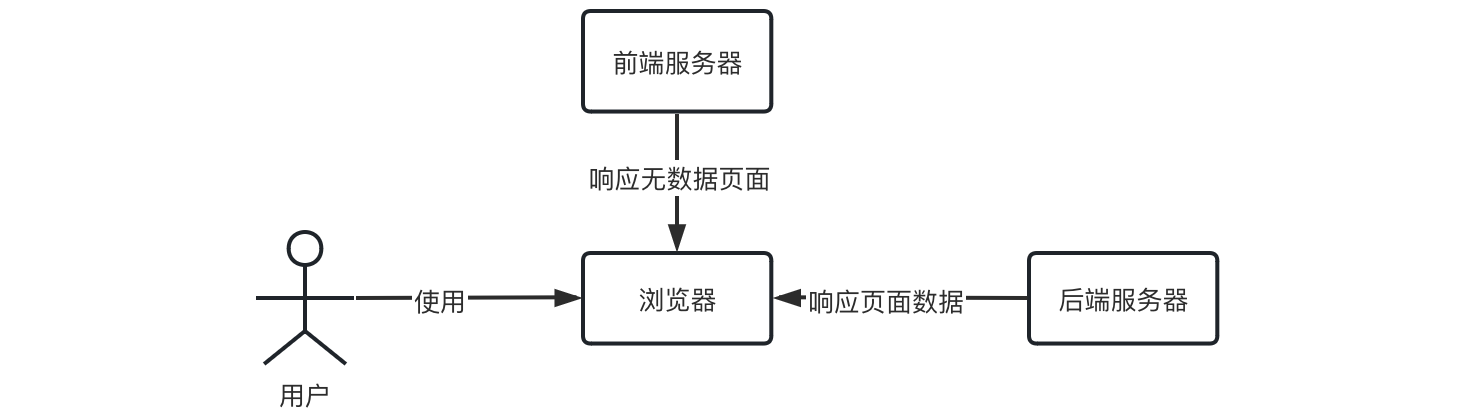
常用框架介绍 前面我们介绍了 SpringBoot 项目的基本搭建,相信各位小伙伴已经体验到 SpringBoot 3 带来的超强便捷性了,不过光靠这些还不够,我们还需要了解更多框架来丰富我们的网站,通过了解其他的 SpringBoot 整合框架,我们就可以在我们自己的 Web 服务器上实现更多更高级的功能,同时也是为了给我们后续学习前后端分离项目做准备。
邮件发送模块 都什么年代了,还在发传统邮件,我们来看看电子邮件。
我们在注册很多的网站时,都会遇到邮件或是手机号验证,也就是通过你的邮箱或是手机短信去接受网站发给你的注册验证信息,填写验证码之后,就可以完成注册了,同时,网站也会绑定你的手机号或是邮箱。
那么,像这样的功能,我们如何实现呢?SpringBoot 已经给我们提供了封装好的邮件模块使用:
1 2 3 4 <dependency > <groupId > org.springframework.boot</groupId > <artifactId > spring-boot-starter-mail</artifactId > </dependency >
在学习邮件发送之前,我们需要先了解一下什么是电子邮件。
电子邮件也是一种通信方式,是互联网应用最广的服务。通过网络的电子邮件系统,用户可以以非常低廉的价格(不管发送到哪里,都只需负担网费,实际上就是把信息发送到对方服务器而已)、非常快速的方式,与世界上任何一个地方的电子邮箱用户联系。
虽说方便倒是方便,虽然是曾经的霸主,不过现在这个时代,QQ 微信横行,手机短信和电子邮箱貌似就只剩收验证码这一个功能了。
要在 Internet 上提供电子邮件功能,必须有专门的电子邮件服务器。例如现在 Internet 很多提供邮件服务的厂商:新浪、搜狐、163、QQ 邮箱等,他们都有自己的邮件服务器。这些服务器类似于现实生活中的邮局,它主要负责接收用户投递过来的邮件,并把邮件投递到邮件接收者的电子邮箱中。
所有的用户都可以在电子邮件服务器上申请一个账号用于邮件发送和接收,那么邮件是以什么样的格式发送的呢?实际上和 Http 一样,邮件发送也有自己的协议,也就是约定邮件数据长啥样以及如何通信。
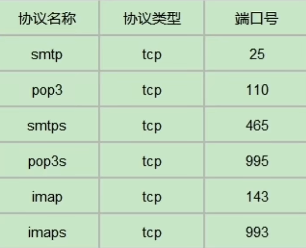
比较常用的协议有两种:
SMTP 协议(主要用于发送邮件 Simple Mail Transfer Protocol)
POP3 协议(主要用于接收邮件 Post Office Protocol 3)
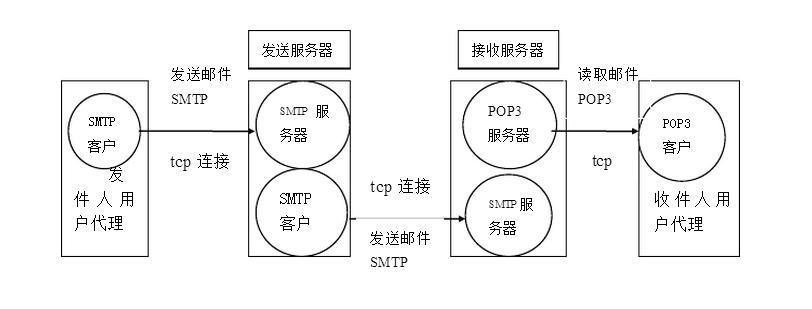
整个发送/接收流程大致如下:
实际上每个邮箱服务器都有一个 smtp 发送服务器和 pop3 接收服务器,比如要从 QQ 邮箱发送邮件到 163 邮箱,那么我们只需要通过 QQ 邮箱客户端告知 QQ 邮箱的 smtp 服务器我们需要发送邮件,以及邮件的相关信息,然后 QQ 邮箱的 smtp 服务器就会帮助我们发送到 163 邮箱的 pop3 服务器上,163 邮箱会通过 163 邮箱客户端告知对应用户收到一封新邮件。
而我们如果想要实现给别人发送邮件,那么就需要连接到对应电子邮箱的 smtp 服务器上,并告知其我们要发送邮件。而 SpringBoot 已经帮助我们将最基本的底层通信全部实现了,我们只需要关心 smtp 服务器的地址以及我们要发送的邮件长啥样即可。
这里以163邮箱 https://mail.163.com 为例,我们需要在配置文件中告诉 SpringBootMail 我们的 smtp 服务器的地址以及你的邮箱账号和密码,首先我们要去设置中开启 smtp/pop3 服务才可以,开启后会得到一个随机生成的密钥,这个就是我们的密码。
1 2 3 4 5 6 7 8 spring: mail: host: smtp.163.com/smtp.qq.com username: javastudy111@163.com / xxx@qq.com password: AZJTOAWZESLMHTNI
配置完成后,接着我们来进行一下测试:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 @SpringBootTest class SpringBootTestApplicationTests {@Autowired @Test void contextLoads () {SimpleMailMessage message = new SimpleMailMessage ();"【电子科技大学教务处】关于近期学校对您的处分决定" );"XXX 同学您好,经监控和教务巡查发现,您近期存在旷课、迟到、早退、上课刷抖音行为," +"现已通知相关辅导员,请手写 5000 字书面检讨,并在 2022 年 4 月 1 日 17 点前交到辅导员办公室。" );"你的 QQ 号@qq.com" );" javastudy111@163.com " );
如果需要添加附件等更多功能,可以使用 MimeMessageHelper 来帮助我们完成:
1 2 3 4 5 6 7 8 9 10 11 12 13 @Test void contextLoads () throws MessagingException {MimeMessage message = sender.createMimeMessage();MimeMessageHelper helper = new MimeMessageHelper (message, true );"Test" );"lbwnb" );"你的 QQ 号@qq.com" );" javastudy111@163.com " );
最后,我们来尝试为我们的网站实现一个邮件注册功能,首先明确验证流程:请求验证码 -> 生成验证码(临时有效,注意设定过期时间) -> 用户输入验证码并填写注册信息 -> 验证通过注册成功!
[!NOTE] 注意
最好将 GetMapping 和 PostMapping 分开写,也最好不要和模板混合在一起,否则会很容易由于传参有问题出 bug
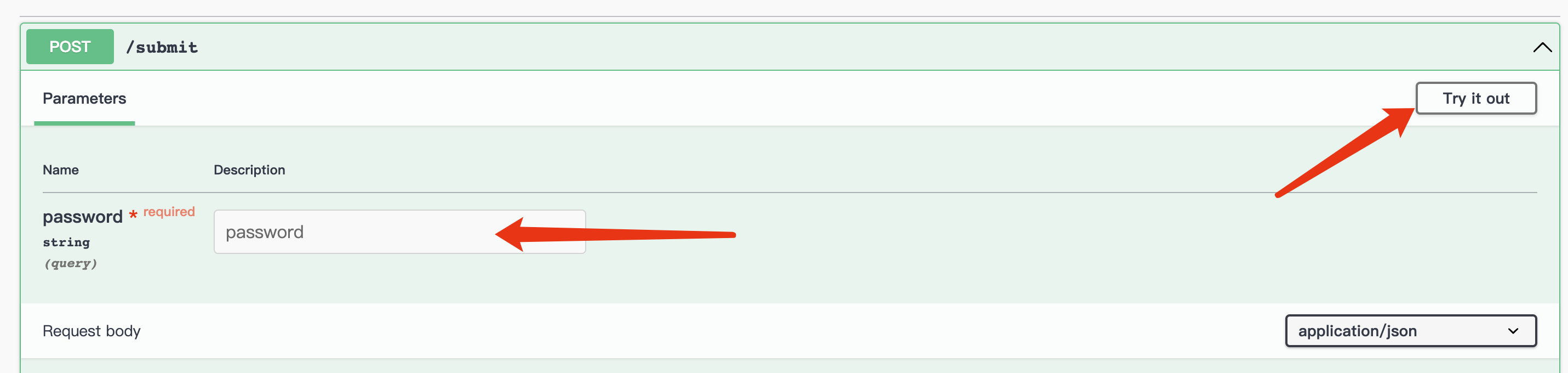
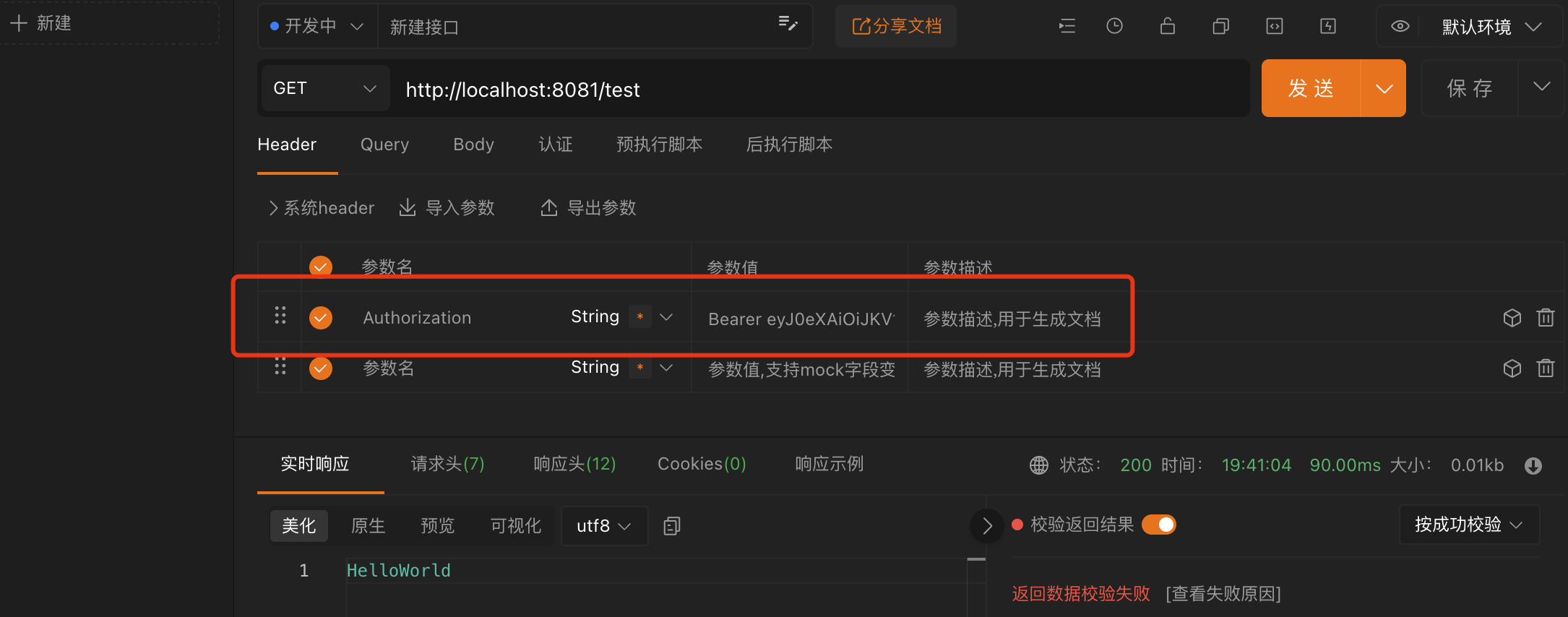
接口规则校验 通常我们在使用 SpringMvc 框架编写接口时,很有可能用户发送的数据存在一些问题,比如下面这个接口:
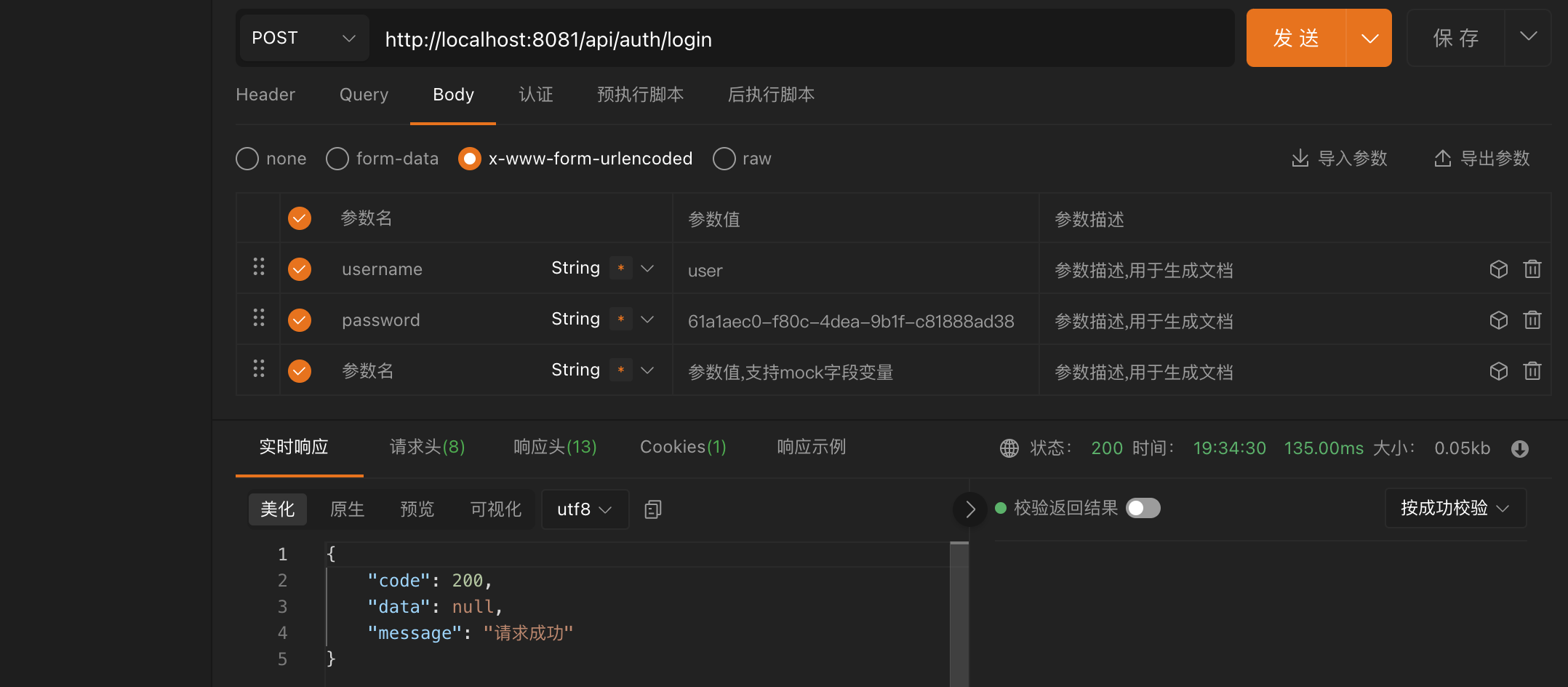
1 2 3 4 5 6 7 8 @ResponseBody @PostMapping("/submit") public String submit (String username, String password) {3 ));2 , 10 ));return "请求成功!" ;
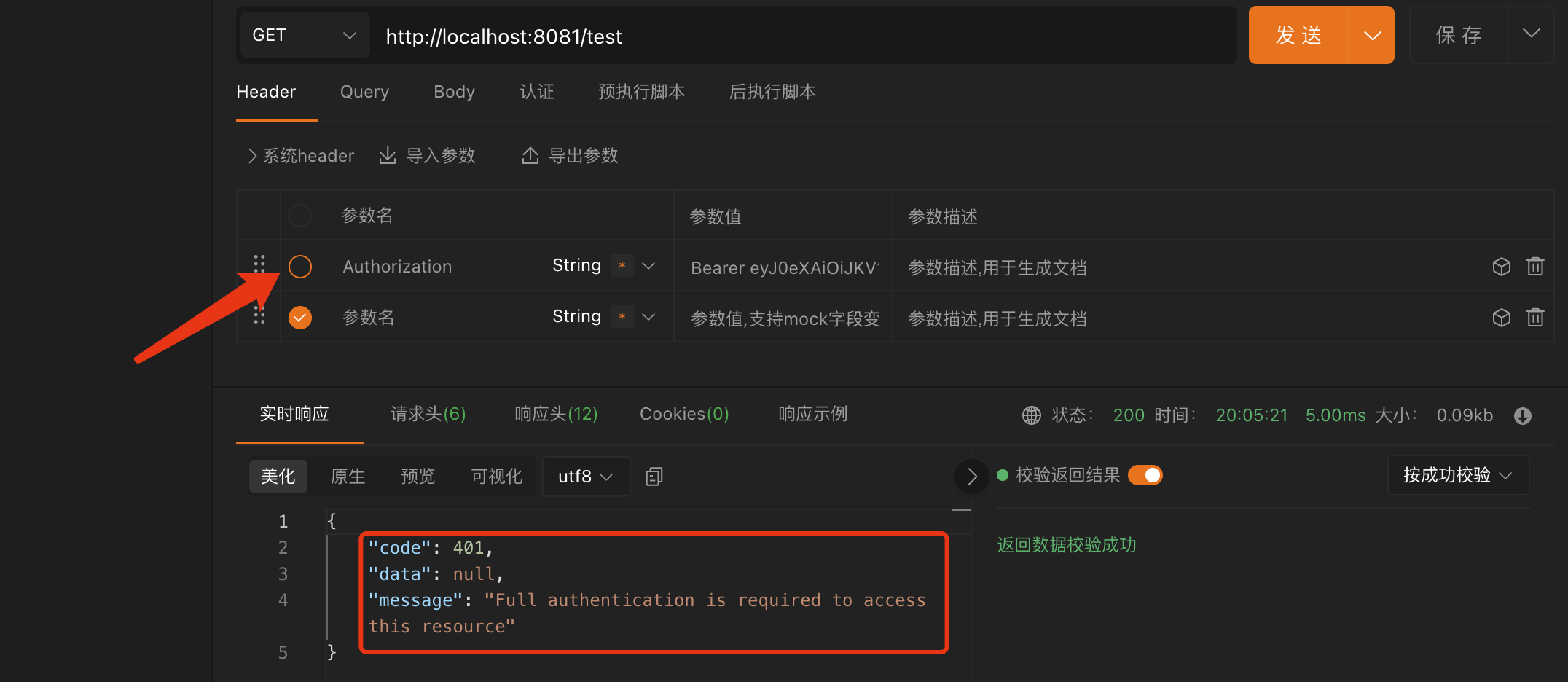
这个接口中,我们需要将用户名和密码分割然后打印,在正常情况下,因为用户名长度规定不小于 5,如果用户发送的数据是没有问题的,那么就可以正常运行,这也是我们所希望的情况,但是如果用户发送的数据并不是按照规定的,那么就会直接报错:
这个时候,我们就需要在请求进来之前进行校验了,最简单的办法就是判断一下:
1 2 3 4 5 6 7 8 9 10 11 12 @ResponseBody @PostMapping("/submit") public String submit (String username, String password) {if (username.length() > 3 && password.length() > 10 ) {3 ));2 , 10 ));return "请求成功!" ;else {return "请求失败" ;
虽然这样就能直接解决问题,但是如果我们的每一个接口都需要这样去进行配置,将会很麻烦,SpringBoot 为我们提供了很方便的接口校验框架:
1 2 3 4 <dependency > <groupId > org.springframework.boot</groupId > <artifactId > spring-boot-starter-validation</artifactId > </dependency >
现在,我们可以直接使用注解完成全部接口的校验:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 @Slf4j @Validated @Controller public class TestController {@ResponseBody @PostMapping("/submit") public String submit (@Length(min = 3) String username, //使用@Length 注解一步到位 @Length(min = 10) String password) {3 ));2 , 10 ));return "请求成功!" ;
现在,我们的接口校验就可以快速进行配置了,一个接口就能搞定:
不过这样依然会抛出一个异常,对用户不太友好,我们可以稍微处理一下,这里我们可以直接使用之前在 SSM 阶段中学习的异常处理 Controller 来自行处理这类异常:
1 2 3 4 5 6 7 8 9 @ControllerAdvice public class ValidationController {@ResponseBody @ExceptionHandler(ConstraintViolationException.class) public String error (ValidationException e) {return e.getMessage();
除了@Length 之外,我们也可以使用其他的接口来实现各种数据校验:
验证注解
验证的数据类型
说明
@AssertFalse
Boolean,boolean
值必须是 false
@AssertTrue
Boolean,boolean
值必须是 true
@NotNull
任意类型
值不能是 null
@Null
任意类型
值必须是 null
@Min
BigDecimal、BigInteger、byte、short、int、long、double 以及任何 Number 或 CharSequence 子类型
大于等于@Min 指定的值
@Max
同上
小于等于@Max 指定的值
@DecimalMin
同上
大于等于@DecimalMin 指定的值(超高精度)
@DecimalMax
同上
小于等于@DecimalMax 指定的值(超高精度)
@Digits
同上
限制整数位数和小数位数上限
@Size
字符串、Collection、Map、数组等
长度在指定区间之内,如字符串长度、集合大小等
@Past
如 java.util.Date, java.util.Calendar 等日期类型
值必须比当前时间早
@Future
同上
值必须比当前时间晚
@NotBlank
CharSequence 及其子类
值不为空,在比较时会去除字符串的首位空格
@Length
CharSequence 及其子类
字符串长度在指定区间内
@NotEmpty
CharSequence 及其子类、Collection、Map、数组
值不为 null 且长度不为空(字符串长度不为 0,集合大小不为 0)
@Range
BigDecimal、BigInteger、CharSequence、byte、short、int、long 以及原子类型和包装类型
值在指定区间内
@Email
CharSequence 及其子类
值必须是邮件格式
@Pattern
CharSequence 及其子类
值需要与指定的正则表达式匹配
@Valid
任何非原子类型
用于验证对象属性
虽然这样已经很方便了,但是在遇到对象的时候,依然不太方便,比如:
1 2 3 4 5 @Data public class Account {
1 2 3 4 5 6 7 @ResponseBody @PostMapping("/submit") public String submit (Account account) { 3 ));2 , 10 ));return "请求成功!" ;
此时接口是以对象形式接收前端发送的表单数据的,这个时候就没办法向上面一样编写对应的校验规则了,那么现在又该怎么做呢?
