图像分类
本文最后更新于:3 年前
背景介绍
LeNet:Yan LeCun 等人于 1998 年第一次将卷积神经网络应用到图像分类任务上[1],在手写数字识别任务上取得了巨大成功。
AlexNet:Alex Krizhevsky 等人在 2012 年提出了 AlexNet[2], 并应用在大尺寸图片数据集 ImageNet 上,获得了 2012 年 ImageNet 比赛冠军(ImageNet Large Scale Visual Recognition Challenge,ILSVRC)。
VGG:Simonyan 和 Zisserman 于 2014 年提出了 VGG 网络结构[3],是当前最流行的卷积神经网络之一,由于其结构简单、应用性极强而深受广大研究者欢迎。
GoogLeNet:Christian Szegedy 等人在 2014 提出了 GoogLeNet[4],并取得了 2014 年 ImageNet 比赛冠军。
ResNet:Kaiming He 等人在 2015 年提出了 ResNet[5],通过引入残差模块加深网络层数,在 ImagNet 数据集上的错误率降低到 3.6%,超越了人眼识别水平。ResNet 的设计思想深刻地影响了后来的深度神经网络的设计。
LeNet
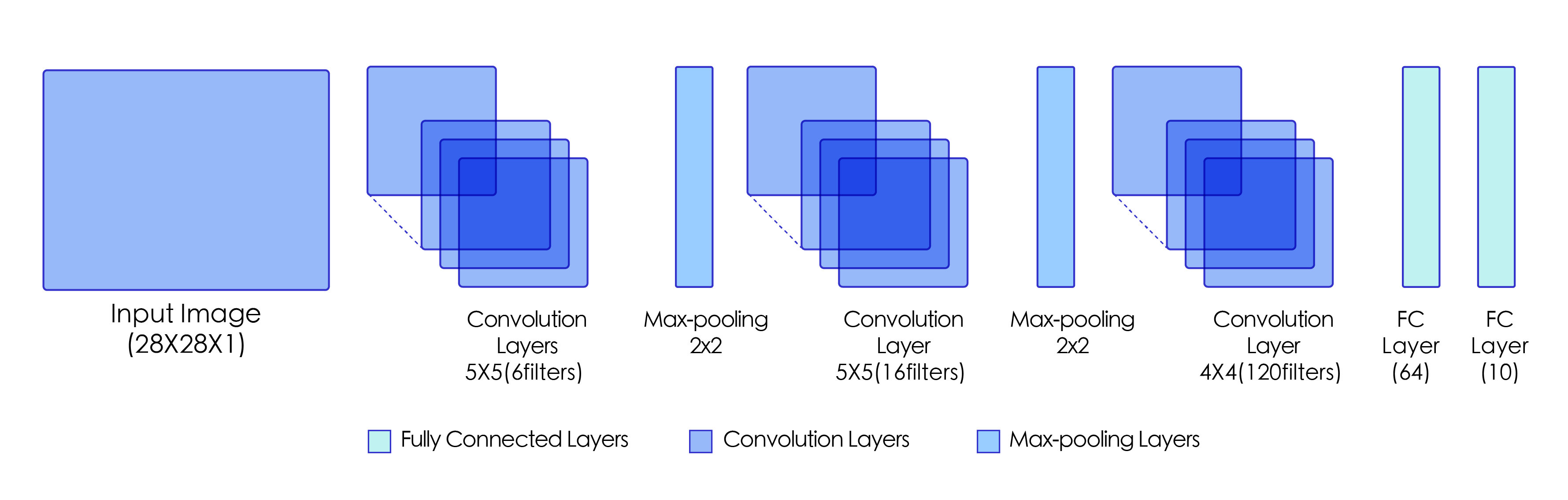
图1:LeNet模型网络结构示意图
【提示】:
[!NOTE] Tips
卷积层的输出特征图如何当作全连接层的输入使用呢?卷积层的输出数据格式是 $[N, C, H, W]$,在输入全连接层的时候,会自动将数据拉平,
也就是对每个样本,自动将其转化为长度为 $K$ 的向量,
其中 $K = C \times H \times W$,一个 mini-batch 的数据维度变成了 $N\times K$ 的二维向量。
手写数字识别
定义网络结构
1 | |
查看网络各层形状
1 | |
数据读取模型训练
1 | |
ResNet
解决网络层数加深后模型效果没有提升。
基础知识
残差块
实现方式:
一般残差块输出通道数为输入通道数的==四倍==。
ResNet-50
depth = [3,4,6,3]
表示 c2 有 3 个残差块,c 3 有 4 个,c 4 有 6 个,c 5 有 3 个。

飞浆高层 API:
1 | |
图像分类 ResNet 实战:眼疾识别分类
CV 任务研发流程

[!NOTE] Tips
其中,基本的计算机视觉任务研发全流程包含模型训练、模型预测和模型部署三大步骤。每个步骤又包含单独的流程:
- 数据准备:根据网络接收的数据格式,完成相应的预处理和跑批量数据读取器操作,保证模型正常读取;
- 模型构建:设计卷积网络结构;
- 特征提取:使用构建的模型提取数据的特征信息;
- 损失函数:通过损失函数衡量模型的预测值和真实值的不一致程度,通常损失函数越小,模型性能越好;
- 模型评估:在模型训练中或训练结束后岁模型进行评估测试,观察准确率;
- 模型预测:使用训练好的模型进行测试,也需要准备数据和模型特征提取,最后对结果进行解析。