对应对象类型,我们也可以进行验证,方法如下:
1 2 3 4 5 6 7 @ResponseBody @PostMapping("/submit") public String submit (@Valid Account account) {3 ));2 , 10 ));return "请求成功!" ;
1 2 3 4 5 6 7 @Data public class Account {@Length(min = 3) @Length(min = 10)
这样当受到请求时,就会对对象中的字段进行校验了,这里我们稍微修改一下 ValidationController 的错误处理,对于实体类接收参数的验证 ,会抛出 MethodArgumentNotValidException 异常,这里也进行一下处理:
1 2 3 4 5 6 7 8 9 10 11 @ResponseBody @ExceptionHandler({ConstraintViolationException.class, MethodArgumentNotValidException.class}) public String error (Exception e) {if (e instanceof ConstraintViolationException exception) {return exception.getMessage();else if (e instanceof MethodArgumentNotValidException exception){if (exception.getFieldError() == null ) return "未知错误" ;return exception.getFieldError().getDefaultMessage();return "未知错误" ;
这样就可以正确返回对应的错误信息了。
接口文档生成(选学) 在后续学习前后端分离开发中,前端现在由专业的人来做,而我们往往只需要关心后端提供什么接口给前端人员调用,我们的工作被进一步细分了,这个时候为前端开发人员提供一个可以参考的文档是很有必要的。
但是这样的一个文档,我们也不可能单独写一个项目去进行维护,并且随着我们的后端项目不断更新,文档也需要跟随更新,这显然是很麻烦的一件事情,那么有没有一种比较好的解决方案呢?
当然有,那就是丝袜哥:Swagger
Swagger 的主要功能如下:
支持 API 自动生成同步的在线文档:使用 Swagger 后可以直接通过代码生成文档,不再需要自己手动编写接口文档了,对程序员来说非常方便,可以节约写文档的时间去学习新技术。
提供 Web 页面在线测试 API:光有文档还不够,Swagger 生成的文档还支持在线测试。参数和格式都定好了,直接在界面上输入参数对应的值即可在线测试接口。
结合 Spring 框架(Spring-doc,官网: https://springdoc.org/ ),Swagger 可以很轻松地利用注解以及扫描机制,来快速生成在线文档,以实现当我们项目启动之后,前端开发人员就可以打开 Swagger 提供的前端页面,查看和测试接口。依赖如下:
1 2 3 4 5 <dependency > <groupId > org.springdoc</groupId > <artifactId > springdoc-openapi-starter-webmvc-ui</artifactId > <version > 2.1.0</version > </dependency >
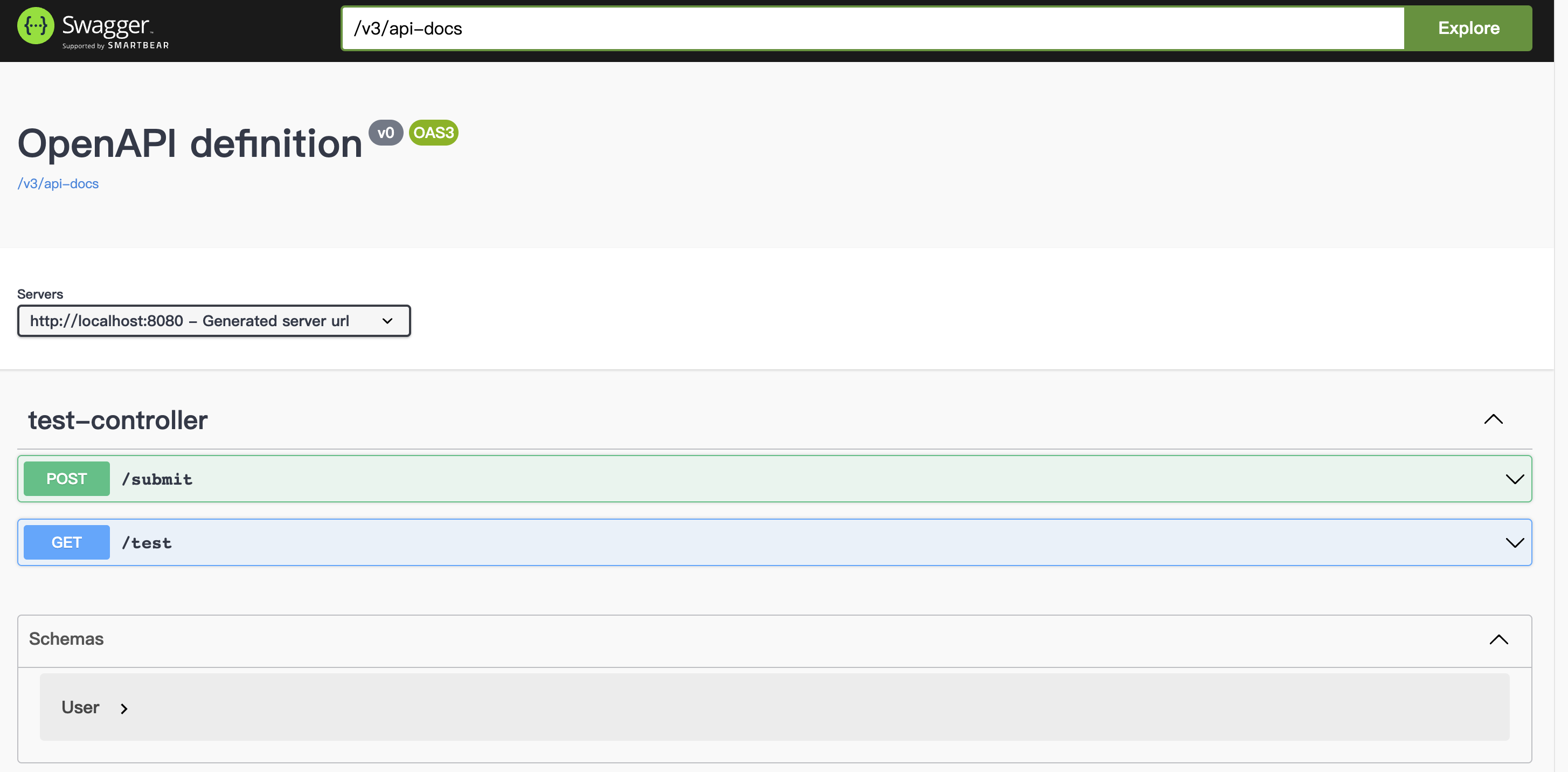
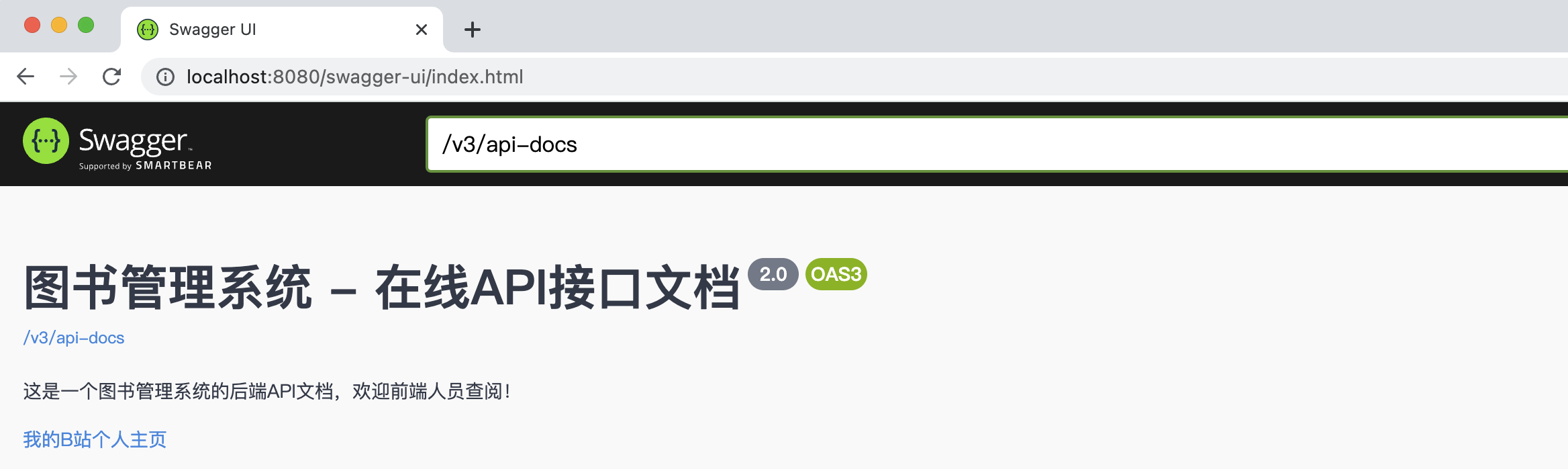
项目启动之后,我们可以直接访问: http://localhost:8080/swagger-ui/index.html ,就能看到我们的开发文档了:
可以看到这个开发文档中自动包含了我们定义的接口,并且还有对应的实体类也放在了下面。这个页面不仅仅是展示接口,也可以直接在上面进行调试:
这就非常方便了,不仅前端人员可以快速查询接口定义,我们自己也可以在线进行接口测试,直接抛弃 PostMan 之类的软件了。
虽然 Swagger 的 UI 界面已经可以很好地展示后端提供的接口信息了,但是非常的混乱,我们来看看如何配置接口的一些描述信息。首先我们的页面肯定要展示一下这个文档的一些信息,只需要一个 Bean 就能搞定,SwaggerConfiguration.java:
1 2 3 4 5 6 7 8 9 @Bean public OpenAPI springDocOpenAPI () {return new OpenAPI ().info(new Info ()"图书管理系统 - 在线 API 接口文档" ) "这是一个图书管理系统的后端 API 文档,欢迎前端人员查阅!" ) "2.0" ) new License ().name("我的 B 站个人主页" ) " https://space.bilibili.com/37737161" )));
这样我们的页面中就会展示自定义的文本信息了:
接着我们来看看如何为一个 Controller 编写 API 描述信息:
1 2 3 4 5 @Tag(name = "账户验证相关", description = "包括用户登录、注册、验证码请求等操作。") public class TestController {
我们可以直接在类名称上面添加 @Tag 注解,并填写相关信息,来为当前的 Controller 设置描述信息。接着我们可以为所有的请求映射配置描述信息:
1 2 3 4 5 6 7 8 9 10 11 @ApiResponses({ @ApiResponse(responseCode = "200", description = "测试成功"), @ApiResponse(responseCode = "500", description = "测试失败") //不同返回状态码描述 }) @Operation(summary = "请求用户数据测试接口") @ResponseBody @GetMapping("/hello") public String hello (@Parameter(description = "测试文本数据", example = "KFCvivo50") @RequestParam String text) {return "Hello World" ;
对于那些不需要展示在文档中的接口,我们也可以将其忽略掉:
1 2 3 4 5 6 @Hidden @ResponseBody @GetMapping("/hello") public String hello () {return "Hello World" ;
对于实体类 ,我们也可以编写对应的 API 接口文档:
1 2 3 4 5 6 7 8 9 10 11 12 @Data @Schema(description = "用户信息实体类") public class User {@Schema(description = "用户编号") int id;@Schema(description = "用户名称") @Schema(description = "用户邮箱") @Schema(description = "用户密码")
这样,我们就可以在文档中查看实体类简介以及各个属性的介绍了。
不过,这种文档只适合在开发环境下生成,如果是生产环境,我们需要关闭文档:
1 2 3 springdoc:false
注解
作用
示例
@Tag 为 RestController 添加综合信息
@Tag(name = “账号验证相关接口”, description = “包括用户登陆、注册、验证码请求等等!”)
@Operation 为具体某个接口添加注释信息
@Operation(summary = “请求用户数据测试接口”, description = “根据用户 id 请求获取用户”) //接口功能描述
@ApiResponses 为接口返回状态码添加描述
@ApiResponses({@ApiResponse(responseCode = “200”, description = “测试成功”),@ApiResponse(responseCode = “500”, description = “测试失败”) //不同返回状态码描述})
@Parameter 为接口参数添加示例描述
@Parameter(description = “测试用户 id 数据”, example = “1”)
@Hidden 隐藏接口不进行展示
@Hidden
Schema 对实体类添加描述(包括字段)
@Schema(description = “用户信息实体类”);@Schema(description = “用户名”)
项目运行监控(选学) 我们的项目开发完成之后,肯定是需要上线运行的,不过在项目的运行过程中,我们可能需要对其进行监控,从而实时观察其运行状态,并在发生问题时做出对应调整,因此,集成项目运行监控就很有必要了。
SpringBoot 框架提供了 spring-boot-starter-actuator 模块来实现监控效果:
1 2 3 4 <dependency > <groupId > org.springframework.boot</groupId > <artifactId > spring-boot-starter-actuator</artifactId > </dependency >
添加好之后,Actuator 会自动注册一些接口用于查询当前 SpringBoot 应用程序的状态,官方文档如下: https://docs.spring.io/spring-boot/docs/3.1.1/actuator-api/htmlsingle/#overview
默认情况下,所有 Actuator 自动注册的接口路径都是 /actuator/{id} 格式的(可在配置文件中修改),比如我们想要查询当前服务器的健康状态,就可以访问这个接口: http://localhost:8080/actuator/health ,结果会以 JSON 格式返回给我们:
直接访问:http://localhost:8080/actuator 根路径,可以查看当前已经开启的所有接口,默认情况下只开启以下接口:
1 2 3 4 5 6 7 { "_links" : { "self" : { "href" : " http://localhost:8080/actuator" , "templated" : false } , "health-path" : { "href" : " http://localhost:8080/actuator/health/ {*path}" , "templated" : true } , "health" : { "href" : " http://localhost:8080/actuator/health" , "templated" : false } } }
我们可以来修改一下配置文件,让其暴露全部接口:
1 2 3 4 5 management: endpoints: web: exposure: include: '*'
重启服务器,再次获取可用接口就可以看到全部的信息了,这里就不全部搬出来了,只列举一些常用的:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 { "_links" : { "self" : { "href" : " http://localhost:8080/actuator" , "templated" : false } , "beans" : { "href" : " http://localhost:8080/actuator/beans" , "templated" : false } , "health" : { "href" : " http://localhost:8080/actuator/health" , "templated" : false } , "health-path" : { "href" : " http://localhost:8080/actuator/health/ {*path}" , "templated" : true } , "info" : { "href" : " http://localhost:8080/actuator/info" , "templated" : false } , "env" : { "href" : " http://localhost:8080/actuator/env" , "templated" : false } , "env-toMatch" : { "href" : " http://localhost:8080/actuator/env/ {toMatch}" , "templated" : true } , "loggers" : { "href" : " http://localhost:8080/actuator/loggers" , "templated" : false } , "loggers-name" : { "href" : " http://localhost:8080/actuator/loggers/ {name}" , "templated" : true } , "heapdump" : { "href" : " http://localhost:8080/actuator/heapdump" , "templated" : false } , "threaddump" : { "href" : " http://localhost:8080/actuator/threaddump" , "templated" : false } , "scheduledtasks" : { "href" : " http://localhost:8080/actuator/scheduledtasks" , "templated" : false } , "mappings" : { "href" : " http://localhost:8080/actuator/mappings" , "templated" : false } , } }
比如我们可以通过 http://localhost:8080/actuator/info 接口查看当前系统运行环境信息:
我们发现,这里得到的数据是一个空的,这是因为我们还需要单独开启对应模块才可以:
1 2 3 4 5 6 7 8 9 10 11 12 13 management: endpoints: web: exposure: include: '*' info: env: enabled: true os: enabled: true java: enabled: true
再次请求,就能获得运行环境相关信息了,比如这里的 Java 版本、JVM 信息、操作系统信息等:
我们也可以让 health 显示更加详细的系统状态信息,这里我们开启一下配置:
1 2 3 4 5 6 7 management: ... endpoint: health: show-details: always env: show-values: always
现在就能查看当前系统占用相关信息了,比如下面的磁盘占用、数据库等信息:
包括完整的系统环境信息,比如我们配置的服务器 8080 端口:
我们只需要通过这些接口就能快速获取到当前应用程序的运行信息了。
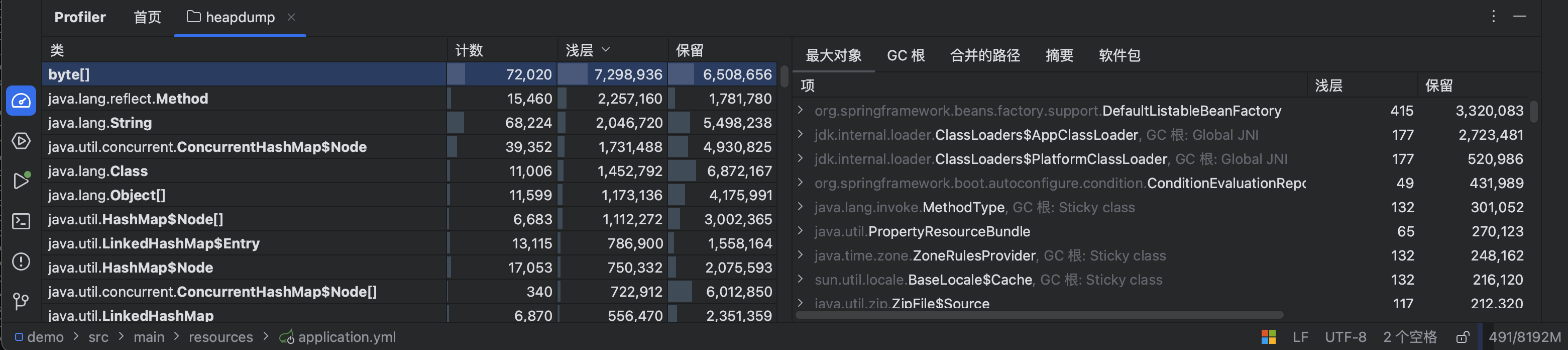
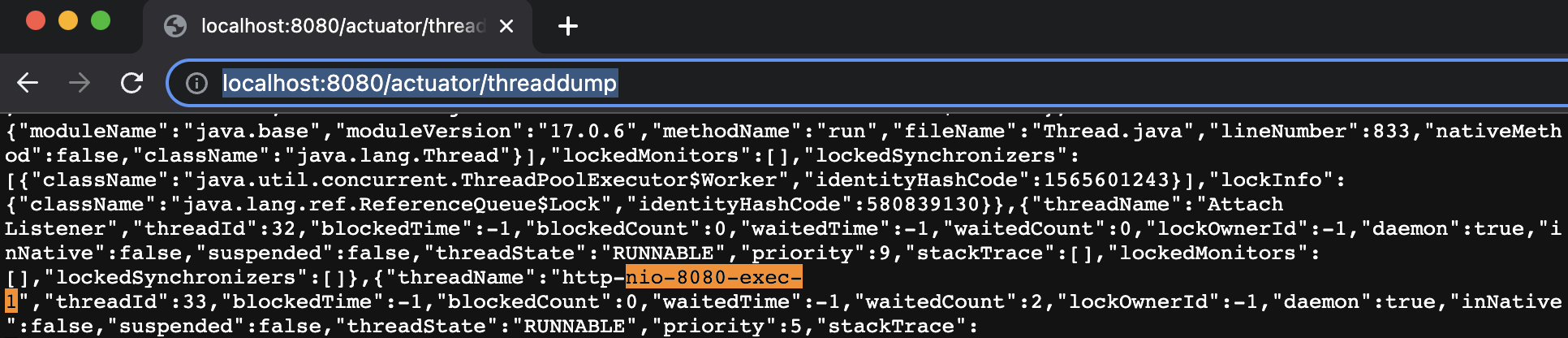
高级一点的还有线程转储和堆内存转储文件 直接生成,便于我们对 Java 程序的运行情况进行分析,这里我们获取一下堆内存转储文件:http://localhost:8080/actuator/heapdump ,文件下载之后直接使用 IDEA 就能打开:
可以看到其中创建的 byte 数组对象计数达到了 72020 个,其中我们自己的 TestController 对象只有有一个:
以及对应的线程转储信息,也可以通过 http://localhost:8080/actuator/threaddump 直接获取:
实现原理探究(选学) 注意:难度较大,本版块作为选学内容,在开始前,必须完成 SSM 阶段源码解析部分的学习。
我们在前面的学习中切实感受到了 SpringBoot 为我们带来的便捷,那么它为何能够实现如此快捷的开发模式,starter 又是一个怎样的存在,它是如何进行自动配置的,我们现在就开始研究。
启动原理与实现 首先我们来看看,SpringBoot 项目启动之后,做了什么事情,SpringApplication 中的静态 run 方法:
1 2 3 public static ConfigurableApplicationContext run (Class<?> primarySource, String... args) {return run(new Class []{primarySource}, args);
套娃如下:
1 2 3 public static ConfigurableApplicationContext run (Class<?>[] primarySources, String[] args) {return (new SpringApplication (primarySources)).run(args);
我们发现,这里直接 new 了一个新的 SpringApplication 对象,传入我们的主类作为构造方法参数,并调用了非 static 的 run 方法,我们先来看看构造方法里面做了什么事情:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 public SpringApplication (ResourceLoader resourceLoader, Class<?>... primarySources) {this .resourceLoader = resourceLoader;"PrimarySources must not be null" );this .primarySources = new LinkedHashSet (Arrays.asList(primarySources));this .webApplicationType = WebApplicationType.deduceFromClasspath();this .bootstrapRegistryInitializers = new ArrayList (this .getSpringFactoriesInstances(BootstrapRegistryInitializer.class));this .setInitializers(this .getSpringFactoriesInstances(ApplicationContextInitializer.class));this .setListeners(this .getSpringFactoriesInstances(ApplicationListener.class));this .mainApplicationClass = this .deduceMainApplicationClass();
1 2 3 4 5 6 7 8 9 10 11 12 13 14 static WebApplicationType deduceFromClasspath () {if (ClassUtils.isPresent(WEBFLUX_INDICATOR_CLASS, null ) && !ClassUtils.isPresent(WEBMVC_INDICATOR_CLASS, null )null )) {return WebApplicationType.REACTIVE; for (String className : SERVLET_INDICATOR_CLASSES) {if (!ClassUtils.isPresent(className, null )) {return WebApplicationType.NONE;return WebApplicationType.SERVLET;
通过阅读上面的源码,我们发现 getSpringFactoriesInstances 这个方法可以一次性获取指定类型已注册的实现类,我们先来研究一下它是怎么做到的。这里就要提到 spring.factories 文件了,它是 Spring 仿造 Java SPI 实现的一种类加载机制。它在 META-INF/spring.factories 文件中配置接口的实现类名称,然后在程序中读取这些配置文件并实例化。这种自定义的 SPI 机制是 Spring Boot Starter 实现的基础。
SPI 的常见例子:
数据库驱动加载接口实现类的加载:JDBC 加载不同类型数据库的驱动
日志门面接口实现类加载:SLF4J 加载不同提供商的日志实现类
说白了就是人家定义接口,但是实现可能有很多种,但是核心只提供接口,需要我们按需选择对应的实现,这种方式是高度解耦的。
我们可以来看看 spring-boot-starter 依赖中怎么定义的,其中有一个很关键的点:
1 2 3 4 5 6 <dependency > <groupId > org.springframework.boot</groupId > <artifactId > spring-boot-autoconfigure</artifactId > <version > 3.1.1</version > <scope > compile</scope > </dependency >
这个 spring-boot-autoconfigure 是什么东西?实际上这个就是我们整个依赖实现自动配置的关键。打开这个依赖内部,可以看到这里确实有一个 spring.factories 文件:
这个里面定义了很多接口的实现类,比如我们刚刚看到的 ApplicationContextInitializer 接口:
不仅仅是 spring-boot-starter 存在这样的文件,其他很多依赖,比如 spring-boot-start-test 也有着对应的 autoconfigure 模块,只不过大部分 SpringBoot 维护的组件,都默认将其中的 spring.factories 信息统一写到了 spring-boot-autoconfigure 和 spring-boot-starter 中,方便后续维护。
现在我们清楚,原来这些都是通过一个单独的文件定义的,所以我们来看看 getSpringFactoriesInstances 方法做了什么:
1 2 3 4 5 6 7 8 private <T> List<T> getSpringFactoriesInstances (Class<T> type) {return this .getSpringFactoriesInstances(type, (SpringFactoriesLoader.ArgumentResolver)null );private <T> List<T> getSpringFactoriesInstances (Class<T> type, SpringFactoriesLoader.ArgumentResolver argumentResolver) {return SpringFactoriesLoader.forDefaultResourceLocation(this .getClassLoader()).load(type, argumentResolver);
1 2 3 4 public static SpringFactoriesLoader forDefaultResourceLocation (@Nullable ClassLoader classLoader) {return forResourceLocation("META-INF/spring.factories" , classLoader);
所以 getSpringFactoriesInstances 其实就是通过读取所有 META-INF/spring.factories 文件得到的列表,然后实例化指定类型下读取到的所有实现类并返回,这样,我们就清楚 SpringBoot 这一大堆参与自动配置的类是怎么加载进来的了。
现在我们回到一开始的地方,目前 SpringApplication 对象已经构造好了,继续来看看 run 方法做了什么:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 public ConfigurableApplicationContext run (String... args) {long startTime = System.nanoTime();DefaultBootstrapContext bootstrapContext = this .createBootstrapContext();ConfigurableApplicationContext context = null ;this .configureHeadlessProperty();SpringApplicationRunListeners listeners = this .getRunListeners(args);this .mainApplicationClass);try {ApplicationArguments applicationArguments = new DefaultApplicationArguments (args);ConfigurableEnvironment environment = this .prepareEnvironment(listeners, bootstrapContext, applicationArguments);Banner printedBanner = this .printBanner(environment);this .createApplicationContext();this .applicationStartup);this .prepareContext(bootstrapContext, context, environment, listeners, applicationArguments, printedBanner);this .refreshContext(context);this .afterRefresh(context, applicationArguments);Duration timeTakenToStartup = Duration.ofNanos(System.nanoTime() - startTime);if (this .logStartupInfo) {new StartupInfoLogger (this .mainApplicationClass)).logStarted(this .getApplicationLog(), timeTakenToStartup);this .callRunners(context, applicationArguments);return context;
至此,SpringBoot 项目就正常启动了。
我们发现,即使是 SpringBoot,也是离不开 Spring 最核心的 ApplicationContext 容器,因为它再怎么也是一个 Spring 项目,即使玩得再高级不还是得围绕 IoC 容器来进行么。所以说,SSM 阶段学习的内容才是真正的核心,而 SpringBoot 仅仅是对 Spring 进行的一层强化封装,便于快速创建 Spring 项目罢了,这也是为什么一直强调不能跳过 SSM 先学 SpringBoot 的原因。
既然都谈到这里了,我们不妨再来看一下这里的 ApplicationContext 是怎么来的,打开 createApplicationContext 方法:
1 2 3 protected ConfigurableApplicationContext createApplicationContext () {return this .applicationContextFactory.create(this .webApplicationType);
我们发现在构造方法中 applicationContextFactory 直接使用的是 DEFAULT:
1 2 3 ...this .applicationContextFactory = ApplicationContextFactory.DEFAULT;
1 ApplicationContextFactory DEFAULT = new DefaultApplicationContextFactory ();
我们继续向下扒 DefaultApplicationContextFactory 的源码 create 方法部分:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 public ConfigurableApplicationContext create (WebApplicationType webApplicationType) {try {return (ConfigurableApplicationContext)this .getFromSpringFactories(webApplicationType, ApplicationContextFactory::create, this ::createDefaultApplicationContext); catch (Exception var3) {throw new IllegalStateException ("Unable create a default ApplicationContext instance, you may need a custom ApplicationContextFactory" , var3);private <T> T getFromSpringFactories (WebApplicationType webApplicationType, BiFunction<ApplicationContextFactory, WebApplicationType, T> action, Supplier<T> defaultResult) {for (ApplicationContextFactory candidate : SpringFactoriesLoader.loadFactories(ApplicationContextFactory.class,T result = action.apply(candidate, webApplicationType);if (result != null ) {return result; return (defaultResult != null ) ? defaultResult.get() : null ;
既然这里又是 SpringFactoriesLoader 加载 ApplicationContextFactory 实现,我们就直接去看有些啥:
我们也不出意外地在 spring.factories 中找到了这两个实现,因为目前是 Servlet 环境,所以在返回时得到最终的结果,也就是生成的 AnnotationConfigServletWebServerApplicationContext 对象,也就是说到这里为止,Spring 的容器就基本已经确定了,差不多可以开始运行了,下一个部分我们将继续介绍 SpringBoot 是如何实现自动扫描以及自动配置的。
自动配置原理 既然主类已经在初始阶段注册为 Bean,那么在加载时,就会根据注解定义,进行更多的额外操作。所以我们来看看主类上的 @SpringBootApplication 注解做了什么事情。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 @Target({ElementType.TYPE}) @Retention(RetentionPolicy.RUNTIME) @Documented @Inherited @SpringBootConfiguration @EnableAutoConfiguration @ComponentScan( excludeFilters = {@Filter( type = FilterType.CUSTOM, classes = {TypeExcludeFilter.class} ), @Filter( type = FilterType.CUSTOM, classes = {AutoConfigurationExcludeFilter.class} )} ) public @interface SpringBootApplication {
我们发现,@SpringBootApplication 上添加了 @ComponentScan 注解,此注解我们此前已经认识过了,但是这里并没有配置具体扫描的包,因此它会自动将声明此接口的类所在的包作为 basePackage,所以,当添加 @SpringBootApplication 之后也就等于直接开启了自动扫描,我们所有的配置都会自动加载,但是一定注意不能在主类之外的包进行 Bean 定义,否则无法扫描到,需要手动配置。
我们自己类路径下的配置、还有各种 Bean 定义如何读取的问题解决了,接着我们来看第二个注解 @EnableAutoConfiguration,它就是其他 Starter 自动配置的核心了,我们来看看它是如何定义的:
1 2 3 4 5 6 7 8 @Target({ElementType.TYPE}) @Retention(RetentionPolicy.RUNTIME) @Documented @Inherited @AutoConfigurationPackage @Import({AutoConfigurationImportSelector.class}) public @interface EnableAutoConfiguration {
这里就是 SSM 阶段我们认识的老套路了,直接一手 @Import,通过这种方式来将一些外部的类进行加载。我们来看看 AutoConfigurationImportSelector 做了什么事情:
1 2 3 public class AutoConfigurationImportSelector implements DeferredImportSelector , BeanClassLoaderAware, ResourceLoaderAware, BeanFactoryAware, EnvironmentAware, Ordered {
我们看到它实现了很多接口,包括大量的 Aware 接口,我们在 SSM 阶段也介绍过,实际上就是为了感知某些必要的对象,在加载时将其存到当前类中。
其中最核心的是 DeferredImportSelector 接口,它是 ImportSelector 的子类,它定义了 selectImports 方法,用于返回需要加载的类名称,在 Spring 加载 ImportSelector 时,会调用此方法来获取更多需要加载的类,并将这些类全部注册为 Bean:
1 2 3 4 5 6 7 8 public interface ImportSelector {@Nullable default Predicate<String> getExclusionFilter () {return null ;
到目前为止,我们了解了两种使用 @Import 有特殊机制的接口:ImportSelector(这里用到的)和 ImportBeanDefinitionRegistrar(之前 SSM 阶段源码有讲)当然还有普通的 @Configuration 配置类。
为了后续更好理解我们可以来阅读一下 ConfigurationClassPostProcessor 的源码,实际上这个后置处理器是 Spring 中提供的,这是专门用于处理配置类的后置处理器,其中 ImportBeanDefinitionRegistrar,还有这里的 ImportSelector 都是靠它来处理,不过当时 Spring 阶段没有深入讲解,我们来看看它到底是如何处理 @Import 的:
1 2 3 4 5 @Override public void postProcessBeanDefinitionRegistry (BeanDefinitionRegistry registry) {
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 public void processConfigBeanDefinitions (BeanDefinitionRegistry registry) {new ArrayList <>();for (String beanName : candidateNames) {BeanDefinition beanDef = registry.getBeanDefinition(beanName);if (beanDef.getAttribute(ConfigurationClassUtils.CONFIGURATION_CLASS_ATTRIBUTE) != null ) {else if (ConfigurationClassUtils.checkConfigurationClassCandidate(beanDef, this .metadataReaderFactory)) { new BeanDefinitionHolder (beanDef, beanName));if (configCandidates.isEmpty()) {return ;int i1 = ConfigurationClassUtils.getOrder(bd1.getBeanDefinition());int i2 = ConfigurationClassUtils.getOrder(bd2.getBeanDefinition());return Integer.compare(i1, i2);ConfigurationClassParser parser = new ConfigurationClassParser (this .metadataReaderFactory, this .problemReporter, this .environment,this .resourceLoader, this .componentScanBeanNameGenerator, registry);new LinkedHashSet <>(configCandidates);new HashSet <>(configCandidates.size());do {StartupStep processConfig = this .applicationStartup.start("spring.context.config-classes.parse" );new LinkedHashSet <>(parser.getConfigurationClasses());this .reader.loadBeanDefinitions(configClasses);while (!candidates.isEmpty());
我们就接着来看,ConfigurationClassParser 是如何进行解析的,直接进入 parse 方法的关键部分:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 protected void processConfigurationClass (ConfigurationClass configClass, Predicate<String> filter) throws IOException {if (!this .conditionEvaluator.shouldSkip(configClass.getMetadata(), ConfigurationPhase.PARSE_CONFIGURATION)) {SourceClass sourceClass = this .asSourceClass(configClass, filter);do {this .doProcessConfigurationClass(configClass, sourceClass, filter);while (sourceClass != null );this .configurationClasses.put(configClass, configClass);
最后我们再来看最核心的 doProcessConfigurationClass 方法:
1 2 3 4 5 6 protected final SourceClass doProcessConfigurationClass (ConfigurationClass configClass, SourceClass sourceClass) true ); return null ;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 private void processImports (ConfigurationClass configClass, SourceClass currentSourceClass, Collection<SourceClass> importCandidates, Predicate<String> exclusionFilter, boolean checkForCircularImports) {if (checkForCircularImports && isChainedImportOnStack(configClass)) {this .problemReporter.error(new CircularImportProblem (configClass, this .importStack));else {this .importStack.push(configClass);try {for (SourceClass candidate : importCandidates) {if (candidate.isAssignable(ImportSelector.class)) {ImportSelector selector = ParserStrategyUtils.instantiateClass(candidateClass, ImportSelector.class, this .environment, this .resourceLoader, this .registry);if (selector instanceof DeferredImportSelector deferredImportSelector) {this .deferredImportSelectorHandler.handle(configClass, deferredImportSelector);else {false );else if (candidate.isAssignable(ImportBeanDefinitionRegistrar.class)) {ImportBeanDefinitionRegistrar registrar = this .environment, this .resourceLoader, this .registry);else {this .importStack.registerImport(
不难注意到,虽然这里特别处理了 ImportSelector 对象,但是还针对 ImportSelector 的子接口 DeferredImportSelector 进行了额外处理,Deferred 是延迟的意思,它是一个延迟执行的 ImportSelector,并不会立即进处理,而是丢进 DeferredImportSelectorHandler,并且在我们上面提到的 parse 方法的最后进行处理:
1 2 3 4 public void parse (Set<BeanDefinitionHolder> configCandidates) {this .deferredImportSelectorHandler.process();
我们接着来看 DeferredImportSelector 正好就有一个 process 方法:
1 2 3 4 5 6 7 8 9 10 11 12 13 ublic interface DeferredImportSelector extends ImportSelector {@Nullable default Class<? extends DeferredImportSelector .Group> getImportGroup() {return null ;public interface Group {void process (AnnotationMetadata metadata, DeferredImportSelector selector) ;public static class Entry {
最后经过 ConfigurationClassParser 处理完成后,通过 parser.getConfigurationClasses() 就能得到通过配置类导入那些额外的配置类或是特殊的类。最后将这些配置类全部注册 BeanDefinition,然后就可以交给接下来的 Bean 初始化过程去处理了:
1 this .reader.loadBeanDefinitions(configClasses);
最后我们再去看 loadBeanDefinitions 是如何运行的:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 public void loadBeanDefinitions (Set<ConfigurationClass> configurationModel) {TrackedConditionEvaluator trackedConditionEvaluator = new ConfigurationClassBeanDefinitionReader .TrackedConditionEvaluator();Iterator var3 = configurationModel.iterator();while (var3.hasNext()) {ConfigurationClass configClass = (ConfigurationClass)var3.next();this .loadBeanDefinitionsForConfigurationClass(configClass, trackedConditionEvaluator);private void loadBeanDefinitionsForConfigurationClass (ConfigurationClass configClass, ConfigurationClassBeanDefinitionReader.TrackedConditionEvaluator trackedConditionEvaluator) {if (trackedConditionEvaluator.shouldSkip(configClass)) {else {if (configClass.isImported()) {this .registerBeanDefinitionForImportedConfigurationClass(configClass); Iterator var3 = configClass.getBeanMethods().iterator();while (var3.hasNext()) {BeanMethod beanMethod = (BeanMethod)var3.next();this .loadBeanDefinitionsForBeanMethod(beanMethod); this .loadBeanDefinitionsFromImportedResources(configClass.getImportedResources());this .loadBeanDefinitionsFromRegistrars(configClass.getImportBeanDefinitionRegistrars());
这样,整个 @Configuration 配置类的底层配置流程我们就大致了解了。接着我们来看 AutoConfigurationImportSelector 是如何实现自动配置的,可以看到内部类 AutoConfigurationGroup 的 process 方法,它是父接口的实现,因为父接口是 DeferredImportSelector,根据前面的推导,很容易得知,实际上最后会调用 process 方法获取所有的自动配置类:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 public void process (AnnotationMetadata annotationMetadata, DeferredImportSelector deferredImportSelector) {instanceof AutoConfigurationImportSelector, () -> {return String.format("Only %s implementations are supported, got %s" , AutoConfigurationImportSelector.class.getSimpleName(), deferredImportSelector.getClass().getName());AutoConfigurationEntry autoConfigurationEntry = ((AutoConfigurationImportSelector)deferredImportSelector).getAutoConfigurationEntry(annotationMetadata);this .autoConfigurationEntries.add(autoConfigurationEntry);Iterator var4 = autoConfigurationEntry.getConfigurations().iterator();while (var4.hasNext()) {String importClassName = (String)var4.next();this .entries.putIfAbsent(importClassName, annotationMetadata);
我们接着来看 getAutoConfigurationEntry 方法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 protected AutoConfigurationImportSelector.AutoConfigurationEntry getAutoConfigurationEntry (AnnotationMetadata annotationMetadata) {if (!this .isEnabled(annotationMetadata)) {return EMPTY_ENTRY;else {AnnotationAttributes attributes = this .getAttributes(annotationMetadata);this .getCandidateConfigurations(annotationMetadata, attributes);return new AutoConfigurationEntry (configurations, exclusions);
我们接着往里面看:
1 2 3 4 5 protected List<String> getCandidateConfigurations (AnnotationMetadata metadata, AnnotationAttributes attributes) {this .getBeanClassLoader()).getCandidates();
到这里终于找到了:
1 2 3 4 5 6 7 public static ImportCandidates load (Class<?> annotation, ClassLoader classLoader) {"'annotation' must not be null" );ClassLoader classLoaderToUse = decideClassloader(classLoader);String location = String.format("META-INF/spring/%s.imports" , annotation.getName());
我们可以直接找到:
可以看到有很多自动配置类,实际上 SpringBoot 的 starter 都是依靠自动配置类来实现自动配置的,我们可以随便看一个,比如用于自动配置 Mybatis 框架的 MybatisAutoConfiguration 自动配置类:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 @Configuration @ConditionalOnClass({SqlSessionFactory.class, SqlSessionFactoryBean.class}) @ConditionalOnSingleCandidate(DataSource.class) @EnableConfigurationProperties({MybatisProperties.class}) @AutoConfigureAfter({DataSourceAutoConfiguration.class, MybatisLanguageDriverAutoConfiguration.class}) public class MybatisAutoConfiguration implements InitializingBean {@Bean @ConditionalOnMissingBean public SqlSessionFactory sqlSessionFactory (DataSource dataSource) throws Exception {@Bean @ConditionalOnMissingBean public SqlSessionTemplate sqlSessionTemplate (SqlSessionFactory sqlSessionFactory) {
可以看到里面直接将 SqlSessionFactory 和 SqlSessionTemplate 注册为 Bean 了,由于这个自动配置类在上面的一套流程中已经加载了,这样就不需要我们手动进行注册这些 Bean 了。不过这里有一个非常有意思的 @Conditional 注解,它可以根据条件来判断是否注册这个 Bean,比如 @ConditionalOnMissingBean 注解就是当这个 Bean 不存在的时候,才会注册,如果这个 Bean 已经被其他配置类给注册了,那么这里就不进行注册。
经过这一套流程,简而言之就是 SpringBoot 读取 META-INF/spring/org.springframework.boot.autoconfigure.AutoConfiguration.imports 文件来确定要加载哪些自动配置类来实现的全自动化,真正做到添加依赖就能够直接完成配置和运行,至此,SpringBoot 的原理部分就探究完毕了。
自定义 Starter 项目 我们仿照 Mybatis 来编写一个自己的 starter,Mybatis 的 starter 包含两个部分:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 <project xmlns ="http://maven.apache.org/POM/4.0.0" xmlns:xsi ="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation ="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd" > <modelVersion > 4.0.0</modelVersion > <parent > <groupId > org.mybatis.spring.boot</groupId > <artifactId > mybatis-spring-boot</artifactId > <version > 2.2.0</version > </parent > <artifactId > mybatis-spring-boot-starter</artifactId > <name > mybatis-spring-boot-starter</name > <properties > <module.name > org.mybatis.spring.boot.starter</module.name > </properties > <dependencies > <dependency > <groupId > org.springframework.boot</groupId > <artifactId > spring-boot-starter</artifactId > </dependency > <dependency > <groupId > org.springframework.boot</groupId > <artifactId > spring-boot-starter-jdbc</artifactId > </dependency > <dependency > <groupId > org.mybatis.spring.boot</groupId > <artifactId > mybatis-spring-boot-autoconfigure</artifactId > </dependency > <dependency > <groupId > org.mybatis</groupId > <artifactId > mybatis</artifactId > </dependency > <dependency > <groupId > org.mybatis</groupId > <artifactId > mybatis-spring</artifactId > </dependency > </dependencies > </project >
因此我们也将我们自己的 starter 这样设计,我们设计三个模块:
spring-boot-hello:基础业务功能模块
spring-boot-starter-hello:启动器
spring-boot-autoconifgurer-hello:自动配置依赖
首先是基础业务功能模块,这里我们随便创建一个类就可以了:
1 2 3 4 5 public class HelloWorldService {public void test () {"Hello World!" );
启动器主要做依赖管理,这里就不写任何代码,只写 pom 文件:
1 2 3 4 5 6 7 8 9 10 11 <dependency > <groupId > org.example</groupId > <artifactId > spring-boot-autoconifgurer-hello</artifactId > <version > 0.0.1-SNAPSHOT</version > </dependency > <dependency > <groupId > org.example</groupId > <artifactId > spring-boot-hello</artifactId > <version > 0.0.1-SNAPSHOT</version > </dependency >
导入 autoconfigurer 模块作为依赖即可,接着我们去编写 autoconfigurer 模块,首先导入依赖:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 <dependencies > <dependency > <groupId > org.springframework.boot</groupId > <artifactId > spring-boot-autoconfigure</artifactId > </dependency > <dependency > <groupId > org.springframework.boot</groupId > <artifactId > spring-boot-configuration-processor</artifactId > <optional > true</optional > </dependency > <dependency > <groupId > org.example</groupId > <artifactId > spring-boot-hello</artifactId > <version > 0.0.1-SNAPSHOT</version > </dependency > </dependencies >
接着创建一个 HelloWorldAutoConfiguration 作为自动配置类:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 @Configuration(proxyBeanMethods = false) @ConditionalOnWebApplication @EnableConfigurationProperties(HelloWorldProperties.class) public class HelloWorldAutoConfiguration {Logger logger = Logger.getLogger(this .getClass().getName());@Autowired @Bean @ConditionalOnMissingBean public HelloWorldService helloWorldService () {"自定义 starter 项目已启动!" );"读取到自定义配置:" +properties.getValue());return new HelloWorldService ();
对应的配置读取类:
1 2 3 4 5 6 7 8 9 10 11 12 13 @ConfigurationProperties("hello.world") public class HelloWorldProperties {private String value;public void setValue (String value) {this .value = value;public String getValue () {return value;
接着再编写 META-INF/spring/org.springframework.boot.autoconfigure.AutoConfiguration.imports 文件,并将我们的自动配置类添加即可:
1 com.test.autoconfigure.HelloWorldAutoConfiguration
最后再 Maven 根项目执行 install 安装到本地仓库,完成。接着就可以在其他项目中使用我们编写的自定义 starter 了。
1 2 3 4 5 url: https://zhuanlan.zhihu.com/p/425864811
深入 SpringBoot 数据交互 本章我们将深入讲解 SpringBoot 的数据交互,使用更多方便好用的持久层框架。
JDBC 交互框架 除了我们前面一直认识的 Mybatis 之外,实际上 Spring 官方也提供了一个非常方便的 JDBC 操作工具,它同样可以快速进行增删改查。首先我们还是通过 starter 将依赖导入:
1 2 3 4 <dependency > <groupId > org.springframework.boot</groupId > <artifactId > spring-boot-starter-jdbc</artifactId > </dependency >
导入完成之后就可以轻松使用了。
JDBC 模版类 Spring JDBC 为我们提供了一个非常方便的 JdbcTemplate 类,它封装了常用的 JDBC 操作,我们可以快速使用这些方法来实现增删改查,这里我们还是配置一下 MySQL 数据源信息:
1 2 3 4 <dependency > <groupId > com.mysql</groupId > <artifactId > mysql-connector-j</artifactId > </dependency >
1 2 3 4 5 6 spring: datasource: url: jdbc:mysql://localhost:3306/test username: root password: 123456 driver-class-name: com.mysql.cj.jdbc.Driver
我们要操作数据库,最简单直接的方法就是使用 JdbcTemplate 来完成:
1 2 @Resource
它给我们封装了很多方法使用,比如我们要查询数据库中的一条记录:
我们可以使用 queryForMap 快速以 Map 为结果的形式查询一行数据:
1 2 3 4 5 @Test void contextLoads () {"select * from user where id = ?" , 1 );
非常方便:
我们也可以编写自定义的 Mapper 用于直接得到查询结果:
1 2 3 4 5 6 7 8 @Data @AllArgsConstructor public class User {int id;
1 2 3 4 5 6 @Test void contextLoads () {User user = template.queryForObject("select * from user where id = ?" ,new User (r.getInt(1 ), r.getString(2 ), r.getString(3 ), r.getString(4 )), 1 );
当然除了这些之外,它还提供了 update 方法适用于各种情况的查询、更新、删除操作:
1 2 3 4 5 @Test void contextLoads () {int update = template.update("insert into user values(2, 'admin', ' 654321@qq.com ', '123456')" );"更新了 " +update+" 行" );
这样,如果是那种非常小型的项目,甚至是测试用例的话,都可以快速使用 JdbcTemplate 快速进行各种操作。
JDBC 简单封装 对于一些插入操作,Spring JDBC 为我们提供了更方便的 SimpleJdbcInsert 工具,它可以实现更多高级的插入功能,比如我们的表主键采用的是自增 ID,那么它支持插入后返回自动生成的 ID,这就非常方便了:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 @Configuration public class WebConfiguration {@Resource @Test void contextLoads () {SimpleJdbcInsert simple = new SimpleJdbcInsert (source)"user" ) "id" ); new HashMap <>(2 ); "name" , "bob" );"email" , " 112233@qq.com " );"password" , "123456" );Number number = simple.executeAndReturnKey(user);
这样就可以快速进行插入操作并且返回自增主键了,还是挺方便的。
当然,虽然 SpringJDBC 给我们提供了这些小工具,但是其实只适用于简单小项目,稍微复杂一点就不太适合了
JPA 框架
用了 Mybatis 之后,你看那个 JDBC,真是太逊了。
这么说,你的项目很勇哦?
开玩笑,我的写代码超勇的好不好。
阿伟,你可曾幻想过有一天你的项目里不再有 SQL 语句?
不再有 SQL 语句?那我怎么和数据库交互啊?
我看你是完全不懂哦
懂,懂什么啊?
你想懂?来,到我项目里来,我给你看点好康的。
好康?是什么新框架哦?
什么新框架,比新框架还刺激,还可以让你的项目登 duang 郎哦。
在我们之前编写的项目中,我们不难发现,实际上大部分的数据库交互操作,到最后都只会做一个事情,那就是把数据库中的数据映射为 Java 中的对象。比如我们要通过用户名去查找对应的用户,或是通过 ID 查找对应的学生信息,在使用 Mybatis 时,我们只需要编写正确的 SQL 语句就可以直接将获取的数据映射为对应的 Java 对象,通过调用 Mapper 中的方法就能直接获得实体类,这样就方便我们在 Java 中数据库表中的相关信息了。
但是以上这些操作都有一个共性,那就是它们都是通过某种条件去进行查询,而最后的查询结果,都是一个实体类,所以你会发现你写的很多 SQL 语句都是一个套路 select * from xxx where xxx=xxx,实际上对于这种简单 SQL 语句,我们完全可以弄成一个模版来使用,那么能否有一种框架,帮我们把这些相同的套路给封装起来,直接把这类相似的 SQL 语句给屏蔽掉,不再由我们编写,而是让框架自己去组合拼接。
认识 SpringData JPA 首先我们来看一个国外的统计:
不对吧,为什么 Mybatis 这么好用,这么强大,却只有 10%的人喜欢呢?然而事实就是,在国外 JPA 几乎占据了主导地位,而 Mybatis 并不像国内那样受待见,所以你会发现,JPA 都有 SpringBoot 的官方直接提供的 starter,而 Mybatis 没有,直到 SpringBoot 3 才开始加入到官方模版中。
那么,什么是 JPA?
JPA(Java Persistence API)和 JDBC 类似,也是官方定义的一组接口,但是它相比传统的 JDBC,它是为了实现 ORM 而生的,即 Object-Relationl Mapping,它的作用是在关系型数据库和对象之间形成一个映射,这样,我们在具体的操作数据库的时候,就不需要再去和复杂的 SQL 语句打交道,只要像平时操作对象一样操作它就可以了。
其中比较常见的 JPA 实现有:
Hibernate:Hibernate 是 JPA 规范的一个具体实现,也是目前使用最广泛的 JPA 实现框架之一。它提供了强大的对象关系映射功能,可以将 Java 对象映射到数据库表中,并提供了丰富的查询语言和缓存机制。
EclipseLink:EclipseLink 是另一个流行的 JPA 实现框架,由 Eclipse 基金会开发和维护。它提供了丰富的特性,如对象关系映射、缓存、查询语言和连接池管理等,并具有较高的性能和可扩展性。
OpenJPA:OpenJPA 是 Apache 基金会的一个开源项目,也是 JPA 规范的一个实现。它提供了高性能的 JPA 实现和丰富的特性,如延迟加载、缓存和分布式事务等。
TopLink:TopLink 是 Oracle 公司开发的一个对象关系映射框架,也是 JPA 规范的一个实现。虽然 EclipseLink 已经取代了 TopLink 成为 Oracle 推荐的 JPA 实现,但 TopLink 仍然得到广泛使用。
在之前,我们使用 JDBC 或是 Mybatis 来操作数据,通过直接编写对应的 SQL 语句来实现数据访问,但是我们发现实际上我们在 Java 中大部分操作数据库的情况都是读取数据并封装为一个实体类,因此,为什么不直接将实体类直接对应到一个数据库表呢?也就是说,一张表里面有什么属性,那么我们的对象就有什么属性,所有属性跟数据库里面的字段一一对应,而读取数据时,只需要读取一行的数据并封装为我们定义好的实体类既可以,而具体的 SQL 语句执行,完全可以交给框架根据我们定义的映射关系去生成,不再由我们去编写,因为这些 SQL 实际上都是千篇一律的。
而实现 JPA 规范的框架一般最常用的就是 Hibernate,它是一个重量级框架,学习难度相比 Mybatis 也更高一些,而 SpringDataJPA 也是采用 Hibernate 框架作为底层实现,并对其加以封装。
官网: https://spring.io/projects/spring-data-jpa
使用 JPA 快速上手 同样的,我们只需要导入 stater 依赖即可:
1 2 3 4 <dependency > <groupId > org.springframework.boot</groupId > <artifactId > spring-boot-starter-data-jpa</artifactId > </dependency >
接着我们可以直接创建一个类,比如用户类,我们只需要把一个账号对应的属性全部定义好即可:
1 2 3 4 5 6 @Data public class Account {int id;
接着,我们可以通过注解形式,在属性上添加数据库映射关系,这样就能够让 JPA 知道我们的实体类对应的数据库表长啥样,这里用到了很多注解:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 @Data @Entity @Table(name = "account") public class Account {@GeneratedValue(strategy = GenerationType.IDENTITY) @Column(name = "id") @Id int id;@Column(name = "username") @Column(name = "password")
接着我们来修改一下配置文件,把日志打印给打开:
1 2 3 4 5 6 7 spring: jpa: show-sql: true hibernate: ddl-auto: update
ddl-auto 属性用于设置自动表定义,可以实现自动在数据库中为我们创建一个表,表的结构会根据我们定义的实体类决定,它有以下几种:
none: 不执行任何操作,数据库表结构需要手动创建。create: 框架在每次运行时都会删除所有表,并重新创建。create-drop: 框架在每次运行时都会删除所有表,然后再创建,但在程序结束时会再次删除所有表。update: 框架会检查数据库表结构,如果与实体类定义不匹配,则会做相应的修改,以保持它们的一致性。validate: 框架会检查数据库表结构与实体类定义是否匹配,如果不匹配,则会抛出异常。
这个配置项的作用是为了避免手动管理数据库表结构,使开发者可以更方便地进行开发和测试,但在生产环境中,更推荐使用数据库迁移工具来管理表结构的变更。
我们可以在日志中发现,在启动时执行了如下 SQL 语句:
我们的数据库中对应的表已经自动创建好了。
我们接着来看如何访问我们的表,我们需要创建一个 Repository 实现类:
1 2 3 @Repository public interface AccountRepository extends JpaRepository <Account, Integer> {
注意 JpaRepository 有两个泛型,前者是具体操作的对象实体,也就是对应的表,后者是 ID 的类型,接口中已经定义了比较常用的数据库操作。编写接口继承即可,我们可以直接注入此接口获得实现类:
1 2 3 4 5 6 7 8 9 10 @Resource @Test void contextLoads () {Account account = new Account ();"小红" );"1234567" );
执行结果如下:
同时,查询操作也很方便:
1 2 3 4 5 @Test void contextLoads () {1 ).ifPresent(System.out::println);
得到结果为:
包括常见的一些计数、删除操作等都包含在里面,仅仅配置应该接口就能完美实现增删改查:
我们发现,使用了 JPA 之后,整个项目的代码中没有出现任何的 SQL 语句,可以说是非常方便了,JPA 依靠我们提供的注解信息自动完成了所有信息的映射和关联。
相比 Mybatis,JPA 几乎就是一个全自动的 ORM 框架,而 Mybatis 则顶多算是半自动 ORM 框架。
方法名称拼接自定义 SQL 虽然接口预置的方法使用起来非常方便,但是如果我们需要进行条件查询等操作或是一些判断 ,就需要自定义一些方法来实现,同样的,我们不需要编写 SQL 语句,而是通过方法名称的拼接来实现条件判断,这里列出了所有支持的条件判断名称:
属性
拼接方法名称示例
执行的语句
Distinct
findDistinctByLastnameAndFirstname
select distinct … where x.lastname = ?1 and x.firstname = ?2
And
findByLastnameAndFirstname
… where x.lastname = ?1 and x.firstname = ?2
Or
findByLastnameOrFirstname
… where x.lastname = ?1 or x.firstname = ?2
Is,Equals
findByFirstname , findByFirstnameIs , findByFirstnameEquals
… where x.firstname = ?1
Between
findByStartDateBetween
… where x.startDate between ?1 and ?2
LessThan
findByAgeLessThan
… where x.age < ?1
LessThanEqual
findByAgeLessThanEqual
… where x.age <= ?1
GreaterThan
findByAgeGreaterThan
… where x.age > ?1
GreaterThanEqual
findByAgeGreaterThanEqual
… where x.age >= ?1
After
findByStartDateAfter
… where x.startDate > ?1
Before
findByStartDateBefore
… where x.startDate < ?1
IsNull,Null
findByAge(Is)Null
… where x.age is null
IsNotNull,NotNull
findByAge(Is)NotNull
… where x.age not null
Like
findByFirstnameLike
… where x.firstname like ?1
NotLike
findByFirstnameNotLike
… where x.firstname not like ?1
StartingWith
findByFirstnameStartingWith
… where x.firstname like ?1(参数与附加 % 绑定)
Containing
findByFirstnameContaining
… where x.firstname like ?1(参数绑定以 % 包装)
OrderBy
findByAgeOrderByLastnameDesc
… where x.age = ?1 order by x.lastname desc
Not
findByLastnameNot
… where x.lastname <> ?1
NotIn
findByAgeNotIn(Collection<Age> ages)
… where x.age not in ?1
True
findByActiveTrue
… where x.active = true
False
findByActiveFalse
… where x.active = false
IgnoreCase
findByFirstnameIgnoreCase
… where UPPER(x.firstname) = UPPER(?1)
In
findByAgeIn(Collection<Age> ages)
… where x.age in ?1
比如我们想要实现根据用户名模糊匹配查找用户:
1 2 3 4 5 @Repository public interface AccountRepository extends JpaRepository <Account, Integer> {findAllByUsernameLike (String str) ;
我们来测试一下:
1 2 3 4 @Test void contextLoads () {"%明%" ).forEach(System.out::println);
又比如我们想同时根据用户名和 ID 一起查询:
1 2 3 4 5 6 7 @Repository public interface AccountRepository extends JpaRepository <Account, Integer> {findAllByUsernameLike (String str) ;findByIdAndUsername (int id, String username) ;
1 2 3 4 @Test void contextLoads () {1 , "小明" ));
比如我们想判断数据库中是否存在某个 ID 的用户:
1 2 3 4 5 6 7 @Repository public interface AccountRepository extends JpaRepository <Account, Integer> {findAllByUsernameLike (String str) ;findByIdAndUsername (int id, String username) ;boolean existsAccountById (int id) ;
注意自定义条件操作的方法名称一定要遵循规则,不然会出现异常:
1 Caused by: org.springframework.data.repository.query.QueryCreationException: Could not create query for public abstract ...
有了这些操作,我们在编写一些简单 SQL 的时候就很方便了,用久了甚至直接忘记 SQL 怎么写。
JPA 可以通过条件属性 进行拼接 以实现复杂的逻辑功能。
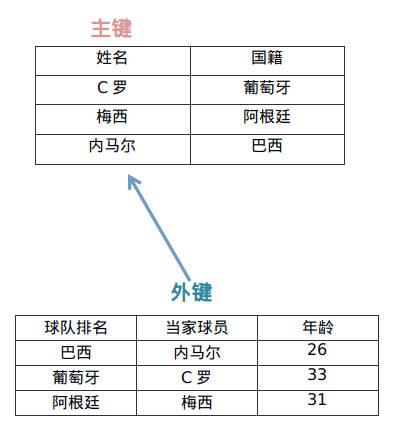
关联查询 在实际开发中,比较常见的场景还有关联查询,也就是我们会在表中添加一个外键字段,而此外键字段又指向了另一个表中的数据,当我们查询数据时,可能会需要将关联数据也一并获取,比如我们想要查询某个用户的详细信息,一般用户简略信息会单独存放一个表,而用户详细信息会单独存放在另一个表中。当然,除了用户详细信息之外,可能在某些电商平台还会有用户的购买记录、用户的购物车,交流社区中的用户帖子、用户评论等,这些都是需要根据用户信息进行关联查询的内容。
我们知道,在 JPA 中,每张表实际上就是一个实体类的映射,而表之间的关联关系,也可以看作对象之间的依赖关系,比如用户表中包含了用户详细信息的 ID 字段作为外键,那么实际上就是用户表实体中包括了用户详细信息实体对象:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 @Data @Entity @Table(name = "users_detail") public class AccountDetail {@Column(name = "id") @GeneratedValue(strategy = GenerationType.IDENTITY) @Id int id;@Column(name = "address") @Column(name = "email") @Column(name = "phone") @Column(name = "real_name")
而用户信息和用户详细信息之间形成了一对一的关系,那么这时我们就可以直接在类中指定这种关系:
一对一 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 @Data @Entity @Table(name = "users") public class Account {@GeneratedValue(strategy = GenerationType.IDENTITY) @Column(name = "id") @Id int id;@Column(name = "username") @Column(name = "password") @JoinColumn(name = "detail_id") @OneToOne
在修改实体类信息后,我们发现在启动时也进行了更新,日志如下:
1 2 3 Hibernate: alter table users add column detail_id integer create table users_detail (id integer not null auto_increment, address varchar (255 ), email varchar (255 ), phone varchar (255 ), real_name varchar (255 ), primary key (id)) engine= InnoDBalter table users add constraint FK7gb021edkxf3mdv5bs75ni6jd foreign key (detail_id) references users_detail (id)
是不是感觉非常方便!都懒得去手动改表结构了。
接着我们往用户详细信息中添加一些数据,一会我们可以直接进行查询:
1 2 3 4 @Test void pageAccount () {1 ).ifPresent(System.out::println);
查询后,可以发现,得到如下结果:
1 2 Hibernate: select account0_.id as id1_0_0_, account0_.detail_id as detail_i4_0_0_, account0_.password as password2_0_0_, account0_.username as username3_0_0_, accountdet1_.id as id1_1_1_, accountdet1_.address as address2_1_1_, accountdet1_.email as email3_1_1_, accountdet1_.phone as phone4_1_1_, accountdet1_.real_name as real_nam5_1_1_ from users account0_ left outer join users_detail accountdet1_ on account0_.detail_id =accountdet1_.id where account0_.id =?id =1, username =Test, password =123456, detail =AccountDetail(id=1, address =四川省成都市青羊区, email= 8371289@qq.com , phone =1234567890, realName =本伟))
也就是,在建立关系之后,我们查询 Account 对象时,会自动将关联数据的结果也一并进行查询。
那要是我们只想要 Account 的数据,不想要用户详细信息数据怎么办呢?我希望在我要用的时候再获取详细信息,这样可以节省一些网络开销,我们可以设置懒加载,这样只有在需要时才会向数据库获取:
懒加载外键信息:
1 2 3 @JoinColumn(name = "detail_id") @OneToOne(fetch = FetchType.LAZY)
接着我们测试一下:
1 2 3 4 5 6 7 8 @Transactional @Test void pageAccount () {1 ).ifPresent(account -> {
接着我们来看看控制台输出了什么:
1 2 3 4 Hibernate: select account0_.id as id1_0_0_, account0_.detail_id as detail_i4_0_0_, account0_.password as password2_0_0_, account0_.username as username3_0_0_ from users account0_ where account0_.id =?id as id1_1_0_, accountdet0_.address as address2_1_0_, accountdet0_.email as email3_1_0_, accountdet0_.phone as phone4_1_0_, accountdet0_.real_name as real_nam5_1_0_ from users_detail accountdet0_ where accountdet0_.id =?id =1 , address=四川省成都市青羊区, email= 8371289 @qq.com , phone=1234567890 , realName=卢本)
可以看到,获取用户名之前,并没有去查询用户的详细信息,而是当我们获取详细信息时才进行查询并返回 AccountDetail 对象。
那么我们是否也可以在添加数据时,利用实体类之间的关联信息,一次性添加两张表的数据呢?可以,但是我们需要稍微修改一下级联关联操作设定:
关联操作:
1 2 3 @JoinColumn(name = "detail_id") @OneToOne(fetch = FetchType.LAZY, cascade = CascadeType.ALL)
ALL:所有操作都进行关联操作PERSIST:插入操作时才进行关联操作REMOVE:删除操作时才进行关联操作MERGE:修改操作时才进行关联操作
可以多个并存,接着我们来进行一下测试:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 @Test void addAccount () {Account account = new Account ();"Nike" );"123456" );AccountDetail detail = new AccountDetail ();"重庆市渝中区解放碑" );"1234567890" );" 73281937@qq.com " );"张三" );"插入时,自动生成的主键 ID 为:" +account.getId()+",外键 ID 为:" +account.getDetail().getId());
可以看到日志结果:
1 2 3 Hibernate : insert into users_detail (address, email, phone, real_name) values (?, ?, ?, ?) Hibernate : insert into users (detail_id, password, username) values (?, ?, ?) ID 为:6 ,外键 ID 为:3
结束后会发现数据库中两张表都同时存在数据。
接着我们来看一对多关联,比如每个用户的成绩信息:
一对多 1 2 3 @JoinColumn(name = "uid") @OneToMany(fetch = FetchType.LAZY, cascade = CascadeType.REMOVE)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 @Data @Entity @Table(name = "users_score") public class Score {@GeneratedValue(strategy = GenerationType.IDENTITY) @Column(name = "id") @Id int id;@OneToOne @JoinColumn(name = "cid") @Column(name = "socre") double score;@Column(name = "uid") int uid;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 @Data @Entity @Table(name = "subjects") public class Subject {@GeneratedValue(strategy = GenerationType.IDENTITY) @Column(name = "cid") @Id int cid;@Column(name = "name") @Column(name = "teacher") @Column(name = "time") int time;
在数据库中填写相应数据,接着我们就可以查询用户的成绩信息了:
1 2 3 4 5 6 7 @Transactional @Test void test () {1 ).ifPresent(account -> {
成功得到用户所有的成绩信息,包括得分和学科信息。
同样的,我们还可以将对应成绩中的教师信息单独分出一张表存储,并建立多对一的关系,因为多门课程可能由同一个老师教授(千万别搞晕了,一定要理清楚关联关系,同时也是考验你的基础扎不扎实):
多对一 1 2 3 @ManyToOne(fetch = FetchType.LAZY) @JoinColumn(name = "tid")
接着就是教师实体类了:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 @Data @Entity @Table(name = "teachers") public class Teacher {@Column(name = "id") @GeneratedValue(strategy = GenerationType.IDENTITY) @Id int id;@Column(name = "name") @Column(name = "sex")
最后我们再进行一下测试:
1 2 3 4 5 6 7 8 9 10 11 @Transactional @Test void test () {3 ).ifPresent(account -> {"课程名称:" +score.getSubject().getName());"得分:" +score.getScore());"任课教师:" +score.getSubject().getTeacher().getName());
成功得到多对一的教师信息。
最后我们再来看最复杂的情况,现在我们一门课程可以由多个老师教授,而一个老师也可以教授多个课程,那么这种情况就是很明显的多对多场景,现在又该如何定义呢?我们可以像之前一样,插入一张中间表表示教授关系,这个表中专门存储哪个老师教哪个科目:
多对多 1 2 3 4 5 6 @ManyToMany(fetch = FetchType.LAZY) @JoinTable(name = "teach_relation", //多对多中间关联表 joinColumns = @JoinColumn(name = "cid"), //当前实体主键在关联表中的字段名称 inverseJoinColumns = @JoinColumn(name = "tid") //教师实体主键在关联表中的字段名称 )
接着,JPA 会自动创建一张中间表,并自动设置外键,我们就可以将多对多关联信息编写在其中了。
通过关联表和关联键注解 来实现一对一、一对多、多对一和多对多 的多表关联关系
JPQL 自定义 SQL 语句 虽然 SpringDataJPA 能够简化大部分数据获取场景,但是难免会有一些特殊的场景,需要使用复杂查询才能够去完成,这时你又会发现,如果要实现,只能用回 Mybatis 了,因为我们需要自己手动编写 SQL 语句,过度依赖 SpringDataJPA 会使得 SQL 语句不可控。
使用 JPA,我们也可以像 Mybatis 那样,直接编写 SQL 语句,不过它是JPQL 语言 ,与原生 SQL 语句很类似,但是它是面向对象 的,当然我们也可以编写原生 SQL 语句。
比如我们要更新用户表中指定 ID 用户的密码:
1 2 3 4 5 6 7 8 @Repository public interface AccountRepository extends JpaRepository <Account, Integer> {@Transactional @Modifying @Query("update Account set password = ?2 where id = ?1") int updatePasswordById (int id, String newPassword) ;
1 2 3 4 @Test void updateAccount () {1 , "654321" );
现在我想使用原生 SQL 来实现根据用户名称修改密码:
1 2 3 4 5 @Transactional @Modifying @Query(value = "update users set password = :pwd where username = :name", nativeQuery = true) int updatePasswordByUsername (@Param("name") String username, //我们可以使用@Param 指定名称 @Param("pwd") String newPassword) ;
1 2 3 4 @Test void updateAccount () {"Admin" , "654321" );
通过编写原生 SQL ,在一定程度上弥补了SQL 不可控 的问题。
虽然 JPA 能够为我们带来非常便捷的开发体验,但是正是因为太便捷了,保姆级的体验有时也会适得其反,尤其是一些国内用到复杂查询业务的项目,可能开发到后期特别庞大时,就只能从底层 SQL 语句开始进行优化,而由于 JPA 尽可能地在屏蔽我们对 SQL 语句的编写,所以后期优化是个大问题,并且 Hibernate 相对于 Mybatis 来说,更加重量级。不过,在微服务的时代,单体项目一般不会太大,JPA 的劣势并没有太明显地体现出来。
[!NOTE] JPA 与 Mybatis 对比:
JPA 是全自动化 ORM 框架,适合简单的增删改查无需编写 sql,只能通过方法条件属性拼接实现复杂条件查询导致方法名太长可读性差,也可以通过 jpql 自定义 sql 或原生 sql 但相对麻烦。
mybatis 是半自动化 ORM 框架,通过注解结合自定义 sql 实现各种复杂条件查询等各种功能,逻辑可控易于后期优化,但编写 sql 相对费时费力。
MybatisPlus 框架 前面我们体验了 JPA 带来的快速开发体验,但是我们发现,面对一些复杂查询时,JPA 似乎有点力不从心,反观稍微麻烦一点的 Mybatis 却能够手动编写 SQL,使用起来更加灵活,那么有没有一种既能灵活掌控逻辑又能快速完成开发的持久层框架呢?
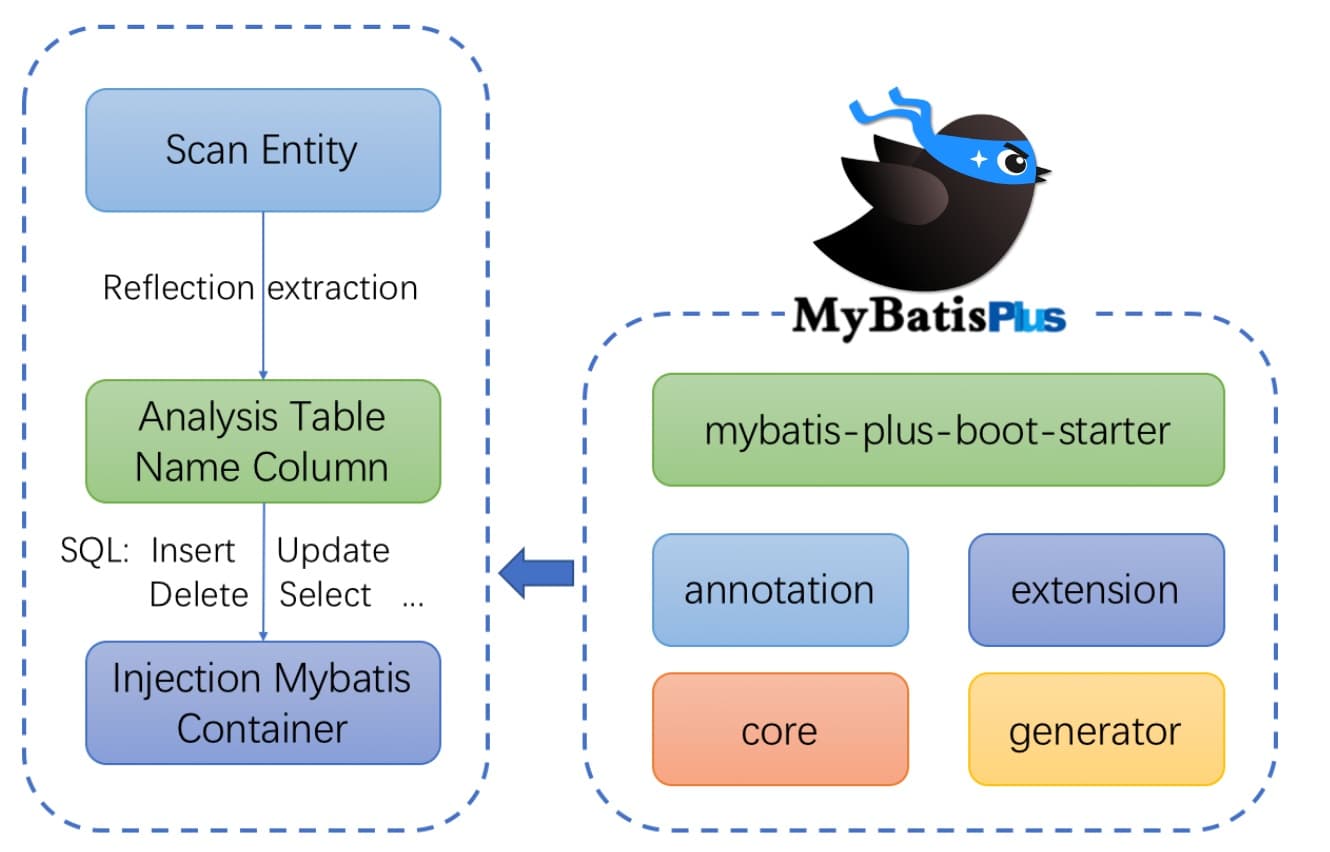
MyBatis-Plus (简称 MP)是一个 MyBatis 的增强工具,在 MyBatis 的基础上只做增强不做改变,为简化开发、提高效率而生。
MybatisPlus 的愿景是成为 MyBatis 最好的搭档,就像 魂斗罗 中的 1P、2P,基友搭配,效率翻倍。
官方网站地址:https://baomidou.com
MybatisPlus 具有以下特性:
无侵入 :只做增强不做改变,引入它不会对现有工程产生影响,如丝般顺滑损耗小 :启动即会自动注入基本 CURD,性能基本无损耗,直接面向对象操作强大的 CRUD 操作 :内置通用 Mapper、通用 Service,仅仅通过少量配置即可实现单表大部分 CRUD 操作,更有强大的条件构造器,满足各类使用需求支持 Lambda 形式调用 :通过 Lambda 表达式,方便的编写各类查询条件,无需再担心字段写错支持主键自动生成 :支持多达 4 种主键策略(内含分布式唯一 ID 生成器 - Sequence),可自由配置,完美解决主键问题支持 ActiveRecord 模式 :支持 ActiveRecord 形式调用,实体类只需继承 Model 类即可进行强大的 CRUD 操作支持自定义全局通用操作 :支持全局通用方法注入( Write once, use anywhere )内置代码生成器 :采用代码或者 Maven 插件可快速生成 Mapper 、 Model 、 Service 、 Controller 层代码,支持模板引擎,更有超多自定义配置等您来使用内置分页插件 :基于 MyBatis 物理分页,开发者无需关心具体操作,配置好插件之后,写分页等同于普通 List 查询分页插件支持多种数据库 :支持 MySQL、MariaDB、Oracle、DB2、H2、HSQL、SQLite、Postgre、SQLServer 等多种数据库内置性能分析插件 :可输出 SQL 语句以及其执行时间,建议开发测试时启用该功能,能快速揪出慢查询内置全局拦截插件 :提供全表 delete 、 update 操作智能分析阻断,也可自定义拦截规则,预防误操作
框架整体结构如下:
不过,光说还是不能体会到它带来的便捷性,我们接着就来上手体验一下。
快速上手 跟之前一样,还是添加依赖:
1 2 3 4 5 6 7 8 9 <dependency > <groupId > com.baomidou</groupId > <artifactId > mybatis-plus-boot-starter</artifactId > <version > 3.5.3.1</version > </dependency > <dependency > <groupId > com.mysql</groupId > <artifactId > mysql-connector-j</artifactId > </dependency >
配置文件依然只需要配置数据源即可:
1 2 3 4 5 6 spring: datasource: url: jdbc:mysql://localhost:3306/test username: root password: 123456 driver-class-name: com.mysql.cj.jdbc.Driver
然后依然是实体类,可以直接映射到数据库中的表:
1 2 3 4 5 6 7 8 9 10 11 12 @Data @TableName("user") public class User {@TableId(type = IdType.AUTO) int id;@TableField("name") @TableField("email") @TableField("password")
接着,我们就可以编写一个 Mapper 来操作了:
1 2 3 4 5 @Mapper public interface UserMapper extends BaseMapper <User> {
这里我们就来写一个简单测试用例:
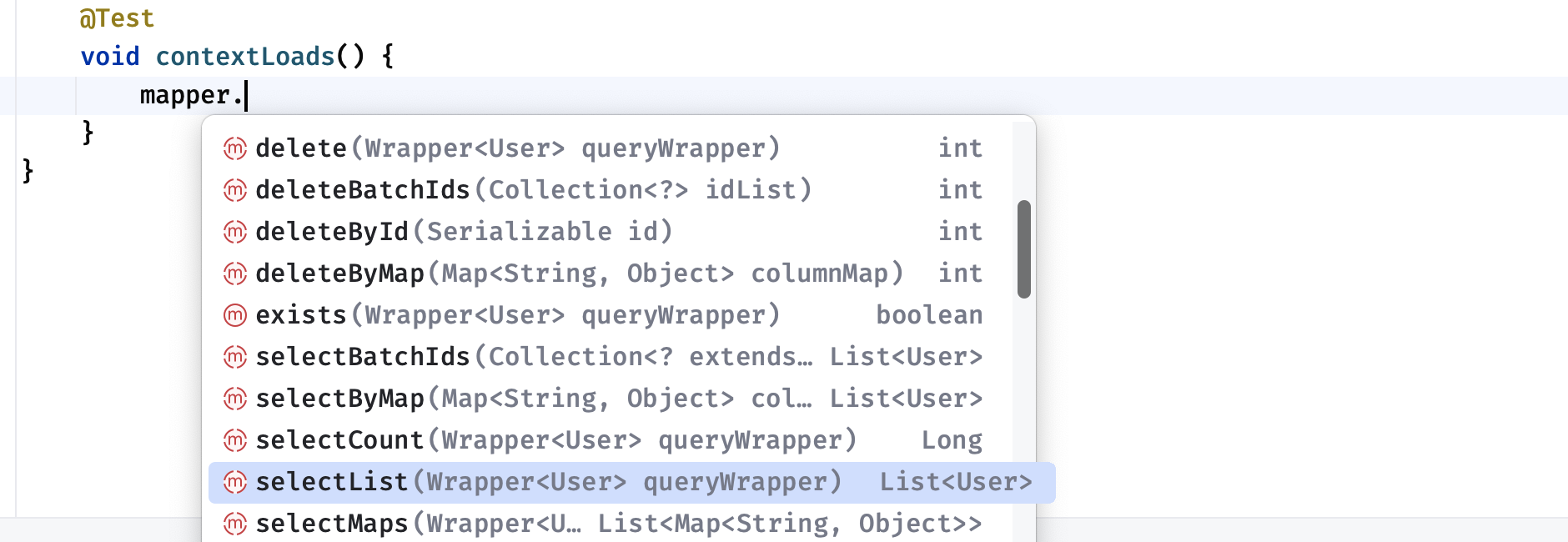
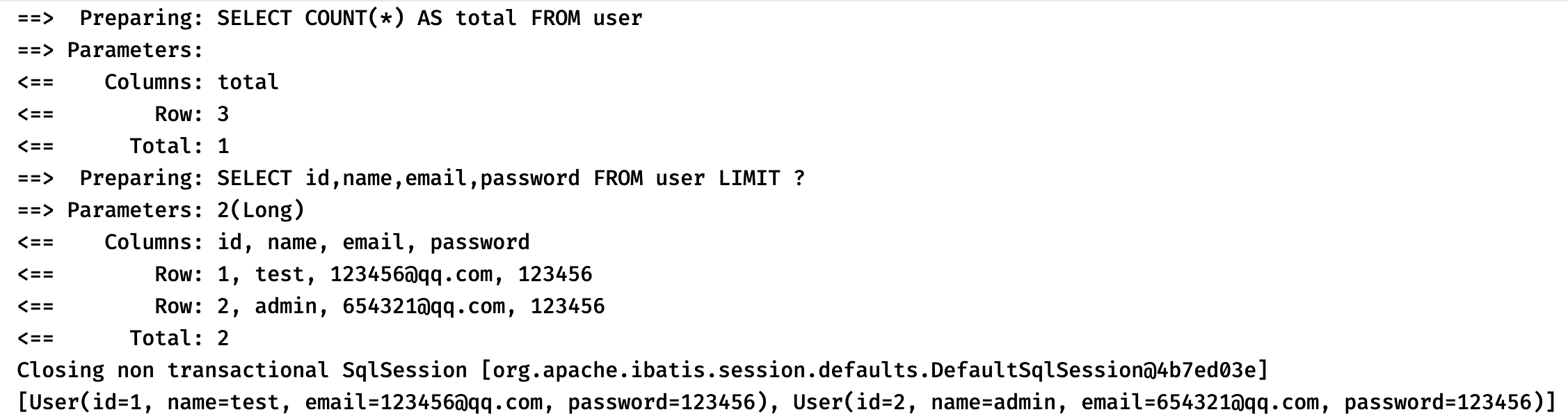
1 2 3 4 5 6 7 8 9 10 11 @SpringBootTest class DemoApplicationTests {@Resource @Test void contextLoads () {1 ));
可以看到这个 Mapper 提供的方法还是很丰富的:
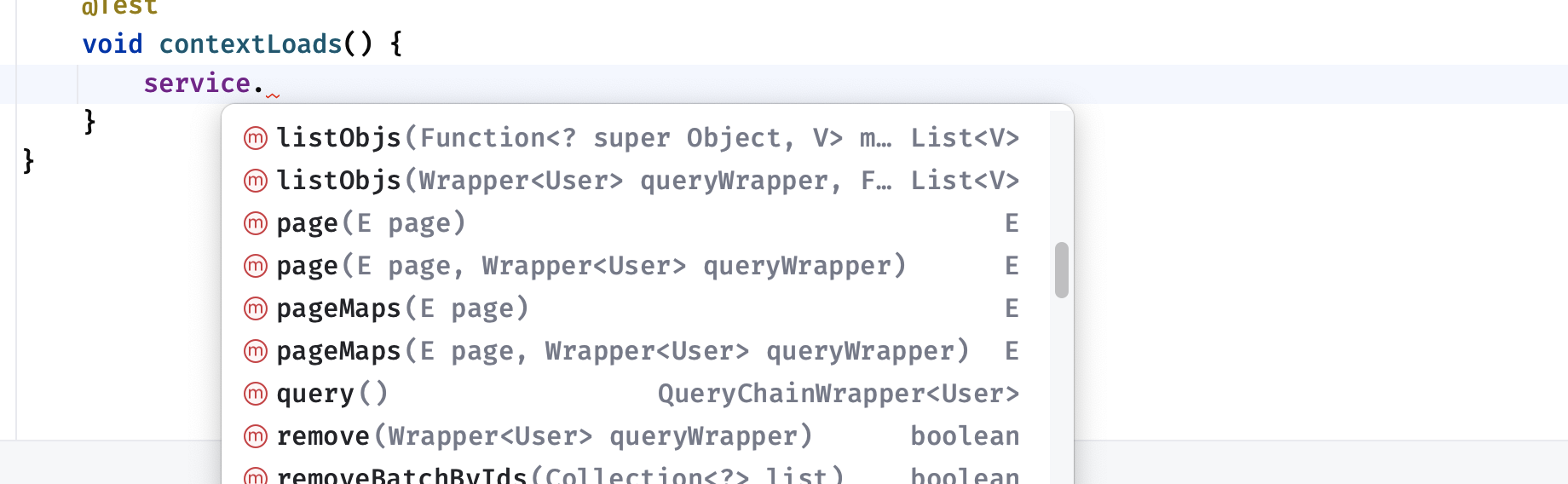
条件构造器 对于一些复杂查询的情况,MybatisPlus 支持我们自己构造 QueryWrapper 用于复杂条件查询 :
1 2 3 4 5 6 7 8 9 @Test void contextLoads () {new QueryWrapper <>(); "id" , "name" , "email" , "password" ) "id" , 2 ) "id" );
通过使用上面的 QueryWrapper 对象进行查询,也就等价于下面的 SQL 语句:
1 select id,name,email,password from user where id >= 2 order by id desc
我们可以在配置中开启 SQL 日志打印:
1 2 3 mybatis-plus: configuration: log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
最后得到的结果如下:
有些时候我们遇到需要批处理的情况,也可以直接使用批处理操作:
1 2 3 4 5 6 @Test void contextLoads () {int count = mapper.deleteBatchIds(List.of(1 , 3 ));
我们也可以快速进行分页查询操作 ,不过在执行前我们需要先配置一下:
1 2 3 4 5 6 7 8 9 10 @Configuration public class MybatisConfiguration {@Bean public MybatisPlusInterceptor paginationInterceptor () {MybatisPlusInterceptor interceptor = new MybatisPlusInterceptor ();new PaginationInnerInterceptor (DbType.MYSQL));return interceptor;
这样我们就可以愉快地使用分页功能了:
1 2 3 4 5 6 @Test void contextLoads () {1 , 2 ), Wrappers.emptyWrapper());
对于数据更新操作 ,我们也可以使用 UpdateWrapper 非常方便的来完成:
1 2 3 4 5 6 7 8 @Test void contextLoads () {new UpdateWrapper <>();"name" , "lbw" )"id" , 1 );null , wrapper));
这样就可以快速完成更新操作了:
QueryWrapper 和 UpdateWrapper 还有专门支持 Java 8 新增的 Lambda 表达式的特殊实现,可以直接以函数式的形式进行编写,使用方法是一样的,这里简单演示几个:
1 2 3 4 5 6 7 8 @Test void contextLoads () {2 )
不过感觉可读性似乎没有不用 Lambda 高啊。
接口基本操作 虽然使用 MybatisPlus 提供的 BaseMapper 已经很方便了,但是我们的业务中,实际上很多时候也是一样的工作,都是去简单调用底层的 Mapper 做一个很简单的事情,那么能不能干脆把 Service 也给弄个模版?MybatisPlus 为我们提供了很方便的 CRUD 接口,直接实现了各种业务中会用到的增删改查操作。
我们只需要继承即可:
xxxService 继承 Iservice:
1 2 3 4 @Service public interface UserService extends IService <User> {
接着我们还需要编写一个实现类,这个实现类就是 UserService 的实现:xxxServiceImpl 继承 ServiceImpl<xxxMapper,xxx>:
1 2 3 @Service public class UserServiceImpl extends ServiceImpl <UserMapper, User> implements UserService {
使用起来也很方便,整合了超多方法:
比如我们想批量插入一组用户数据到数据库中:
1 2 3 4 5 6 @Test void contextLoads () {new User ("xxx" ), new User ("yyy" ));
还有更加方便快捷的保存或更新操作,当数据不存在时(通过主键 ID 判断)则插入新数据,否则就更新数据:
1 2 3 4 @Test void contextLoads () {new User ("aaa" ));
我们也可以直接使用 Service 来进行链式查询,写法非常舒服:
1 2 3 4 5 @Test void contextLoads () {User one = service.query().eq("id" , 1 ).one();
新版代码生成器 它能够根据数据库做到代码的一键生成
你没看错,整个项目从 Mapper 到 Controller,所有的东西全部都给你生成好了,你只管把需要补充的业务给写了就行,这是真正的把饭给喂到你嘴边的行为,是广大学子的毕设大杀器。
那么我们就来看看,这玩意怎么去用的,首先我们需要先把整个项目的数据库给创建好,创建好之后,我们继续下一步,这里我们从头开始创建一个项目,感受一下它的强大,首先创建一个普通的 SpringBoot 项目:
接着我们导入一会需要用到的依赖:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 <dependency > <groupId > com.baomidou</groupId > <artifactId > mybatis-plus-boot-starter</artifactId > <version > 3.5.3.1</version > </dependency > <dependency > <groupId > com.baomidou</groupId > <artifactId > mybatis-plus-generator</artifactId > <version > 3.5.3.1</version > </dependency > <dependency > <groupId > org.apache.velocity</groupId > <artifactId > velocity-engine-core</artifactId > <version > 2.3</version > </dependency >
然后再配置一下数据源:
1 2 3 4 5 6 spring: datasource: url: jdbc:mysql://localhost:3306/test username: root password: 123456 driver-class-name: com.mysql.cj.jdbc.Driver
接着我们就可以开始编写自动生成脚本了,这里依然选择测试类,用到 FastAutoGenerator 作为生成器:
1 2 3 4 5 6 7 @Test void contextLoads () {new DataSourceConfig .Builder(dataSource))
接着我们配置一下全局设置,这些会影响一会生成的代码:
1 2 3 4 5 6 7 8 9 10 11 @Test void contextLoads () {new DataSourceConfig .Builder(dataSource))"lbw" ); "2024-01-01" ); "src/main/java" );
然后是打包设置,也就是项目的生成的包等等,这里简单配置一下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 @Test void contextLoads () {"com.example" ))
最终完整配置如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 @Test void contextLoads () { new DataSourceConfig .Builder(source)) "alleyf" ); "2023-11-04" ); "src\\main\\java" ); "com.example" ))
接着我们就可以直接执行了这个脚本了:
现在,可以看到我们的项目中已经出现自动生成代码了:
我们也可以直接运行这个项目:
速度可以说是非常之快,一个项目模版就搭建完成了,我们只需要接着写业务就可以了,当然如果需要更多定制化的话,可以在官网查看其他的配置:https://baomidou.com/pages/981406/
对于一些有特殊要求的用户来说,我们希望能够以自己的模版来进行生产,怎么才能修改它自动生成的代码模版呢,我们可以直接找到 mybatis-plus-generator 的源码:
生成模版都在在这个里面有写,我们要做的就是去修改这些模版,变成我们自己希望的样子,由于默认的模版解析引擎为 Velocity,我们需要复制以 .vm 结尾的文件到 resource 随便一个目录中,然后随便改:
接着我们配置一下模版:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 @Test void contextLoads () {"/template/mapper.java.vm" );
这样,新生成的代码中就是按照我们自己的模版来定义了:
[!NOTE] MybatisPlus 核心用法
pom.xml 引入 mybatisplus 依赖 ,并配置数据源、日志打印 等手动编写:
编写 Xxxmapper 接口继承 baseMapper<entity>
编写IXxxService 接口继承 IService<entity>
编写XxxServiceImpl 继承 ServiceImpl<Xxxmapper,entity> 并实现 IXxxService 接口
代码生成器:
在测试文件中编写代码生成器配置代码 ,设置注释信息、生成目录、项目包名 等
补充多表关联表和外键 (JoinTable/JoinColumn )
根据需要补充复杂逻辑 Sql 功能,完成 Controller 逻辑功能
走进 SpringBoot 前后端分离 前后端分离是一种软件架构模式,它将前端和后端的开发职责分开,使得前端和后端可以独立进行开发、测试和部署。在之前,我们都是编写 Web 应用程序,但是随着时代发展,各种桌面 App、手机端 App 还有小程序层出不穷,这都完全脱离我们之前的开发模式,客户端和服务端的划分越来越明显,前后端分离开发势在必行。
在前后端分离架构中,前端主要负责展示层的开发,包括用户界面的设计、用户交互的实现等。前端使用一些技术栈,如 Vue、React 等技术来实现用户界面,同时通过 Ajax、Axios 等技术与后端进行数据的交互,这样前端无论使用什么技术进行开发,都与后端无关,受到的限制会小很多。
后端主要负责业务逻辑的处理和数据的存储,包括用户认证、数据验证、数据处理、数据库访问等实际上后端只需要返回前端需要的数据即可,一般使用 JSON 格式进行返回。
前后端分离架构的优势包括:
前后端可以同时独立进行开发,提高开发效率。
前端可以灵活选择技术栈和框架,提供更好的用户体验。
后端可以专注于业务逻辑的实现,提高代码的可维护性。
前后端通过接口进行通信,使得前端和后端可以分别进行部署,提高系统的可扩展性和灵活性。
然而,前后端分离架构也存在一些挑战,包括接口设计的复杂性、前后端协作的沟通成本等。因此,在选择前后端分离架构时,需要综合考虑项目的特点和团队成员的技能,以及开发周期等因素。
基于 Session 的分离(有状态) 基于 Cookie 的前后端分离是最简单的一种,也是更接近我们之前学习的一种。在之前,我们都是使用 SpringSecurity 提供的默认登录流程完成验证。
我们发现,实际上 SpringSecurity 在登录之后,会利用Session 机制记录用户的登录状态,这就要求我们每次请求的时候都需要携带 Cookie 才可以,因为 Cookie 中存储了用于识别的 JSESSIONID 数据 。因此,要实现前后端分离,我们只需要稍微修改一下就可以实现了,这对于小型的单端应用程序非常友好。
学习环境搭建 考虑到各位小伙伴没有学习过 Vue 等前端框架,这里我们依然使用前端模版进行魔改。只不过现在我们的前端页面需要单独进行部署,而不是和后端揉在一起,这里我们需要先创建一个前端项目,依赖只需勾选 SpringWeb 即可,主要用作反向代理前端页面:
如果各位小伙伴学习了 Nginx 代理,使用 Nginx 代理前端项目会更好一些。
接着我们将所有的前端模版文件全部丢进对应的目录中,创建一个 web 目录到 resource 目录下,然后放入我们前端模版的全部文件:
然后配置一下静态资源代理,现在我们希望的是页面直接被代理,不用我们手动去写 Controller 来解析视图:
1 2 3 4 spring: web: resources: static-locations: classpath:/web
然后启动服务器就行了:
接着我们就可以随便访问我们的网站了:
这样前端页面就部署完成了,接着我们还需要创建一个后端项目,用于去编写我们的后端,选上我们需要的一些依赖:
接着我们需要修改一下后端服务器的端口,因为现在我们要同时开两个服务器,一个是负责部署前端的,一个是负责部署后端的,这样就是标准的前后端分离了,所以说为了防止端口打架,我们就把端口开放在 8081 上:
现在启动这两个服务器,我们的学习环境就搭建好了。
实现登录授权和跨域处理 在之前,我们的登录操作以及登录之后的页面跳转都是由 SpringSecurity 来完成,但是现在前后端分离之后,整个流程发生了变化,现在前端仅仅是调用登录接口进行一次校验即可,而后端只需要返回本次校验的结果,由前端来判断是否校验成功并跳转页面:
因此,现在我们只需要让登录模块响应一个 JSON 数据告诉前端登录成功与否即可,当然,前端在发起请求的时候依然需要携带 Cookie 信息,否则后端不认识是谁。
现在我们就来尝试实现一下这种模式,首先我们配置一下 SpringSecurity 的相关接口:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 @Configuration public class SecurityConfiguration {@Bean public SecurityFilterChain filterChain (HttpSecurity http) throws Exception {return http"/api/auth/login" );
虽然这样成功定义了登录接口相关内容,但是怎么才能让 SpringSecurity 在登录成功之后返回一个 JSON 数据给前端而不是默认的重定向呢?这时我们可以手动设置 SuccessHandler 和 FailureHandler 来实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 @Bean public SecurityFilterChain filterChain (HttpSecurity http) throws Exception {return http"/api/auth/login" );this ::onAuthenticationFailure);this ::onAuthenticationSuccess);void onAuthenticationFailure (HttpServletRequest request, HttpServletResponse response, AuthenticationException exception) {void onAuthenticationSuccess (HttpServletRequest request, HttpServletResponse response, Authentication authentication) {
现在我们需要返回一个标准的 JSON 格式数据作为响应,这里我们根据 Rest API 标准来进行编写:
REST API 是遵循 REST(Representational State Transfer, 表述性状态转移)原则的 Web 服务接口,下面简单介绍一下 REST 接口规范以及对应的响应数据该如何编写:
1. REST 接口规范
使用 HTTP 方法 :GET(检索资源)、POST(创建资源)、PUT(更新资源)、DELETE(删除资源)。无状态 : REST 接口要求实现无状态从而使其独立于之前的请求。使用正确的 HTTP 状态码 :在 HTTP 响应中反馈操作的结果(例如,200 表示成功,404 表示资源不存在等)。URI 应该清晰易懂 :URI 应能清晰地指示出所引用资源的类型和编号,并能易于理解和使用。
2. 响应数据格式 REST 应答一般使用的格式为 JSON,以下是一个标准的 JSON 响应数据样例:
1 2 3 4 5 6 7 8 9 > { "code" : 200 , "data" : { "id" : 1 , "name" : "Tom" , "age" : 18 } , "message" : "查询成功" }
字段的含义分别为:
code :HTTP 状态码,表示请求的结果。常见的有 200(成功)、400(客户端错误)、500(服务器错误)等。data :响应的真实数据。在上例中,是一个包含用户信息的对象。message :请求响应信息,常用于描述请求处理结果。
上述都是建议的最佳实践,实际应用中可以根据具体的业务需求进行适当的调整。
这里我们创建一个实体类来装载响应数据,可以使用记录类型:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 public record RestBean <T> (int code, T data, String message) {public static <T> RestBean<T> success (T data) {return new RestBean <>(200 , data, "请求成功" );public static <T> RestBean<T> failure (int code, String message) {return new RestBean <>(code, null , message);public static <T> RestBean<T> failure (int code) {return failure(code, "请求失败" );public String asJsonString () {return JSONObject.toJSONString(this , JSONWriter.Feature.WriteNulls);
接着我们稍微设置一下对应的 Handler 即可:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 void onAuthenticationFailure (HttpServletRequest request, HttpServletResponse response, AuthenticationException exception) throws IOException {"application/json;charset=utf-8" );PrintWriter writer = response.getWriter();401 , exception.getMessage()).asJsonString());void onAuthenticationSuccess (HttpServletRequest request, HttpServletResponse response, Authentication authentication) throws IOException {"application/json;charset=utf-8" );PrintWriter writer = response.getWriter();
现在我们就可以使用 API 测试工具来调试一下了:
可以看到响应的结果是标准的 JSON 格式数据,而不是像之前那样重定向到一个页面,这样前端发起的异步请求就可以进行快速判断了。
我们来尝试写一个简单的前端逻辑试试看,这里依然引入 Axios 框架来发起异步请求:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 <script src ="https://unpkg.com/axios@1.1.2/dist/axios.min.js" > </script > <script > function getInfo ( axios.post (' http://localhost:8081/api/auth/login ' , { username : document .getElementById ('username' ).value , password : document .getElementById ('password' ).value }, { headers : { 'Content-Type' : 'application/x- www-form-urlencoded ' }, withCredentials : true }).then (({data} ) => { if (data.code === 200 ) { window .location .href = '/index.html' } else { alert ('登录失败:' +data.message ) } }) } </script >
可能会有小伙伴好奇,这个前端不是每个页面都能随便访问吗,这登录跟不登录有啥区别?实际上我们的前端开发者会在前端做相应的路由以及拦截来控制页面的跳转,我们后端开发者无需担心,我们只需要保证自己返回的数据是准确无误的即可,其他的交给前端小姐姐就好,这里我们只是做个样子。
当点击按钮时就能发起请求了,但是我们现在遇到了一个新的问题:
我们在发起登录请求时,前端得到了一个跨域请求错误,这是因为我们前端的站点和后端站点不一致导致的,浏览器为了用户的安全,防止网页中一些恶意脚本跨站请求数据,会对未经许可的跨域请求发起拦截。那么,我们怎么才能让这个请求变成我们许可的呢?对于跨域问题,是属于我们后端需要处理的问题,跟前端无关,我们需要在响应的时候,在响应头中添加一些跨域属性,来告诉浏览器从哪个站点发来的跨域请求是安全的,这样浏览器就不会拦截了。
那么如何进行配置呢,我们现在使用了 SpringSecurity 框架,可以直接进行跨域配置 :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 public SecurityFilterChain filterChain (HttpSecurity http) throws Exception {return httpCorsConfiguration cors = new CorsConfiguration ();" http://localhost:8080" );true ); "*" ); "*" );"*" );UrlBasedCorsConfigurationSource source = new UrlBasedCorsConfigurationSource ();"/**" , cors);
这样,当我们再次重启服务器,返回的响应头中都会携带跨域相关的信息,这样浏览器就不会进行拦截了:
这样就可以实现前后端分离的登录模式了:
由于记住我功能和退出登录操作跟之前是一样的配置,这里我们就不进行演示了。
响应 JSON 化 前面我们完成了前后端分离的登录模式,我们来看看一般的业务接口该如何去实现,比如这里我们写一个非常简单的的用户名称获取接口:
1 2 3 4 5 6 7 8 9 10 @RestController @RequestMapping("/api/user") public class UserController {@GetMapping("/name") public RestBean<String> username () {User user = (User) SecurityContextHolder.getContext().getAuthentication().getPrincipal();return RestBean.success(user.getUsername());
这样前端就可以在登录之后获取到这个接口的结果了,注意一定要在请求时携带 Cookie,否则服务端无法识别身份,会直接被拦截并重定向:
1 2 3 4 5 6 7 <script > axios.get (' http://localhost:8081/api/user/name ' , { withCredentials : true }).then (({data} ) => { document .getElementById ('username' ).innerText = data.data }) </script >
注意一定要登录之后再请求,成功的请求结果如下:
不过我们发现,我们的一些响应还是不完善,比如用户没有登录,默认还是会 302 重定向,但是实际上我们只需要告诉前端没有登录就行了,所以说我们修改一下未登录状态下返回的结果:
1 2 3 4 5 6 7 8 9 10 11 12 @Bean public SecurityFilterChain filterChain (HttpSecurity http) throws Exception {return httpthis ::onAccessDeny);this ::onAuthenticationFailure);
现在有三个方法,但是实际上功能都是一样的,我们可以把它们整合为同一个方法:
1 2 3 4 5 6 7 8 9 10 11 12 13 private void handleProcess (HttpServletRequest request, HttpServletResponse response, Object exceptionOrAuthentication) throws IOException {"application/json;charset=utf-8" );PrintWriter writer = response.getWriter();if (exceptionOrAuthentication instanceof AccessDeniedException exception) {403 , exception.getMessage()).asJsonString());else if (exceptionOrAuthentication instanceof Exception exception) {401 , exception.getMessage()).asJsonString());else if (exceptionOrAuthentication instanceof Authentication authentication){
这样,用户在没有登录的情况下,请求接口就会返回我们的自定义 JSON 信息了:
对于我们页面中的一些常见的异常,我们也可以编写异常处理器来将其规范化返回 ,比如 404 页面,我们可以直接配置让其抛出异常:
1 2 3 4 5 6 spring: mvc: throw-exception-if-no-handler-found: true web: resources: add-mappings: false
然后编写异常处理器:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 @RestController @ControllerAdvice public class ExceptionController {@ExceptionHandler(Exception.class) public RestBean<String> error (Exception e) {if (e instanceof NoHandlerFoundException exception) return RestBean.failure(404 , e.getMessage()); else if (e instanceof ServletException exception) return RestBean.failure(400 , e.getMessage());else return RestBean.failure(500 , e.getMessage());
这样我们的后端就返回的是非常统一的 JSON 格式数据了,前端开发人员只需要根据我们返回的数据编写统一的处理即可,基于 Session 的前后端分离实现起来也是最简单的。
基于 Token 的分离(无状态) 基于 Token 的前后端分离主打无状态,无状态服务是指在处理每个请求时,服务本身不会维持任何与请求相关的状态信息。每个请求被视为独立的、自包含的操作,服务只关注处理请求本身,而不关心前后请求之间的状态变化。也就是说,用户在发起请求时,服务器不会记录其信息,而是通过用户携带的 Token 信息来判断是哪一个用户:
有状态:用户请求接口 -> 从 Session 中读取用户信息 -> 根据当前的用户来处理业务 -> 返回
无状态:用户携带 Token 请求接口 -> 从请求中获取用户信息 -> 根据当前的用户来处理业务 -> 返回
无状态服务的优点包括:
服务端无需存储会话信息 :传统的会话管理方式需要服务端存储用户的会话信息,包括用户的身份认证信息和会话状态。而使用 Token,服务端无需存储任何会话信息,所有的认证信息都包含在 Token 中,使得服务端变得无状态,减轻了服务器的负担,同时也方便了服务的水平扩展。减少网络延迟:传统的会话管理方式需要在每次请求中都携带会话标识,即使是无状态的 RESTful API 也需要携带身份认证信息。而使用 Token,身份认证信息已经包含在 Token 中,只需要在请求的 Authorization 头部携带 Token 即可,减少了每次请求的数据量,减少了网络延迟。
客户端无需存储会话信息:传统的会话管理方式中,客户端需要存储会话标识,以便在每次请求中携带。而使用 Token,客户端只需要保存 Token 即可,方便了客户端的存储和管理。
跨域支持:Token 可以在各个不同的域名之间进行传递和使用,因为 Token 是通过签名来验证和保护数据完整性的,可以防止未经授权的修改。
这一部分,我们将深入学习目前比较主流的基于 Token 的前后端分离方案。
认识 JWT 令牌 在认识 Token 前后端分离之前,我们需要先学习最常见的 JWT 令牌,官网: https://jwt.io
JSON Web Token 令牌(JWT)是一个开放标准(RFC 7519 ),它定义了一种紧凑和自成一体的方式,用于在各方之间作为 JSON 对象安全地传输信息。这些信息可以被验证和信任,因为它是数字签名的。JWT 可以使用密钥(使用HMAC 算法)或使用RSA 或ECDSA 进行公钥/私钥对进行签名。
JWT 令牌的格式如下:
一个 JWT 令牌由 3 部分组成:标头(Header)、有效载荷(Payload)和签名(Signature)。在传输的时候,会将 JWT 的钱 2 部分分别进行 Base64 编码后用 . 进行连接形成最终需要传输的字符串。
标头:包含一些元数据信息,比如 JWT 签名所使用的加密算法,还有类型,这里统一都是 JWT。
有效载荷:包括用户名称、令牌发布时间、过期时间、JWT ID 等,当然我们也可以自定义添加字段,我们的用户信息一般都在这里存放。
签名:首先需要指定一个密钥,该密钥仅仅保存在服务器中,保证不能让其他用户知道。然后使用 Header 中指定的算法对 Header 和 Payload 进行 base64 加密之后的结果通过密钥计算哈希值,然后就得出一个签名哈希。这个会用于之后验证内容是否被篡改。
这里还是补充一下一些概念,因为很多东西都是我们之前没有接触过的:
Base64 :就是包括小写字母 a-z、大写字母 A-Z、数字 0-9、符号”+”、”/“一共 64 个字符 的字符集(末尾还有 1 个或多个 = 用来凑够字节数),任何的符号都可以转换成这个字符集中的字符,这个转换过程就叫做 Base64 编码,编码之后会生成只包含上述 64 个字符的字符串。相反,如果需要原本的内容,我们也可以进行 Base64 解码,回到原有的样子。
1 2 3 4 5 6 7 8 public void test () {String str = "你们可能不知道只用 20 万赢到 578 万是什么概念" ;String encodeStr = Base64.getEncoder().encodeToString(str.getBytes());"Base64 编码后的字符串:" +encodeStr);"解码后的字符串:" +new String (Base64.getDecoder().decode(encodeStr)));
注意 Base64 不是加密算法,只是一种信息的编码方式而已。
加密算法:加密算法分为对称加密和非对称加密 ,其中对称加密(Symmetric Cryptography)比较好理解,就像一把锁配了两把钥匙一样,这两把钥匙你和别人都有一把,然后你们直接传递数据,都会把数据用锁给锁上,就算传递的途中有人把数据窃取了,也没办法解密,因为钥匙只有你和对方有,没有钥匙无法进行解密,但是这样有个问题,既然解密的关键在于钥匙本身,那么如果有人不仅窃取了数据,而且对方那边的治安也不好,于是顺手就偷走了钥匙,那你们之间发的数据不就凉凉了吗。
因此,非对称加密 (Asymmetric Cryptography)算法出现了,它并不是直接生成一把钥匙,而是生成一个公钥和一个私钥 ,私钥只能由你保管,而公钥交给对方或是你要发送的任何人都行,现在你需要把数据传给对方,那么就需要使用私钥进行加密,但是,这个数据只能使用对应的公钥进行解密,相反,如果对方需要给你发送数据,那么就需要用公钥进行加密,而数据只能使用私钥进行解密 ,这样的话就算对方的公钥被窃取,那么别人发给你的数据也没办法解密出来,因为需要私钥才能解密,而只有你才有私钥。
因此,非对称加密的安全性会更高一些,包括 HTTPS 的隐私信息正是使用非对称加密来保障传输数据的安全(当然 HTTPS 并不是单纯地使用非对称加密完成的)
对称加密和非对称加密都有很多的算法,比如对称加密,就有:DES、IDEA、RC2 ,非对称加密有:RSA、DAS、ECC
不可逆加密算法: 常见的不可逆加密算法有 MD5, HMAC, SHA-1, SHA-224, SHA-256, SHA-384, 和 SHA-512, 其中 SHA-224、SHA-256、SHA-384,和 SHA-512 我们可以统称为 SHA2 加密算法,SHA 加密算法的安全性要比 MD5 更高,而 SHA2 加密算法比 SHA1 的要高,其中 SHA 后面的数字表示的是加密后的字符串长度,SHA1 默认会产生一个 160 位的信息摘要。经过不可逆加密算法得到的加密结果,是无法解密回去的,也就是说加密出来是什么就是什么了。本质上,其就是一种哈希函数,用于对一段信息产生摘要,以防止被篡改 。
实际上这种算法就常常被用作信息摘要计算,同样的数据通过同样的算法计算得到的结果肯定也一样,而如果数据被修改,那么计算的结果肯定就不一样了。
因此,JWT 令牌实际上是一种经过加密的 JSON 数据 ,其中包含了用户名字、用户 ID 等信息 ,我们可以直接解密 JWT 令牌得到用户的信息,我们可以写一个小测试来看看,导入 JWT 支持库依赖:
1 2 3 4 5 <dependency > <groupId > com.auth0</groupId > <artifactId > java-jwt</artifactId > <version > 4.3.0</version > </dependency >
要生成一个 JWT 令牌非常简单:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 public class Main {public static void main (String[] args) {String jwtKey = "abcdefghijklmn" ; Algorithm algorithm = Algorithm.HMAC256(jwtKey); String jwtToken = JWT.create()"id" , 1 ) "name" , "lbw" )"role" , "nb" )new Date (2024 , Calendar.FEBRUARY, 1 )) new Date ())
可以看到最后得到的 JWT 令牌就长这样:
1 eyJ0 eXAiOiJKV1 QiLCJhbGciOiJIUzI1 NiJ9 .eyJyb2 xlIjoibmIiLCJuYW1 lIjoibGJ3 IiwiaWQiOjEsImV4 cCI6 NjE2 NjQ4 NjA4 MDAsImlhdCI6 MTY5 MDEzMTQ3 OH0. KUuGKM0 OynL_DEUnRIETDBlmGjoqbt_5 dP2 r21 ZDE1 s
我们可以使用 Base64 将其还原为原本的样子:
1 2 3 4 5 6 7 8 9 public static void main (String[] args) {String jwtToken = "eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJyb2xlIjoibmIiLCJuYW1lIjoibGJ3IiwiaWQiOjEsImV4cCI6NjE2NjQ4NjA4MDAsImlhdCI6MTY5MDEzMTQ3OH0.KUuGKM0OynL_DEUnRIETDBlmGjoqbt_5dP2r21ZDE1s" ;"\\." );for (int i = 0 ; i < split.length - 1 ; i++) {String s = split[i];byte [] decode = Base64.getDecoder().decode(s);new String (decode));
解析前面两个部分得到:
1 2 { "typ" : "JWT" , "alg" : "HS256" } { "role" : "nb" , "name" : "lbw" , "id" : 1 , "exp" : 61664860800 , "iat" : 1690131478 }
可以看到确实是经过 Base64 加密的 JSON 格式数据,包括我们的自定义数据也在其中,而我们可以直接使用 JWT 令牌来作为我们权限校验的核心,我们可以像这样设计我们的系统:
首先用户还是按照正常流程进行登录,只不过用户在登录成功之后,服务端会返回一个 JWT 令牌用于后续请求使用,由于 JWT 令牌具有时效性,所以说当过期之后又需要重新登录。就像我们进入游乐园需要一张门票一样,只有持有游乐园门票才能进入游乐园游玩,如果没有门票就会被拒之门外,而游乐园门票也有时间限制,如果已经过期,我们也是没有办法进入游乐园的。
所以,我们只需要在后续请求中携带这个 Token 即可(可以放在 Cookie 中,也可以放在请求头中)这样服务器就可以直接从 Token 中解密读取到我们用户的相关信息以及判断用户是否登录过期了。
既然现在用户信息都在 JWT 中,那要是用户随便修改里面的内容,岂不是可以以任意身份访问服务器了?这会不会存在安全隐患?对于这个问题,前面我们已经说的很清楚了,JWT 实际上最后会有一个加密的签名,这个是根据秘钥+JWT 本体内容计算得到的,用户在没有持有秘钥的情况下,是不可能计算得到正确的签名的,所以说服务器会在收到 JWT 时对签名进行重新计算,比较是否一致,来验证 JWT 是否被用户恶意修改,如果被修改肯定也是不能通过的。
SpringSecurity 实现 JWT 校验 前面我们介绍了 JWT 的基本原理以及后端的基本校验流程,那么我们现在就来看看如何实现这样的流程。
SpringSecurity 中并没有为我们提供预设的 JWT 校验模块(只有 OAuth2 模块才有,但是知识太超前了,我们暂时不讲解)这里我们只能手动进行整合,JWT 可以存放在 Cookie 或是请求头中,不过不管哪种方式,我们都可以通过 Request 获取到对应的 JWT 令牌,这里我们使用比较常见的请求头携带 JWT 的方案,客户端发起的请求中会携带这样的的特殊请求头:
1 Authorization : Bearer eyJhbGciOiJSUzI1NiJ9.eyJpc3MiOiJzZWxmIiwic3ViIjoidXNlciIsImV4cCI6MTY5MDIxODE2NCwiaWF0IjoxNjkwMTgyMTY0LCJzY29wZSI6ImFwcCJ9.Z5-WMeulZyx60WeNxrQg2z2GiVquEHrsBl9V4dixbRkAD6rFp-6 gCrcAXWkebs0i-we4xTQ7TZW0ltuhGYZ1GmEaj4F6BP9VN8fLq2aT7GhCJDgjikaTs-w5BbbOD2PN_vTAK_KeVGvYhWU4_l81cvilJWVXAhzMtwgPsz1Dkd04cWTCpI7ZZi-RQaBGYlullXtUrehYcjprla8N-bSpmeb3CBVM3kpAdehzfRpAGWXotN27PIKyAbtiJ0rqdvRmvlSztNY0_1IoO4TprMTUr-wjilGbJ5QTQaYUKRHcK3OJrProz9m8ztClSq0GRvFIB7HuMlYWNYwf7lkKpGvKDg
这里的 Authorization 请求头就是携带 JWT 的专用属性,值的格式为”Bearer Token”,前面的 Bearer 代表身份验证方式,默认情况下有两种:
Basic 和 Bearer 是两种不同的身份验证方式。
Basic 是一种基本的身份验证方式,它将用户名和密码进行 base64 编码后,放在 Authorization 请求头中,用于向服务器验证用户身份。这种方式不够安全,因为它将密码以明文的形式传输,容易受到中间人攻击。
Bearer 是一种更安全的身份验证方式,它基于令牌(Token)来验证用户身份。Bearer 令牌是由身份验证服务器颁发给客户端的,客户端在每个请求中将令牌放在 Authorization 请求头的 Bearer 字段中。服务器会验证令牌的有效性和权限,以确定用户的身份。Bearer 令牌通常使用 JSON Web Token (JWT) 的形式进行传递和验证。
一会我们会自行编写 JWT 校验拦截器来处理这些信息。
首先我们先把用于处理 JWT 令牌的工具类完成一下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 public class JwtUtils {private static final String key = "abcdefghijklmn" ;public static String createJwt (UserDetails user) {Algorithm algorithm = Algorithm.HMAC256(key);Calendar calendar = Calendar.getInstance();Date now = calendar.getTime();3600 * 24 * 7 );return JWT.create()"name" , user.getUsername()) "authorities" , user.getAuthorities().stream().map(GrantedAuthority::getAuthority).toList())public static UserDetails resolveJwt (String token) {Algorithm algorithm = Algorithm.HMAC256(key);JWTVerifier jwtVerifier = JWT.require(algorithm).build();try {DecodedJWT verify = jwtVerifier.verify(token); if (new Date ().after(claims.get("exp" ).asDate())) return null ;else return User"name" ).asString())"" )"authorities" ).asArray(String.class))catch (JWTVerificationException e) {return null ;
接着我们需要自行实现一个 JwtAuthenticationFilter 加入到 SpringSecurity 默认提供的过滤器链中,用于处理请求头中携带的 JWT 令牌,并配置登录状态:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 public class JwtAuthenticationFilter extends OncePerRequestFilter { @Override protected void doFilterInternal (HttpServletRequest request, HttpServletResponse response, FilterChain filterChain) throws ServletException, IOException {String authorization = request.getHeader("Authorization" );if (authorization != null && authorization.startsWith("Bearer " )) {String token = authorization.substring(7 ); UserDetails user = JwtUtils.resolveJwt(token);if (user != null ) {UsernamePasswordAuthenticationToken authentication = new UsernamePasswordAuthenticationToken (user, null , user.getAuthorities());new WebAuthenticationDetailsSource ().buildDetails(request));
最后我们来配置一下 SecurityConfiguration 配置类,其实配置方法跟之前还是差不多,用户依然可以使用表单进行登录,并且登录方式也是一样的,就是有两个新增的部分需要我们注意一下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 @Configuration public class SecurityConfiguration {@Bean public SecurityFilterChain filterChain (HttpSecurity http) throws Exception {return httpnew JwtAuthenticationFilter (), UsernamePasswordAuthenticationFilter.class)private void handleProcess (HttpServletRequest request, HttpServletResponse response, Object exceptionOrAuthentication) throws IOException {"application/json;charset=utf-8" );PrintWriter writer = response.getWriter();if (exceptionOrAuthentication instanceof AccessDeniedException exception) {403 , exception.getMessage()).asJsonString());else if (exceptionOrAuthentication instanceof AuthenticationException exception) {401 , exception.getMessage()).asJsonString());else if (exceptionOrAuthentication instanceof Authentication authentication){
最后我们创建一个测试使用的 Controller 来看看效果:
1 2 3 4 5 6 7 8 @RestController public class TestController {@GetMapping("/test") public String test () {return "HelloWorld" ;
那么现在采用 JWT 之后,我们要怎么使用呢?首先我们还是使用工具来测试一下:
登录成功之后,可以看到现在返回给我们了一个 JWT 令牌,接着我们就可以使用这个令牌了。比如现在我们要访问某个接口获取数据,那么就可以携带这个令牌进行访问:
注意需要在请求头中添加:
1 Authorization: Bearer 刚刚获取的 Token
如果以后没有登录或者携带一个错误的 JWT 访问服务器,都会返回 401 错误:
我们现在来模拟一下前端操作:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 <script > function getInfo ( axios.post (' http://localhost:8081/api/auth/login ' , { username : document .getElementById ('username' ).value , password : document .getElementById ('password' ).value }, { headers : { 'Content-Type' : 'application/x- www-form-urlencoded ' } }).then (({data} ) => { if (data.code === 200 ) { sessionStorage .setItem ("access_token" , data.data ) window .location .href = '/index.html' } else { alert ('登录失败:' +data.message ) } }) } </script >
接着是首页,获取信息的时候携带上 JWT 即可,不需要依赖 Cookie 了:
1 2 3 4 5 6 7 8 9 <script > axios.get (' http://localhost:8081/api/user/name ' , { headers : { 'Authorization' : "Bearer " +sessionStorage .getItem ("access_token" ) } }).then (({data} ) => { document .getElementById ('username' ).innerText = data.data }) </script >
这样我们就实现了基于 SpringSecurity 的 JWT 校验,整个流程还是非常清晰的。
退出登录 JWT 处理 虽然我们使用 JWT 已经很方便了,但是有一个很严重的问题就是,我们没办法像 Session 那样去踢用户下线,什么意思呢?我们之前可以使用退出登录接口直接退出,用户 Session 中的验证信息也会被销毁,但是现在是无状态的,用户来管理 Token 令牌,服务端只认 Token 是否合法,那这个时候该怎么让用户正确退出登录呢?
首先我们从最简单的方案开始,我们可以直接让客户端删除自己的 JWT 令牌,这样不就相当于退出登录了吗,这样甚至不需要请求服务器,直接就退了:
1 2 3 4 5 6 7 8 9 10 <script > ... function logout ( sessionStorage .removeItem ("access_token" ) window .location .href = '/login.html' } </script >
这样虽然是最简单粗暴的,但是存在一个问题,用户可以自行保存这个 Token 拿来使用。虽然客户端已经删除掉了,但是这个令牌仍然是可用的,如果用户私自保存过,那么依然可以正常使用这个令牌,这显然是有问题的。
目前有两种比较好的方案:
黑名单方案:所有黑名单中的 JWT 将不可使用。
白名单方案:不在白名单中的 JWT 将不可使用。
这里我们以黑名单机制为例,让用户退出登录之后,无法再次使用之前的 JWT 进行操作,首先我们需要给 JWT 额外添加一个用于判断的唯一标识符,这里就用 UUID 好了:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 public class JwtUtils {private static final String key = "abcdefghijklmn" ;public static String createJwt (UserDetails user) {Algorithm algorithm = Algorithm.HMAC256(key);Calendar calendar = Calendar.getInstance();Date now = calendar.getTime();3600 * 24 * 7 );return JWT.create()"name" , user.getUsername())"authorities" , user.getAuthorities().stream().map(GrantedAuthority::getAuthority).toList())
这样我们发出去的所有令牌都会携带一个 UUID 作为唯一凭据,接着我们可以创建一个专属的表用于存储黑名单:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 public class JwtUtils { private static final HashSet<String> blackList = new HashSet <>();public static boolean invalidate (String token) {Algorithm algorithm = Algorithm.HMAC256(key);JWTVerifier jwtVerifier = JWT.require(algorithm).build();try {DecodedJWT verify = jwtVerifier.verify(token);return blackList.add(verify.getId());catch (JWTVerificationException e) {return false ;public static UserDetails resolveJwt (String token) {Algorithm algorithm = Algorithm.HMAC256(key);JWTVerifier jwtVerifier = JWT.require(algorithm).build();try {DecodedJWT verify = jwtVerifier.verify(token);if (blackList.contains(verify.getId()))return null ;if (new Date ().after(claims.get("exp" ).asDate()))return null ;return User"name" ).asString())"" )"authorities" ).asArray(String.class))catch (JWTVerificationException e) {return null ;
接着我们来 SecurityConfiguration 中配置一下退出登录操作:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 private void onLogoutSuccess (HttpServletRequest request, HttpServletResponse response, Authentication authentication) throws IOException {"application/json;charset=utf-8" );PrintWriter writer = response.getWriter();String authorization = request.getHeader("Authorization" );if (authorization != null && authorization.startsWith("Bearer " )) {String token = authorization.substring(7 );if (JwtUtils.invalidate(token)) {"退出登录成功" ).asJsonString());return ;400 , "退出登录失败" ).asJsonString());
这样,我们就成功安排上了黑名单机制,即使用户提前保存,这个 Token 依然是失效的:
虽然这种黑名单机制很方便,但是如果到了后面的微服务阶段,可能多个服务器都需要共享这个黑名单,这个时候我们再将黑名单存储在单个应用中就不太行了,后续我们可以考虑使用 Redis 服务器来存放黑名单列表,这样就可以实现多个服务器共享,并且根据 JWT 的过期时间合理设定黑名单中 UUID 的过期时间,自动清理。
自动续签 JWT 令牌 在有些时候,我们可能希望用户能够一直使用我们的网站,而不是 JWT 令牌到期之后就需要重新登录,这种情况下前端就可以配置 JWT 自动续签,在发起请求时如果令牌即将到期,那么就向后端发起续签请求得到一个新的 JWT 令牌。
这里我们写一个接口专门用于令牌刷新:
1 2 3 4 5 6 7 8 9 10 11 @RestController @RequestMapping("/api/auth") public class AuthorizeController {@GetMapping("/refresh") public RestBean<String> refreshToken () {User user = (User) SecurityContextHolder.getContext().getAuthentication().getPrincipal();String jwt = JwtUtils.createJwt(user);return RestBean.success(jwt);
这样,前端在发现令牌可用时间不足时,就会先发起一个请求自动完成续期,得到一个新的 Token:
我们可能还需要配置一下这种方案的请求频率,不然用户疯狂请求刷新 Token 就不太好了,我们同样可以借助 Redis 进行限流等操作,防止频繁请求,这里就不详细编写了,各位小伙伴可以自行实现。
我们最后可以来对比一下两种前后端分离方式的优缺点如何:
JWT 校验方案的优点:
无状态: JWT 是无状态的,服务器不需要在后端维护用户的会话信息,可以在分布式系统中进行水平扩展,减轻服务器的负担。
基于 Token: JWT 使用 token 作为身份认证信息,该 token 可以存储用户相关的信息和权限。这样可以减少与数据库的频繁交互,提高性能。
安全性: JWT 使用数字签名或加密算法保证 token 的完整性和安全性。每次请求都会验证 token 的合法性,防止伪造或篡改。
跨域支持: JWT 可以在不同域之间进行数据传输,适合前后端分离的架构。
JWT 校验方案的缺点:
无法做到即时失效: JWT 中的 token 通常具有较长的有效期,一旦签发,就无法立即失效。如果需要即时失效,需要在服务端进行额外的处理。
信息无法撤销: JWT 中的 token 一旦签发,除非到期或者客户端清除,无法撤销。无法中途取消和修改权限。
Token 增大的问题: JWT 中包含了用户信息和权限等,token 的体积较大,每次请求都需要携带,增加了网络传输的开销。
动态权限管理问题: JWT 无法处理动态权限管理,一旦签发的 token 权限发生变化,仍然有效,需要其他手段进行处理。
传统 Session 校验方案的优点:
即时失效: Session 在服务器端管理,可以通过设置过期时间或手动删除实现即时失效,保护会话的安全性。
信息即时撤销: 服务器端可以随时撤销或修改 Session 的信息和权限。
灵活的权限管理: Session 方案可以更灵活地处理动态权限管理,可以根据具体场景进行即时调整。
传统 Session 校验方案的缺点:
状态维护: 传统 Session 需要在服务器端维护会话状态信息,增加了服务器的负担,不利于系统的横向扩展。
性能开销: 每次请求都需要在服务器端进行会话状态的校验和读写操作,增加了性能开销。
跨域问题: Session 方案在跨域时存在一些问题,需要进行额外的处理。
无法分布式共享: 传统 Session 方案不适用于多个服务器之间共享会话信息的场景,需要额外的管理和同步机制。
综上所述,JWT 校验方案适用于无状态、分布式系统,几乎所有常见的前后端分离的架构都可以采用这种方案。而传统 Session 校验方案适用于需要即时失效、即时撤销和灵活权限管理的场景,适合传统的服务器端渲染应用,以及客户端支持 Cookie 功能的前后端分离架构。在选择校验方案时,需要根据具体的业务需求和技术场景进行选择。
项目实战-大事件 环境配置
执行资料中的 big_event.sql 脚本,准备数据库表
创建 springboot 工程,引入对应的依赖(web、mybatis、mysql 驱动)
配置文件 application.yml 中引入 mybatis 的配置信息
创建包结构,并准备实体类
参数校验
参数名称
说明
类型
是否必须
备注
username
用户名
string
是
4-16 位非空字符
password
密码
string
是
4-16 位非空字符
使用 Spring Validation,对注册接口的参数进行合法性校验
引入 Spring Validation 起步依赖
在参数前面添加 @Pattern 注解
在 Controller 类上添加 @Validated 注解
1 2 @Validated @Pattern(regexp = "^\\S{4,16}$", message = "用户名格式不正确") String username
参数校验失败异常处理 1 2 3 4 5 6 @RestControllerAdvice public class GlobalExceptionHandler @ExceptionHandler(Exception.class) public Result handleException (Exception e) {return Result.error(StringUtils.hasLength(e.getMessage())?e.getMessage():"操作失败" );
==实体参数校验==实体类的属性上添加校验规则 ,然后在方法的形参前添加 @Validated 注解。
1 2 3 4 5 6 7 8 9 10 11 12 13 @Pattern(regexp = "^\\S{4,16}$", message = "用户名格式不正确") private String username;@Email @NotEmpty private String email;@PutMapping("/update") public Result update (@Validated @RequestBody User user) { return Result.success();
jakarta.validation.constraints 包中的常用校验注解如下表所示:
注解
解释
@AssertTrue
被注解的元素必须为 true
@AssertFalse
被注解的元素必须为 false
@DecimalMax
被注解的元素必须小于或等于指定的最大值
@DecimalMin
被注解的元素必须大于或等于指定的最小值
@Digits
被注解的元素必须是数字,并且限制整数和小数部分的位数
@Future
被注解的元素必须是将来的日期
@Max
被注解的元素必须小于或等于指定的最大值
@Min
被注解的元素必须大于或等于指定的最小值
@NotNull
被注解的元素不能为 null
@Null
被注解的元素必须为 null
@Pattern
被注解的元素必须符合指定正则表达式
@Size
被注解的元素必须在指定范围内
@NotEmpty
被注解的元素非 null,且非空
@Email
被注解的元素必须是邮箱格式
登录认证
承载业务数据,减少后续请求查询数据库的次数。
防篡改,保证信息的合法性和有效性。
JWT(JSON Web Token)https://jwt.io/
定义了一种简洁的、自包含的格式,用于通信双方以 jso 数据格式安全的传输信息。
组成:Header (头),记录_令牌类型、签名算法_等。例如:{“alg”:”HS256”,”type”:”JWT”)Payload (有效载荷),携带一些 自定义信息、默认信息(不包括密码等私密数据) 等。例如:{"id":"1","username":"Tom"}Signature (签名),防止 Token 被篡改、确保安全性。将 _header、payload,并加入指定秘钥,通过指定签名算法计算而来_。
载荷采用 Base64 编码,便于传输数据,中文 json 数据不支持直接传输。
Base64:是一种==基于 64 个可打印字符(A-Za-z0-9+)来表示二进制数据==的编码方式。
采用 java-jwt 或者 hutool 都可以:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 java-jwt:最基础的jwt包<dependency > <groupId > com.auth0</groupId > <artifactId > java-jwt</artifactId > <version > 4.4.0</version > </dependency > <dependency > <groupId > io.jsonwebtoken</groupId > <artifactId > jjwt</artifactId > <version > 0.9.1</version > </dependency > <dependency > <groupId > cn.hutool</groupId > <artifactId > hutool-jwt</artifactId > <version > 5.8.16</version > </dependency >
编写 Jwt 工具类,实现 token 生成、验证等方法
JWT 校验时使用的签名秘钥,必须和生成 WT 令牌时使用的秘钥是配套的。
如果 JWT 令牌解析校验时报错,则说明 JWT 令牌被篡改或失效了,令牌非法。
==hutool-jwt:==
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 @Test public void createJwtToken () {User user = User.builder().id(1 ).username("alleyf" ).build();new HashMap <>() {@Serial private static final long serialVersionUID = 1L ;"id" , user.getId());"username" , user.getUsername());"expire_time" , System.currentTimeMillis() + expire);"JWT令牌:{}" , JWTUtil.createToken(claims, secret.getBytes()));@Test public void parseToken () {String token = "eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJleHBpcmVfdGltZSI6MTcwMzYwMjk0MzQxNiwiaWQiOjEsInVzZXJuYW1lIjoiYWxsZXlmIn0.cw6142Ix4xHpYrM_Ol_VeNljw63oyIOKTjK_oFZiqkE" ; if (JWTUtil.verify(token, secret.getBytes())) { JWT jwt = JWTUtil.parseToken(token);
hutool-jwt 解析 jwt 的结果如下:JSONObject:{"typ":"JWT","alg":"HS256"}JSONObject:{"expire_time":1703602943416,"id":1,"username":"alleyf"}
==java-jwt:==
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 @Test public void testGen () {new HashMap <>();"id" , 1 );"username" , "张三" );String token = JWT.create()"user" , claims)new Date (System.currentTimeMillis() + expire))@Test public void parseJwtToken () {String token = "eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJ1c2VyIjp7ImlkIjoxLCJ1c2VybmFtZSI6IuW8oOS4iSJ9LCJleHAiOjE3MDM2MDIxMzh9.Y6FXkyOfoCl0CJd53_iqI3D6acxyK81b7UjvAY7sM_s" ;JWTVerifier jwtVerifier = JWT.require(Algorithm.HMAC256(secret)).build();DecodedJWT decodedJWT = jwtVerifier.verify(token);"JWT令牌:{}" , claims);
java-jwt 解析 jwt 的结果如下:Map<String, Claim>:{exp=1703602138, user={"id":1,"username":"张三"}}
由此可见 java-jwt 结果中嵌套了一层来存储用户信息,而 hutool-jwt 是直接将用户信息和过期时间保存在同一层的。
文件上传 本地存储 文件上传思路:
获取文件名和后缀基本信息(如果需要文件大小等附加信息也可以直接获取)
引入 yml 文件配置的文件存储路径,判断目录是否存在,不存在则新建该目录
定义一个文件唯一标识码 UUID,保证文件名唯一,防止同名文件被覆盖
拼接目录+uuid+类型得到待存储的文件名
把文件存储到本地磁盘目录
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 @PostMapping("/upload") public Result<String> upload (@RequestParam MultipartFile file) throws IOException {String originalFilename = file.getOriginalFilename();String type = FileUtil.extName(originalFilename);File uploadFileDirectory = new File (fileUploadPath);if (!uploadFileDirectory.exists()) {"创建文件目录失败" );String uuid = IdUtil.fastSimpleUUID();File uploadFile = new File (fileUploadPath + uuid + StrUtil.DOT + type);return Result.success("success" );
[!NOTE] 本地存储缺陷
云端存储 第三方服务-通用思路:
准备工作:开通第三方 OSS 对象存储服务,如阿里云 oss,腾讯云 oss,七牛云 oss 等。
创建 bucket(存储空间是用户用于游储对象(Object,就是文件)的容器,所有的对象都必须隶属于某个存储空间。)
获取 AccessKey (秘钥用户名)和 SecretKey(密码)
参照官方 SDK 编写入门程序
集成使用
本次测试以七牛云 oss 存储为例进行测试:
==文件上传工具类:==
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 package org.fcs.utils;import cn.hutool.core.io.FileUtil;import cn.hutool.core.util.IdUtil;import cn.hutool.core.util.StrUtil;import com.qiniu.storage.Configuration;import com.qiniu.storage.Region;import com.qiniu.storage.UploadManager;import com.qiniu.util.Auth;import lombok.extern.slf4j.Slf4j;import org.springframework.beans.factory.annotation.Value;import org.springframework.stereotype.Component;import org.springframework.web.multipart.MultipartFile;import java.io.IOException;import java.util.ArrayList;import java.util.HashMap;import java.util.List;import java.util.Map;@Component @Slf4j public class QiniuOssUtil {@Value("${qiniu.accessKey}") private String accessKey;@Value("${qiniu.secretKey}") private String accessSecretKey;@Value("${qiniu.bucket}") private String bucket;@Value("${qiniu.domain}") private String url;public List<Map<String, String>> uploadImages (MultipartFile[] multipartFiles) throws IOException {"张图片上传中..." );new ArrayList <>();for (MultipartFile file : multipartFiles) {String originalFilename = file.getOriginalFilename();String fileUrl = uploadImageQiniu(file);new HashMap <>() {"张图片上传成功" );return imageUrls;private String uploadImageQiniu (MultipartFile multipartFile) throws IOException {byte [] fileBytes = multipartFile.getBytes();String dirPath = "bigEvent/" ;String originalFilename = multipartFile.getOriginalFilename();String type = FileUtil.extName(originalFilename);String uuid = IdUtil.fastSimpleUUID();String filename = dirPath + uuid + StrUtil.DOT + type;Configuration cfg = new Configuration (Region.regionAs0());UploadManager uploadManager = new UploadManager (cfg);Auth auth = Auth.create(accessKey, accessSecretKey);String upToken = auth.uploadToken(bucket);return url + filename;
==Controller 接口实现层:==
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 @RestController @CrossOrigin @RequestMapping("/api/file") public class FileUploadController {@Value("${files.upload.path}") private String fileUploadPath;@Resource private QiniuOssUtil qiniuOssUtil;@PostMapping("/uploadToLocal") public Result<String> uploadToLocal (@RequestParam MultipartFile file) throws IOException {String originalFilename = file.getOriginalFilename();String type = FileUtil.extName(originalFilename);File uploadFileDirectory = new File (fileUploadPath);if (!uploadFileDirectory.exists()) {"创建文件目录失败" );String uuid = IdUtil.fastSimpleUUID();File uploadFile = new File (fileUploadPath + uuid + StrUtil.DOT + type);return Result.success("success" );@PostMapping("/uploadToQiniu") public Result<List<Map<String, String>>> uploadToQiniu (@RequestParam(required = false, value = "file") MultipartFile[] file) throws IOException {return Result.success(uploadedUrls);
接口测试结果如下图所示:
tomcat 默认上传的单个文件大小限制是 1M,同时上传默认的文件大小是 10M ,需要进行以下配置调整:
1 2 3 4 5 6 spring: servlet: multipart: max-file-size: 100MB max-request-size: 500MB
登陆优化 令牌主动失效机制
登录成功后,给浏览器响应令牌的同时,把==该令牌存储到 redis 中==
LoginInterceptor 拦截器中,需要==验证浏览器携带的令牌,并同时需要获取到 redis 中存储的与之相同的令牌==
当用户==修改密码成功后,删除 redis 中存储的旧令牌==
SpringBoot 集成 Redis
导入 spring-boot-starter-data-redis 起步依赖
在 yml 配置文件中,配置 redis 连接信息
调用 APl(StringRedisTemplate) 完成字符串的存取操作
springboot 的 redis 依赖:
1 2 3 4 <dependency > <groupId > org.springframework.boot</groupId > <artifactId > spring-boot-starter-data-redis</artifactId > </dependency >
配置文件配置 redis 连接信息:
1 2 3 4 5 6 7 8 data: redis: host: 127.0 .0 .1 port: 6379 password: 123456 database: 0 timeout: 3000
使用 StringRedisTemplate 操作 redis:
1 2 3 4 5 @Test public void test () { "user:name" , "alleyf" , 20 , TimeUnit.SECONDS); "user:name:{}" , redis.opsForValue().get("user:name" ));
redis 控制 token 有效与否
1 2 3 4 5 6 7 1000 , TimeUnit.SECONDS);"token已过期" );"密码修改成功" );
项目部署 项目写完后需要使用以下 maven 打包插件将项目打包为 jar 包运行于云服务器上:
1 2 3 4 5 6 7 8 9 <build > <plugins > <plugin > <groupId > org.springframework.boot</groupId > <artifactId > spring-boot-maven-plugin</artifactId > </plugin > </plugins > </build >
然后使用 maven 的 package 命令对项目进行打包,打包过程中会自动测试所有 @test 注解的方法,所有测试用例通过才能打包成功。
接着执行以下命令即可运行 jar 包:
1 java -jar big_event-1.0-SNAPSHOT.jar
环境属性配置 命令行参数 在启动 jar 时可以添加需要的参数进行动态配置:
1 2
环境变量 设置系统的环境变量(eg:windows 的用户变量,可以设置一个变量名为:server.port,值为:8080 ),jar 包启动时会自动读取环境变量进行配置.
外部配置文件 可以在 jar 包同级目录下编写一个 application.yml 外部配置文件,根据内容覆盖原配置文件的部分配置。
环境属性配置优先级如下 :优先级从上往下依次变高 。
项目中 resources 目录下的 application.yml
Jar 包所在目录下的 application.yml
操作系统环境变量
命令行参数
多环境开发-Profiles 单文件多环境配置 Spring Boott 提供的 Profiles 可以用来隔离应用程序配置的各个部分,并在特定环境下指定部分配置生效.
如何隔离不同环境?
如何指定哪些配置属于哪个环境?
1 2 3 4 spring: config: activate: on-profile: 环境名称
如何指定哪个环境的配置生效?
1 2 3 spring: profiles: active: 环境名称
多环境配置,不同环境之间通过 --- 分隔符区分:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 spring: profiles: active: prod --- spring: config: activate: on-profile: dev server: port: 8081 --- spring: config: activate: on-profile: prod server: port: 8082 --- spring: config: activate: on-profile: test server: port: 8083
通用环境配置信息与特定环境配置冲突,则采用特定环境配置信息 ,特定环境配置优先级高于通用配置。
多文件多环境配置
通过多个文件分别配置不同环境的属性
文件的名字为 application-环境名称.yml
在 application.yml 中激活环境
在 resources 目录下创建多环境 application-xxx.yml 文件(专有配置)和 application.yml(通用配置和环境激活配置)根配置文件。
多环境开发-Pofiles-分组 尽管按照环境拆分多文件配置,但是如果一个环境中配置太多也不利于维护管理,因此可以按照功能对不同环境的配置拆分为不同模块进行分组,如下图所示:
分组配置,一个组内包含多个模块配置。application-分类名.ymlspring.profiles.groupspring,profiles.active
细节要点
在用户实体上的密码字段添加 @JsonIgnore 设置密码在序列化转换为 json 字符串时忽略,从而在 json 字符串结果在不包含密码来保证信息安全,
1 2 3 @Pattern(regexp = "^\\S{4,16}$") @JsonIgnore private String password;
在实体的日期相关属性上一般可以添加 @JsonFormat 对序列化的 json 字符串格式进行设置,对日期一般设置以下格式:
1 @JsonFormat(pattern = "yyyy-MM-dd HH:mm:ss")
分组校验 :对同一个实体类被复用于不同的业务作为参数时分组采用不同的校验规则,以隔离校验条件实现不同业务逻辑。
未指定分组的校验项默认属于 Default 分组,并且分组可以继承,子类可以继承父类所有校验项 。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 @Data @Builder public class Category extends BaseEntity {@NotNull(message = "主键ID不能为空", groups = {Edit.class}) private Integer id;@NotEmpty(message = "分类名称不能为空", groups = {Add.class, Edit.class}) @Length(min = 2, max = 10, groups = {Add.class, Edit.class}) private String categoryName;@NotEmpty(message = "分类别名不能为空", groups = {Add.class, Edit.class}) @Length(min = 1, max = 10, groups = {Add.class, Edit.class}) private String categoryAlias;public interface Add {public interface Edit {
==controller 层==:
1 2 3 4 5 6 7 8 9 10 @PostMapping("/add") public Result<?> add(@Validated(Category.Add.class) @RequestBody Category category) {return Result.success();@PutMapping("/update") public Result<?> edit(@Validated(Category.Edit.class) @RequestBody Category category) {return Result.success();
自定义校验 ,已有的 Valid 校验不满足需求时可以自定义校验注解进行定制化校验,自定义校验需要包括以下几点:
自定义注解 State(包含三部分:message、groups、payload),并且 @Constraint 添加校验器
自定义校验数据的类 StateValidation(校验器)实现 ConstraintValidator 接口重写 isValid 方法
在需要自定义校验的地方使用自定义注解
在配置文件中开启数据库下划线命名字段到驼峰命名变量的自动转换 ,否则无法接收到数据库字段信息,数据库字段名通过下划线连接,而 java 程序中变量名遵循驼峰原则,因此两者需要进行转换。
1 2 3 4 5 6 7 mybatis: configuration: map-underscore-to-camel-case: true log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
PageHelper 分页实现:
引入xml 依赖 :1 2 3 4 5 6 <dependency > <groupId > com.github.pagehelper</groupId > <artifactId > pagehelper-spring-boot-starter</artifactId > <version > 1.4.7</version > </dependency >
controller 层:请求参数设置pageNum、pageSize 和附加条件参数 (一般设置为不必须参数)service 层:1.创建 pageBean 对象,2.开启分页查询 pageHelper,3.调用 mapper 方法条件查询,4.设置 pageBean,填充数据并返回 pageBean mapper 层:不使用 sql 注解,通过 xml 配置文件编写动态 sql(==mapper 标签的 namespace 属性指定扫描的 mapper 类、select 标签 id 属性指定映射 mapper 中的方法名、select 标签的 resultType 属性指定返回值映射类、where 标签条件查询结合 if 标签进行动态条件查询==)
springboot 每个 web 请求都是一个线程 ,spring boot web 层基于 servlet,servlet 的每个 request 是一个线程,因此用户每次请求都会从线程池中获取一个线程,从而隔离不同请求。
ThreadLocal,提供线程局部变量,每次设置新键值都是独立的,不会修改原来的键值,==常用于存储登录用户的信息==。
用来存取数据:set()/get(),减少参数传递
使用 ThreadLocal 存储的数据,线程安全,同一线程参数共享,不同线程参数隔离。
用完记得调用 remove 方法释放数据,否则会造成内存泄漏 。
每个请求都隔离在各自的线程中,因此 userId 的存取都是线程安全的获取到各自正确的值。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 @SuppressWarnings("all") public class ThreadLocalUtil { private static final ThreadLocal THREAD_LOCAL = new ThreadLocal (); public static <T> T get () { return (T) THREAD_LOCAL.get(); public static void set (Object value) { public static void remove () { JSONObject userJsonObj = ThreadLocalUtil.get();
当子类继承父类时 并且添加了 @Data 注解,需要在类上添加 @EqualsAndHashCode(callSuper = true) 注解,添加之后就可以在生成 equals/hashCode 方法时包含其父类的属性,否则生成的方法不包括父类属性 。或者在主包目录下新建 lombok.config 文件,并添加 config.stopBubbling=truelombok.equalsAndHashCode.callSuper=call,效果与第一种方法一样。
常用第三方库 简介 hutool 一个 Java 基础工具类,对文件、流、加密解密、转码、正则、线程、XML 等 JDK 方法进行封装,组成各种 Util 工具类,同时提供以下组件:
模块
介绍
hutool-aop
JDK 动态代理封装,提供非 IOC 下的切面支持
hutool-bloomFilter
布隆过滤,提供一些 Hash 算法的布隆过滤
hutool-cache
简单缓存实现
hutool-core
核心,包括 Bean 操作、日期、各种 Util 等
hutool-cron
定时任务模块,提供类 Crontab 表达式的定时任务
hutool-crypto
加密解密模块,提供对称、非对称和摘要算法封装
hutool-db
JDBC 封装后的数据操作,基于 ActiveRecord 思想
hutool-dfa
基于 DFA 模型的多关键字查找
hutool-extra
扩展模块,对第三方封装(模板引擎、邮件、Servlet、二维码、Emoji、FTP、分词等)
hutool-http
基于 HttpUrlConnection 的 Http 客户端封装
hutool-log
自动识别日志实现的日志门面
hutool-script
脚本执行封装,例如 Javascript
hutool-setting
功能更强大的 Setting 配置文件和 Properties 封装
hutool-system
系统参数调用封装(JVM 信息等)
hutool-json
JSON 实现
hutool-captcha
图片验证码实现
hutool-poi
针对 POI 中 Excel 和 Word 的封装
hutool-socket
基于 Java 的 NIO 和 AIO 的 Socket 封装
hutool-jwt
JSON Web Token (JWT)封装实现
用法 Hutool-all 是一个 Hutool 的集成打包产品,由于考虑到“懒人”用户及分不清各个模块作用的用户,“无脑”引入 hutool-all 模块是快速开始和深入应用的最佳方式。
引入 hutool-all 以便使用所有工具类功能。
引入 hutool-xxx 单独模块使用。
父工程引入 hutool-bom 进行版本管理,子工程按需引入 hutool-xxx 模块进行使用。
import 方式 如果你想像 Spring-Boot 一样引入 Hutool,再由子模块决定用到哪些模块,你可以在父模块中加入:
1 2 3 4 5 6 7 8 9 10 11 12 <dependencyManagement > <dependencies > <dependency > <groupId > cn.hutool</groupId > <artifactId > hutool-bom</artifactId > <version > ${hutool.version}</version > <type > pom</type > <scope > import</scope > </dependency > </dependencies > </dependencyManagement >
在子模块中就可以引入自己需要的模块了:
1 2 3 4 5 6 <dependencies>
使用 import 的方式,只会引入 hutool-bom 内的 dependencyManagement 的配置,其它配置在这个引用方式下完全不起作用。
exclude 方式 如果你引入的模块比较多,但是某几个模块没用,你可以:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 <dependencies > <dependency > <groupId > cn.hutool</groupId > <artifactId > hutool-bom</artifactId > <version > ${hutool.version}</version > <type > pom</type > <exclusions > <exclusion > <groupId > cn.hutool</groupId > <artifactId > hutool-system</artifactId > </exclusion > </exclusions > </dependency > </dependencies >
这个配置会传递依赖 hutool-bom 内所有 dependencies 的内容,当前 hutool-bom 内的 dependencies 全部设置了 version,就意味着在 maven resolve 的时候 hutool-bom 内就算存在 dependencyManagement 也不会产生任何作用。
Reference 1 2 3 4 url: https://itbaima.net/
柏码 - 让每一行代码都闪耀智慧的光芒!